11月05日@凯佳er
背景
知识学习通常是总分总的形式推动,先了解整体方向之后再做细化。本篇是基于AI的开源应用项目来对AIGC领域的技术做整体性的了解,包括业务、技术栈、技术名词等等。目的是快速学习相关的基本知识,为此找到一些可了解的开源应用,可以先本地部署跑起来理解大致的方向。
有一些example,后续再可以做了解:
- Speech and Audio Field 语音和音频领域:flinkerlab/neural_speech_decoding
- Humor Generation 讲幽默笑话: CLoT
- Animation Field 动漫领域:SaaRaaS-1300/InternLM2_horowag
- Food Field 食品领域:SmartFlowAI/TheGodOfCookery
- Tool Learning 工具学习:ToolBench
- Autonomous Driving Field 自动驾驶领域:DriveVLM
- …
开源项目
这次寻找的是业务方向是基于开源项目构建属于自己的私域知识库问答系统,先来看行业项目的通常解决方案。
共两种:
1. 一是用私域数据在开源模型上进行训练微调2. 二是结合向量检索,将专业领域知识和原始提问转化为向量,再使用通用大语言模型进行回答。
这两种方式各有利弊,基于开源模型训练微调存在成本高,包括机器成本和人力成本,另外时效性也较差,但是数据安全性更高;而第二种基于向量检索的形式,工程上需要做的工作比较多,需要文档切片,向量存储,向量检索等技术,同时需要跟通用大模型进行交互,所以会有一些数据安全风险以及一些 Token 额度的消耗。
目前来看,方案二形成了很多行业解决方案,包括云上产品以及一些开源项目,这里介绍一个开源项目 DialoqBase。这是一个开源应用程序,旨在通过使用个性化知识库来促进定制聊天机器人的创建。该应用程序利用先进的语言模型生成准确和上下文感知的回复。此外,它利用 PostgreSQL,用于高效的向量搜索操作和存储知识库。
DialoqBase
项目地址:https://github.com/n4ze3m/dialoqbase(部署方式查看readme,访问:http://localhost:3000)
- 创建对话的robot
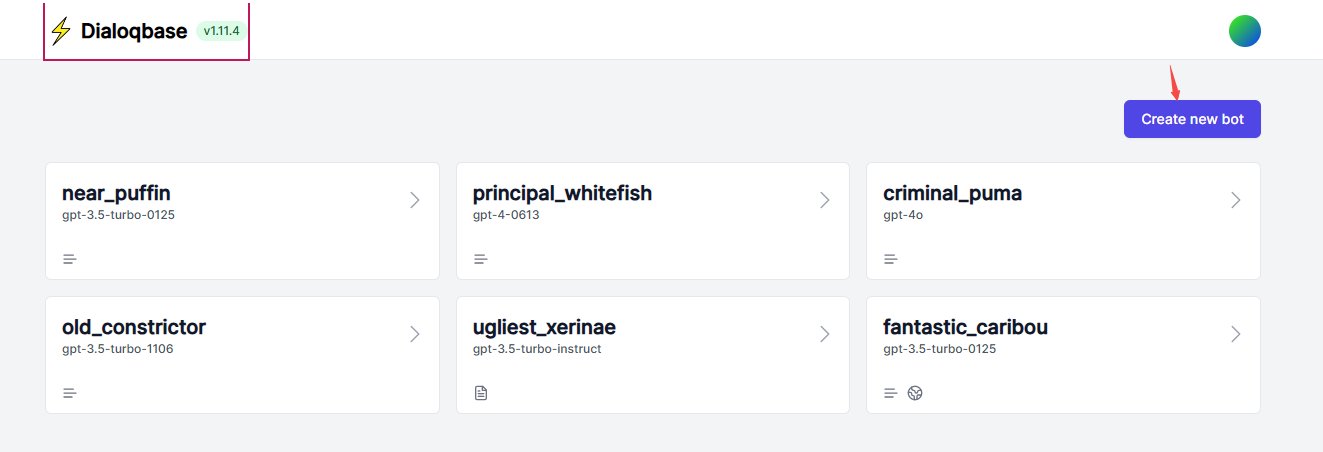
- 创建的时候可以选择数据源,这里的数据源就是私域知识库,知识库的类型有很多中,可以是一个网页,可以是一段文本,也可以是一个文件,或者是爬虫等。数据源内容的多少决定了 Embedding 的时间长短,以及对应 Embedding 模型 Token 的消耗多少。
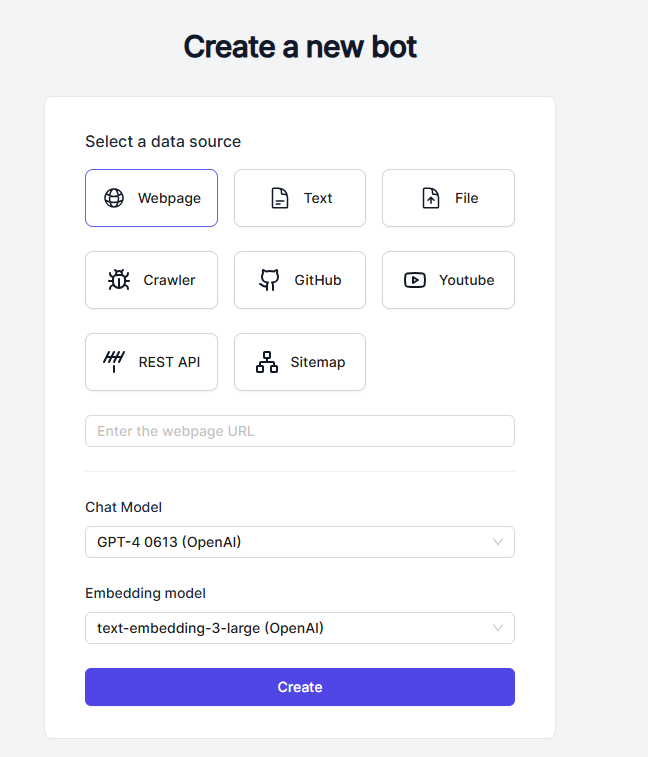
