- 1. Iterator与Enumerator区别
- 2. Iterator与ListIterator
- 3. ArrayList与Vector
- 4.集合继承关系
- 5. Collection
- 6. Comparator与Comparable
- 7. CopyOnWriteArrayList
- 8.AbstractSequentialList
- 9. Queue
- 10. Dueue
- 11. LinkedList
- 12 NavigableSet
- 13 Map
- 14.HashMap
- 15.LinkedHashMap
- 16 TreeMap
- 17 WeakHashMap
- 18 ConcurrentHashMap
- 19 BlockigQueque
- 20 ArrayBlockingQueue
- 21 LinkedBlockingQueue
- 22 ArrayBlockingQueue与LinkedBlockingQueue单/双锁实现,性能对比
- 23 SynchronousQueue 同步队列
- 22 ConcurrentLinkedQueue
- 23 isEmpty()与size
- 24 PriorityQueue
- 25 有界队列与无界队列
1. Iterator与Enumerator区别
- enumerator缺少remove方法
- 迭代顺序不同,iterator从前到后
- iterator支持fast-failed机制,enumerator不支持
- enumerator迭代速度更快递
enumerator用于Vector、HashTable、java.io.SequenceInputStream
2. Iterator与ListIterator
都支持fast-failed机制
- ListIterator实现了Iterator接口,属性有cursor(下一个要遍历的元素索引),lastRest(上一个遍历元素的索引),方法有,hasNext(),next(),remove(),forEachRemainint()(遍历剩下的元素
ListIterator构造函数可以穿一个整型参数,表示从指定位置开始遍历;并且在Iterator(Itr)的基础上增加了方法hasPrevious(),nextIndex(),previousIndex(),previous() ,set(E e),add(E e);对应的功能是:返回是否有遍历过元素,返回下一个要遍历元素的索引,返回上一个遍历元素的索引,返回上一个遍历的元素,修改当前遍历元素的值,在当前遍历的元素后面加入一个元素
3. ArrayList与Vector
Vector与ArrayList一样,继承与List,也是通过数组实现的,不同的是它支持线程的同步
- Vector扩容是100%,ArrayList是50%
迭代器AarryList用的是ListIterator,Vector用的是Enumerator
4.集合继承关系
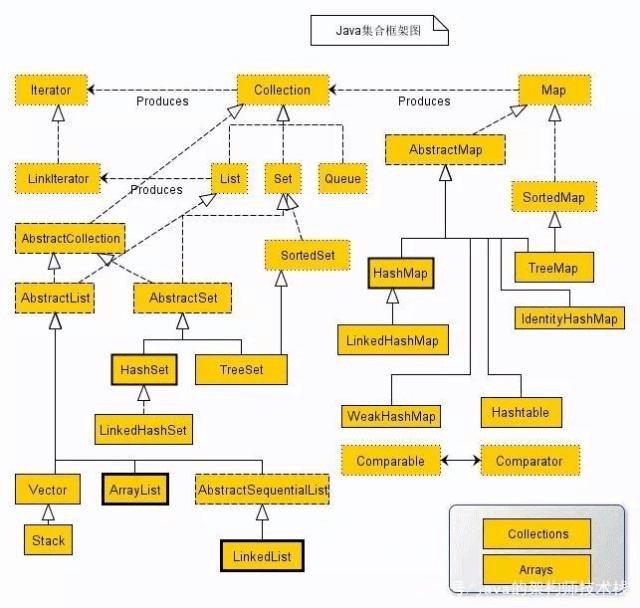
Collection
|_List 有序,可重复
|AbstractArrayList
|ArrayList 底层数据结构是数组,增删慢,查询快;线程不安全,效率高
| AbstractSequentialList
| LinkedList 底层数据结构是链表,增删快,查询慢;线程不安全,效率高
|Vector 底层数据结构是数组,增删慢,查询快;线程安全,效率低
|Stack
