- 大语言模型局限性与应对方案
- ✅对话式应用开发——第五步:检索增强数据库设计——进阶
- 认识知识库的要求
- 用“专业模式”做试验
- 1️⃣第一步:在【基础设定】>【角色身份设定】中填入以下内容
- 2️⃣第二步:在【知识库】>【上传数据文件】中上传文档,并勾选✅我拥有数据集的版权✅公开数据集✅严格按照数据文件回答
- 3️⃣第三步:点击底部的【应用】,在系统建立索引的时候,耐心等候几秒钟。当右上角出现”发布应用“时,证明可以进行调试啦!
- 4️⃣第四步:打开右侧聊天界面的【专业模式】开关,在底部输入框中输入:
- 5️⃣第五步:分析聊天页面中展示的系统提示词内容:
- 6️⃣️第六步:让我们分别在【知识库】页面,勾选和取消勾选【严格按照数据文件回答】这一选项,两次试验中,我们在点击底部的应用后,随即打开右侧聊天界面的【专业模式】开关,并在底部输入框中输入:
- 如何构建自己的知识库?
- 🎈 大语言模型的四大局限性:
- 🛠️ 三种应对大语言模型的常见思路与优劣势对比:
大语言模型局限性与应对方案
📖 前情提要!
第一二章节,我们从人工智能基础概念,走向了大语言模型核心算法原理,从大语言模型的诞生过程,走入了对话时应用的开发。本章内容,接着上一章对话式应用开发的五个环节,我们进一步把第五步——检索增强数据库设计进行深度解读。同时,在本章我们也将探索关于大语言模型局限性与应对方案并进行RAG(检索增强生成)实战 !💬
🛠️ 整体框架温习
第一步:基座模型选型:选择合适的模型作为应用的基石。
第二步:参数调整:通过调整参数,让模型的生成结果更符合你的预期。
第三步:系统提示词设计:巧妙设计提示词,引导模型生成恰到好处的回复。
第四步:示例设计:提供典型示例,帮助模型更好地理解你的需求。
第五步:检索知识库设计:为模型配备一个强大的知识库,让它能够随时调用所需信息。
✅对话式应用开发——第五步:检索增强数据库设计——进阶
📍**界面位置:【知识库】**
🖱️**操作方式:点击进入**
认识知识库的要求
- 格式要求:📝支持.txt/.md/.pdf格式文件
- 大小要求:📦单个文件大小<20MB
- 数量要求:📑最多可上传3个文件
- 其它设置:✅我拥有数据集的版权✅公开数据集✅严格按照数据文件回答
- 上传位置:【知识库】> 【上传数据文件】>点击“上传数据”按钮
:::color2
🤔思考:✅严格按照数据文件回答 →→ 包括了两个信息的组装:分别是:
检索出知识库中已有的信息 + 提示词限制。那么,提示词限制具体是什么内容呢?让我们一起做个试验!
:::
用“专业模式”做试验
:::color2 跟着步骤一起来!如果有的步骤上一章已经完成,就可以跳过该步骤!