- 接下来再选择一个需要进行交互的 Chat Model,支持 OpenAI 和 Claude 的模型。
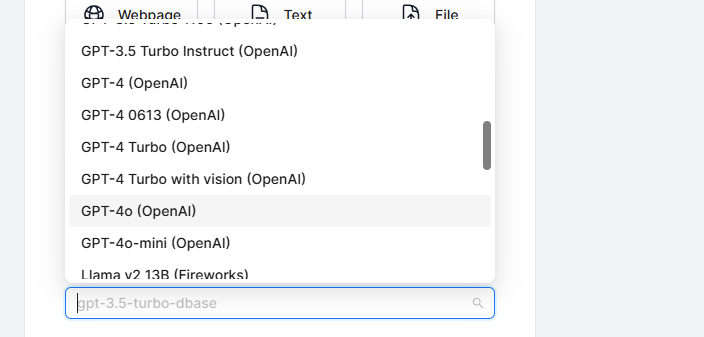
- 接下来再选择 Embedding 模型,目前支持的有下面这些。注意对于创建的一个 Bot 来说,Embedding 模型一旦选择过后是不能进行修改的。

- 创建完成过后会进入到 Playground 模块,如果前面增加了 DataSource 的话,这里就可以直接进行问答了,如果没有增加 DataSource 的话,可以在左侧的 DataSource 模块进行添加,支持添加多个。

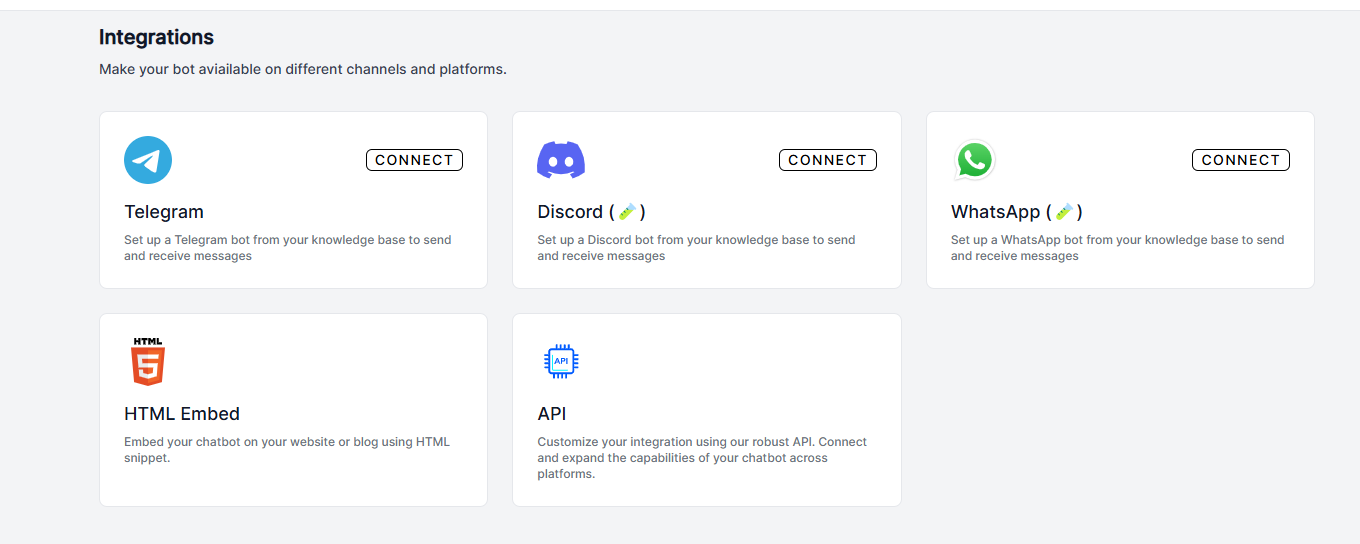
- 可以将文章作为数据源添加测试,DialoqBase 还支持集成到一些社交软件中。
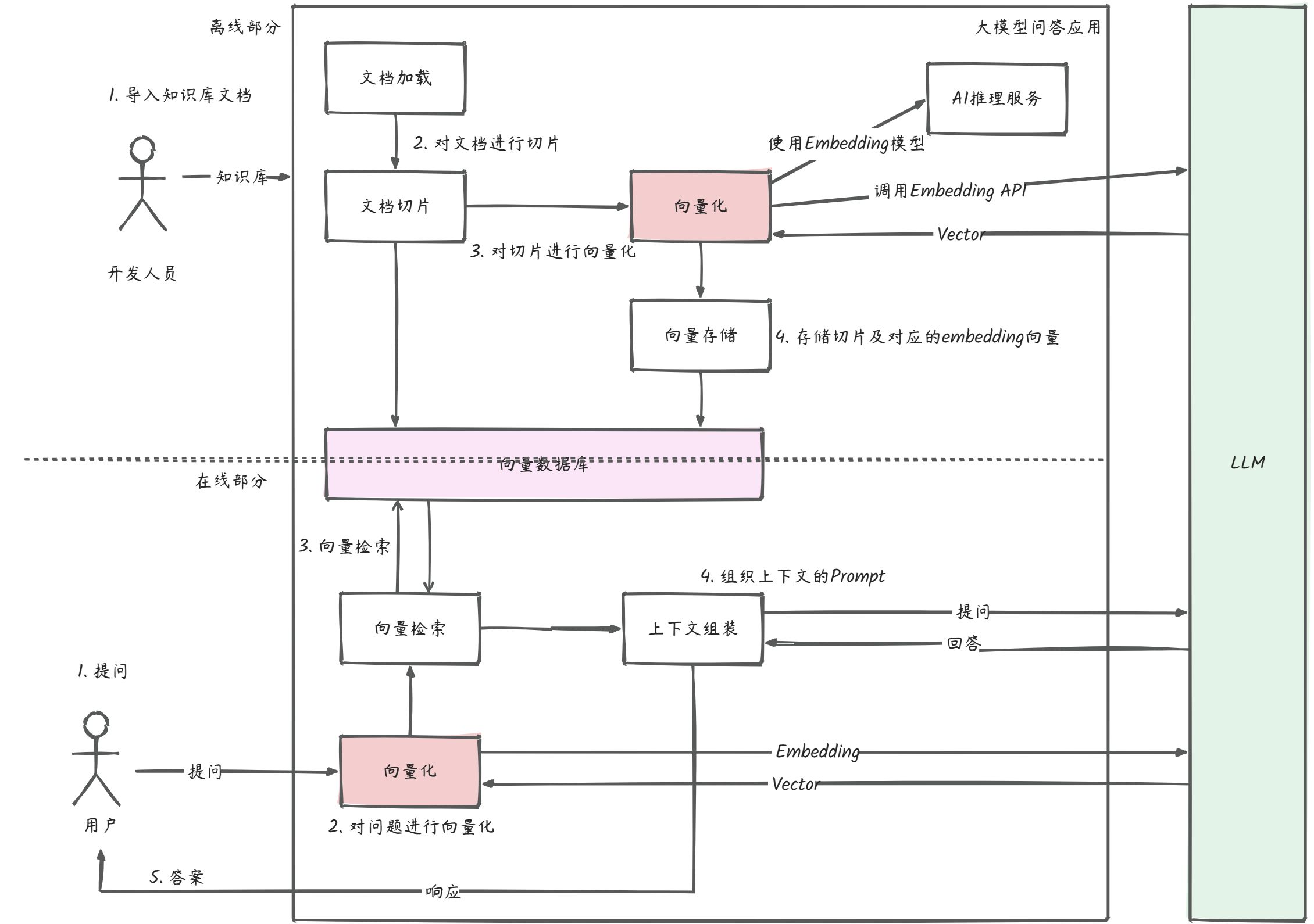
项目架构
先来看看整体流程。这个流程中向量化的过程以及问答的时候都会涉及到跟大模型进行交互,而消耗的 token 跟上下文的内容的大小都有关系。
简单来说就分两步,一个是对文档的向量化并做持久化,二是对提问做向量化再组织提示词和大模型交互。
随着行业发展这种方案形成了很多框架,其中很著名的就是 LangChain。如果自己想实现的话,也可以使用 LangChain 来实现上述的整个流程。那LangChain具体是什么?
