原文链接
https://mp.weixin.qq.com/s/jA44AmWkHOIBl8VaQ5TUWQ
分享摘要
日志在企业应用中是最有价值的数据之一,追溯过去的记录,记录现在的状态,探寻未来的趋势。本文将分享云平台环境下大流量日志基于云原生技术的价值密度分类处理方案与落地实践,在提升企业日志服务质量、降低企业日志存储成本方面具有参考意义。
背景起源
360搜索是业务QPS峰值达数十万级的典型互联网大并发场景,高流量的业务伴随着大流量的日志,在日志输出效益、治理方面带来很大的挑战。在企业对于日志的价值目标输出落地以及存储管理成本方面,需要根据企业自身的特点和需求做出合适的解决方案,从而规避一刀切粗放的处理模式,有效的提升日志整体的服务质量。
在360搜索日志的价值输出方面,按照用途分为以商务分析的打点日志、以监控业务基本运行状况的监控分析日志、以日常运维排错的消费日志、以及反映基础平台健康状况的平台日志。
从分类特点的角度对日志提出了基于价值分类特性的不同要求。打点日志终端服务于商务,是商务正确输出商业分析数据,对宏观市场定位的重要数据支撑,需要保证日志的准确、稳定、连续,不丢失、不重复、不中断,价值密度很高,在管理上也提出了更高的要求,而这部分日志在总体的日志总量中的占比不到20%。业务监控日志实时反映出业务的QPS、延迟、处理能力等各方面的业务健康态、汇总分析层面指标,作为大屏投放输出企业的基本运营情况,这部分日志在总量日志中占比一般会达到30%。日常排错日志以及平台运行日志需要根据业务的重要性、消费频率、故障应急等输出合适的方案,在量比方面穿插于前两者之间,占比通常会超80%。
针对以上背景,结合云原生技术及企业自身特点,输出云计算平台价值密度的落地实践方案。
解决了哪类问题
方案起源一方面为有效解决不同类的日志服务质量问题、另一方面从企业运营成
本角度降低基于云原生的资源成本。
从搜索运营及成本的角度,在大业务流量规模下,需要解决日志在企业运营中不同角色、不同用途日志使用面临的问题,尽可能的发挥日志价值。以搜索云以下方面去分析:
总日志流量峰值在数GB/s,基于消息缓冲会形成日近百T左右的存储资源用量。
(1)、20%的商务打点日志需要保障7*24小时稳定运行,提供商务分析数据,重要性高但属于离线分析计算,可接受24小时延迟,数据占比也集中在个别重要业务的输出。
为应对数据的连续性以及准确性,通过消息集群建立缓冲生产与消费。总流量峰值在N百MB/s,单日志最大峰值在N百兆MB/s,以N个数据中心Kafka 几十台物理集群支撑,保留时常在24-72小时自动清理。为防止集群故障造成数据丢失,运行数百消费进程实时消费落HDFS留存。而该部分日志不涉及存储索引引擎检索以及可视化需求。
(2)、30%的业务分析日志大屏提供业务健康运行态监控,通过UDP输入原生全文索引ES,总流量峰值在N GB/s,单日志最大峰值不超过N百MB/s。以TB级ES集群提供支撑,以ES的索引查询能力和聚合计算输出业务运行监控数据运行指标和分析指标,在可视化及延迟及故障告警方面存较高要求。
