https://cloud.tencent.com/developer/article/1446555
https://cloud.tencent.com/developer/article/1142546
https://blog.csdn.net/lzcaqde/article/details/80868854
1 指令重排序
执行任务的时候,为了提高编译器和处理器的执行性能,编译器和处理器(包括内存系统,内存在行为没有重排但是存储的时候是有变化的)会对指令重排序。编译器优化的重排序是在编译时期完成的,指令重排序和内存重排序是处理器重排序
1 编译器优化的重排序,在不改变单线程语义的情况下重新安排语句的执行顺序
2 指令级并行重排序,处理器的指令级并行技术将多条指令重叠执行,如果不存在数据的依赖性将会改变语句对应机器指令的执行顺序
3 内存系统的重排序,因为使用了读写缓存区,使得看起来并不是顺序执行的。
2 内存屏障
我们知道一个线程是由一个CPU核来处理的,但现代CPU为了继续挖掘并行运算能力,出现了流水线技术,即每个内核有多个电路,调度器将串行指令分解为多步,并将不同指令的各步操作结果叠加,从而实现并行处理,指令的每步都由各自独立的电路来处理,最后汇总处理。这在相当程度上提高了并发能力。那么指令该如何分解?指令的前后执行顺序是否有关系?如何保证结果正确?这又是一个复杂的课题:重排序。
作为CPU来说,为了提高执行效率,允许将一段程序代码分发到各个流水线去执行,但我们的程度代码可能是有前后逻辑关系的,比如int a=10;int b=a2;这里如果将第二行移到第一行前面执行,则产生了错误结果,这里的计算b的代码我们称之为与前面的a存在数据依赖。下面是不同处理器对不同重排序类型的支持程度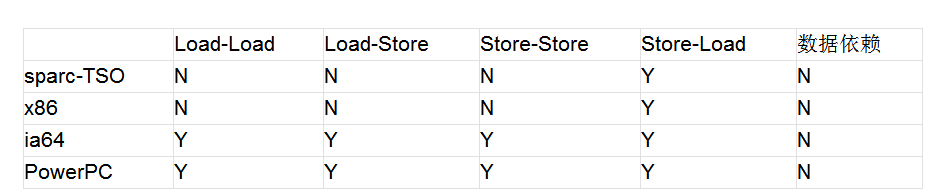
从上面可以看到,各种处理器均不对“数据依赖”类型的语句进行重排序。那这里的一堆Load-Load、Load-Store是什么意思呢?
Load指的是从内存中读取数据的操作,即if(a<1)这样的语句(只读不写);Store指的是向内存中写入数据的操作,即a=10这样的语句(只写不读)。Load-Load指先读后读的操作是否允许重排序;Load-Store指先读后写是否允许重排序;Store-Store指先写后写的两个语句是否允许重排序;Store-Load指先写后读的两个语句是否允许重排序。
从上表可以看到,对于我们常用的Intel和AMD所使用的x86架构,只支持Store-Load重排序,这是因为CPU在写入的时候是首先写入寄存器,包括各级缓存,此时并没有刷新到内存中,如果等待其完成再读则太慢了,所以允许重排序。只要理解了写入是通过缓存批量执行的,那就不难理解。
说了这么多,还是没有提到内存屏障,它究竟是什么?仍然以ia64为例,它是允许Store-Store重排序的,但未必能保证在多线程环境下准确,比如这样的程序
1: static class ThreadA extends Thread{
2: public void run(){
3: a=1;
4: flag=true;
5: }
6: }
7:
8: static class ThreadB extends Thread{
9: public void run(){
10: if(flag){
11: a=a1;
12: }
13: if(a==0){
14: System.out.println(“ha,a==0”);
15: }
16: }
17: }
当ThreadA执行的时候,按照顺序执行的逻辑,当flag=true的时候,a必然等于1;那么ThreadB在if(flag)为真时,会用a=1的值去计算a1,但CPU对Store-Load重排序后,ThreadA中的a=1可能会在flag=true后面执行,如此就造成ThreadB中a=a1没有根据预期的a=1来执行,所以操作系统需要提供一种机制,以禁用重排序,将决定是否重排序的选择权交给应用程序。如果应用程序不允许重排序,则插入相应的内存屏障指令将其禁用。
Java为了能在不同平台下都能正确运行,提出了自己的内存模型,其中就定义了几种内存屏障指令(间接调用的都是底层操作系统的内存屏障指令)
StoreLoad Barriers是一个“全能型”的屏障,它同时具有其他三个屏障的效果。现代的多处理器大都支持该屏障(其他类型的屏障不一定被所有处理器支持)。执行该屏障开销会很昂贵,因为当前处理器通常要把写缓冲区中的数据全部刷新到内存中(buffer fully flush)
3 volatile
1 volatile关键字只能修饰类变量和实例变量。方法参数、局部变量、实例常量以及类常量都是不能用volatile关键字进行修饰的“。
2 volatile变量自身具有下列特性:
- 可见性/一致性: 。
- 指令重排序: 。
3 volatile 提供 happens-before 的保证,确保一个线程的修改能对其他线程是可见的。某些情况下,volatile 还能提供原子性,如读 64 位数据类型,像 long 和 double 都不是原子的(低32位和高32位),但 volatile 类型的 double 和 long 就是原子的.