|CopyOnWriteArrayList CopyOnWrite思想的list,有价值的
|Set 无序,不可重复
| SortedSet
|NavigableSet
|TreeSet
|ConcurrentSkipListSet
| AbstractSet
|EnumSet
|HashSet
|LinkedHashSet
|TreeSet
|CopyOnWriteArraySet
|_ConcurrentSkipListSet
|Qeue
|Deque
|BlockingDeque
|LinkedBlockingDeque
|LinkedList
|ArrayDeque
|ConcurrentLinkedDeque
|BlockingQueue
|TransferQueue
|ArrayBlockingQue 常用
|DelayedWorkQueue
|BlockingDeque
|SynchronousQueue 常用
|DelayQueue
|LinkedBlockingQueue 常用
|PriorityBlockingQueue
|AbstractQueue
|ArrayBlockingQueue
|LinkedTransferQueue
|SynchronousQueue
|PriorityQueue
|LinkedBlockingDeque
|DelayQueue
|LinkedBlockingQueue
|ConcurrentLinkedQueue
|PriorityBlockingQueue
|AbstractCollection
Map
|SortedMap
|NavigableMap
|TreeMap
|ConcurrentSkipListMap
|ConcurrentMap
|ConcurrentHashMap
|AbstractMap
|EnumMap
|Hashtable
|Properties
|IdentityHashMap
|HashMap
|LinkedHashMap
|TreeMap
|WeakHashMap
|ConcurrentHashMap
|___ConcurrentSkipListMap5. Collection
继承与Iteral接口,接口仅包含iteraator spliterator forEach
-
6. Comparator与Comparable
在《Effective Java》一书中,作者Joshua Bloch推荐大家在编写自定义类的时候尽可能的考虑实现一下Comparable接口,一旦实现了Comparable接口,它就可以跟许多泛型算法以及依赖于改接口的集合实现进行协作。你付出很小的努力就可以获得非常强大的功能。事实上,Java平台类库中的所有值类都实现了Comparable接口。如果你正在编写一个值类,它具有非常明显的内在排序关系,比如按字母顺序、按数值顺序或者按年代顺序,那你就应该坚决考虑实现这个接口。 compareTo方法不但允许进行简单的等同性进行比较,而且语序执行顺序比较,除此之外,它与Object的equals方法具有相似的特征,它还是一个泛型。类实现了Comparable接口,就表明它的实例具有内在的排序关系,为实现Comparable接口的对象数组进行排序就这么简单: Arrays.sort(a);是排序接口;若一个类实现了 Comparable 接口,就意味着 “该类支持排序”。而 Comparator 是比较器;我们若需要控制某个类的次序,可以建立一个 “该类的比较器” 来进行排序。 前者应该比较固定,和一个具体类相绑定,而后者比较灵活,它可以被用于各个需要比较功能的类使用。可以说前者属于 “静态绑定”,而后者可以 “动态绑定”。 我们不难发现:Comparable 相当于 “内部比较器”,而 Comparator 相当于 “外部比较器”
