🥖ElasticSearch-01-ElasticSearch基础概念
ElasticSearch(简称ES)Elasticsearch是用Java开发并且是当前最流行的开源的企业级搜索引擎。能够达到实时搜索,稳定,可靠,快速,安装使用方便。
官方网站: https://www.elastic.co/
下载地址:https://www.elastic.co/cn/start
🍼为什么要学习ElasticSearch呢?
1、在当前软件行业中,搜索是一个软件系统或平台的基本功能, 学习ElasticSearch就可以为相应的软件打造出良好的搜索体验。

2、其次,ElasticSearch具备非常强的大数据分析能力。虽然Hadoop也可以做大数据分析,但是ElasticSearch的分析能力非常高,具备Hadoop不具备的能力。比如有时候用Hadoop分析一个结果,可能等待的时间比较长。
3、ElasticSearch可以很方便的进行使用,可以将其安装在个人的笔记本电脑,也可以在生产环境中,将其进行水平扩展。
4、国内比较大的互联网公司都在使用,比如小米、滴滴、携程等公司。另外,在腾讯云、阿里云的云平台上,也都有相应的ElasticSearch云产品可以使用。
5、在当今大数据时代,掌握近实时的搜索和分析能力,才能掌握核心竞争力,洞见未来。
🍼ElasticSearch到底是什么?
ElasticSearch是一款非常强大的、基于Lucene的开源搜索及分析引擎;它是一个实时的分布式搜索分析引擎,它能让你以前所未有的速度和规模,去探索你的数据。
它被用作全文检索、结构化搜索、分析以及这三个功能的组合:
- Wikipedia 使用 Elasticsearch 提供带有高亮片段的全文搜索,还有 search-as-you-type 和 did-you-mean 的建议。
- 卫报 使用 Elasticsearch 将网络社交数据结合到访客日志中,为它的编辑们提供公众对于新文章的实时反馈。
- Stack Overflow 将地理位置查询融入全文检索中去,并且使用 more-like-this 接口去查找相关的问题和回答。
- GitHub 使用 Elasticsearch 对1300亿行代码进行查询。
- …
除了搜索,结合Kibana、Logstash、Beats开源产品,Elastic Stack(简称ELK)还被广泛运用在大数据近实时分析领域,包括:日志分析、指标监控、信息安全等。它可以帮助你探索海量结构化、非结构化数据,按需创建可视化报表,对监控数据设置报警阈值,通过使用机器学习,自动识别异常状况。
ElasticSearch是基于Restful WebApi,使用Java语言开发的搜索引擎库类,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。其客户端在Java、C#、PHP、Python等许多语言中都是可用的。
🍼ElasticSearch与Lucene的关系
Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库(框架)
但是想要使用Lucene,必须使用Java来作为开发语言并将其直接集成到你的应用中,并且Lucene的配置及使用非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Lucene缺点:
- 只能在Java项目中使用,并且要以jar包的方式直接集成项目中.
- 使用非常复杂-创建索引和搜索索引代码繁杂
- 不支持集群环境-索引数据不同步(不支持大型项目)
- 索引数据如果太多就不行,索引库和应用所在同一个服务器,共同占用硬盘.共用空间少.
上述Lucene框架中的缺点,ES全部都能解决.
Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单,**通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API**。
然而,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:
- 一个分布式的实时文档存储,每个字段 可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
🍼ES vs Solr比较
Elasticsearch 基本被大量的互联网厂商使用,当然还有一些其他的组件比如Solr 下面就简单的配合ES 说明一下
当单纯的对已有数据进行搜索时,Solr更快。

当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。
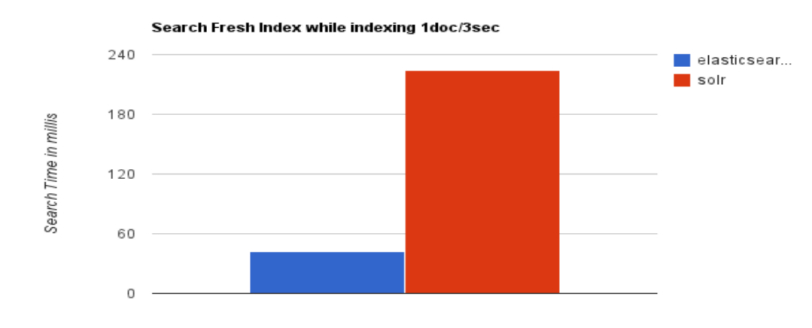
大型互联网公司,实际生产环境测试,将搜索引擎从Solr转到 Elasticsearch以后的平均查询速度有了50倍的提升。
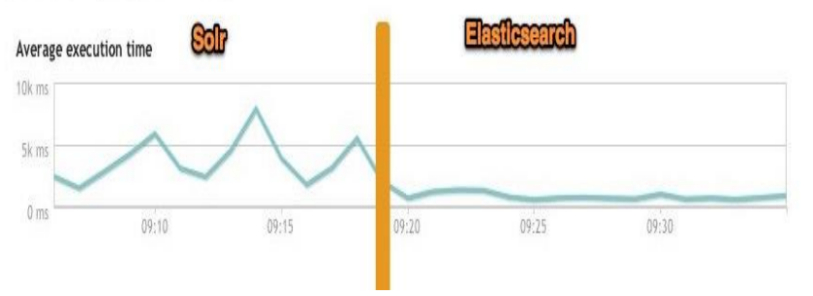
总结:
二者安装都很简单。
1、Solr 利用 Zookeeper 进行分布式管理,而Elasticsearch 自身带有分布式协调管理功能。
2、Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
3、Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
4、Solr 是传统搜索应用的有力解决方案,但 Elasticsearch更适用于新兴的实时搜索应用。
🍼ES的倒排索引
所谓的正排索引,就是搜索引擎会将待搜索的文件都对应一个文件ID,搜索时将这个ID和搜索关键字进行对应,形成K-V对,然后对关键字进行统计计数。
正排索引(传统):
| id | content |
|---|---|
| 1001 | my name is zhang san |
| 1002 | my name is li si |
但是互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
倒排索引
| keyword | id |
|---|---|
| name | 1001, 1002 |
| zhang | 1001 |
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档.
🍼Lucene全文检索框架和分词
全文检索:
- 通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置、以及出现的次数
- 用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内容读取出来了
分词:
如把下面黄色的三条数据添加到索引库里面去,所有会把单词拆开,这个就是分词的操作,然后在去重和排序.当用户输入的信息在排好序的里面查找index,在通过index获取具体的信息