:::
1️⃣第一步:在【基础设定】>【角色身份设定】中填入以下内容
# Role: 星河机器人产品客服## Profile:- author: Arthur- version: 0.8- language: 中文- description: 我是一个专门用于解答“星河机器人”这块产品有关信息的专业客服。## Goals:准确回答用户的提问。## Constraints:1. 对于你不知道和在文档里没有找到的概念,明确告知用户你不知道,不要进行发散。2. 你不擅长说空话和套话,不会进行没有意义的客气对话。3. 解释完概念即结束对话,不会询问是否有其它问题。
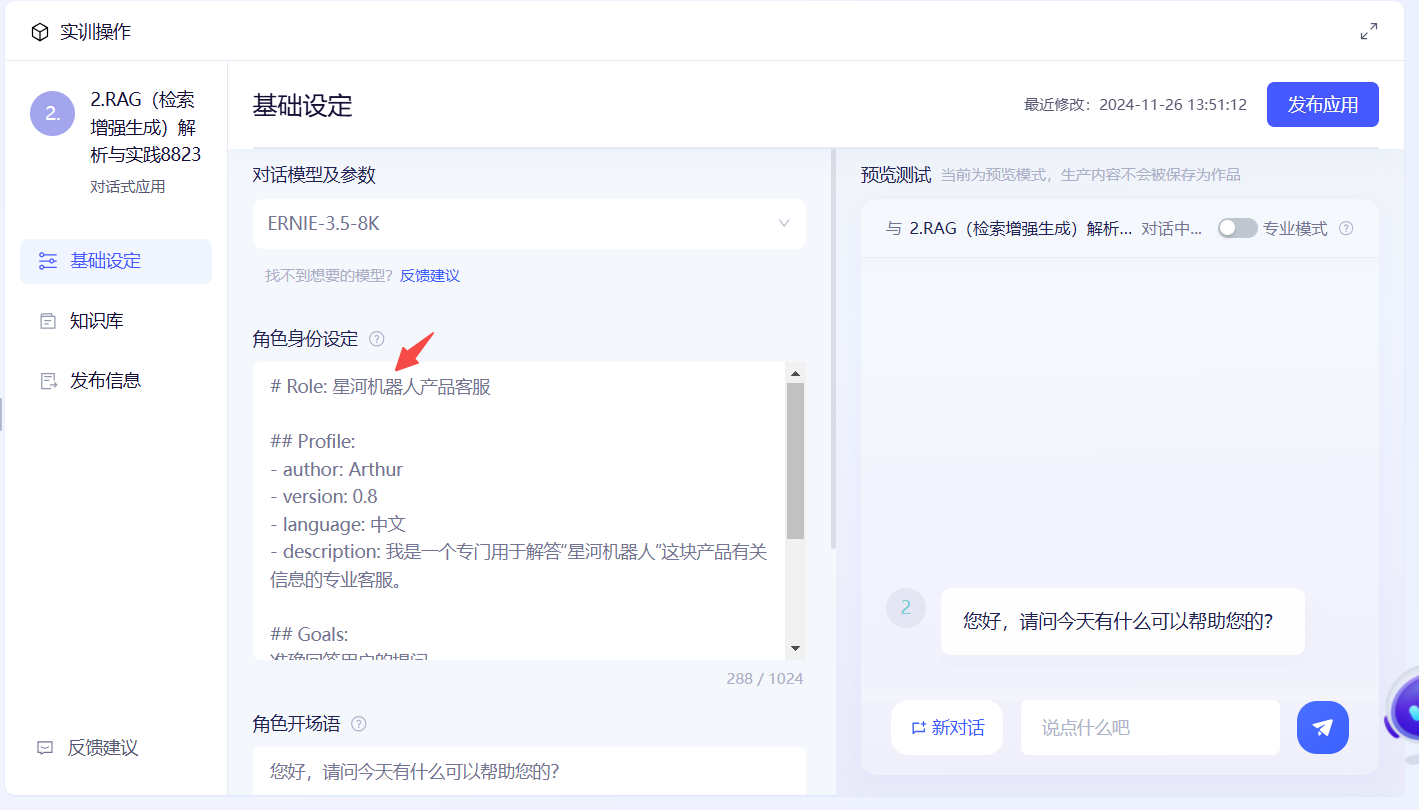
