Redis数据结构(Redis都是k-v模式,这里说的数据结构主要是value的结构)
笔记来源:https://www.cnblogs.com/hunternet/p/12671125.html
https://tech.meituan.com/2018/07/27/redis-rehash-practice-optimization.html
https://github.com/redis/redis/blob/unstable/src/dict.c
Redis五大对象和数据结构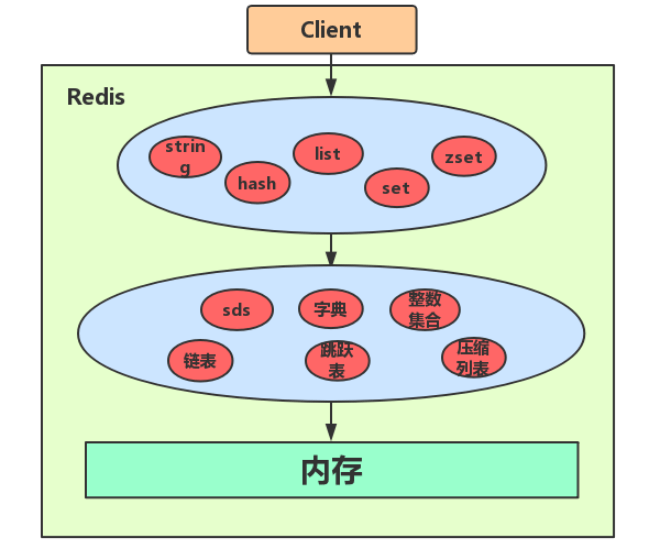
1.String
String是二进制安全的,一个string可以包含字符串,图像,图片或者序列化之后的对象。
命令:get,set,del
场景:1.缓存层,常用的字符串,图像视频等都能放,相对于mysql的持久层读写压力更小。
2.计数器:redis是单线程模型,一个命令执行完才会执行下一个
3.用于用户登录的session或者token存储共享。
c语言使用n+1长度的数组来保存长度为n的字符串,求长度需要遍历整个字符串
java中String类使用char[],后来改成byte[] ,求string的长度是求这个数组的长度,而数组的长度是存储在Java堆中一个对象数据区中的对象头中的。
Redis自己对字符串做了实现,叫做简单动态字符串(simple dynamic string,SDS).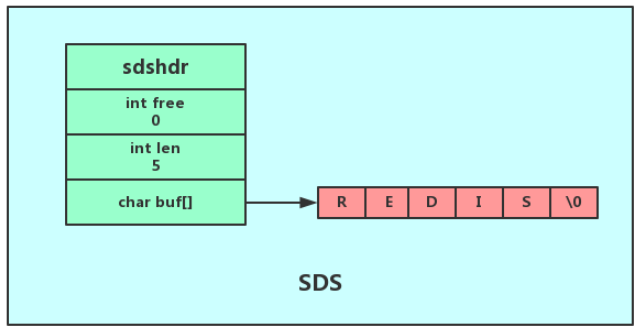
SDS除了包含string内容信息,还包含了string长度信息,以及代表剩余空间的free指针。
SDS主要保障两个方面
(1)缓冲区溢出:修改string时可能新string的长度很长溢出缓冲区,free指针说明还有多少空余位置
(2)空间预分配:
当修改后len小于1M,free和len值相同,即string长度为10,那么free=10,缓冲区长度为21。
当修改后空间大于1M,free为为1M,如果string大小30M,那么free1M,缓冲区大小30M+1M+1byte
(3)惰性释放:当改成更短的string,不会立即回收,而是使用free记录备用
2.List 列表
List元素是有序且可以重复的
Redis以前使用链表(linkedlist)或者压缩列表(ziplist)作为列表的内部编码,3.2版本之后使用quicklist 。
