- 概述和背景
- 整体平台架构
- 网络架构
- 如何解决虚拟机业务和容器业务的并存问题
- 应用开发流程变化
- SOA和service mesh的对比与取舍
- 总结
- Q & A
- 容器和微服务的区别以及它们的关联性、应用场景,客户群体,带来的价值?
- 用来什么软件实现 Service Mesh? istio?
- 实施过程当中有使用到Istio吗?有定制一些Mixer适配器吗?
- 不论是使用K8S或Istio都会产生大量的配置(yaml),尤其是Envoy/Istio,系统中会有大量零散的配置文件,维护困难,还有版本管理,有什么很好的维护实践经验吗
- 请问,实现微服务过程中有没有考虑分布式跟踪和分布式事务,如果有,和ServiceMesh有没有关系?
- 性能优化方案有哪些
- 有没有遇到过envoy被oom kill的情况,你们是如何处理的
- 刚才提及的全量接入http2,有文章链接吗
- 如何用jenkins自动完成k8s部署?
- 我理解房多多目前的Mesh方案没有给每个微服务配一个Envoy作为sidecar,而是使用一组Enovy并自研了xDS的配置发布管理系统,对吗?我想请问backend微服务之间的请求现在是怎么走的呢?
- service mesh比传统的微服务治理好在哪里?
- 你们目前的项目中, 大量的微服务,以及调度层,瓶颈和容灾是如何处理的?