LangChain
LangChain是一个框架,用于开发由LLM驱动的应用程序。可以简单认为是LLM领域的Spring,以及开源版的ChatGPT插件系统。核心的2个功能为:
- 可以将 LLM 模型与外部数据源进行连接。
- 允许与 LLM 模型与环境进行交互,通过Agent使用工具。
地址:GitHub - langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications
下图是根据一些LangChain的一些资料画出来的一张整体架构图,可以看到,它具体分了六个部分,分别是:Models、Prompts、Indexes、Memory、Chains、Agents。(组件里有标颜色是预备后面重点了解一下的内容)
LangChain 的六个组件可以分为以下几个层次:
- 数据层(Indexes 和 Memory):负责存储和检索数据,保证上下文的连贯性。
- 模型层(Models 和 Prompts):直接与 LLM 交互,提供标准化的接口和提示设计。
- 流程控制层(Chains 和 Agents):负责控制任务执行的逻辑和顺序,能够灵活地调整操作流程。

Models
架构的核心,负责和底层的语言模型进行交互的。抽象了各种语言模型(包括 OpenAI 的 GPT-3/4、Cohere、Hugging Face 等)的接口,以统一的方式处理多种模型。
这里models组件分了3个部分:Chat Models、Embedding、LLMs
Chat Models就是支持一些消息类型:AIMessage、HumanMessage、SystemMessage 和 ChatMessage。它还支持批处理和结果的缓存。
Embedding 就是用于文本数据的总结和问答,一般和向量库一起使用,实现向量匹配。其实就是把文本等内容转成多维数组,可以后续进行相似性的计算和检索。
LLMs就是大语言模型了,这个官网有支持清单。使用基本上就是import不同的 SDK 连接到不同 LLM 提供商,用API 密钥取调用。
Prompts
专注于如何为语言模型设计合适的提示(Prompt),因为模型的输出质量很大程度上取决于输入提示的设计。这个就是可以帮开发创建高效的提示,引导模型生成所需的输出。
它包含了 Prompt Templates、Few-shot example、Example Selector,支持参数化提示,简化了复杂提示的生成。
可以将固定的模板与动态内容组合,生成灵活的提示。例如,系统可根据上下文生成问题的前缀或参数化内容。
Indexes
旨在管理和组织数据,使语言模型能够有效地在大规模数据集上查找信息。个人理解和sql的索引类似。就是把文档进行结构化,以便 LLM 能够更好的与之交互。这个组件主要包括:Document Loaders(文档加载器)、Text Splitters(文本拆分器)、VectorStores(向量存储器)以及 Retrievers(检索器)。
创建数据索引,支持在大型文本库中快速检索相关内容。包括向量索引、倒排索引、文本分块等,用于处理结构化和非结构化数据。通过将文本数据向量化存储,可以使用向量数据库(如 Pinecone、Weaviate、FAISS)进行快速检索。
Memory
其实是为了让 LLM 具有“记忆”功能,使其能够在会话中保持上下文连续性。
如果我们一直聊天,发送的内容越来越多,可能就碰到 token 的限制。memory的话可以带着上下文保留最近几次的聊天记录。
langchain 提供了不同的 Memory 组件完成内容记忆,可以保存和检索上下文信息,支持短期和长期记忆,各个组件记忆策略都不一样,这些可以在图中看到。
重点看下VectorStoreRetrieverMemory,它是将所有之前的对话通过向量的方式存储到 VectorDB(向量数据库)中,在每一轮新的对话中,会根据用户的输入信息,匹配向量数据库中最相似的 K 组对话。也就是可以把记忆存储在本地或外部数据库中,通过算法控制记忆的生命周期和使用范围。
Chains
链是一种用于连接多个模型调用的机制,使得开发者可以通过流水线方式实现复杂的任务。链允许我们将多个组件组合在一起以创建一个单一的、连贯的任务。