(1)链表
Redis使用双向无环链表,拥有头指针和尾指针,带链表长度计数器
结构:包含节点本身值的指针和前后指针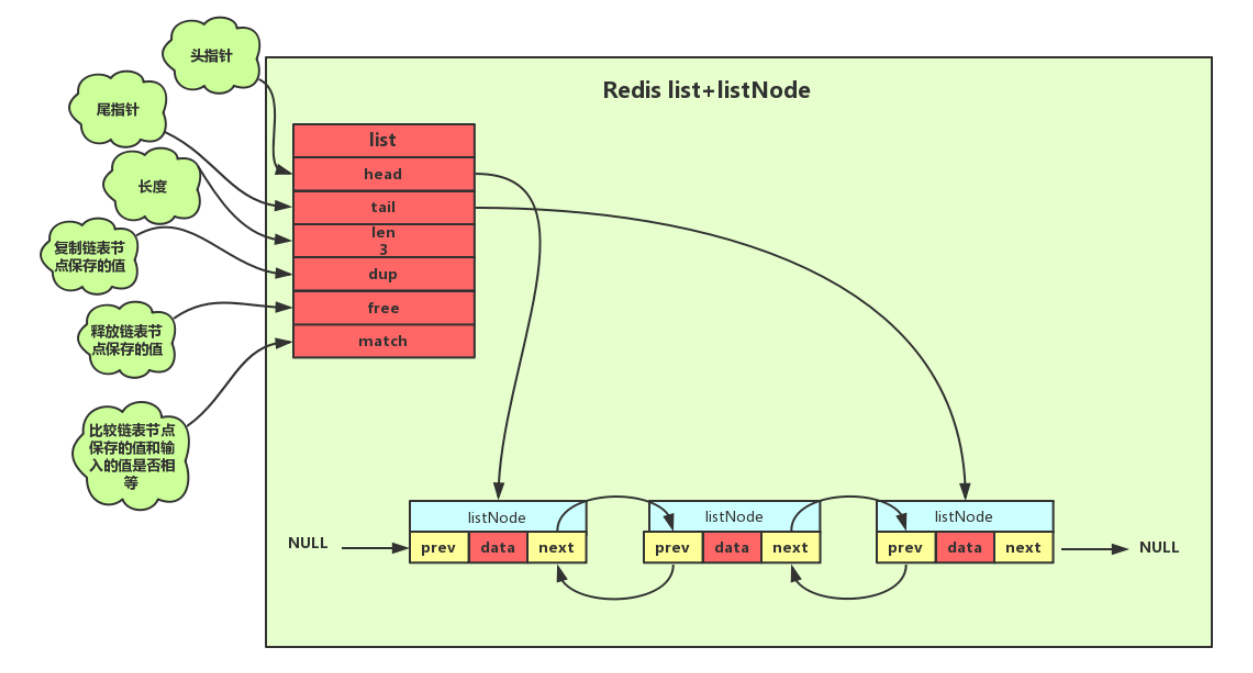
应用:
发布订阅模式,慢查询,监视器功能。慢查询即把查询时间超过一定阈值(默认10000us=10ms)的查询记录存储在一个list中。
命令:rpush(右添加),lpush(左添加),rpop(右移出),lpop(左移出),len(长度),lrem(删除指定元素),lset(设置指定元素)
(2)压缩列表
将所有元素存储在物理连续的位置上,并使用一个长度标记每个节点的长度。
ziplist可以作为list,hash或者zset的底层存储结构
节点可以存储字节数组或者整数。
整个压缩列表的结构:
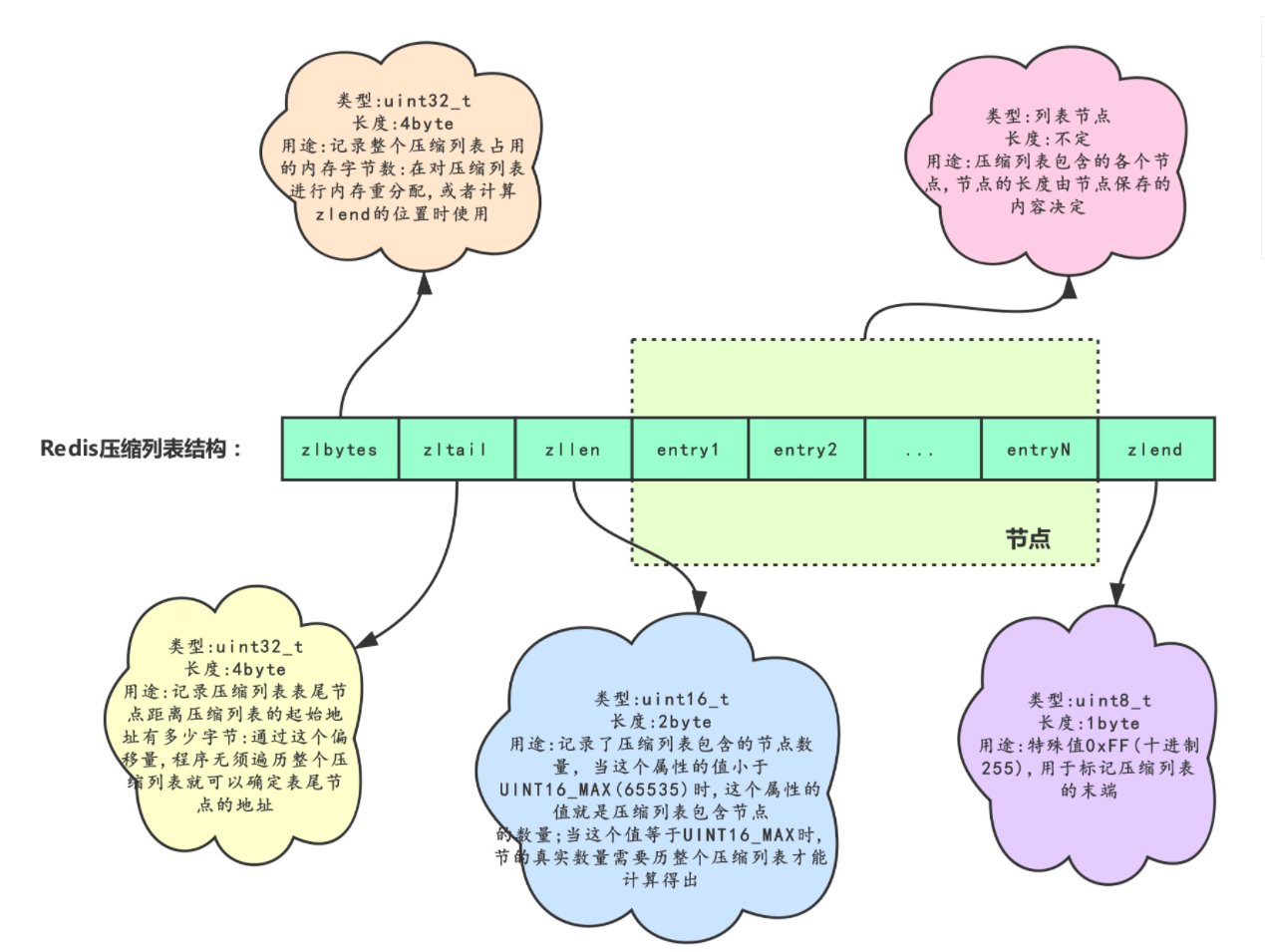
节点的结构: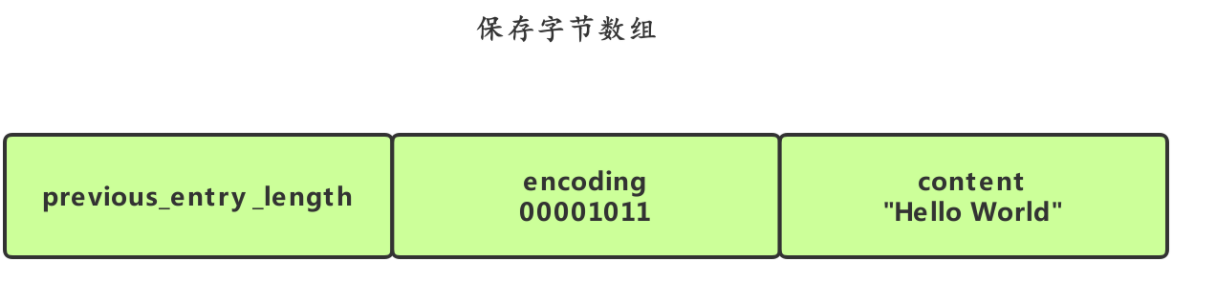
previous_entry_length属性以字节为单位,记录了压缩列表中前一个节点的长度,encoding表示内容是整数还是字节数组。
(3)quicklist
ziplist当元素太多时候要求分配很大的连续空间,因此此时会转化成双向链表,但是双向链表会因为每个节点的前后指针造成空间浪费。
quicklist其实是以上两者的一个折中,本质上是一个节点为ziplist的双向linkedlist,结构如下: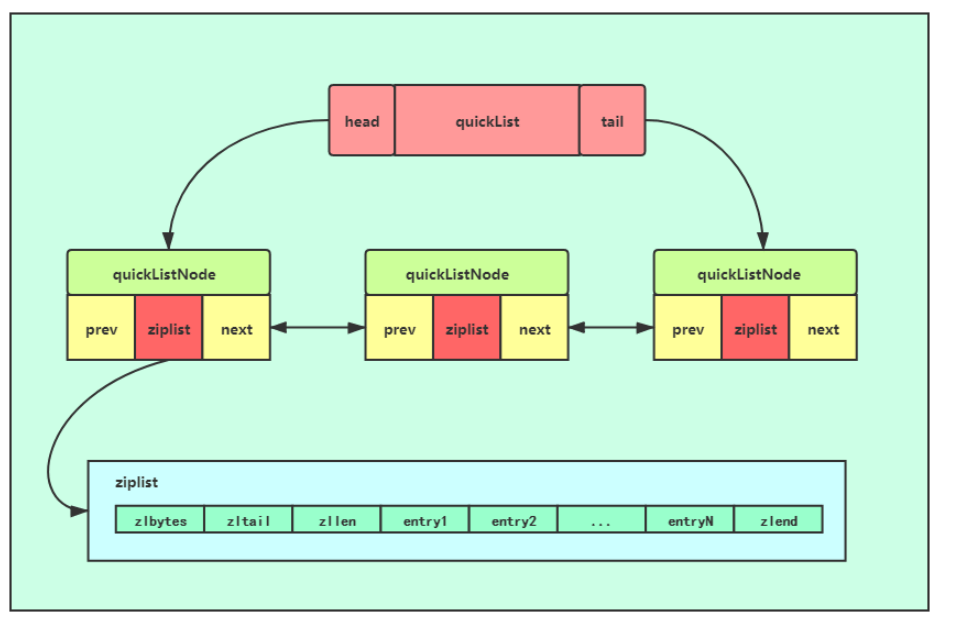
3.Hash(也被称为字典)
Redis存储数据本身是根据key存储value,Hash是指值本身又是一个键值对(Hash/字典)结构
value=[{field1,value1},…{fieldN,valueN}]
和string对象的区别如下: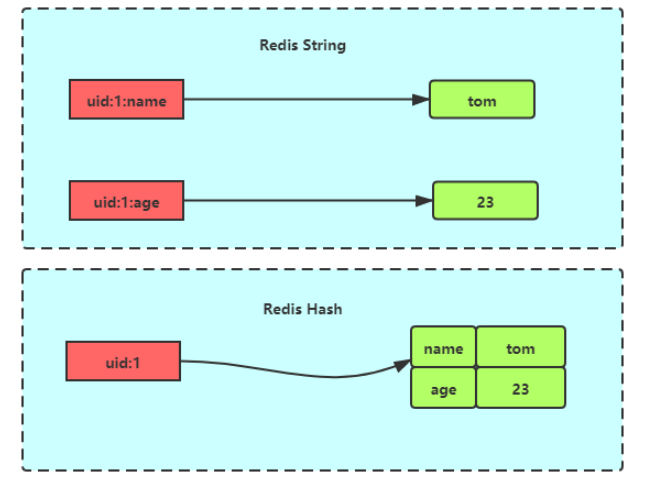
Hash底层实现包括ziplist和hashtable
(1)压缩列表
(2)hashtable
散列表:使用散列函数将key映射到指定位置
负载因子:底层数组填充的元素个数/数组长度,像hashmap中一个数组中有一颗红黑树,那么也只算填充一个。
字典结构如下: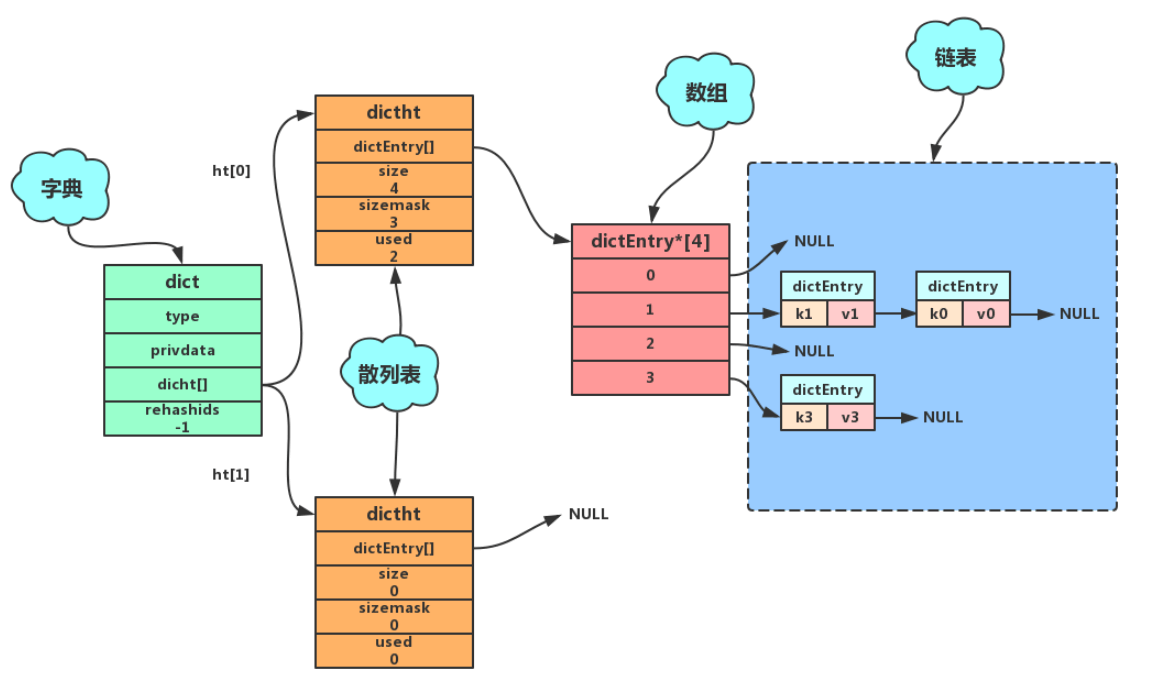
一个字典包含两个哈希表(dictht),通常只用一个,另一个用来rehash,新表和旧表是复用的