- 还是有一个服务治理/配置管理的问题请教,比如cpu,内存,这种资源request,在dev,test,staging,prod环境均不同,那么我们在编写k8s配置的时候不同环境会不同,比如测试环境的replics数跟cpu需求就很低,生产就很高,谢谢,追问:那这个配置在不同环境是多个还是一个呢?
概述和背景
房多多国内领先的经纪人直卖平台,目前房多多app和多多卖房app的后端服务主要运行在自建的IDC机房。2018年之前,我们的服务都是运行在VM上,也同时基本上完成了基于dubbo的微服务改造,目前的语言技术栈主要有:Java、Node.js、Golang。相对于其他公司而言,技术栈不是特别分散,这给我们服务容器化带来了极大的便利。
我们在2018年Q3的时候已经完成大部分服务容器化,此时我们的微服务数量已经超过400个了,在沟通和维护上的成本很高。因为我们后端服务是主要是基于dubbo的,跟前端直接的交互还是通过http的方式,在没有上service mesh之前,http请求都是经过nginx转发的。
维护nginx的配置文件是一个工作量大且重复性高的事情,运维团队和业务团队迫切的需要更高效的方案来解决配置管理和沟通成本的问题,构建房多多 Service Mesh 体系就显得尤为重要。Envoy 是一个成熟稳定的项目,也能够满足近期的需求,在现阶段我们并没有人力去动 Envoy,所以我们直接使用了 Envoy做service mesh的数据平面,关于控制平面这块,在调研了一些方案之后,我们采用了自研的方案。