7. CopyOnWriteArrayList
内部组合了ReentrakLock和另一个数组Object[] array;读不加锁;写入加锁,拷贝一份给array。
注意两件事情: 减少扩容开销。根据实际需要,初始化CopyOnWriteMap的大小,避免写时CopyOnWriteMap扩容的开销。
- 使用批量添加。因为每次添加,容器每次都会进行复制,所以减少添加次数,可以减少容器的复制次数。如使用上面代码里的addBlackList方法。
CopyOnWrite的缺点:
CopyOnWrite容器有很多优点,但是同时也存在两个问题,即内存占用问题和数据一致性问题。所以在开发的时候需要注意一下。
内存占用问题。因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比如说200M左右,那么再写入100M数据进去,内存就会占用300M,那么这个时候很有可能造成频繁的Yong GC和Full GC。之前我们系统中使用了一个服务由于每晚使用CopyOnWrite机制更新大对象,造成了每晚15秒的Full GC,应用响应时间也随之变长。
针对内存占用问题,可以通过压缩容器中的元素的方法来减少大对象的内存消耗,比如,如果元素全是10进制的数字,可以考虑把它压缩成36进制或64进制。或者不使用CopyOnWrite容器,而使用其他的并发容器,如ConcurrentHashMap。
数据一致性问题。CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
8.AbstractSequentialList
实现序列访问的数据储存结构的提供了所需要的最小化的接口实现 。 重写了AbstractList中的iterator和listIterator方法,AbstractList中的这个方法便用于ArrayList这种底层顺序表实现的列表
9. Queue
- offer,add 区别:
一些队列有大小限制,因此如果想在一个满的队列中加入一个新项,多出的项就会被拒绝。
这时新的 offer 方法就可以起作用了。它不是对调用 add() 方法抛出一个 unchecked 异常,而只是得到由 offer() 返回的 false。
- poll,remove 区别:
remove() 和 poll() 方法都是从队列中删除第一个元素。remove() 的行为与 Collection 接口的版本相似, 但是新的 poll() 方法在用空集合调用时不是抛出异常,只是返回 null。因此新的方法更适合容易出现异常条件的情况。
- peek,element区别:
element() 和 peek() 用于在队列的头部查询元素。与 remove() 方法类似,在队列为空时, element() 抛出一个异常,而 peek() 返回 null。
10. Dueue
| First Element (Head) | Last Element (Tail) | |||
|---|---|---|---|---|
| Throws exception | Special value | Throws exception | Special value | |
