第一章
- 谷歌的三驾马车:GFS(Google File System,包含ChunkServer,对应HDFS);MapReduc);BigTable(包括TabletServer,RegionServer。对应HBase)
GFS的块副本位置选择有两大目标:最大化数据的 可靠性 和 可用性。对比HDFS,其机架感知主要考虑 安全 和 效率。
Hadoop的作者是:Doug cutting
- Hadoop数据块默认冗余度是 3,Hadoop1.x默认每个数据块的大小是 64M ,Hadoop2.x时默认大小为128M
- 大数据的核心问题是 存储 和 计算 ,分别对应Hadoop中的 HDFS 和 MapReduce 技术
- Hadoop 源自始于 2002 年的 Apache Nutch项目。
- Hadoop 集群默认没有严格的权限管理和安全措施保障。
- 当 NameNode 出错时,采用 NameNode HA,当一个 NameNode 出错时,另一个 NameNode 接管它的工作。是最佳方案。
- HDFS Federation(联邦),当一个 Namenode 挂掉了,不会影响其他 Namenode。
- Namenode 在启动时自动进入安全模式,在安全模式阶段,文件系统不允许有修改
- 快照是 HDFS 2.x 版本新增加的基于某时间点的数据的备份复制。开启快照的 命令是: hdfs dfsadmin -allowSnapshot
, 禁用快照的命令是 hdfs dfsadmin -disallowSnapshot 。
第二章
- HDFS 回收站默认不开启
- HDFS 为每一个用户都创建了回收站,这个类似操作系统的回收站。位置是 /user/用户名/.Trash/
- hdfs dfs -expunge 命令清空回收站
- 写入数据后,多个副本会复制到不同机架的多个 DataNode 中。(注意,第一个写入的数据就在数据节点本地,写入时是不会同时写到多个数据节点中的。)
- HDFS 的是基于流数据模式访问和处理超大文件的需求而开发的,具有高容 错、高可靠性、高可扩展性、高吞吐率等特征,适合的读写任务是 一次写入,多次读写
- SecondaryNameNode 默认每隔 60 分钟,或当 edits (editLog)文件达到 100 万 条事务进行合并。
- 请描述 Hadoop 副本冗余存储策略(机架感知)。
答:
默认副本数为 3
第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑选一台 磁盘不太满、CPU 不太忙的节点。
第二个副本:放置在与第一个副本不同的机架的节点上。
第三个副本:与第二个副本相同机架的其他节点上。
更多副本:随机节点
第四章
- YARN Web 界面默认占用 8088 端口
第五章 MapReduce
- MapReduce无法进行实时处理(流处理)
- MapReduce 是一种简化__并行计算_的编程模型。简而言之,MapReduce 就是 “分散任务(map),_汇总结果(reduce)_”
- MapReduce中Mapper(Map任务)的个数是由输入分片(SplitInput)决定的,即文件内容切成多少段,是一种逻辑划分。
- Reducer的个数是由Partition分区的个数决定的(partition/partitioner:用来指定map输出的key交给哪个reuducer处理。
默认是通过对map输出的key取hashcode对指定的reduce个数取余
partition数决定reduce数,业务又决定reduce数) - MapReduce 程序的默认数据读取组件是 TextInputFormat
- MapReduce 编程模型中 Reducer 组件是最后执行的。
- 开发 MapReduce 程序,自定义的类型如果要实现序列化,需要实现接口_Writable_。
- MapReduce 程序只能对 key 排序
- Combiner 是一种特殊 Reducer,在 Mapper 端,先执行一次 Reducer
- MapReduce 中,OutputFormat 主要用于描述输出数据的格式,采用 NullWritable 可以省略输出的 key 或 value。