Hash表包含hash节点数组指针,数组大小,计算hash的掩码,和已经使用的大小
每个Hash节点除了key和value,还有next指针,使用链地址法用来解决hash冲突
当存储一个key时候,通过存储在type中的hash函数计算出hash值,放进dictht的hash节点数组中,当hash冲突的时候使用头插法。
(3)ReHash
当负载因子过大(>=1时),为了hash散列表的性能,需要进行rehash;当负载因子<=0.1,进行缩容
字典拥有的dictht[0]一般用于存储原始数据,当需要rehash的时候将dictht[0]中数据移动到dictht[1],但是由于一次性将所有数据移动到另一个dictht中太耗费性能,所以Redis使用渐进式Rehash:
dict中的rehashids变量标记当前字典是否在进行rehash操作,为-1则表示不需要rehash,为正数表示需要对rehashids位置的桶进行数据移动,每次增删改查的时候,判断是否在进行rehash,是则将当前访问的这个桶上的链表数据转移到dictht[1],并更新dictht[0]和dictht[1]的used字段,当dictht[0]所有数据完成之后,dictht[0]和dictht[1]角色互换(交换指针)。
每次增删改查判断是否需要Rehash,添加的过程如下
//宏定义函数:判断当前dict是否处于rehash过程#define dictIsRehashing(d) ((d)->rehashidx != -1)//当一个元素添加进字典的时候,首先调用dictAdd/* Add an element to the target hash table */int dictAdd(dict *d, void *key, void *val){//得到分配的内存dictEntry *entry = dictAddRaw(d,key,NULL);if (!entry) return DICT_ERR;dictSetVal(d, entry, val);return DICT_OK;}//具体的为添加元素分配内存的逻辑dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing){long index;dictEntry *entry;int htidx;//判断当前dict是否在执行rehash过程,是则调用一个_dictRehashStep过程//初始状态下是没有的if (dictIsRehashing(d)) _dictRehashStep(d);/* Get the index of the new element, or -1 if* the element already exists. *///_dictKeyIndex方法获得key的key在dictht[0]中的位置,并且还会调用_dictExpandIfNeeded方法//判断是否需要扩容if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)return NULL;/* Allocate the memory and store the new entry.* Insert the element in top, with the assumption that in a database* system it is more likely that recently added entries are accessed* more frequently. */htidx = dictIsRehashing(d) ? 1 : 0;entry = zmalloc(sizeof(*entry));entry->next = d->ht_table[htidx][index];d->ht_table[htidx][index] = entry;d->ht_used[htidx]++;/* Set the hash entry fields. */dictSetKey(d, entry, key);return entry;}static void _dictRehashStep(dict *d) {if (d->pauserehash == 0) dictRehash(d,1);}int dictRehash(dict *d, int n) {int empty_visits = n*10; /* Max number of empty buckets to visit. */if (!dictIsRehashing(d)) return 0;//传入的n=1,默认只进行一次bucket的rehashwhile(n-- && d->ht_used[0] != 0) {dictEntry *de, *nextde;/* Note that rehashidx can't overflow as we are sure there are more* elements because ht[0].used != 0 */assert(DICTHT_SIZE(d->ht_size_exp[0]) > (unsigned long)d->rehashidx);//rehashidx索引从0开始,意思是从头开始进行rehash,遇到为空,则移动到后续不为空的桶进行桶中节点的移动,并设置最大访问空桶时间减小阻塞时间。while(d->ht_table[0][d->rehashidx] == NULL) {d->rehashidx++;if (--empty_visits == 0) return 1;}de = d->ht_table[0][d->rehashidx];/* Move all the keys in this bucket from the old to the new hash HT */while(de) {uint64_t h;nextde = de->next;/* Get the index in the new hash table */h = dictHashKey(d, de->key) & DICTHT_SIZE_MASK(d->ht_size_exp[1]);de->next = d->ht_table[1][h];d->ht_table[1][h] = de;d->ht_used[0]--;d->ht_used[1]++;de = nextde;}d->ht_table[0][d->rehashidx] = NULL;d->rehashidx++;}static int _dictExpandIfNeeded(dict *d){/* Incremental rehashing already in progress. Return. */if (dictIsRehashing(d)) return DICT_OK;/* If the hash table is empty expand it to the initial size. *///dictht[0]如果为空就if (DICTHT_SIZE(d->ht_size_exp[0]) == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);/* If we reached the 1:1 ratio, and we are allowed to