整体平台架构
我们的容器平台整体是基于物理机的,除了调度节点是用的虚拟机以外,所有的工作节点都是使用物理机。之前我们的虚拟化方案是用的Xenserver,Xenserver对高版本的内核支持并不好,会时不时的出现自动虚拟机关机的bug,所以我们在工作节点上只使用物理机以保障业务的稳定和高效。
我们的业务主要工作在自建idc机房,公有云只有少量的灾备服务。因为是自建机房,相比较公有云而言,自建机房使用macvlan是一个比较好的方案。我们预先划分了几个20位地址的子网,每个子网内配置一些物理机,通过集中式的ip管理服务去管理物理机和容器的ip。相比较bridge网络,macvlan网络有着非常接近物理网络的性能,尤其是在大流量场景下性能出色,下面一张图显示了性能对比:
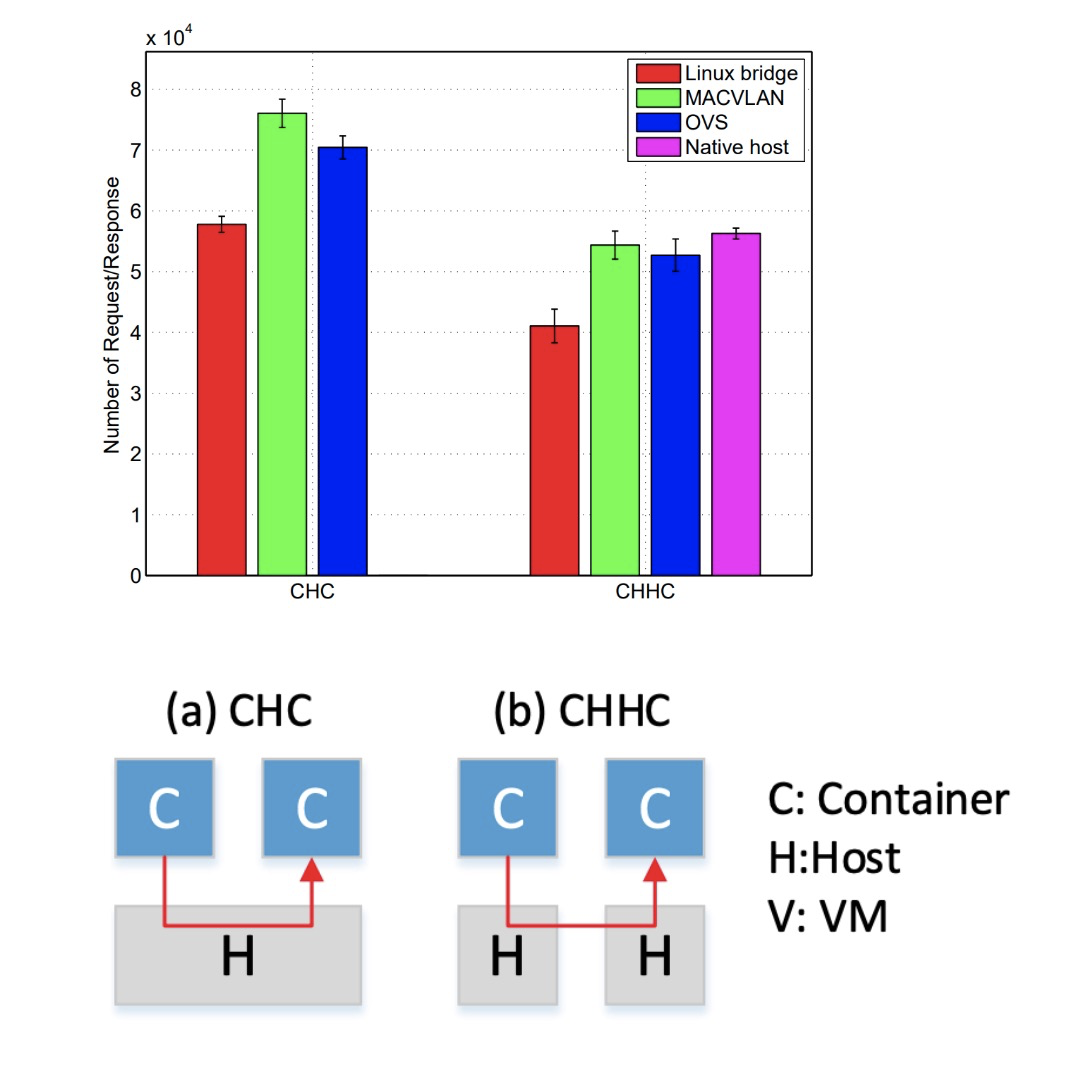
网络架构
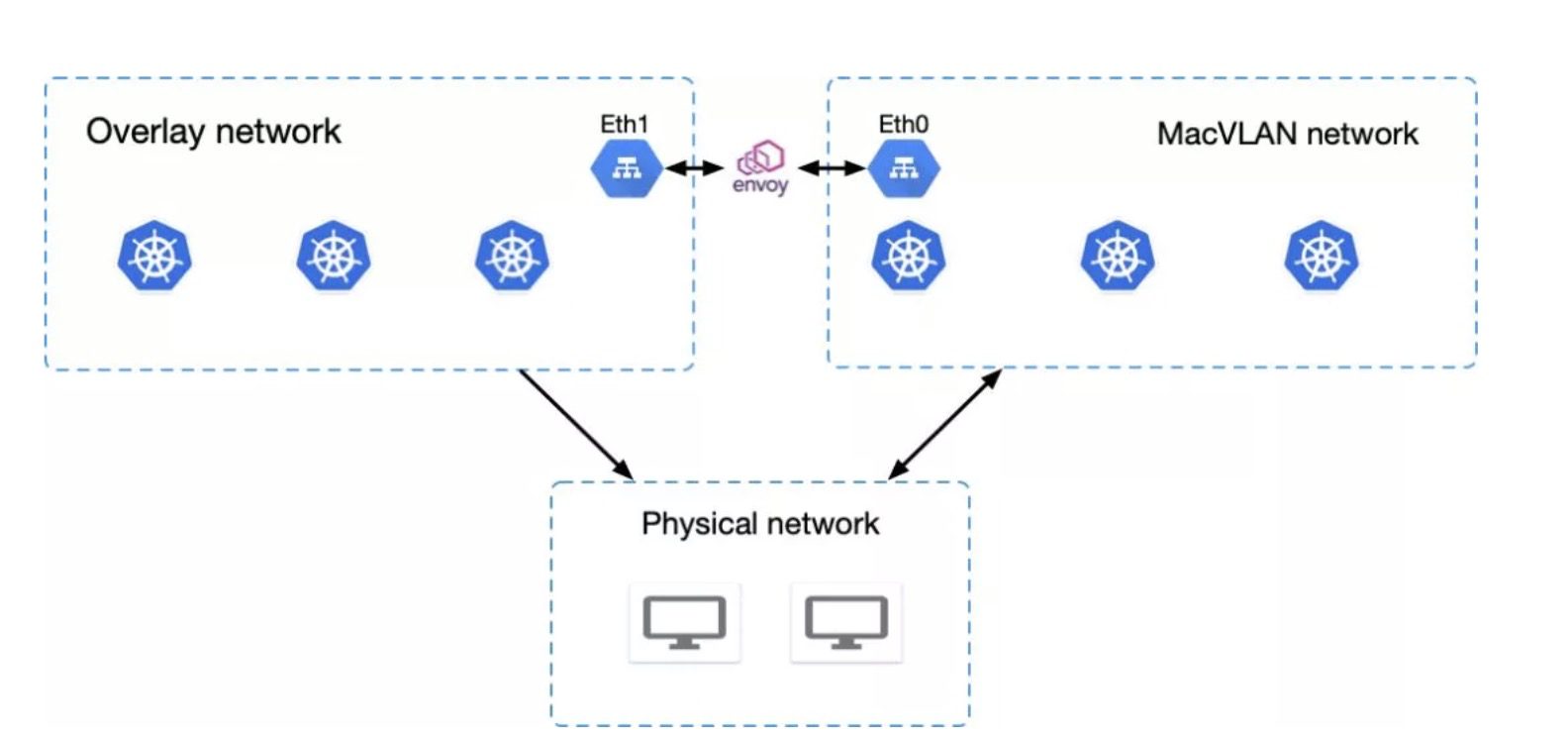
我们把envoy作为两个网络之间的连接桥,这么做的好处在于可以控制流量都经过负载均衡器,便于集中管理以及对流量做分析。看到这里,肯定有疑问是为什么不使用sidecar的方式部署envoy。