| Insert | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| Remove | removeFirst() | pollFirst() | removeLast() | pollLast() |
| Examine | getFirst() | peekFirst() | getLast() | peekLast() |
对比于queue
| Queue Method | Equivalent Deque Method |
|---|---|
| add(e) | addLast(e) |
| offer(e) | offerLast(e) |
| remove() | removeFirst() |
| poll() | pollFirst() |
| element() | getFirst() |
| peek() | peekFirst() |
对比于stack
| Stack Method | Equivalent Deque Method |
|---|---|
| push(e) | addFirst(e) |
| pop() | removeFirst() |
| peek() | peekFirst() |
/* Returns an iterator over the elements in this deque in reverse sequential order. The elements will be returned in order from last (tail) to first (head). @return an iterator over the elements in this deque in reverse sequence /
Iterator
11. LinkedList
// get
Node
// assert isElementIndex(index);
if (index < (size >> 1)) {<br /> Node<E> x = first;<br /> for (int i = 0; i < index; i++)<br /> x = x.next;<br /> return x;<br /> } else {<br /> Node<E> x = last;<br /> for (int i = size - 1; i > index; i--)<br /> x = x.prev;<br /> return x;<br /> }<br /> }
12 NavigableSet
NavigableSet扩展了 SortedSet,具有了为给定搜索目标报告最接近匹配项的导航方法。方法 lower、floor、ceiling 和 higher 分别返回小于、小于等于、大于等于、大于给定元素的元素,如果不存在这样的元素,则返回 null。
headSet 、tailSet .返回传入元素 小于、大于的视图
13 Map
Map接口提供三个集合视图 Set keySet() Collection values() Set entrySet()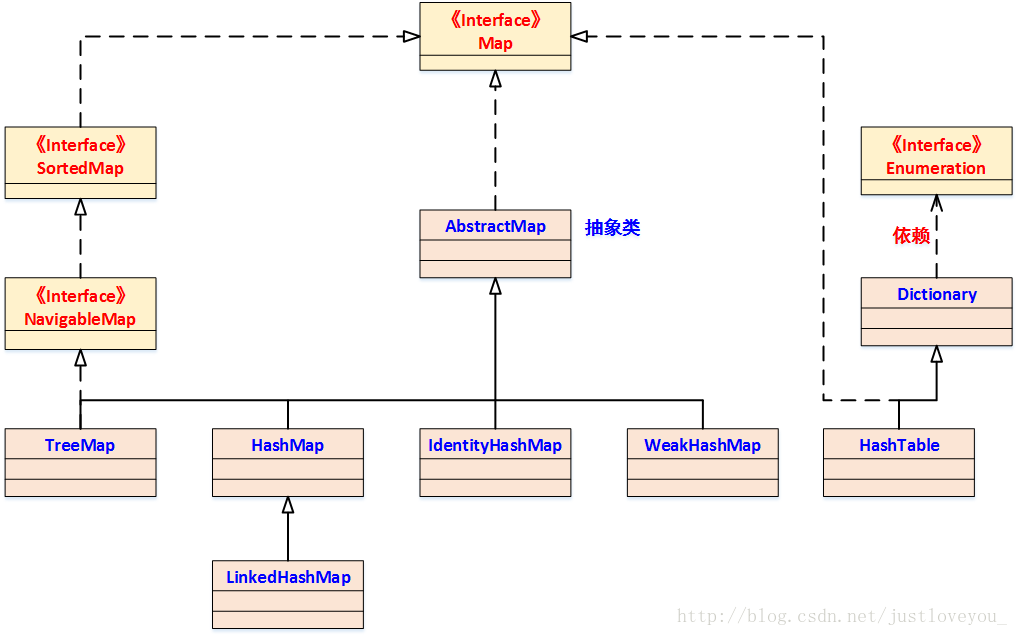
14.HashMap
15.LinkedHashMap
https://www.cnblogs.com/pypua/p/9973794.html jdk1,7
https://segmentfault.com/a/1190000012964859 jdk1,8