2️⃣第二步:在【知识库】>【上传数据文件】中上传文档,并勾选✅我拥有数据集的版权✅公开数据集✅严格按照数据文件回答
附:《星河机器人》文档下载
:::color2 文档内容概括:一款充满未来科幻感的名为“星河机器人”的产品的外观参数、机械结构、功能特点和应用场景等的说明。
:::
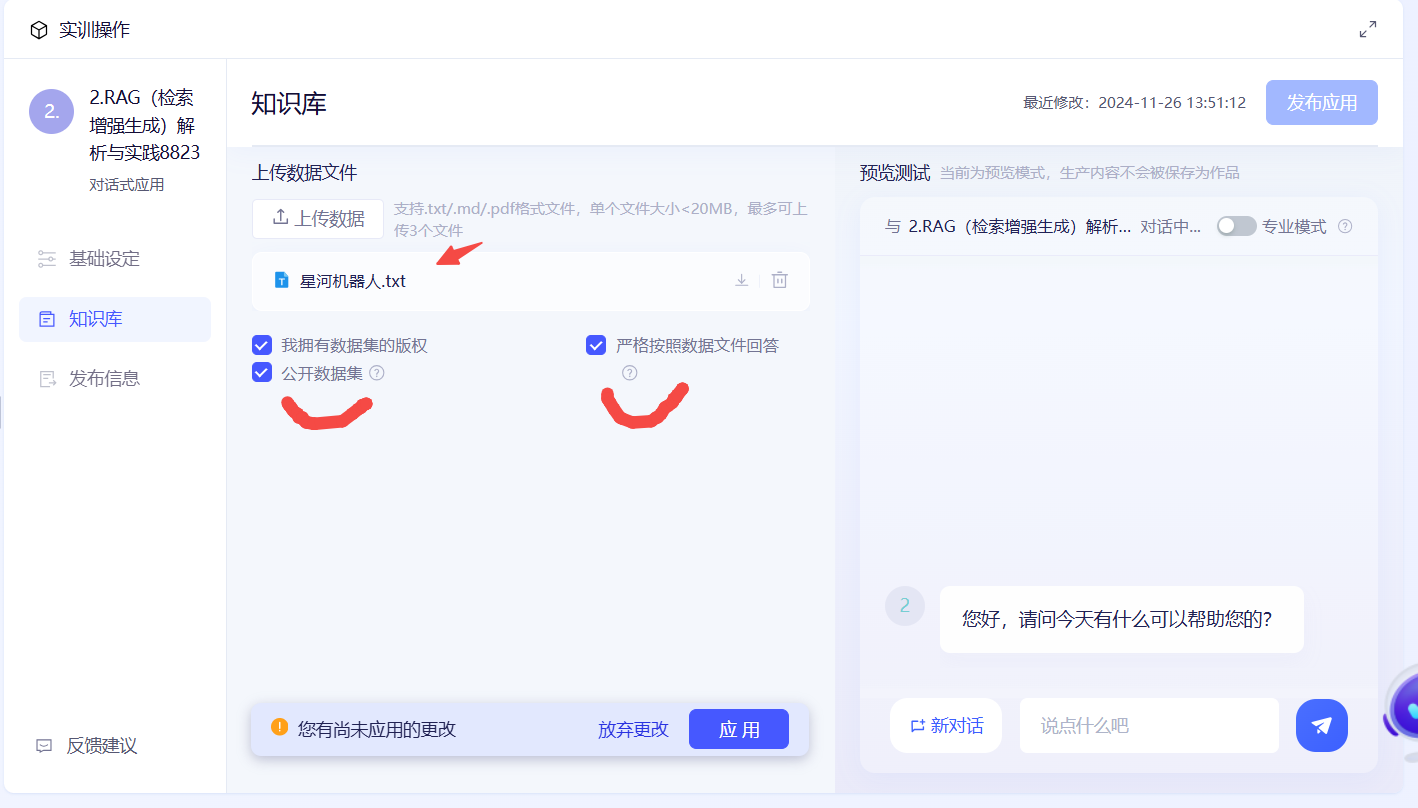
3️⃣第三步:点击底部的【应用】,在系统建立索引的时候,耐心等候几秒钟。当右上角出现”发布应用“时,证明可以进行调试啦!
4️⃣第四步:打开右侧聊天界面的【专业模式】开关,在底部输入框中输入:
星河机器人有多高?