这就形成了下图的服务调用架构
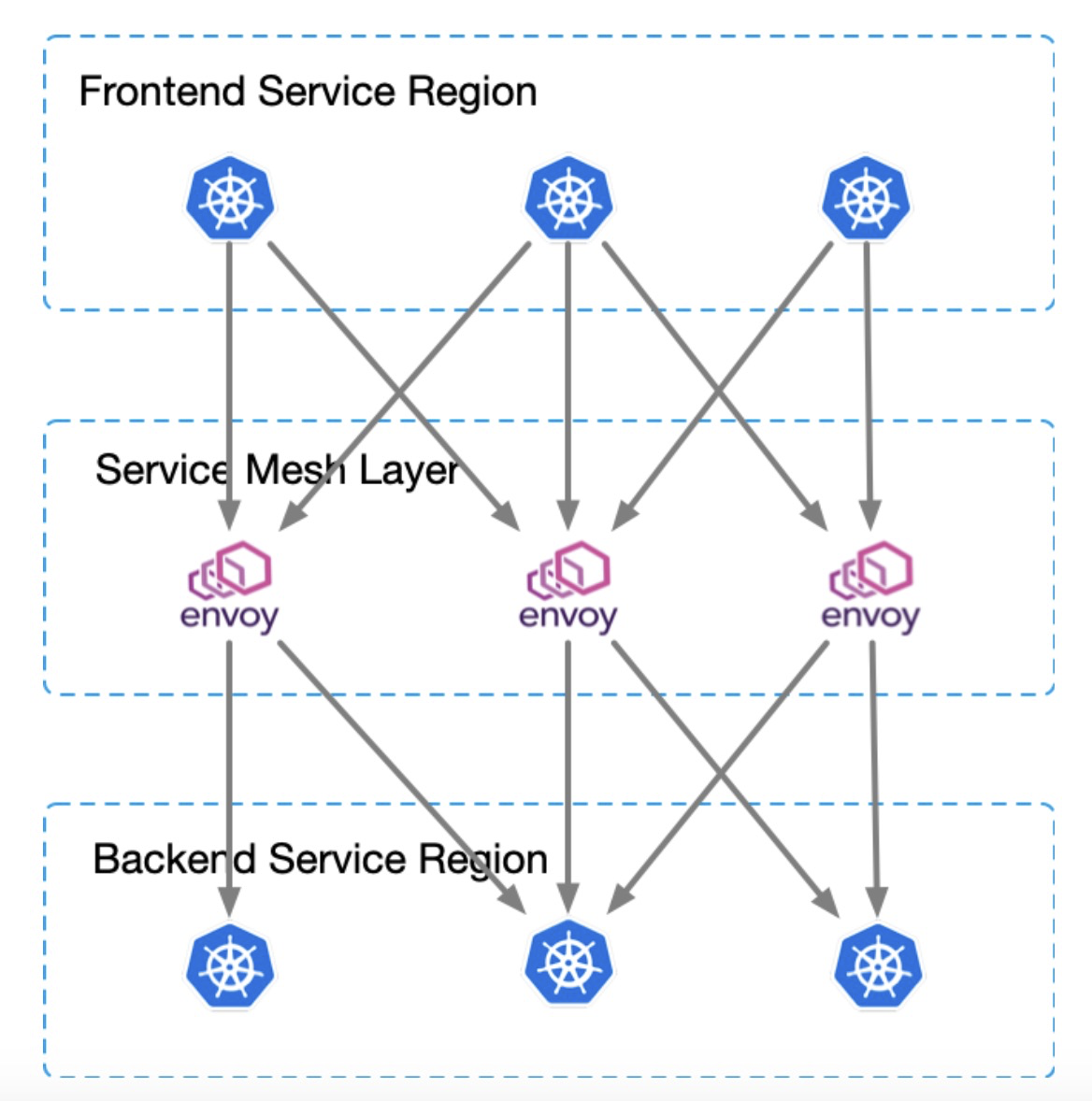
关于sidecar我的考虑是,在现有的业务场景下,集中部署的维护成本更低且性能满足需求,也相对来说比较简单。我们在2018年Q4已经完成主要业务http2接入,目前来看,我们的网站速度应该是同行业中最快的,大家可以体验一下,https://m.fangdd.com
如何解决虚拟机业务和容器业务的并存问题
我们原有的架构大量使用了虚拟机,迁移虚拟机上面的服务是一个漫长的过程,当前阶段还需要解决业务的并存问题,我们自己开发了envoy对应的配置集中管理服务,同时支持虚拟机服务和容器服务。
控制平面服务主要基于data-plane-api开发,功能上主要是给数据平面提供服务的集群配置、路由配置等信息,并且需要实现微服务架构中重试和限流的配置功能。容器内部的集群数据主要依赖dnsrr实现,而虚拟机上的服务,我们在CMDB上存有appid和机器的对应关系,很容器生成集群配置数据。
由于历史原因,还有相当多的业务无法从 VM 迁移到容器,需要有一个同时兼容容器和 VM 的数据平面服务,目前 XDS 服务的支持的功能如下:
集群数据来源同时包括容器内部DNS和外部CMDB中的 VM 数据
支持多个 vhost 配置
支持路由配置
支持速率控制和网关错误重试