HashMap和双向链表合二为一即是LinkedHashMap。所谓LinkedHashMap,其落脚点在HashMap,因此更准确地说,它是一个将所有Entry节点链入一个双向链表的HashMap。由于LinkedHashMap是HashMap的子类,所以LinkedHashMap自然会拥有HashMap的所有特性。比如,LinkedHashMap的元素存取过程基本与HashMap基本类似,只是在细节实现上稍有不同。当然,这是由LinkedHashMap本身的特性所决定的,因为它额外维护了一个双向链表用于保持迭代顺序。此外,LinkedHashMap可以很好的支持LRU算法。
HashMap是无序的,也就是说,迭代HashMap所得到的元素顺序并不是它们最初放置到HashMap的顺序。HashMap的这一缺点往往会造成诸多不便,因为在有些场景中,我们确需要用到一个可以保持插入顺序的Map。庆幸的是,JDK为我们解决了这个问题,它为HashMap提供了一个子类 —— LinkedHashMap。虽然LinkedHashMap增加了时间和空间上的开销,但是它通过维护一个额外的双向链表保证了迭代顺序。特别地,该迭代顺序可以是插入顺序,也可以是访问顺序。因此,根据链表中元素的顺序可以将LinkedHashMap分为:保持插入顺序的LinkedHashMap 和 保持访问顺序的LinkedHashMap,其中LinkedHashMap的默认实现是按插入顺序排序的。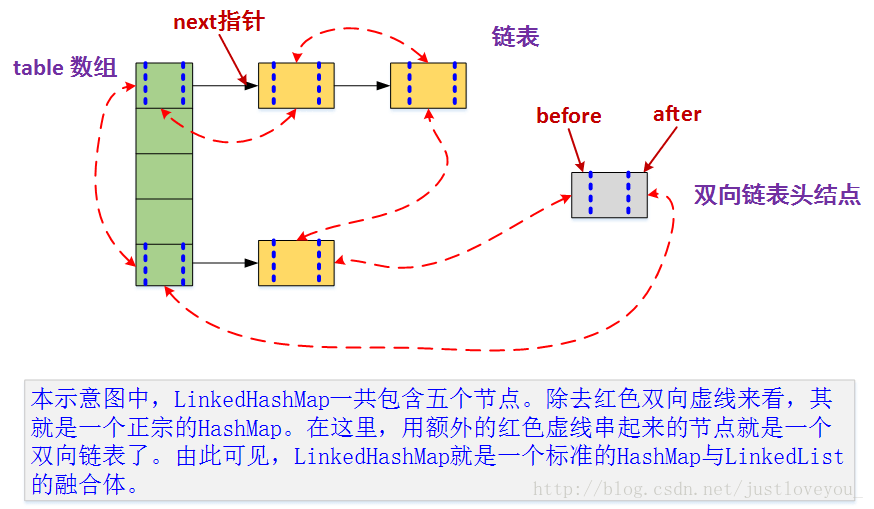
private final boolean accessOrder; //true表示按照访问顺序迭代,false时表示按照插入顺序
LinkedHashMap采用的hash算法和HashMap相同,但是它重新定义了Entry。LinkedHashMap中的Entry增加了两个指针 before 和 after,它们分别用于维护双向链接列表。特别需要注意的是,next用于维护HashMap各个桶中Entry的连接顺序,before、after用于维护Entry插入的先后顺序的,源代码如下
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor); // 调用HashMap对应的构造函数
accessOrder = false; // 迭代顺序的默认值
}
- 链表的建立过程:在插入键值对节点时开始的,初始情况下,让 LinkedHashMap 的 head 和 tail 引用同时指向新节点,链表就算建立起来了。随后不断有新节点插入,通过将新节点接在 tail 引用指向节点的后面,即可实现链表的更新。Map 类型的集合类是通过 put(K,V) 方法插入键值对,LinkedHashMap 本身并没有覆写父类的 put 方法,而是直接使用了父类的实现。但在 HashMap 中,put 方法插入的是 HashMap 内部类 Node 类型的节点,该类型的节点并不具备与 LinkedHashMap 内部类 Entry 及其子类型节点组成链表的能力。那么,LinkedHashMap 是怎样建立链表的呢?// HashMap 中实现
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// HashMap 中实现
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node
if ((tab = table) == null || (n = tab.length) == 0) {…}
