- 1.OOM可能怎么发生?如何排查
- 2.分布式锁
- 3.Redis集群选举算法
- 4.MySql的hash索引
- 5.缓存雪崩时间怎么设置
- 6.Redis IO的优化
- 7.Java线程数过多时,如何保证性能
- 8.分布式Hash存储,一致性Hash
- 9.Major GC Full GC Minor GC
- 10.JVM分析常用命令
- 10.TCP reset命令
- 11.MySql Char和varchar的区别
- 12.负载均衡算法
- 13.为什么需要区分内核空间与用户空间
- 14.ConcurrentHashmMap JDK1.8
- 15.Volatile关键字
- 16.常用的类加载器
- 17.CMS垃圾回收器和G1垃圾回收器
- 18.深拷贝和浅拷贝
- 19.CAS的ABA问题
- 20.RocketMQ的两阶段事务提交过程
1.OOM可能怎么发生?如何排查
OOM发生主要是由于分配的太少了或者用的太多了
常见情况
(1)堆内存溢出,对象太多或者收不回来
(2)永久代空间溢出,大量class文件,cglib代理,大量jsp页面
(3)栈溢出,一般因为死循环或者深度递归
如何排查
(1)查看泄露对象到GC root的引用链,分析如何泄露的
(2)没有泄露的话,可以调大堆内存的参数
或者代码上检查是否有对象存活或者持有时间过长的情况
2.分布式锁
单进程下,多线程对共享变量的访问通过锁实现,因为堆中数据一般是线程共享的,一般可以通过堆内存中的对象来实现锁。在多进程环境下,不能访问共享内存,所以分布式锁需要另外的实现方式,例如Redis和数据库等。
分布式锁应该具有的特性:
1.同一时刻只能被不同机器的同一进程的同一线程访问
2.高性能获取和释放锁
3.可重入
4.防止死锁
5.非阻塞,获取不到锁就返回失败
(1)使用数据库乐观锁
使用一个版本号控制,多个线程都读取同一行数据,包括它的版本号,然后多个线程写入数据的时候where条件中带上版本号条件,因为mysql更新操作是自带排他锁的,所以只会有一个线程更新数据成功:
-- 添加版本号控制字段ALTER TABLE table ADD COLUMN version INT DEFAULT '0' NOT NULL AFTER t_bonus;-- 线程1查询,当前left_count为1,则有记录,当前版本号为1234select left_count, version from t_bonus where id = 10001 and left_count > 0-- 线程2查询,当前left_count为1,有记录,当前版本号为1234select left_count, version from t_bonus where id = 10001 and left_count > 0-- 线程1,更新完成后当前的version为1235,update状态为1,更新成功update t_bonus set version = 1235, left_count = left_count-1 where id = 10001 and version = 1234-- 线程2,更新由于当前的version为1235,udpate状态为0,更新失败,再针对相关业务做异常处理update t_bonus set version = 1235, left_count = left_count-1 where id = 10001 and version = 1234
(2)使用数据库悲观锁控制
通过select for update给一行数据加排他锁,就可以实现悲观的锁获取,但是也有缺点,当查询不走索引的时候,就会使用表锁,影响性能。
