引入了高速缓存(cache)解决了处理器与内存速度的矛盾,引入了更为复杂的矛盾。 多核处理器拥有自己独立的内存,又同时共享一个主内存。多个缓存同步到主内存的不一致如何处理呢?为了解决这个问题,每个处理器访问内存都准守一下协议,如:MSI、MESI、MOSI、Synapse、Firefly、DragonProtocal等。
JMM模型:
1.定义:
JVM为了屏蔽各个操作系统和硬件的差异而生。并不真实存在,是一套内存访问的规范。由线程、线程的工作内存、主内存(存放变量(实例字段、静态字段、构成数组对象的元素))。线程的工作内存存放该线程使用变量的主内存副本(对象引用的拷贝、或者对象的某个字段)。线程对变量的操作必须在工作内存完成,不能直接读写主内存。不同线程工作线程不能相互访问。线程之间的变量值传递必须在主内存中完成。
JMM规定了内存主要划分为主内存和工作内存两种。此处的主内存和工作内存跟JVM内存划分(堆、栈、方法区)是在不同的层次上进行的,如果非要对应起来,主内存对应的是Java堆中的对象实例部分,工作内存对应的是栈中的部分区域,从更底层的来说,主内存对应的是硬件的物理内存,工作内存对应的是寄存器和高速缓存。
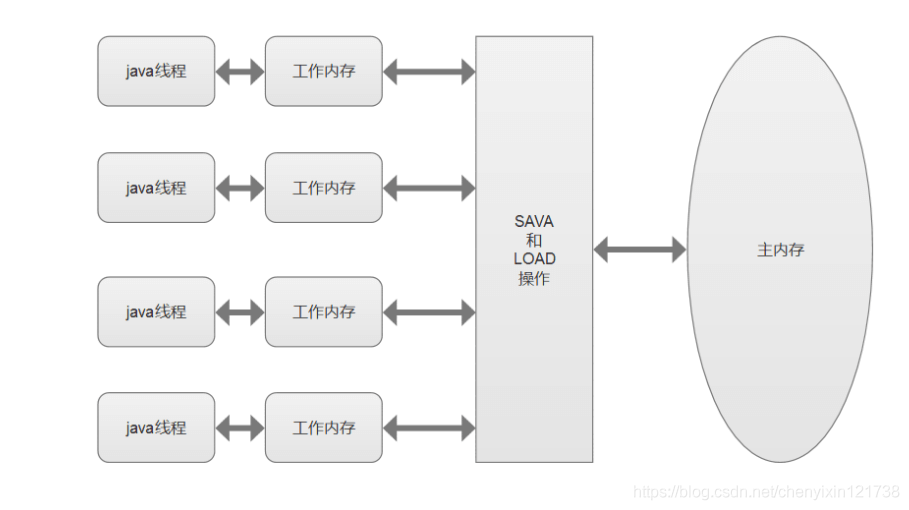
2.主内存与工作内存交互
JVM提供了8种原子操作来完成:
(1)lock:作用于主内存变量,把变量标识为一条线程读占状态
(2)unlock:作用于主内存变量,把一条线程读占状态变量标识释放出来
(3)read:作用于主内存变量,传输到线程的工作内存中,以便随后的load动作使用
(4)load:作用于工作内存,把read的从主内存的内容放入到工作内存的变量副本中
(5)use:作用于工作内存的变量,把一个工作内存的变量传递执行引擎,每当JVM需要使用到的变量的字节码指令时,执行该操作
(6)assign:作用于工作内存变量,把一个执行引擎的变量值赋给工作内存的变量。
(7)store:用于工作内存变量,把工作内存中的变量值传送到主内存中,以便write使用
(8)write:作用于主内存变量,把store操作从工作区的到的变量放入主内存变量中。
把一个主内存的变量复制到工作内存,必须顺序执行read和load操作,把一个工作内存变量同步到主内存,顺序执行store和write,中间可以存入其他指令。
(1)不允许read和load、store和write操作之一单独出现(必须成对出现)。即使用了read必须load,使用了store必须write
(2)不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存。
(3)不允许一个线程无原因的(没有经过assign的)把数据从工作内存同步回主内存
(4)一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是对变量实施use、store操作之前,必须经过assign和load操作
(5)一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁
(6)如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值
(7)如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
(8)对一个变量进行unlock操作之前,必须把此变量同步回主内存
这8个规则严禁也复杂,加上对volatile的特殊处理,可以判断哪些内存访问时安全的,等效于先发生原则。
3.对于volatile变量的特殊规则
volatile对于
参考 :
1.《深入理解java虚拟机-JVM高级特性与最佳实践》第二版-周志明
2.java内存模型JMM理解整理 - 阿姆斯特朗回旋炮 - 博客园

若有收获,就点个赞吧
0 人点赞