(3)、80%的业务与平台运行日志用于日常排错,这部分日志与打点日志共用消息集群提供短期存储,根据需求进行短期消费。在检索查询、聚合、日志告警、消费资源、可视化方面有较强需求。
基于以上场景,分析主要问题集中在以下几个方面:
(1)、没有分类处理不同特性日志,输出不同角色、不同用途的日志使用需求;(2)、依托于消息集群提供缓存存储存留时间过短,存在大部分日志存已过期自动清理,无法消费使用问题。若增加留存时间,需加大消息集群规模,会有资源用量成倍增长的问题。(3)、消息集群提供缓冲存储的方式,不具备存储索引引擎检索能力,消费后数据入ES或其它引擎存储造成二次资源占用,或临时消费到本地文件存在文件过大无法检索问题。(4)、消费带来消费进程的资源占用,在流量较大的场景,准确实时获取数据需要按生产者分区数设定消费数,二次耗用资源。(5)、 人工干预过多,带来终端用户、管理者使用的复杂度,有统一管理降低人工依赖的需求。(6)、日志源、管理端、终端端点过多,没有有效的统一管理,存较高风险。(7)、日志使用需求方的可视化、检索、聚合、时效性无法分类覆盖。(8)、升级的风险考量评估。接入采集、版本升级、集群切换等场景,每次需要提前做风险评估预案,很难做到全覆盖。(9)、日志采集不统一,多采集、多存储、多引擎、多输出,造成新业务纳管困难,有较强统一采集需求。(10)、从提供日志服务给业务使用,需要从功能支撑、资源利用、风险评估、机房划分综合考量针对性梳理方案。
方案特性与预期收益
(1)、拥抱云原生,以云原生为基础展开集成、扩展。
(2)、适用于大流量日志场景下使用分类处理与服务输出。
(3)、与大数据平台解耦,可在PaaS范畴作为独立日志中心提供日志服务。
(4)、支持与大数据平台通过消息队列对接,与某头部云商大数据平台无缝对接。
(5)、部分云原生产品与社区脱离,暂无法同步社区升级迭代。
○1、以Beats 家族filebeat作为统一日志数据采集源,实时采集。
采集源:容器业务日志;基础平台日志;中间件日志;操作系统日志;Journal日志;
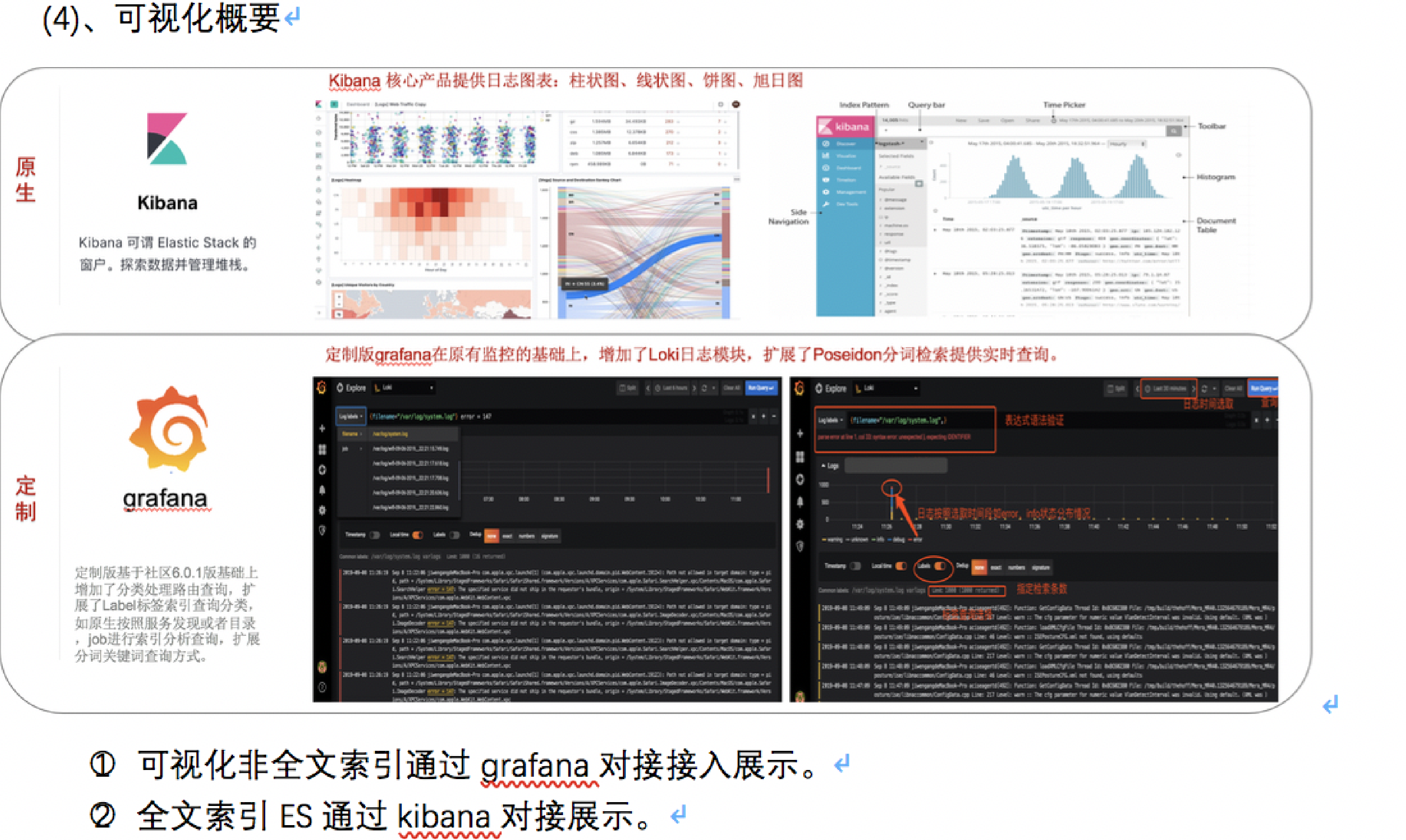
○2、以Grafana loki作为日常排错日志KV存储引擎,提供基于Label的索引检索及数据块压缩、可视化查询。适用于大部分业务日志场景。
○3、以Poseidon 作为基础平台日志规律性日志存储引擎,提供基于预先设定分词的高效分词索引检索,根据场景设定在线与离线计算。适用于大部分规律性平台日志。
○4、以Beats 家族ES作为业务监控日志的存储引擎,提供全文索引及可视化、告警对接与分析汇总计算功能。适用于价值密度高、留存较短的日志场景。
○5、以Kafka 作为商务分析日志的临时缓冲存储,提供一定周期的存储与消费,提供消费对接HDFS转储大数据分析,对接Grafana loki转储提供在线可视化检索查询。
○6、以 Queue 作为对接分类转发的规则处理,与以上引擎对接。
(2)、预期收益,
在日志用途输出方面,提升商务、监控等重要日志的服务级别,降低低频使用日志的资源用量。
在管理方面,降低一刀切日志的故障风险以及在运维管理、升级等方面的复杂度。
合理利用消息集群,释放消息集群资源规模,降低消费终端资源消耗。