(3)使用Redis的Setnx()和expire()
Setnx(key,value)方法只有在key不存在的时候才会设置,当key存在的时候就返回失败。利用redis本身的原子性来实现只有一个set能访问成功。然后使用expire()设置key的过期时间,可以在业务完成之后就让key过期,即释放锁
缺点:当设置了key之后,expire之前redis宕机,那么就会死锁,就算恢复了expire也不会得到执行
(4)使用Redis的setnx(),get(),getset()实现避免死锁的分布式锁
setnx(lockkey, 当前时间+过期超时时间) ,如果返回1,则获取锁成功,否则下一步。
get(lockkey)获取值oldExpireTime,并和系统时间比较,如果小于系统时间则已经过期,执行下一步
计算newExpireTime=当前时间+过期超时时间,然后getset(lockkey, newExpireTime) 会返回当前锁的过期时间,如果和oldExpireTime相等,那么表示获取成功;如果不相等,那么说明过程中被其他进程获取了,再重复第一步进行获取
3.Redis集群选举算法
3.1选举
Raft的Follower在没接收到Leader随机延迟(150-300ms)后,检查是否能连接到全部节点,发起选举。
Redis的slave在没有如期收到Master的心跳消息时,如果太久没收到master信息,不会发起选举。否则休眠一段时间,发起选举,休眠时间的确定按照公式计算,和Master通信时间越少,休眠时间就越短,就会首先发起选举,成为Master,这样是为了保证拥有和Master最接近的数据。
投票方只能投一票,并且只能投给term更大的选举者
3.2日志同步
全量复制:Redis和Raft都是将主节点内数据生成快照,Redis叫做RDB
部分复制:收到数据操作请求,master本地操作完立即返回客户端,然后将命令异步转发给slave节点。
4.MySql的hash索引
索引是存储引擎层次实现的而不是MySQL数据库层次的,Mermory引擎默认的是Hash索引
Hash索引只能支持等值查询,不支持范围查询
注意,Innodb有一个支持自适应Hash索引功能:
当某些查询模式被频繁访问,innodb会在内存中建立hash表,提升查询速度,这个功能只能设置开关,没有参数调节
5.缓存雪崩时间怎么设置
预防
使用高可用技术,例如Redis的集群
key的过期时间不要设置为一样,尽量使用随机
发生了怎么解决
限制mysql的流量
使用微服务的熔断机制,设置服务降级快速返回
6.Redis IO的优化
Redis使用多路复用机制,当监听到文件描述符上有请求,就将事件放入事件队列,单线程一直不断处理事件队列中的数据。
性能调优:
不要把List当做列表使用,仅当做队列来使用
可能的话,将 、并集、交集等操作放在客户端执行
禁止使用KEYS命令
7.Java线程数过多时,如何保证性能
线程池策略
8.分布式Hash存储,一致性Hash
当使用分布式缓存的时候,一种方式是数据的hash值对机器数取模,确定缓存放在哪个机器上,但是当机器扩容的时候,数据需要迁移,这时所有数据都需要重新计算hash值,导致所有的缓存全部失效,可能会发生雪崩。
一致性Hash也是取模,但是是将数据的hash值%2^32,然后服务器分布在大小为2^32的圆环上,数据放在从hash值开始的右边第一个服务器。这样,当增删服务器节点的时候,使只用移动一部分数据。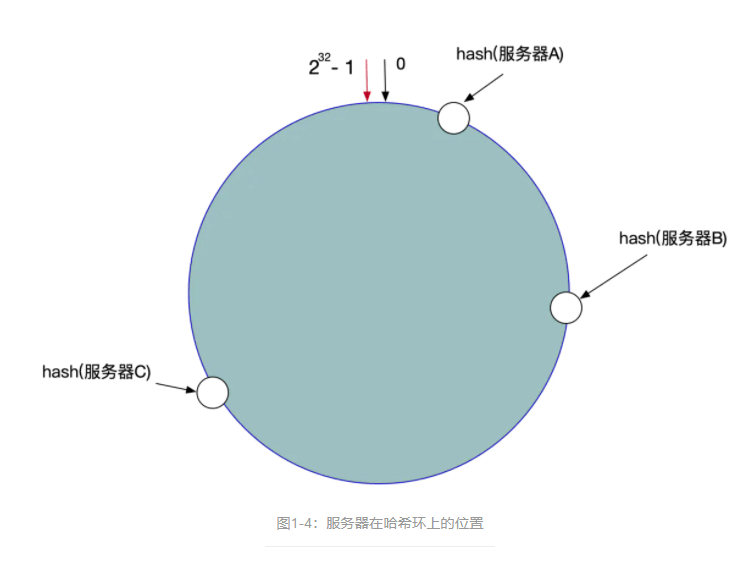