1.保证此变量对所有的线程的可见性,当一个线程修改了这个变量的值,volatile 保证了新值能立即同步到主内存,其它线程每次使用前立即从主内存刷新但普通变量做不到这点,普通变量的值在线程间传递均需要通过主内存来完成
2.禁止指令重排序。有volatile修饰的变量,赋值后多执行了一个“load addl $0x0, (%esp)”操作,这个操作相当于一个内存屏障(指令重排序时不能把后面的指令重排序到内存屏障之前的位置)这些操作的目的是用线程中的局部变量维护对该域的精确同步。通过对OpenJDK中的unsafe.cpp源码的分析,会发现被volatile关键字修饰的变量会存在一个“lock:”的前缀。
1 这个实际上相当于是一个内存屏障,该内存屏障会为指令的执行提供如下保障:
确保指令重排序时不会将其后面的代码排到内存屏障之前。
同样也会确保重排序是不会将其前面的代码排到内存屏障之后。
确保在执行到内存屏障修饰的指令时前面的代码全部执行完成。
强制将线程的工作内存中值的修改刷新至主内存中。
volatile写-读建立的happens before关系 ,volatile对线程的内存可见性的影响比volatile自身的特性更为重要,也更需要我们去关注。
volatile 的 happens-before 原则其实就是依赖的 StoreLoad 内存屏障
3.重排序
JMM为volatile定制的重排序规则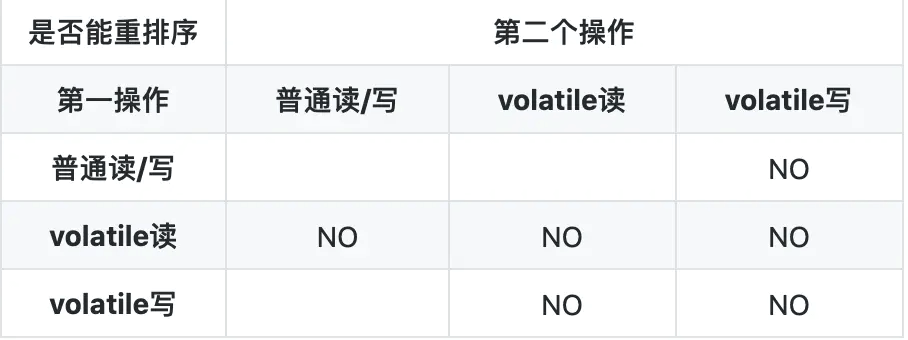
(1)当第一个操作是 volatile读时,不管第二个操作是什么,都不能重排序.确保volatile读之后的操作不会被重排序到 volatile读之前.
(2)当第二个操作是 volatile写时,不管第一个操作是什么,都不能重排序.确保volatile写之前的操作不会被重排序到volatile写之后.
(3)当第一个操作是 volatile写,第二个操作是 volatile读时,不能重排序.
1 volatile写内存屏障
StoreStore屏障 可以保证在volatile写之前,其前面的所有普通写操作已经对任 意处理器可见了。
StoreLoad屏障 将 volatile写操作刷新到内存.由此达到, volatile写 立马刷新到主内存的效果.
2 volatile读内存屏障
LoadLoad屏障 保障后续是读操作时, volatile读装载到内存数据.LoadStore屏障 保障后续是写操作时, volatile读装载到内存数据.
StoreLoad屏障 指令示例:
Store1; StoreLoad; Load2
确保Store1数据对其他处理器变得可见(指刷新到内存)先于Load2及所有后续装载指令的装载。StoreLoad Barriers会使该屏障之前的所有内存访问指令(存储和装载指令)完成之后,才执行该屏障之后的内存访问指令。StoreLoad Barriers是一个“全能型”的屏障,它同时具有其他3个屏障的效果(LoadLoad Barriers、StoreStore Barriers、LoadStore Barriers)
按转载者的理解,作者想表达的是 Store1是存储数据到内存的操作; StoreLoad 是’StoreLoad‘屏障;Load2 是读取内存的数据的操作.然后 StoreLoad是为了确保Store1存储数据到内存的操作,能够先于Load2及所有屏障后面装载指令的操作。StoreLoad 屏障会使该屏障之前的所有内存访问指令(存储和装载指令)完成后才能执行该屏障之后的内存访问指令。StoreLoad 屏障是一种“全能型”的屏障,它同时具有其他3个屏障的效果[LoadLoad 屏障、StoreStore 屏障、LoadStore 屏障]
4 cpu实现
lock前缀与cas相同

若有收获,就点个赞吧
0 人点赞