resize the hash* table (global setting) or we should avoid it but the ratio between* elements/buckets is over the "safe" threshold, we resize doubling* the number of buckets. */if (d->ht_used[0] >= DICTHT_SIZE(d->ht_size_exp[0]) &&(dict_can_resize ||d->ht_used[0]/ DICTHT_SIZE(d->ht_size_exp[0]) > dict_force_resize_ratio) &&dictTypeExpandAllowed(d)){//虽然这里传入的参数是原容量+1,但是找的是大于他的最小的2的幂,所以新容量是旧的两倍return dictExpand(d, d->ht_used[0] + 1);}return DICT_OK;}int dictExpand(dict *d, unsigned long size) {//这里面会调用_dictNextExp方法return _dictExpand(d, size, NULL);}//指定size的扩充逻辑,指定dictht[1]的大小为比size大的第一个2的整数次幂/* Our hash table capability is a power of two */static signed char _dictNextExp(unsigned long size){unsigned char e = DICT_HT_INITIAL_EXP;if (size >= LONG_MAX) return (8*sizeof(long)-1);while(1) {if (((unsigned long)1<<e) >= size)return e;e++;}}
总结一下:
增删改查的时候,先判断是否扩容,如果不需要,就计算key对应的hash值对应的索引值,放入dictht[0]
如果需要扩容,首先给dictht[1]分配内存,大小为比size大的第一个2的整数次幂,然后使用一个rehashidx变量标记要将dictht[0]哪个桶的元素移动到ht[1],移动完成之后rehashidx++,ht[0].used++,ht[1].used—,等待下一次增删改查操作继续渐进式hash.