// 通过节点 hash 定位节点所在的桶位置,并检测桶中是否包含节点引用
if ((p = tab[i = (n - 1) & hash]) == null) {…}
else {
Node
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode) {…}
else {
// 遍历链表,并统计链表长度
for (int binCount = 0; ; ++binCount) {
// 未在单链表中找到要插入的节点,将新节点接在单链表的后面
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) {…}
break;
}
// 插入的节点已经存在于单链表中
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) {…}
afterNodeAccess(e); // 回调方法,后续说明
return oldValue;
}
}
++modCount;
if (++size > threshold) {…}
afterNodeInsertion(evict); // 回调方法,后续说明
return null;
}
// HashMap 中实现
Node
return new Node<>(hash, key, value, next);
}
// LinkedHashMap 中覆写
Node
LinkedHashMap.Entry
new LinkedHashMap.Entry
// 将 Entry 接在双向链表的尾部
linkNodeLast(p);
return p;
}
// LinkedHashMap 中实现
private void linkNodeLast(LinkedHashMap.Entry
LinkedHashMap.Entry
tail = p;
// last 为 null,表明链表还未建立
if (last == null)
head = p;
else {
// 将新节点 p 接在链表尾部
p.before = last;
last.after = p;
}
}
2 链表节点的删除过程:
所以,在删除及节点后,回调方法 afterNodeRemoval 会被调用。LinkedHashMap 覆写该方法,并在该方法中完成了移除被删除节点的操作
// HashMap 中实现
public V remove(Object key) {
Node
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
// HashMap 中实现
final Node
boolean matchValue, boolean movable) {
Node
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode) {…}
else {
// 遍历单链表,寻找要删除的节点,并赋值给 node 变量
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode) {…}
// 将要删除的节点从单链表中移除
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
—size;
afterNodeRemoval(node); // 调用删除回调方法进行后续操作
return node;
}
}
return null;
}
// LinkedHashMap 中覆写