例如,我们可以创建一个链,它接受用户输入,使用 PromptTemplate 对其进行格式化,然后将格式化的响应传递给 LLM。另外我们也可以通过将多个链组合在一起,或者将链与其他组件组合来构建更复杂的链。
它支持顺序执行、条件执行和循环调用,可以在链的不同步骤间传递信息。可以将不同的 Prompt、模型调用、API 请求等串联起来,完成类似“问题->搜索->生成答案”这样的复杂任务。
Agents
Agents 是 LangChain 中最灵活的组件,它们可以根据上下文自由选择调用哪个链或模型,实现更复杂的决策逻辑。个人理解它类似与GMP模型中的Processor,动态编排调用模型的。
一些应用程序需要根据用户输入灵活地调用 LLM 和其他工具的链。代理接口为这样的应用程序提供了灵活性。代理可以访问一套工具,并根据用户输入确定要使用哪些工具。我们可以简单的理解为他可以动态的帮我们选择和调用 chain 或者已有的工具。代理主要有两种类型 Action agents(行为代理: 在每个时间步,使用所有先前动作的输出来决定下一个动作) 和 Plan-and-execute agents(预先决定完整的操作顺序,然后执行所有操作而不更新计划)。
作为一个智能代理,能够根据环境和任务动态选择模型和链条,适用于需要自适应的应用场景。包含动作决策逻辑,支持使用工具(例如数据库查询、外部 API 调用)来完成复杂任务。通过结合不同的模型调用、提示、索引和内存模块,Agents 能够根据需求动态执行不同的操作。
技术名词解释
Milvus
Milvus 是一个开源的 向量数据库管理系统,专门为 非结构化数据(如文本、图像、视频等)而设计。它特别适合用于 高维向量检索,通常应用在 AI 和 机器学习 领域,用于处理和存储 Embedding 向量。
Milvus 支持高效的向量检索算法,能够处理大量数据并进行快速的相似性搜索。它的典型应用场景包括 推荐系统、自然语言处理 和 图像识别 等领域。
Hugging Face
Hugging Face 提供了一个开源的机器学习平台和大量的预训练模型,如 Transformer 模型(BERT、GPT-2、T5 等)。Hugging Face 拥有一个称为 Transformers 库 的 Python 库,为开发者提供了便捷的工具,用于加载和微调各种预训练的 NLP 模型。
地址:Hugging Face
此外,Hugging Face 也为开发者提供了一个模型库和数据集库,方便使用、共享和训练 AI 模型,极大地简化了 NLP 开发的流程。
Vector
Vector(向量)在数学和计算机科学中指的是一组数字的有序集合。在 AI 和机器学习中,向量通常用于表示数据的特征或嵌入。例如,一段文本、一个图像、一个视频片段可以被转换为向量表示,以便机器进行处理和分析。
向量可以被看作是在高维空间中的一个点,向量之间的距离表示了它们的相似性。这种表示方法在 相似性搜索、推荐系统 和 聚类分析 中非常重要。
LLM(Large Language Model)
LLM 指的是 大语言模型,例如 GPT-3、GPT-4、BERT 等,它们通常由数十亿到数千亿个参数构成,具备对自然语言进行生成、理解、翻译等多种任务的能力。
地址:GitHub - run-llama/llama_index: LlamaIndex is a data framework for your LLM applications
LLM 通过在海量文本数据上进行训练,学习到语言的复杂模式和结构,并可以执行各种自然语言处理任务。大语言模型在对话系统、文本生成、问答系统和信息提取等应用场景中具有广泛应用。
本文参考链接
- 中文教程:https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng
- 官方:https://python.langchain.com/docs/introduction/
- 其他:https://juejin.cn/post/7355525978594983988
- 代码走读:https://mp.weixin.qq.com/s/bYzNNL3F0998Do2Jl0PQtw
- …
其他问题
- GPU的相关知识,HAMI(Huawei AI Matrix Interface),卡的拆分,多卡使用(TODO)

若有收获,就点个赞吧
0 人点赞