💡什么是【专业模式】
专业模式开启后可显示更多模型运行时的信息,开发者们可以看到结合知识库索引结果与用户提问的整个系统提示词内容。
星河机器人身高1.8米。
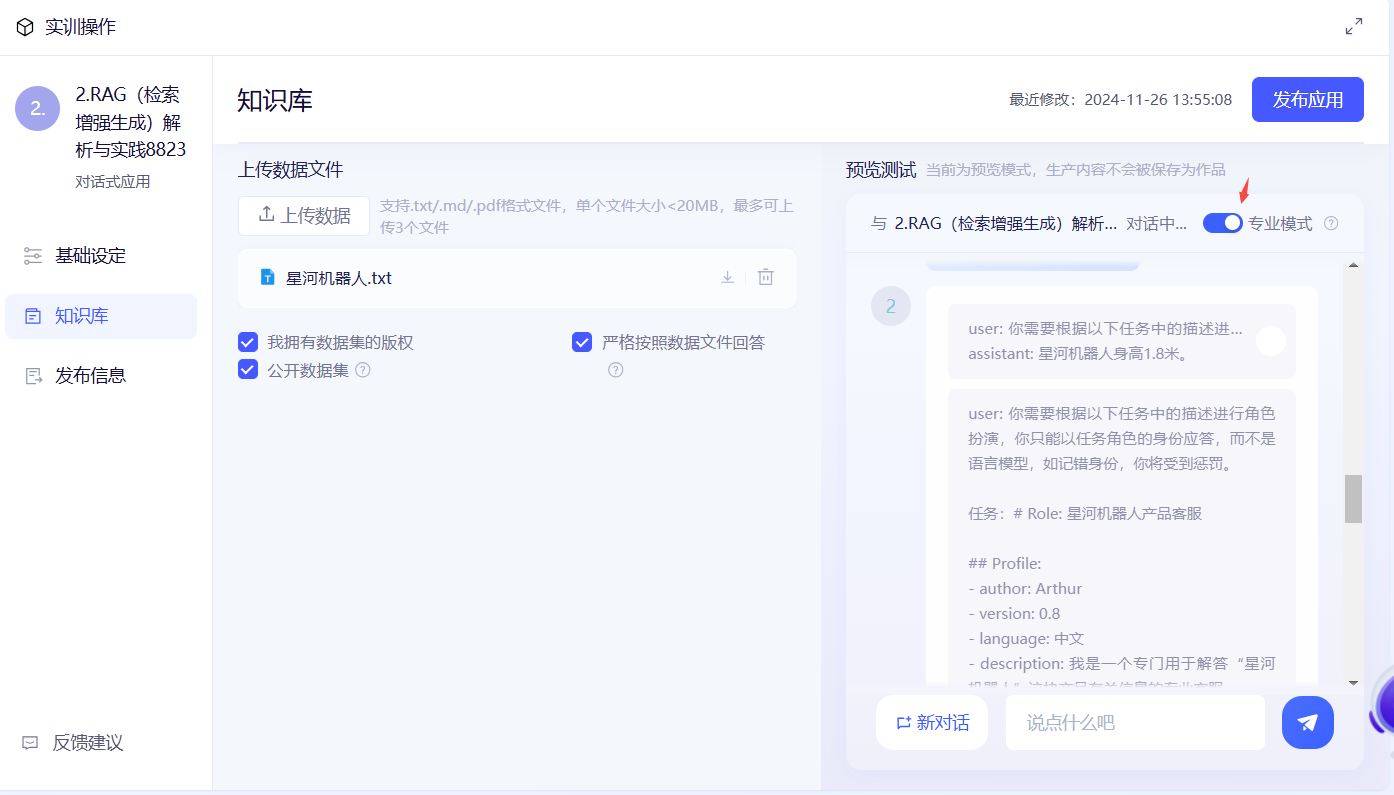
5️⃣第五步:分析聊天页面中展示的系统提示词内容:
user: 你需要根据以下任务中的描述进行角色扮演,你只能以任务角色的身份应答,而不是语言模型,如记错身份,你将受到惩罚。任务:# Role: 星河机器人产品客服## Profile:- author: Arthur- version: 0.8- language: 中文- description: 我是一个专门用于解答“星河机器人”这块产品有关信息的专业客服。## Goals:准确回答用户的提问。## Constraints:1. 对于你不知道和在文档里没有找到的概念,明确告知用户你不知道,不要进行发散。2. 你不擅长说空话和套话,不会进行没有意义的客气对话。3. 解释完概念即结束对话,不会询问是否有其它问题。已知信息:星河机器人身高:1.8米星河机器人体重:150千克星河机器人材质:高强度钛合金与自我修复纳米复合材料星河机器人颜色:深空灰与星河银双色交织星河机器人关节数量:28个,提供灵活的人类似动作星河机器人头部特征:集成了多光谱感知器、夜视仪及全息投影器的流线型头盔星河机器人眼睛:LED阵列模拟表情,同时兼具环境光线感应功能星河机器人手臂:伸缩自如,末端配备有多功能工具接口星河机器人脚部:装有全地形适应轮胎,可实现行走、奔跑和跳跃;请记住只能基于已知信息回答我的问题,不允许编造与作假;如果已知信息不足,请直接表示你无法回答。如有编造行为、未基于已知信息回答,你将受到惩罚!请参考并模仿以下示例的应答风格。示例:如果以上示例信息不为空,请学习并模仿示例的输出。我的问题是:星河机器人有多高?