void afterNodeRemoval(Node
LinkedHashMap.Entry
(LinkedHashMap.Entry
// 将 p 节点的前驱后后继引用置空
p.before = p.after = null;
// b 为 null,表明 p 是头节点
if (b == null)
head = a;
else
b.after = a;
// a 为 null,表明 p 是尾节点
if (a == null)
tail = b;
else
a.before = b;
}
删除的过程并不复杂,上面这么多代码其实就做了三件事:
- 根据 hash 定位到桶位置
- 遍历链表或调用红黑树相关的删除方法
- 从 LinkedHashMap 维护的双链表中移除要删除的节点
举个例子说明一下,假如我们要删除下图键值为 3 的节点。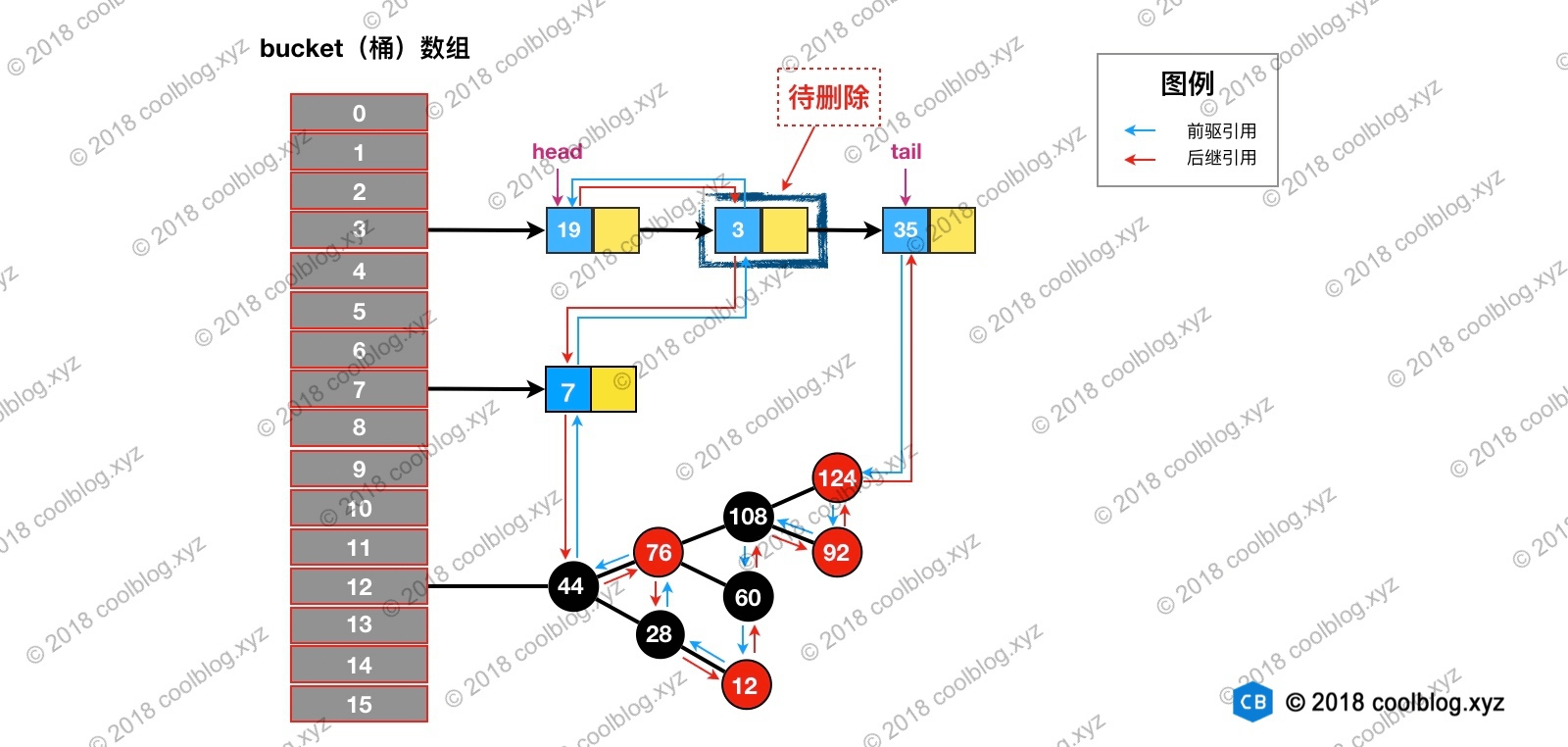
根据 hash 定位到该节点属于3号桶,然后在对3号桶保存的单链表进行遍历。找到要删除的节点后,先从单链表中移除该节点。如下: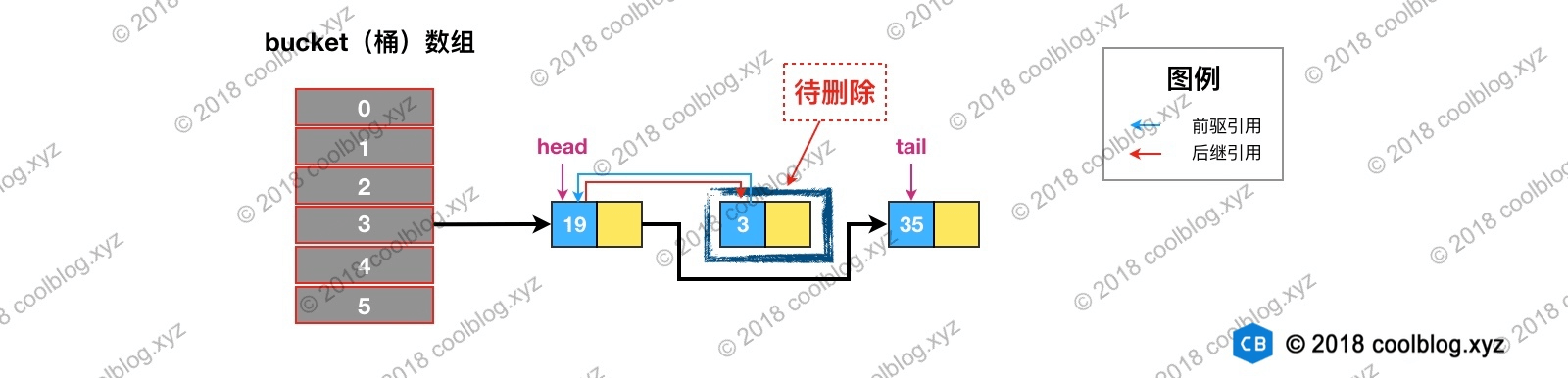
然后再双向链表中移除该节点: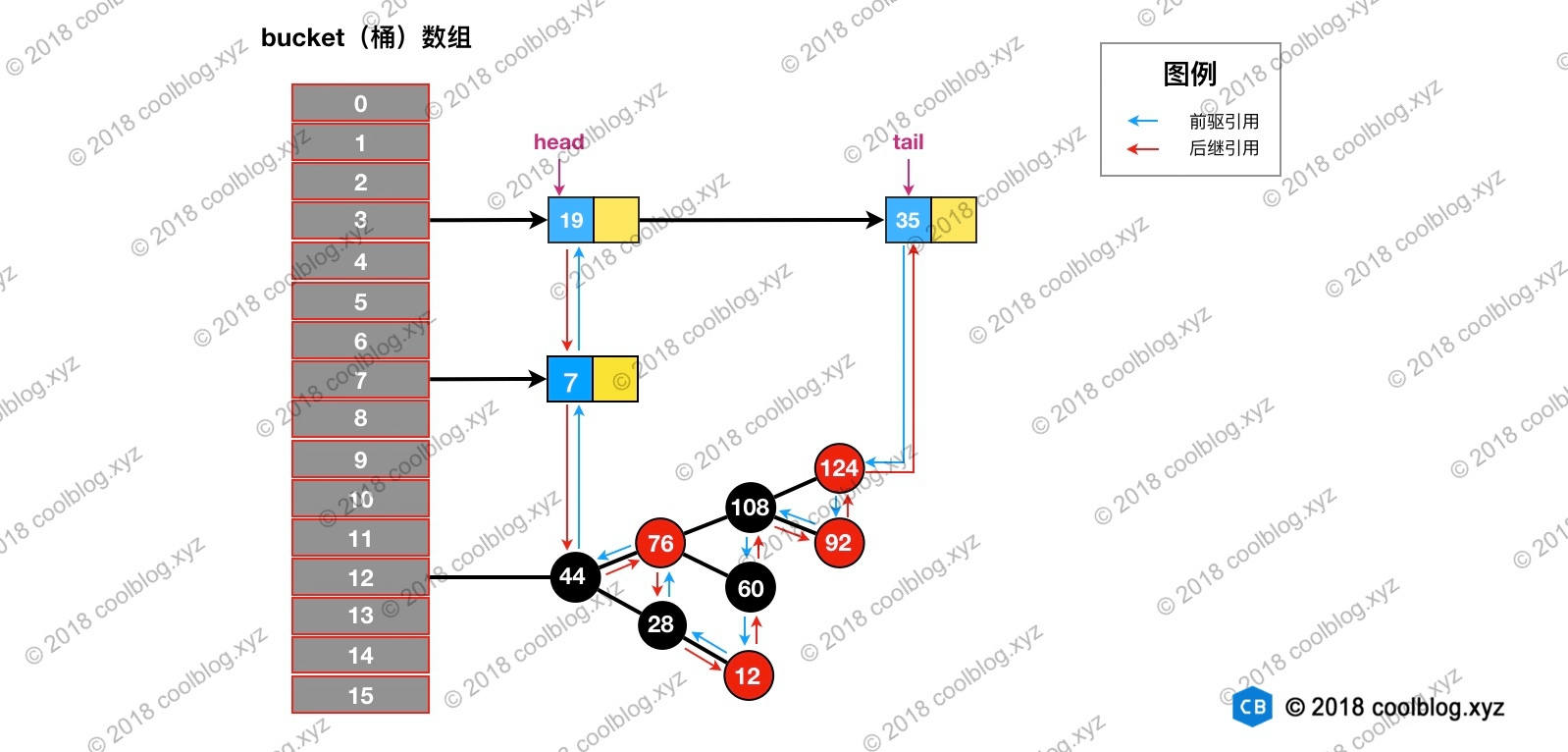
删除及相关修复过程并不复杂,结合上面的图片,大家应该很容易就能理解,这里就不多说了。
3 访问顺序的维护过程
LinkedHashMap 是按插入顺序维护链表。不过我们可以在初始化 LinkedHashMap,指定 accessOrder 参数为 true,即可让它按访问顺序维护链表。访问顺序的原理上并不复杂,当我们调用get/getOrDefault/replace等方法时,只需要将这些方法访问的节点移动到链表的尾部即可。
访问的节点移至链表尾部,淘汰时,淘汰头
// LinkedHashMap 中覆写
public V get(Object key) {
Node
if ((e = getNode(hash(key), key)) == null)
return null;
// 如果 accessOrder 为 true,则调用 afterNodeAccess 将被访问节点移动到链表最后
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
// LinkedHashMap 中覆写
void afterNodeAccess(Node
LinkedHashMap.Entry
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry
(LinkedHashMap.Entry
p.after = null;
// 如果 b 为 null,表明 p 为头节点
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
/
这里存疑,父条件分支已经确保节点 e 不会是尾节点,
那么 e.after 必然不会为 null,不知道 else 分支有什么作用
/
else
last = b;
if (last == null)
head = p;
else {
// 将 p 接在链表的最后
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
假设我们访问下图键值为3的节点,访问前结构为: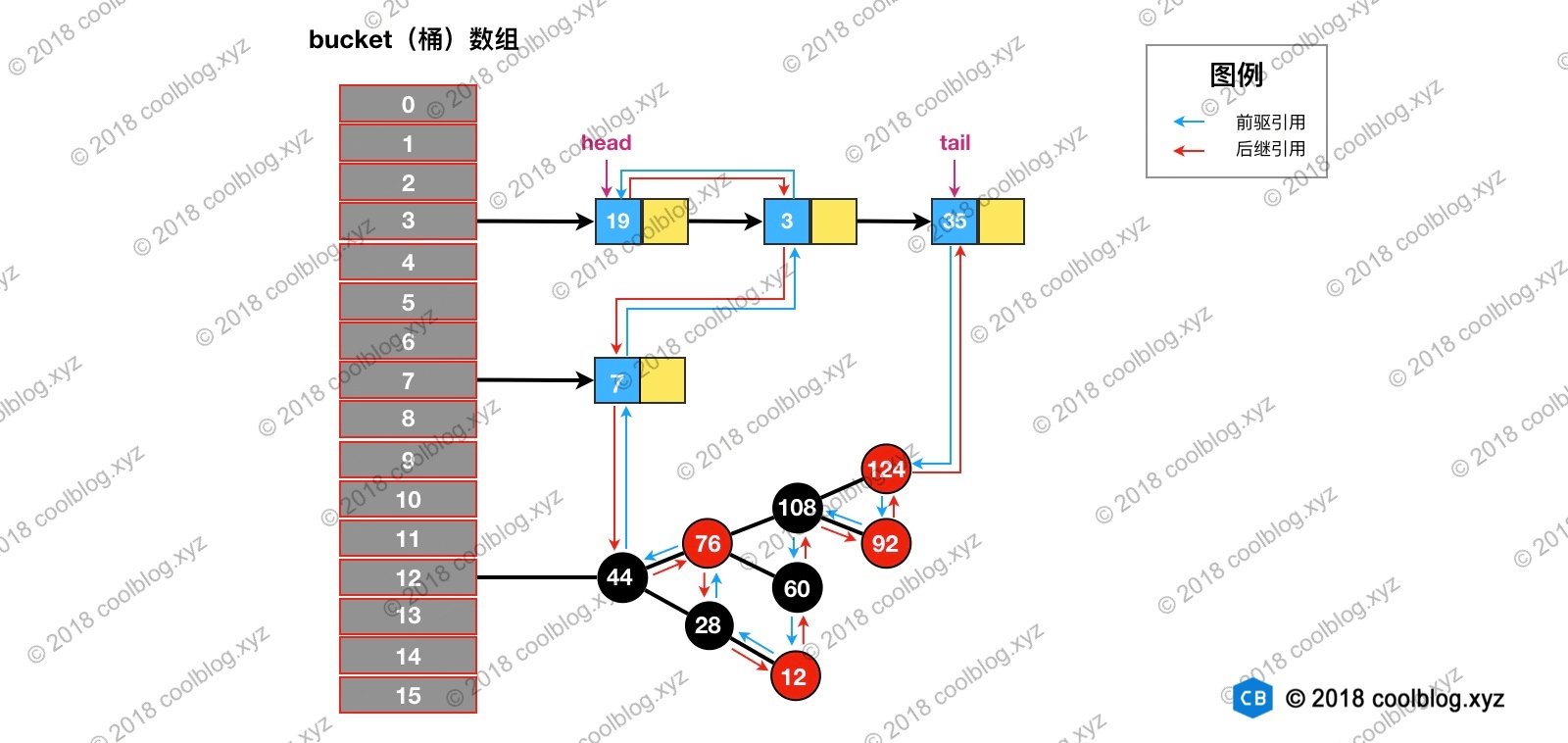
