Redis为什么这么快
(官方数据:最高可达10w+的QPS)
完全基于内存,绝大部分请求是纯粹的内存操作;
数据结构简单,都是K-V,对数据操作也简单;
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消 耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
使用多路I/O复用模型,非阻塞IO
Redis的内存淘汰策略
(1)volatile-lru:从已设置过期时间的数据集中挑选最近最少使用的数据淘汰。
(2)volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰。
(3)volatile-random:从已设置过期时间的数据集中任意选择数据淘汰。
(4)volatile-lfu:从已设置过期时间的数据集挑选使用频率最低的数据淘汰。
(5)allkeys-lru:从数据集中挑选最近最少使用的数据淘汰。
(6)allkeys-lfu:从数据集中挑选使用频率最低的数据淘汰。
(7)allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰。
(8)no-eviction(驱逐):禁止驱逐数据,这也是默认策略。意思是当内存不足以容纳新入数据时,新写入操作就会报错。
(注意:这里的volatile不是在过期了的key实施内存淘汰策略,而是对设置了过期时间的key执行)。
Redis过期了的key怎么删除
(1)定时删除:设置定时器,到时间了就删除过期key。
对内存友好,过期key能很快被删除;但是对cpu不友好,需要维护计时器
(2)惰性删除:当试图获取某个键时再检查是否过期,过期则删除。
对cpu友好,不用额外的消耗;对内存不友好,可能会存在过期key堆积
(3)定期删除:每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。是前两种方案的折中。
Redis持久化
1.RDB(内存快照)
某个时刻把内存中的数据记录下来,以文件的形式保存到硬盘上,这样即使宕机,数据依然存在。
RDB文件的创建可以分为手动触发和被动触发
(1)手动触发:save
阻塞当前Redis服务器,直到RDB过程完成为止。在服务器进程阻塞期间,服务器不能处理任何命令请求。
(2)手动触发:bgsave
bgsave命令会派生出一个子进程(而不是线程),由子进程进行RDB文件创建,而父进程继续处理命令。
(3)自动触发:可以设置条件触发保存RDB
例如:
save 9001 save 30010 save 6010000
- 服务器在900秒内对数据库进行了至少1次修改
- 服务器在300秒内对数据库进行了至少10次修改
- 服务器在60秒内对数据库进行了至少10000次修改
Redis启动时会首先加载AOF文件,如果没有才会加载RDB,因为AOF频率比RDB高
(4)写RDB修改数据问题
Redis 借助了操作系统提供的写时复制技术(Copy-On-Write, COW),fork子进程和父进程共享一块物理区域,当父进程需要修改数据,就将要修改的数据复制一份,作为RDB写的依据,然后父进程就可以在原来的数据上修改
2.AOF(Append Only File)
AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库状态的。即每执行一个命令,就会把该命令写到日志文件里。
AOF是在redis主进程中执行的,所以可能有写入压力大或者日志丢失问题,采用首先写入缓冲区的策略:
Always(同步写回): 命令写入 AOF缓冲区后调用系统 fsync操作同步到AOF文件, fsync完成后线程返回 每次修改都要写入,影响性能
Everysec(每秒写回): 命令写人 AOF缓冲区后调用系统 write操作, write完成后线程返回。fsync同步文件操作由专门线程每秒调用一次,默认策略