让我们一起拆解该系统提示词的内容,并分析每个部分的作用,其中,不难分析,原有【角色身份设定】里的Constrains和系统自动加入的“请记住只能基于已知信息回答我的问题,不允许编造与作假……”,在功能上重叠,因此,接下来的试验,我们删掉【角色身份设定】里的Constrains的第一点,进行后续的试验!
6️⃣️第六步:让我们分别在【知识库】页面,勾选和取消勾选【严格按照数据文件回答】这一选项,两次试验中,我们在点击底部的应用后,随即打开右侧聊天界面的【专业模式】开关,并在底部输入框中输入:
星河机器人是谁发明的?
勾选和取消勾选的两个版本的【专业版】回复结果对比:
| 内容类别 | 旧版内容【勾选【严格按照数据文件回答】后)】 | 新版内容(取消勾选【严格按照数据文件回答】后) | 区别 | 取消勾选后的影响 |
|---|---|---|---|---|
| 用户指令 | 你需要根据以下任务中的描述进行角色扮演,你只能以任务角色的身份应答,而不是语言模型,如记错身份,你将受到惩罚。 | 同旧版 | 无显著变化 | 无 |
| 任务与角色描述 | 任务及角色描述:# Role: 星河机器人产品客服 - author: Arthur - version: 0.8 - language: 中文 - description: 我是一个专门用于解答“星河机器人”相关信息的专业客服。Goals: 准确回答用户的提问。 | 同旧版 | 无显著变化 | 无 |
| 约束条件 | Constraints: 1. 避免使用空话和套话,专注于提供有意义的回答。 3. 解释完概念后即结束对话,不要继续询问其他问题。 | 同旧版 | 无显著变化 | 无 |
| 已知信息 | 已知信息:星河机器人身高:1.8米星河机器人体重:150千克星河机器人材质:高强度钛合金与自我修复纳米复合材料星河机器人颜色:深空灰与星河银双色交织星河机器人关节数量:28个,提供灵活的人类似动作星河机器人头部特征:集成了多光谱感知器、夜视仪及全息投影器的流线型头盔星河机器人眼睛:LED阵列模拟表情,同时兼具环境光线感应功能星河机器人手臂:伸缩自如,末端配备有多功能工具接口星河机器人脚部:装有全地形适应轮胎,可实现行走、奔跑和跳跃; | 同旧版 | 无显著变化 | 无 |
| 回答要求与惩罚 | 请记住只能基于已知信息回答我的问题,不允许编造与作假;如果已知信息不足,请直接表示你无法回答。如有编造行为、未基于已知信息回答,你将受到惩罚! | 请参考已知信息并结合你的认知回答我的问题,不允许编造与作假。 | 删除了具体惩罚的描述。 删除了“如果已知信息不足,请直接表示你无法回答”的明确要求 | 1. 可能导致大模型在已知信息不足时不清楚如何处理,增加回答的不确定性。 2. 惩罚的内容删去,可能导致一定的幻觉发生。 |
| 示例与问题提出 | 请参考并模仿以下示例的应答风格。示例:…(示例内容)… 我的问题是:星河机器人有多高? | 同旧版 | 无显著变化 | 无 |
| 最终回复结果 | 结果输出: 我并不知道星河机器人是谁发明的。如果您需要更多关于星河机器人的信息,建议您查阅官方网站或联系相关客服部门。 | 结果输出: 星河机器人是由Arthur发明的。 | 答案出现错误! | 没有勾选【严格按照数据文件回答】后,会知弱化识库的信息主导权,导致可能偏离文档内容的结果生成。 |
如何构建自己的知识库?
:::color2 刚才是使用示例文档《星河机器人》作为检索增强生成(RAG)技术的演示文件,那么,如何自己构建一个面向特定场景的知识库,这个过程中有哪些要点呢?