9.Major GC Full GC Minor GC
Minor是清理年轻代,Major是清理老年代,Full是清理老年代和年轻代
9.1Minor GC
当Eden区无法创建新的对象的时候,就会触发MinorGC,将Eden区和S0区的对象进行可达性分析,找出活跃的对象一起放到S1区,然后对象年龄+1。
所有的MinorGC都会stop the world,之所以采用两个survivor区,是因为大部分对象生命周期很短,只需要付出少量的复制成本就可以完成收集。
9.2 Major GC
当大对象放进Eden区,放不下,就会MinorGC,如果还是放不下,就会试着放入老年代,Survior区的达到年龄的对象也会放入老年代,如果放不下,就Major GC,如果还是放不下,就OOM。
老年代的大小通常比新生代大很多,一般为1:2,即老年代占据2/3,一般采用标记整理算法
9.3 Full GC
同时进行MinorGC 和Major GC,并且回收永久代(方法区),例如当Minor GC触发时,虚拟机检查每次进入老年代的对象是否小于老年代剩余空间,如果小于那么就触发Full GC
方法区的回收主要包括常量和类文件,类回收的条件是:
所有实例已经被回收
类加载器已经被回收
没有指向该类的引用
9.4可达性分析
从永久代到年轻代的引用被当成GC roots,但是从年轻代到永久代的引用会在引用的标记阶段被直接忽略。
10.JVM分析常用命令
(1)jstat :擦好看JVM信息,包括垃圾回收统计,类加载统计,各个分代内存统计
(2)jps:显示Java进程信息
(3)jinfo:查看指定进程的JVM配置信息,比如各个
以上三个命令一般是首先使用jps查看指定Jar包运行的对应进程,在使用jinfo查看配置,最后使用jstat分析具体状态(垃圾回收,类加载等)。
Top命令查看进程资源占用情况,Top -Hp pid查看指定进程下所有线程占用资源的情况
(4)jstack:查看指定线程的堆栈信息,定位死循环这种类型的位置
要关注的线程状态包括:
死锁,Deadlock(重点关注)
等待资源,Waiting on condition(重点关注)
等待获取监视器,Waiting on monitor entry(重点关注)
阻塞,Blocked(重点关注)
(5)jmap:查看当前内存的堆快照,例如存活的对象个数,大小等,也可以看到堆各个分区的容量和使用情况,还可以将堆的快照输出到文件
(6)jhat:当jmap的堆快照输出到二进制文件后,jhat可以读取并在本地7000端口进行html页面可视化
可以搜索查询指定的类信息。
10.TCP reset命令
11.MySql Char和varchar的区别
char定长,不足就会使用空格补足
varchar不定长,最右边使用一个位置记录长度
12.负载均衡算法
轮询法,随机法,源地址hash法,加权轮询,加权随机,最小连接法
加权轮询:根据权重大小判断,权重越大,就多加几个到选择列表
加权随机:在加权轮询基础上,不轮询而是随机
最小连接法:从服务端的角度来看,选择积压连接最少的服务器
13.为什么需要区分内核空间与用户空间
在 CPU 的所有指令中,有些指令是非常危险的,如果错用,系统崩溃的概率将大大增加。
14.ConcurrentHashmMap JDK1.8
采用CAS加Synchronized来保证并发
Node节点的val相比HashMap中的val值多了一个volatile保证变量的可见性
在put值的时候,使用cas往table中放置数据,成功直接返回