envoy的动态路由配置:
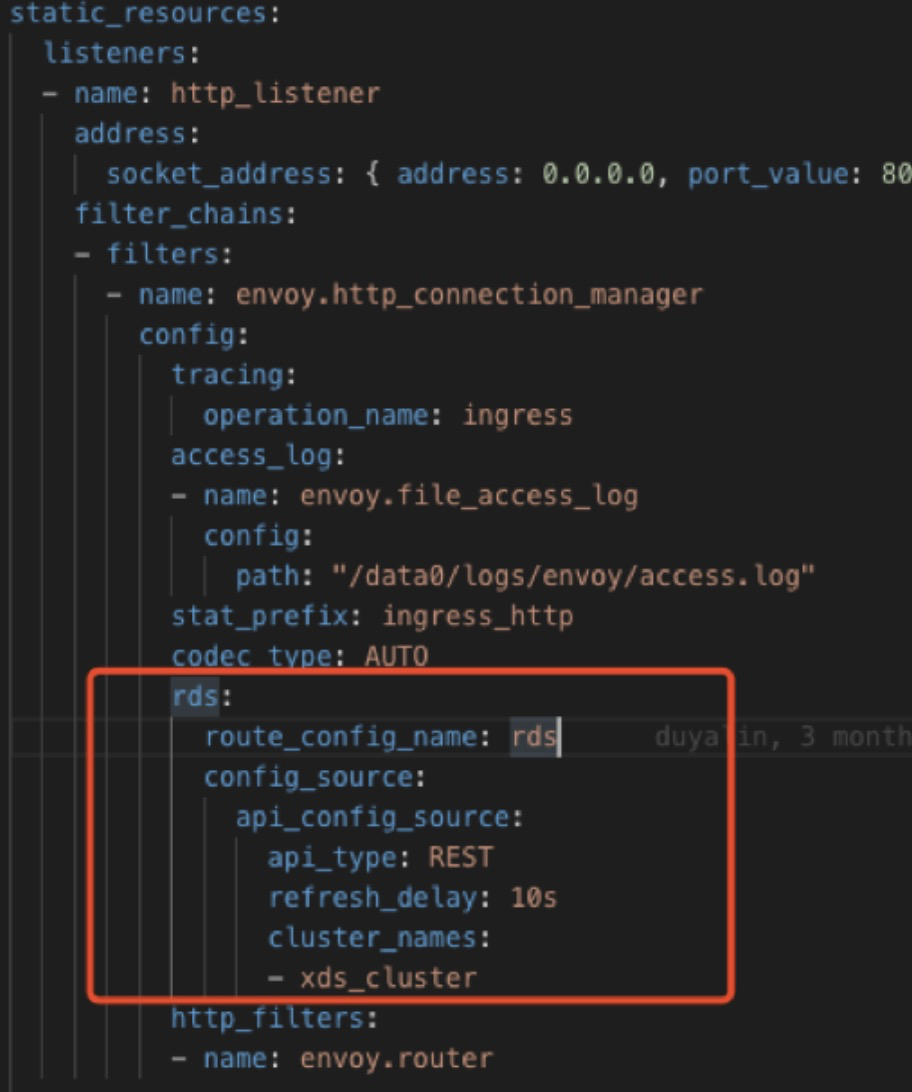
应用开发流程变化
初步建设起service mesh体系之后,理论上业务开发只需要开发一个单体服务,在服务间互相调用的过程中,只需要知道服务名即可互相调用,这就很像把所有服务都看做一个微服务一样,所以我们的业务开发流程发生了以下变化:
同时也降低了框架开发成本和业务改动的成本,每次推动业务升级框架都需要比较长的一段时间,业务无法及时用上新框架的功能,多种框架版本也加重运维负担,Service Mesh 帮我们解决了很多痛点。同时再加上我们的网关层建设,我们上线一个新服务几乎是零配置成本的。
代理层实现服务发现,对于开发而言只需要开发一个单机的应用,降低框架开发成本
降级和限流都在代理层实现,规则灵活,方便修改策略
框架功能的升级无需依赖业务
SOA和service mesh的对比与取舍
在我们的service mesh实践中,增加了链路的请求长度,并且服务的链路越长,链路请求的放大效应会越明显,这就带来了一些性能上面的担忧。
毫无疑问,mesh层本身的业务逻辑开销是不大,但是在网络传输和内存复制上的性能消耗在一定程度上会影响链路的性能,envoy也在探索相关的方案来优化网络传输性能,如bpfilter和VPP,减少用户态和内核态的内存拷贝。在可定制性层面,SOA能做的事情也相对较多,可以实现很多hack的需求。