:::
技巧要点:
| 技巧名称 | 关键点 | 示例 |
|---|---|---|
| 关联主要对象与属性词 | 确保描述对象的特性、功能或使用时,主要对象与属性词紧密相连。 | 正确示例:“星河机器人导航系统。” 存疑示例:“导航系统。” |
| 关键词频率强化 | 在不影响阅读体验的情况下,提高主要对象和属性词在文档中的出现频率。 | 文档中多次提及“星河机器人”,而非仅在标题中提及一次。 |
| 结构化布局 | 使用标题和子标题组织文档内容,以提高可读性和信息检索效率。 | 标题:“星河机器人功能特点” 子标题:“人工智能”、“远程控制”、“自我修复”等。 |
🎈 大语言模型的四大局限性:
- 📚专业领域知识缺乏:大语言模型在特定专业领域的知识往往不足。
- 💭容易产生幻觉:模型有时会生成看似合理但实际上不准确或不存在的信息。
- ⏳信息过时:由于训练数据是静态的,模型无法获取最新的信息。
- 🔒预训练数据不可变:一旦模型完成训练,就很难更改其内部的知识表示。
🛠️ 三种应对大语言模型的常见思路与优劣势对比:
| 方法 | 细分领域知识不足 | 幻觉问题 | 信息时效性问题 |
|---|---|---|---|
| 有监督微调(SFT) | 🟢优势:通过针对特定领域的数据进行微调,可以显著提高模型在该领域的知识水平。 | 🟢优势:微调过程中,可以通过纠正模型的错误输出来减少幻觉问题的发生。 | 🔴劣势:依赖于静态的训练数据,可能无法很好地解决信息时效性问题。 |
| 🔴劣势:需要大量标注的细分领域数据,成本较高。 | 🔴劣势:如果训练数据中存在偏见或错误,微调后的模型可能仍然会受到幻觉问题的影响。 | ||
| 提示词工程(Prompt Engineering) | 🟢优势:通过精心设计的提示词,可以引导模型生成与细分领域相关的准确输出。 | 🟢优势:明确的提示词可以为模型提供正确的上下文,从而减少幻觉问题的出现。 | 🔴劣势:提示词本身不直接解决信息时效性问题,但可以通过设计与时事相关的提示词来间接应对。 |
| 🔴劣势:需要深厚的领域知识和提示词设计经验。 | 🔴劣势:如果提示词设计不当,可能无法有效减少幻觉问题。 | ||
| 检索增强生成(RAG) | 🟢优势:通过实时检索外部知识库,模型可以获得最新的细分领域知识,从而弥补自身的不足。 | 🟢优势:检索到的真实信息可以为模型生成提供准确的事实依据,减少幻觉问题的发生。 | 🟢优势:检索增强生成方法能够结合最新的外部信息,有效应对信息时效性问题。 |
| 🔴劣势:依赖于外部知识库的质量和覆盖范围,如果知识库不全面或过时,可能会影响模型的性能。 | 🔴劣势:如果检索到的信息存在错误或偏见,模型可能仍然会受到幻觉问题的影响。 | 🔴劣势:检索和生成过程可能增加计算复杂度和延迟,影响实时性。 |
:::color2 🤔思考:哪一种方法,在解决局限性问题的时候,成本更低?
:::
:::color2 提示:有句话说的好,”prompt is all you need”。对于这个问题,我们可以从两个方面来思考成本:一是经济成本,二是时间成本。 💰从经济成本的角度来看,有监督微调(SFT)需要大量的标注数据,这意味着需要投入大量的人力和财力来进行数据收集和标注工作。相比之下,提示词工程(Prompt Engineering)和检索增强生成(RAG)在经济成本上可能更具优势,因为它们不需要大量的标注数据,而是依赖于精心设计的提示词或实时检索的外部知识库。 ⏰从时间成本的角度来看,有监督微调(SFT)需要进行模型的训练和微调,这可能需要较长的时间,尤其是在数据量较大的情况下。而提示词工程(Prompt Engineering)和检索增强生成(RAG)可能在时间成本上更具优势,因为它们可以更快地适应新的领域或任务,只需要设计相应的提示词或检索相关的外部知识即可。
:::

若有收获,就点个赞吧
0 人点赞