No(操作系统自动写回): 命令写入 AOF缓冲区后调用系统 write操作,不对AOF文件做 fsync同步,同步硬盘操作由操作系统负责,通常同步周期最长30秒 不可控,一半不选择
3.AOF重写:精简AOF文件
为了减小aof文件的体量,通过子进程生成更小体积的aof,然后替换掉旧的、大体量的aof文件。子进程把数据转为写指令存入新的AOF文件时,记录的只是每个数据的最后一次写指令,也就是最新的数据,不会记录之前冗余的操作,所以这样会很大程度的缩小AOF的体量,同时,该操作是产生新的AOF文件进行写入,而不是在原有文件上的修改,通过上图也可以看出来。
设置合适的持久化方式
1.RDB的优点:
相同数据量体积更小:因为RDB记录的是数据的快照,AOF记录的是操作
数据恢复更加方便:因为直接是数据的复制
性能更高:只需要fork子进程来完成,不会导致主Redis进行IO操作
2.RDB的缺点
由于是每次备份RDB都是全量,因此不能频繁进行,两次备份之间的数据丢失可能性比较大
全量的备份在数据量很大的时候可能导致磁盘和cpu占用率高
兼容性
3.AOF的优点
易于解析,因为备份的是操作命令,不容易有兼容性问题
因为是追加写,所以可以频繁执行,数据丢失的可能性比较小,就算丢失也是两次写之间很短时间的数据
4.AOF的缺点
因为是在Redis主进程执行写,所以会影响Redis性能;只有当AOF文件太大了才会fork子进程执行重写策略
体积较大,因为记录的是操作的过程
Redis启动的恢复速度较慢,因为不是数据本身而是数据的操作,所以要解析命令写入
5.混合持久化
RDB以一定的频率执行,而在两次RDB快照之间,使用 AOF 日志记录这期间的所有命令操作。
这样:
RDB不用频繁执行
AOF只用执行两次RDB之间的操作,占用空间比较小。
6.合适的选择策略
(1)业务需要高性能以及宕机后很快恢复,对数据完整性要求不高,能容忍一定程度的数据丢失,使用RDB
(2)要求数据高完整性,要求数据尽可能丢失少,使用AOF
(3)两者都要求,使用混合持久化
Redis的内存消耗
1.Redis自身进程内存
2.对象内存
3.缓冲区内存
(1)连接缓冲区
为了处理客户端和redis服务器传输速率不匹配的问题,redis服务器会将客户端发送的命令存储在输入缓冲区中,将输出的结果暂时存储在输出缓冲区中
(2)AOF缓冲区
(3)用于主从同步的复制积压缓冲区
主节点在向从节点传输 RDB 文件的同时,会继续接收客户端发送的写命令请求。这些写命令就会先保存在复制缓冲区中,等 RDB 文件传输完成后,再发送给从节点去执行。主节点上会为每个从节点都维护一个复制缓冲区,来保证主从节点间的数据同步。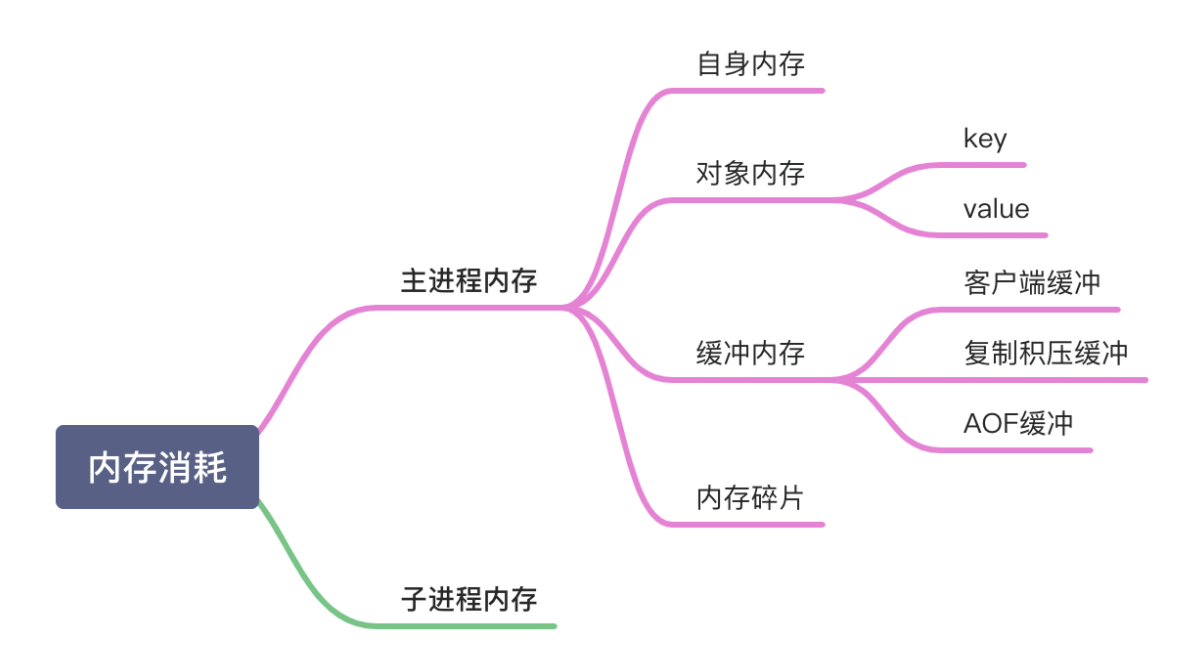
Redis集群
来源:https://zhuanlan.zhihu.com/p/104641341
1.数据分布
Redis采用将数据分到不同的桶中,一共16384个桶,当有数据进来,使用CRC16函数计算key的键值,再对16384取模,放到对应的桶中,每个桶只能由一个主节点存储,但是一个一个主节点可以负责多个桶。事实上,每个槽中放的都是一个跳跃表。只有Master才拥有槽的所有权,如果是某个Master的slave,这个slave只负责槽的使用,但是没有所有权。
CRC16可以分配65535个槽,但为什么是16384:
(1)65535个槽导致Redis集群中的心跳消息太大了,不利于集群内部更新状态
(2)16384是2的整数次方,%操作可以用&操作替代,更快速。
2.路由查询
每个节点都保存一个槽数组,用于标记负责每个槽的节点
unsigned char slots[CLUSTER_SLOTS/8];
每个节点处理键命令时,首先计算根据CRC16计算槽位,再根据槽数据计算节点,如果自身就是该节点,直接处理,否则向客户端返回Moved消息,包含对应的桶和对应的桶的地址节点.