基于分类处理的日志方案,降低资源成本40%,支持GB/s级流量,PB量级存储。
方案咨询设计
(1)、解决存储索引引擎特性分析与业务场景适配。
(2)、现行日志压缩减量、收集过滤减量、业务方优化减量。优化减量的目的在于在分类处理前日志的洁净,避免对后续环节造成流量压力。示例,在实际案例场景中,经过技术压缩及行级过滤以及业务日志精简,部分业务日志从N百M/s 减量到N百M/s,部分白名单过滤精简缩减20%整体日志量,部分Debug日志从N十M/s缩减至KB级。 整体缩减日志量在30%以上。
总体技术架构从采集、存储、检索、可视化到对接。
○1 统一采集。
○2 统一分类转发。
○3 分类存储索引引擎。
○4 缓冲消息队列。
○5 可视化集成。
○6 消息队列对接大数据。
技术概要:采集侧filebeat增加分类规则配置,输送配置数据到分发控制器分发。采集侧filebeat增加Qqueue output消息队列输出组件,作为分发控制器客户端。
采集侧增加snappy压缩包,在采集侧到数据落地前进行压缩,压缩率可达20%。
采集侧增加out多路输出,可同时支持多个out共享同一个pipeline数据管道输出,用于在集群升级切换时启动备用输出,防止商务打点日志中断。
采集侧增加processes处理,用于容器环境动态生成对象topic,如部署、任务、状态副本等不同对象多集群部署的容器,根据topic名称做日志聚合。
采集侧增加非容器日志以日志文件名指定topic并自动创建topic。
采集侧增加白名单过滤规则,用于从日志采集侧输入洁净日志。
采集侧增加zk集群服务配置基本信息,用于topic、分类配置规则等与分发器同步。
采集侧增加多源接入组件,用于不同类型如容器与非容器业务组件、不同目录日志如容器目录与系统日志目录,通过一套采集端一套配置支持。
增加分类处理器,用于接收采集数据消息队列,接收采集消息处理规则进行分类分发。
分类处理器增加ES、Loki、Poseidon output客户端,用于对接存储索引引擎。
Grafana Loki存储索引引擎剥离采集组件Promtail,规避数据丢失、收集功能单一等诸多问题。Promtail为基本日志采集组件,经过压测功能性能无法与beats媲美,Promtail优势在于复用Prometheus的服务发现包,在大规模大流量场景下并不适用。用filebeat输出消息的方式对接替代采集。
Grafana Loki 增加Poseidon查询接口,用于支持分词索引引擎Poseidon的grafana可视化查询。
Grafana修改Promtail Label查询方式,统一修改为filebeat Topic查询方式。
增加消息队列消费,用于商务分析数据及其他用途日志消费场景落地HDFS。
○1分发控制器分发消息到ES集群提供全文索引,通过kibana可视化查询。
○2分发控制器分发消息到HDFS落地。
○3分发控制器分发消息到Poseidon提供分词检索,通过Loki路由对接grafana可视化查询。
○3分发控制器分发消息到Loki,提供Label索引检索,通过grafana可视化查询。Loki KV剥离Promtail采集器,使用Filebeat以消息输出的方式接入。