在我们现有的业务场景下,service mesh主要还是解决前后端的微服务对接问题,当做前后端服务的连接桥梁。但不可否认的是,service mesh带来研发效率的提升,在现有的场景下的价值远大于性能上的损失。
在大多数的场景下,维护业务框架需要比较大的人力成本,很多团队都没有全职的人去维护业务框架。此外,推动业务框架的更新和升级也相对来说成本较高,这也是我们考虑的一个重要方面。
总结
得益于云原生架构,Service Mesh 可以使用云原生的基础设施,基础设施能力的改进可以直接赋能业务,而不像传统的框架一样,基础设施的升级和改进无法提高传统框架的服务能力。房多多的 Service Mesh 还处于初级阶段,后面还将继续探索。
Q & A
容器和微服务的区别以及它们的关联性、应用场景,客户群体,带来的价值?
微服务的应用场景主要是解决降低单个服务体积,满足业务的快速开发需求。容器可以说是微服务的载体,容器方面还是运维关注的比较多,带来的标准化
用来什么软件实现 Service Mesh? istio?
我们目前只使用了envoy,istio也做过一些选型的调研,不是很符合我们现在的业务场景和业务需求,我们在之后的实践中会考虑使用一部分istio的功能。
实施过程当中有使用到Istio吗?有定制一些Mixer适配器吗?