CAS失败就说明有竞争,该节点已经被放了,然后使用synchronized获取头节点的锁,然后遍历添加值
添加完后释放锁,看是否变树,变树过程也要加锁
15.Volatile关键字
volatile变量的写之后和读之前会加入内存屏障指令,这个指令强制从主存而不是缓存中读取数据,内存屏障指令在不同的系统上对应的实现方式不一样
16.常用的类加载器
BootStrap ClassLoader(启动类加载器):C++实现,由JVM启动,加载%JRE_HOME%\lib下的rt.jar、resources.jar、charsets.jar和class等
Extension ClassLoader(扩展类加载器):加载%JRE_HOME%\lib\ext目录下的jar包和class文件
Application ClassLoader(应用类加载器,也称为系统类加载器):加载当前应用classpath路径下的类
采用双亲委派模型进行类加载,加载类的时候,首先通过缓存查看该类是否已经加载,是则直接返回,否则当父加载器不为空的时候尝试使用父加载器加载。
应用场景:引入不同的第三方库的时候可能出现类名冲突,这时候可以自定义类加载器,因为JVM判断类相同的依据是类名和类加载器都相同。
当将非.class文件转化成Java类的时候就可以自定义类加载器从文件读取指定字节流
自定义类加载器:双亲加载失败,就需要类加载器自己通过findClass负责加载类,所以自定义类加载器需要重写findClass方法(如果需要打破双亲委派机制,就需要重写loadClass方法),findClass定义了如何将一个文件读取到字节数组中(相当于读取到内存中),
17.CMS垃圾回收器和G1垃圾回收器
CMS是一个并发的使用标记清除算法的垃圾回收器,用于回收老年代和方法区,时延较低
缺点:使用标记清除算法,内存碎片化
算法比较复杂
周期性Major GC:老年代或者方法区的使用率达到92%的时候启动:
初始标记:STW,标记GC root或者年轻代中直接指向的老年代的对象
并发标记:
重新标记:STW,遍历GC root和新生代对象,以及之前标记的老年代对象
G1垃圾回收器
18.深拷贝和浅拷贝
浅拷贝只拷贝地址值
深拷贝拷贝的是对象
clone()方法中使用的是浅克隆,引用对象其实克隆的是引用,要使用深拷贝,就要修改每个引用类型的clone()方法,并在当前类中修改clone()方法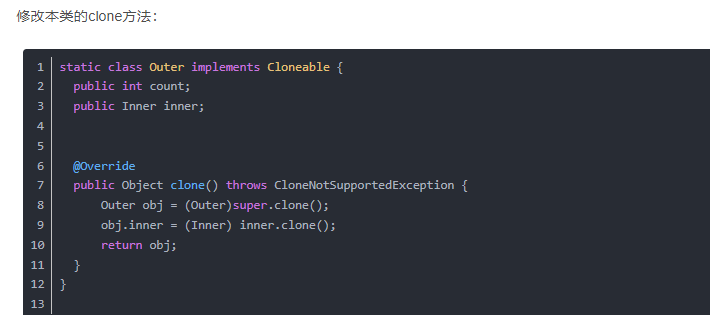
另外,每个类都去实现Cloneable很麻烦,使用序列化也可以实现深克隆
19.CAS的ABA问题
当使用CAS的时候,某个变量开始的值是A,后来被改成B之后又改成A,虽然值和开始一样,但是已经不是原来的数据了,可能会发生错误,因此在有类似业务需求比对的时候应该要同时比对值和版本号。
20.RocketMQ的两阶段事务提交过程
首先producer将半消息发送到broker,然后broker将消息持久化,持久化成功之后返回producer执行本地事务,本地事务执行之后,发送结束半消息的请求,并带上提交状态(提交 or 回滚),broker收到半消息结束的请求之后,从持久化的消息队列中找到这个消息,然后如果提交状态是提交则将这个消息放到对应topic的队列中去,就可以被消费了,如果状态时回滚那么就什么也不做。Broker启动时,会启动一个TransactionalMessageCheckService任务,该任务会定时从半消息队列中读出所有超时未完成的半消息,通过producer的回调方法checkLocalTransaction方法来重新确认消息的状态。

若有收获,就点个赞吧
0 人点赞