方案的技术规划
落地的技术实践
基于原生的改造简述
提问链接
Q && A
一、 分类处理前生产部署三套daemonset资源占用过大,造成极大资源浪费。
多机房机房实例数CPU limit上下限/多机房总CPU = 20.39 %
多机房机房实例数MEM limit 上下限/多机房总MEM = 6.7%
二、 为什么不使用一套damonset统一采集。
主要原由有以下几个方面考量:
1)、Filebeat6.1 版本未同时支持多源不同模式采集,如容器日志文件方式输出,动态生成topic,基础平台日志静态Pod及系统日志方式、监控日志UDP采集等无法通过一套部署同时收集。
2)、同一套采集端无法保障商务打点日志的稳定、连续。容器日志收集、基础平台日志收集会较频繁变动配置如增加过滤规则,增加删减白名单后需要自动reload,reload过程中守护进程会存在至少reload时间差,对于百兆秒日志量的商务打点,reload时间差会造成数GB流量数据丢失。
3)、Filebeat屏蔽多路输出功能后,转发后置于官方推荐的logstash进行转发,而在大流量背景下的场景存在未选型logstash作为转发中继而直接输出的日志,从而在需要在采集源头增加多路输出功能,保障数据备份等重要功能。
4)、其他细节问题。
三、 单Filebeat实例资源占用过大,CPU、MEM 上下限资源均需要2-4G,造成极大的浪费,需要对单实例作优化。
1)、未分类前,日志的收集方式按照提取日志注册偏移量保障数据不丢失。存在问题对于商务打点日志输出,必须采用严格的偏移量来保障数据准确性,但是对于日常运维排错,低频使用的绝大部份日志,严格采用偏移量计算,在集群发生升级、重启采集端实例或者reload配置的情况,会造成大流量冲击。需要按照日志的特点进程分类处理,曾发生过一次采集damonset版本升级切换因偏移量数差造成流量极速上升打垮消息队列集群的故障。 优化点在于低频日志允许一定的切换数据丢失,从尾端重新收集。
2)、未分类前,采集日志扫描频率全部按照固定配置时间,需要根据日志的情况分类处理,对于不活动、或者活动频率较低的日志,可设置按小时级扫描,高频日志提升妙级扫描。
3)、其他细节优化,优化后CPU 上限2G MEM 上限2G,CPU 下限1G MEM下限0.5G。释放了机房核心资源。
解决问题总结:
一、通过增加多源接入及多路输出功能,将不同类型、不同目录的日志通过一套配置进行采集,商务打点日志通过多路输出作备份保障,容器日志文件输出方式与基础平台日志系统日志由多源接入建立响应的通道输出。二、从daemonset部署实例层面,从3套减少到1套部署,降低的资源用 量。三、从daemonset 单实例方面优化后,尤其在扫描优化后明显降低了CPU的单实例资源占用率,在对偏移量和文件尾部提取分类优化后,降低了MEM的资源用量,request 500m 实际监控运行通常不到100m。
一、 监控日志由业务内程序UDP输出,变更为容器目录日志,打标签输出。由filebeat统一采集。