当前桶移动完成之后,在ht[1]上执行本次增删改查操作,因此ht[0]上的元素越来越少,等到若干次增删改查操作之后,ht[0]的used字段变成0之后,rehash过程结束。
4.Set(集合)
(1)整数集合intlist
当元素都是整数且数量小于512,使用整数集合,否则使用hashtable
//每个intset结构表示一个整数集合typedef struct intset{//编码方式uint32_t encoding;//集合中包含的元素数量uint32_t length;//保存元素的数组int8_t contents[];} intset;
当编码方式为int16,放入int32的时候,就需要整数集合升级,升级过程:
首先为已有元素和新的元素分配内存 将已有元素换成新的类型,放到对应位置上,保持相对位置不变 将新元素放入
(2)Hashtable
set集合也是基于hashtable实现的,但是特殊的是他的所有value都是null值,当存储的时一个对象有多个属性的时候适合用hash,当存储的是不重复的k-v对的时候,适合用hash.
5.ZSet
zset基于ziplist和skiplist实现,有序集合包含的元素数量比较多,又或者有序集合中元素的成员是比较长的字符串时, Redis就会使用跳跃表来作为有序集合健的底层实现。
(1)压缩列表
见list部分
使用ziplist的条件
- 有序集合保存的元素个数要小于 128 个;
- 有序集合保存的所有元素成员的长度都必须小于 64 字节。
(2)skiplist跳跃表
一个skiplist结构如图,由skiplist和skiplistNode组成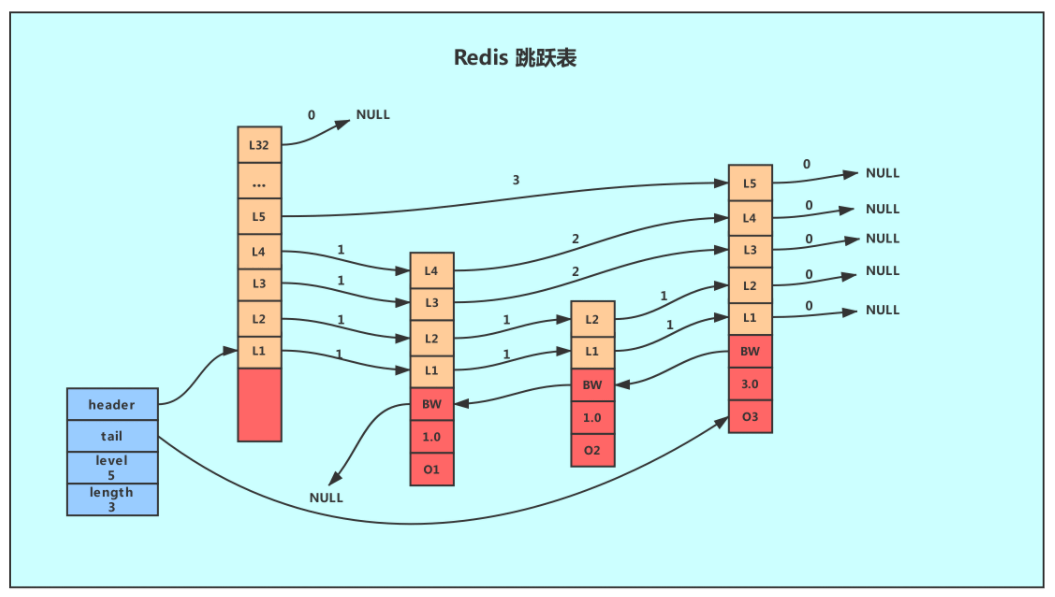
skiplist包括:
header:指向跳跃表的表头节点,通过这个指针程序定位表头节点的时间复杂度就为O(1)