访问后,键值为3的节点将会被移动到双向链表的最后位置,其前驱和后继也会跟着更新。访问后的结构如下: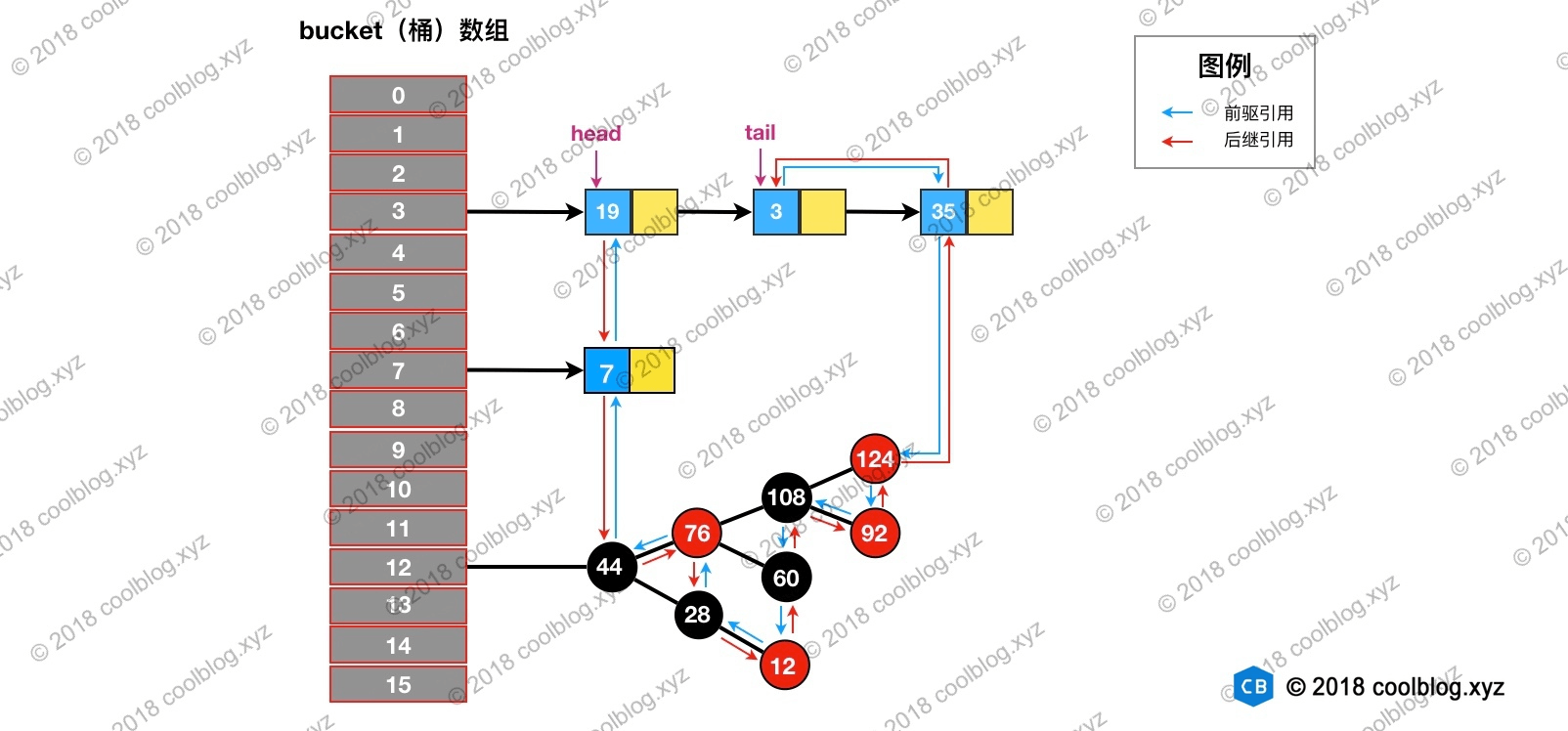
4 基于 LinkedHashMap 实现缓存
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry
// 根据条件判断是否移除最近最少被访问的节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
// 移除最近最少被访问条件之一,通过覆盖此方法可实现不同策略的缓存
protected boolean removeEldestEntry(Map.Entry
return false;
}
测试代码如下:
public class SimpleCacheTest { @Test public void test() throws Exception { SimpleCache
测试结果如下: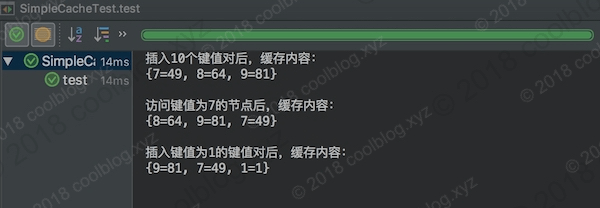
在测试代码中,设定缓存大小为3。在向缓存中插入10个键值对后,只有最后3个被保存下来了,其他的都被移除了。然后通过访问键值为7的节点,使得该节点被移到双向链表的最后位置。当我们再次插入一个键值对时,键值为7的节点就不会被移除。
16 TreeMap
红黑树:http://www.tianxiaobo.com/2018/01/11/%E7%BA%A2%E9%BB%91%E6%A0%91%E8%AF%A6%E7%BB%86%E5%88%86%E6%9E%90/
TreeMap:
http://www.tianxiaobo.com/2018/01/11/TreeMap%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/
- 查找
TreeMap基于红黑树实现,而红黑树是一种自平衡二叉查找树,所以 TreeMap 的查找操作流程和二叉查找树一致。二叉树的查找流程是这样的,先将目标值和根节点的值进行比较,如果目标值小于根节点的值,则再和根节点的左孩子进行比较。如果目标值大于根节点的值,则继续和根节点的右孩子比较。在查找过程中,如果目标值和二叉树中的某个节点值相等,则返回 true,否则返回 false。TreeMap 查找和此类似,只不过在 TreeMap 中,节点(Entry)存储的是键值对。在查找过程中,比较的是键的大小,返回的是值,如果没找到,则返回null。TreeMap 中的查找方法是get,具体实现在getEntry方法中,相关源码如下:
public V get(Object key) { Entry
17 WeakHashMap
WeakHashMap 继承于AbstractMap,使用ReferenceQueue是一个队列,它会保存被GC回收的“弱键“,既然有WeakHashMap,那么有WeakHashSet吗? java collections包是没有直接提供WeakHashSet的。我们可以通过Collections.newSetFromMap(Map map)方法可以将任何 Map包装成一个Set。看一下node的定义:
/ The entries in this hash table extend WeakReference, using its main ref field as the key. */ private static class Entry

若有收获,就点个赞吧
0 人点赞