🍼ElasticSearch的基础概念
我们还需对比结构化数据库,看看ES的基础概念,为我们后面学习作铺垫。
Near Realtime(NRT) 近实时。数据提交索引后,立马就可以搜索到。
Cluster 集群,一个集群由一个唯一的名字标识,默认为“elasticsearch”。集群名称非常重要,具有相同集群名的节点才会组成一个集群。集群名称可以在配置文件中指定。
Node 节点:
存储集群的数据,参与集群的索引和搜索功能。像集群有名字,节点也有自己的名称,默认在启动时会以一个随机的UUID的前七个字符作为节点的名字,你可以为其指定任意的名字。通过集群名在网络中发现同伴组成集群。一个节点也可是集群。Index 索引: 一个索引是一个文档的集合(等同于solr中的集合)。每个索引有唯一的名字并且由一个名字来标识==(必须全部是小写字母)==,并且当我们要对这个索引中的文档进行索引、搜索、更新和删除(CRUD)的时候,都要使用到这个名字。在一个集群中,可以
定义任意多的索引。
Elasticsearch 索引的精髓:一切设计都是为了提高搜索的性能。
Field 字段:相当于是数据表的字段,对文档数据根据不同属性进行的分类标识。
Type 类型:指在一个索引中,可以索引不同类型的文档,如用户数据、博客数据。
| 版本 | Type |
|---|---|
| 5.x | 支持多种 type |
| 6.x | 只能有一种 type |
| 7.x | 默认不再支持自定义索引类型(默认类型为: _doc) |
Document 文档:被索引的一条数据,索引的基本信息单元,以
JSON格式来表示。Mapping 映射: 用来定义一个文档,处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分词器、是否被索引等等,这些都是映射里面可以设置的
其它就是处理 ES 里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
Shard 分片:在创建一个索引时可以指定分成多少个分片来存储。每个分片本身也是一个功能完善且独立的“索引”,可以被放置在集群的任意节点上。分片说白了就是单个节点不能存储所有的数据,为了将数据分开存入不同的节点上面才产生出来的,主要是能让我们做一下两个点:
允许水平分割 / 扩展内容容量。
运行在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
Replication 备份/副本: 一个分片可以有多个备份(副本)
- 在分片/节点失败的情况下,提供了高可用性,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上
- 扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行,每个索引可以被分成多个分片。一个索引有0个或者多个副本。 一旦设置了副本,每个索引就有了主分片和副本分片,分片和副本的数量可以在索引创建的时候指定。
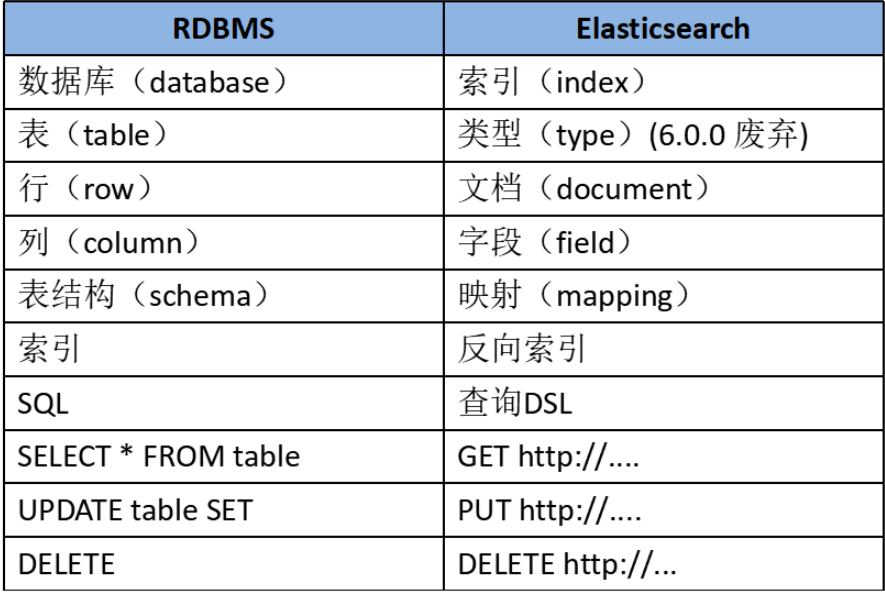
为了方便理解,作一个ES和数据库的对比
参考文章

若有收获,就点个赞吧
0 人点赞