目前还没有用,之后会考虑是用istio中的pilot,我们目前在流量的控制程度上面还欠缺
不论是使用K8S或Istio都会产生大量的配置(yaml),尤其是Envoy/Istio,系统中会有大量零散的配置文件,维护困难,还有版本管理,有什么很好的维护实践经验吗
是的,据我所知有些团队会使用configmap来管理配置,我们做了一个配置的集中管理服务,从CMDB和dns定时的抓取数据,数据会存在数据库里面,也会存一定量的副本用于配置回退,这个地方还是要结合你们现在其他配套系统的建设来看看怎么做比较好的。
请问,实现微服务过程中有没有考虑分布式跟踪和分布式事务,如果有,和ServiceMesh有没有关系?
service mesh层可以做到简单的分布式追踪,比如可以做到基于请求的追踪,envoy可以把trace数据接入zipkin这样的trace系统,但是更细粒度的trace目前还做不到。
性能优化方案有哪些
之前文章中有提到过,对于http服务可以全量接入http2,http2的长连接和多路复用对于一般的业务来说提升是很明显的,我们在全量接入http2之后,网站的响应时间几乎下降了50%。另外还可以在底层的依赖上面做一些优化
有没有遇到过envoy被oom kill的情况,你们是如何处理的
这个我有碰到过一次,之前我们在对envoy做测试的时候,发现envoy总会尽可能的占满cgroup的内存大小,这个之前在使用TLS的情况下碰到的比较多。但是目前我们内部服务间使用TLS的情况并不多,所以后续这个问题就没有继续跟进了。
刚才提及的全量接入http2,有文章链接吗
这个目前还没有写成文章,我们做了一些前期准备工作,我们在端上做了一些改进,主要是nodejs这边我们自己做了一个fddRequest组件,用来包装http请求,会在请求头里面带上服务标识和校验。有了端上的组件支持还需要后端服务和负载均衡器支持,现在mesh层基本可以代理我们生产环境的所有服务。
如何用jenkins自动完成k8s部署?
自动部署这块我们有完善的发布系统,如果单纯只要实现jenkins自动完成k8s的话,jenkins可以直接调用k8s的api,这个网上有挺多资料的,你可以找找看。
我理解房多多目前的Mesh方案没有给每个微服务配一个Envoy作为sidecar,而是使用一组Enovy并自研了xDS的配置发布管理系统,对吗?我想请问backend微服务之间的请求现在是怎么走的呢?
是的,刚刚文章中说了,我们后端SOA服务还是基于dubbo的,这块目前我们还没有做改动,之后的话我们的初步构想会通过sidecar的方式把这些dubbo服务都接入到mesh里面来。我们目前的Envoy也是会充当网关的角色。
service mesh比传统的微服务治理好在哪里?
降低框架开发成本、代理规则灵活,方便修改策略、框架功能的升级无需依赖业务,最大的好处我觉得就是可以降低框架开发成本。
你们目前的项目中, 大量的微服务,以及调度层,瓶颈和容灾是如何处理的?
由于我们的业务类型还是B端业务为主,流量的峰值是可以预估的,很少会出现突发的大流量的情况,我们一般都预留了1倍的容量用于临时的扩容。容灾和调度的话我们主要还是尽可能的隔离工作节点和调度节点,以及大量使用物理机集群,从我们的使用体验上来看,物理机的稳定性还是很不错的。
还是有一个服务治理/配置管理的问题请教,比如cpu,内存,这种资源request,在dev,test,staging,prod环境均不同,那么我们在编写k8s配置的时候不同环境会不同,比如测试环境的replics数跟cpu需求就很低,生产就很高,谢谢,追问:那这个配置在不同环境是多个还是一个呢?
我们现在会在CMDB里面维护这些配置数据,一般来说在新建项目的时候,我们就会要求业务线评估一下这个业务需要的资源,比如你说到的test和staging环境这种,我们默认会给一个很低的需求,比如1c1g这样的,而且replication也会默认设置为1,除非业务有特殊的需求,然后我们去根据配置的数据去生成yaml格式为配置。
配置在数据存储的形式上是多个,但是在对业务展示上,尽量让业务感觉到是一个数据,这样也能使每个环境都规范起来,跟生产环境尽可能保持一致,这个对测试的好处还是很大的。

若有收获,就点个赞吧
0 人点赞