客户端为了高效访问每个槽对应的节点信息可以将这个数组缓存下来,这种缓存slots信息的客户端就是Smart Client
节点迁移的时候,某个桶A中的数据迁移到B的过程中,对A的访问如果没有命中,就会返回重定向信息ASK,包括B的地址(不同于MOVED,ASK并不会被客户端更新记录)
3.Cluster节点通信
Redis使用Gossip协议发送消息,一个大小为N的集群的每一个节点每次向随机K个其他节点传输自己视角下的随机M个节点的状态。其中M和K都远远小于N。
M最小值为3,最大值为N-2;
4.集群的伸缩
数据是基于slot来存储的,所以Redis集群的伸缩本质上是slot在不同的节点上的移动,
4.1扩容
扩容可以分为3步,准备新节点,加入集群,迁移slot到新的节点
加入集群可以让新启动的Redis与集群中的任意节点握手,这样经过Gossip协议,一段时间之后,整个集群都会感知到新节点的存在。
为了负载均衡,将原有的节点上的16384个slot均分到现有所有的slot上,因此,每个旧的节点都会分一些slot给新的节点。但是呢,迁移多少个,具体是由用户自身实现的。
路由问题:每个节点都会保存一个数组用于映射slot对应的处理节点,当源A正在迁移slot1到B的时候,AB都会将slot1状态标记为转移(IMGRATING)或导入(IMORTING)状态,如果有slot1的访问请求到AB之外的节点,统一转发给A,A查看slot1中是否存在数据,有就返回,没有就ASK重定向给B; B收到slot1的请求查看是否有ASK,没有就定向到A,有就说明是A发过来的,直接查询正在转发中的slot1是否有数据。
4.2 扩容时的键值对迁移
批量迁移,将slot1中所有的键值对都统一序列化之后传输给目标节点。
注意:slot的迁移是逐个进行的。批量迁移指的是某个slot中的键值对
4.3集群变化后的广播消息
现在slot由B而不是A负责了,需要向其他节点通知这个消息,可以只向某几个节点通知,按照Gossip协议,整个集群最终也能知道,但是为了低延迟,最好向每个节点广播消息。
4.4集群收缩
首先将持有的slot迁移到其他节点,然后广播通知集群中的所有节点自己下线了。
5.Redis集群的一致性协议
5.1Raft协议
是解决分布式情况下的一致性的协议,集群中每个节点都可能处于三个状态,Leader、Follower、Candidate
Leader:所有请求的处理者,Leader副本接受client的更新请求,本地处理后再同步至多个其他副本; Follower:请求的被动更新者,从Leader接受更新请求,然后写入本地日志文件。只接受Leader和Follower的消息。 Candidate:如果Follower副本在一段时间内没有收到Leader副本的心跳,则判断Leader可能已经故障,此时启动选主过程,此时副本会变成Candidate状态,直到选主结束。
Raft将时间分成片term并编号,每个节点维持同一个termId,Leader使用心跳消息发送给所有的Follow维护自己的地位,当Follower长时间没有收到Leader消息,就变成Candidate发起选举成为Leader:
首先,将TermId自增,给其他节点发送RequestVote RPC消息,如果Leader收到termId大于自己的消息,自动变成Follower,原来的其他Follower收到这个消息就会投票给发起的Candidate,最终如果有大于等于N/2+1的节点投票,发起投票的Candidate自动变成Leader.
如果投票期间收到其他candidate竞争者的消息,则比较termId大小看是否成为Follower还是继续竞争。
所有节点的数据状态一致性是通过日志来保障的,命令都被写在日志里,只要保证日志一致,那么各个节点执行日志命令就能保证数据状态一致。

若有收获,就点个赞吧
0 人点赞