第六章 HBase和Hive
- HBase Web Console 的默认端口是 16010
- 查看 HBase 的表的结构,可以通过 describe 命令.
- 通过 JAVA API 操作 HBase,哪个 JAVA 类是操作列簇的? HtableDescriptor
- 从存储位置上,可以拿 Hive 与 HDFS 进行比较,下面说法不正确的是? Hive 的桶保存到 HDFS 上是一个目录 (不正确)
- Hive 哪一种数据模型,删除表时,存储目录中的数据不会被删除,只是删 除与数据的链接? 外部表
- hive 不支持数据删除和修改(数据仓库一般不能直接修改)
- Region_是 HBase 中分布式存储和负载均衡的最小单 元。
- HBase 列数据属性中,_时间戳_作为列数据版本, HBase(0.96 版本之后的HBase)每个列默认只存_1__个数据版本。
- HBase 的安装分_本地模式__、_伪分布模式 _、完全分布模式(或集群模式)_三种。(与Hadoop相同)
- HBase 要删除一张表,第一步__disable __‘表名称’, 第二步 __drop__‘表名称’(注:空格内填 HBase Shell 的命令)
- Hive 的 Metastore 三 种 运 行 模 式 分 别 是 : _Embedded(或嵌 入)__、_Local(本地)__、_Remote (远程)__。
- Hive 最终都会转化为__MapReduce__程序来运行。
问答题
如果把 HBase 看作是一个 Key-Value 型数据库,哪它的 Key 是什么?
答:表、行键、列族、列限定符和时间戳
请用图形描述 HBase 的体系结构,并文字描述 HBase 主要组成部分的职责。
答: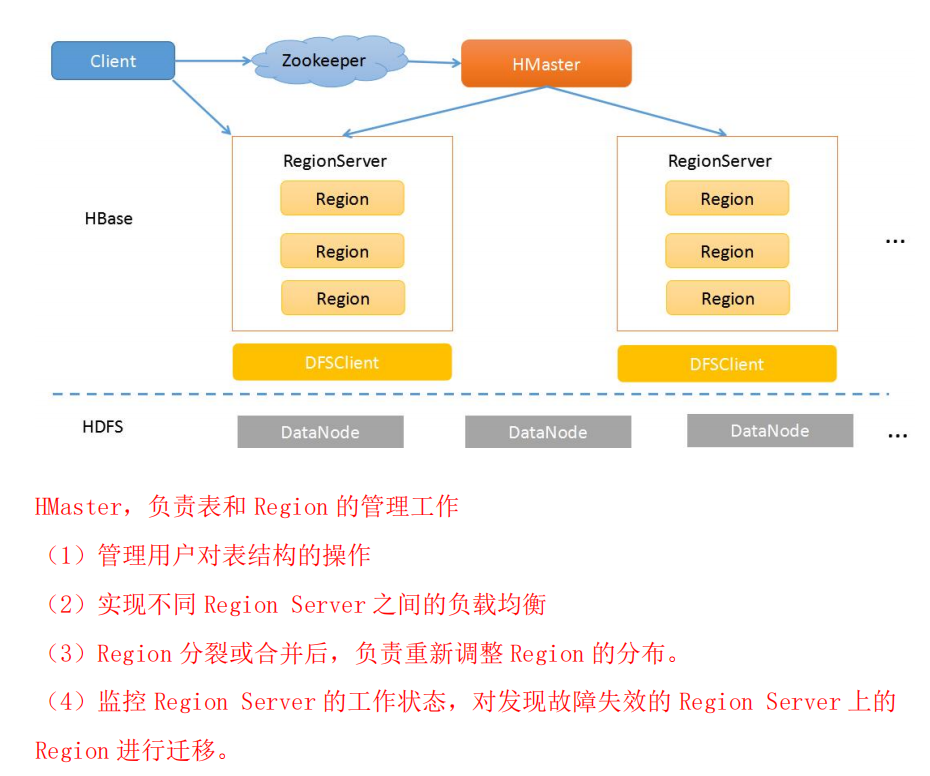

第九章
- Zookeeper 服务端默认的对外服务端口是 2181

若有收获,就点个赞吧
0 人点赞