二、 基础平台日志对静态pod、系统message、journal等通过扩展filebeat process覆盖到基本的k8s对象动态topic生成。对容器集群外日志,单独部署filebeat 采集数据,输送到Qqueue,部署实例较少,根据外围部署集群情况部署agent。
三、 商务打点通过容器目录收集,通过提取配置规则输送到Qqueue,转储HDFS。
Q1:filebeat 与flunted的区别大不?该如何选择
A: Fluentd 针对结构化的数据,灵活性是一个考量。
Q2:filebeat单纯采集docker日志发现不能获取docker.container.name,docker.container.image信息不知为何?
A:filebeat支持多种采集方式,可以将filebeat以进程运行在docker容器中,收集容器日志,也可以单独部署filebeat采集docker生成的日志文件,可以参考filebeat官方yaml配置文件。
Q3:能否对采集到的日志信息做到告警处理?
A:告警需要分场景,入库ES可以通过sentinl插件接入告警。 规范处理方式应将各类落地日志对接中心告警平台。
Q4 es的机器学习功能是否有实际价值?
A:在机器学习方面没有太多接触。
Q5:采集agent是sidecar还是daemon模式?
A:守护进程与二进制部署。分场景部署,大部分采集场景使用daemonset,部分集群外中间件等组件以systemd部署。
Q6:有没有EFKoperator相关项目推荐?
A:暂时没有相关推荐。
Q7:对于日志采集系统占用资源过多,怎么解决?
A:需要从各方面优化,技术层面也是优化项,如提取偏移量方式对流量有很大影响,如文件扫描频率,对cpu有很大影响。 优化点首先从原生参数根据业务场景进行适配调整,特殊场景考虑原生扩展。
Q8:能用filebeat采集journald日志吗?怎么将系统日志和pod日志用同一个filebeat采集?
有journalbeat 开源插件可以采集journald日志。系统日志和pod日志都落地文件,以多源目录采集,一般采用对接logstash做区分处理,若转发不采用logstash,需要扩展filebeat组件支持多目录指定不同的输出采集。
A:有没有调研过阿里开源的log-pilot来采集pod日志?
没有做过相关调研。
Q9:beats组件之间是否会有互相影响?比如filebeat MySQL的采集器 redis的采集器 docker的各种,部署很多是否会相互之间有影响
A:你指的是filebeat内置module模块和对外部采集方式如何统一一套部署采集而不相互有影响么? 如果是这样,通过filebeat配置文件指定module采集以及docker产生的文件配置进行采集。
Q10:日志告警是用的开源项目还是自研的呢?
A:根据自身的平台确定方案,本案例的场景可以通过开源方案做一些简单告警,如ES通过sentinl做告警,Loki通过grafana告警,若自有大数据平台或者单独的告警平台,按照平台规则对接告警。
Q11:日志系统接入消息队列的意义是什么?
A:消息队列是缓冲,重要日志接入消息队列可以提供缓冲存储,多次消费。

若有收获,就点个赞吧
0 人点赞