tail:指向跳跃表的表尾节点,通过这个指针程序定位表尾节点的时间复杂度就为O(1)
level:记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内),通过这个属性可以再O(1)的时间复杂度内获取层高最好的节点的层数。
length:记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内),通过这个属性,程序可以再O(1)的时间复杂度内返回跳跃表的长度。
skiplistNode包括
成员对象(oj):同一个跳跃表中,各个节点保存的成员对象必须是唯一的,但是多个节点保存的分值却可以是相同的。 分值(score):各个节点中的1.0、2.0和3.0是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列。 后退(backward)指针:节点中用BW字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。与前进指针所不同的是每个节点只有一个后退指针,因此每次只能后退一个节点。 层(level):用L1、L2、L3等字样标记节点的各个层,L1代表第一层,L代表第二层,以此类推。 每层包含前进指针和跨度数 生成节点的时候层数是随机的(1-32),越高的层出现的几率越小。不同节点层数示意如下图
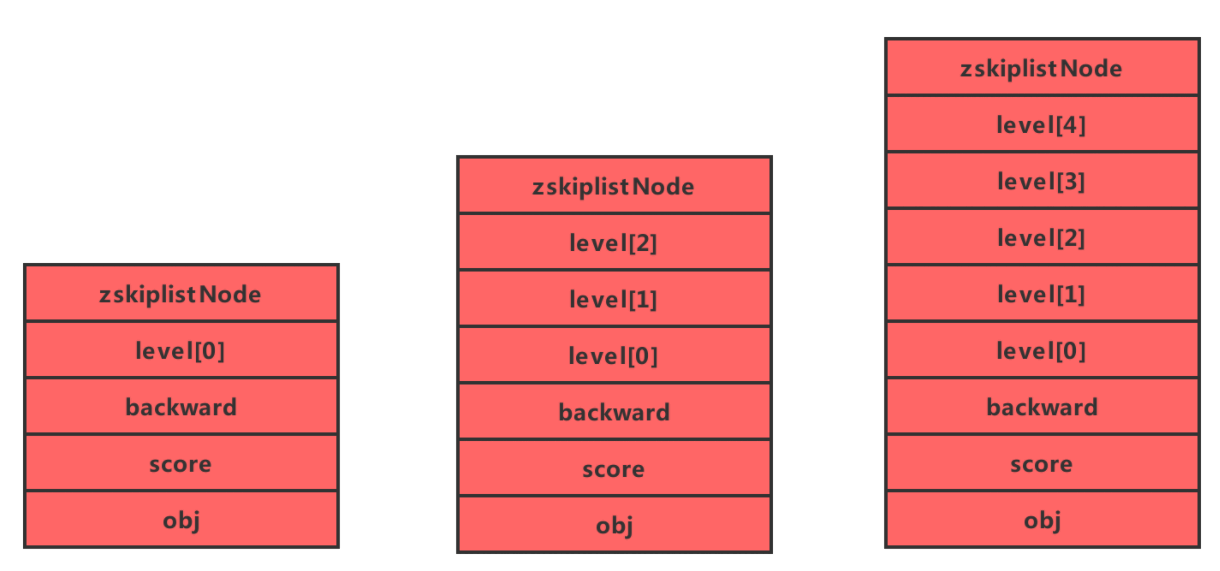
(4)zset的命令
zadd:添加成员及其分数
zincrby:对成员分数增加(正负)
zscore:查看成员的分数
zrevrangebyrank:展示分数最高的几个成员
ZRANGEBYLEX:展示分数满足指定条件的成员
Redis的常见使用场景
1.缓存:提升服务器性能

若有收获,就点个赞吧
0 人点赞
