基础知识篇:深度学习模型训练与部署
lesson2️⃣ 了解深度学习平台:飞桨PaddlePaddle
上一节课中我们学到,人工智能背后是由复杂的数理知识和数值计算支撑的,对于传统(人工规则)算法,要求程序员显式写出每一行代码来实现这些数值计算,对于编程能力的要求是很高的。深度学习框架带来了一场开发流程的巨大变革,为程序员提供基础计算组件和执行 API,程序员只需通过代码定义神经网络结构,由深度学习框架自动构建计算图与优化参数求解,部署模型实现对新数据的推理预测。
大模型时代对深度学习框架提出了更高的要求。首先,深度学习模型参数规模从 Million(百万)跨入了 Billion(十亿)时代,以13B(130亿)参数的模型为例,训练需要的显存空间 > 230GB(包括参数、梯度、优化器状态、中间变量等存储),即至少需要 V100 32GB 8卡资源才能支撑计算。其次,大模型需要大数据来训练,大语言模型的训练数据量达到了 T tokens(万亿)级别,1T tokens 对应3~5TB的语料存储,相当于135万本《哈利·波特与魔法石》。最后,训练/推理模型需要超大算力规模,据公开数据显示,文心大模型4.0基于万卡规模算力训练。面向大模型的深度学习平台进一步简化神经网络开发工作,增强分布式计算能力,大幅降低领域标注数据规模要求,基于大模型微调及提示词构建低代码开发工具链。
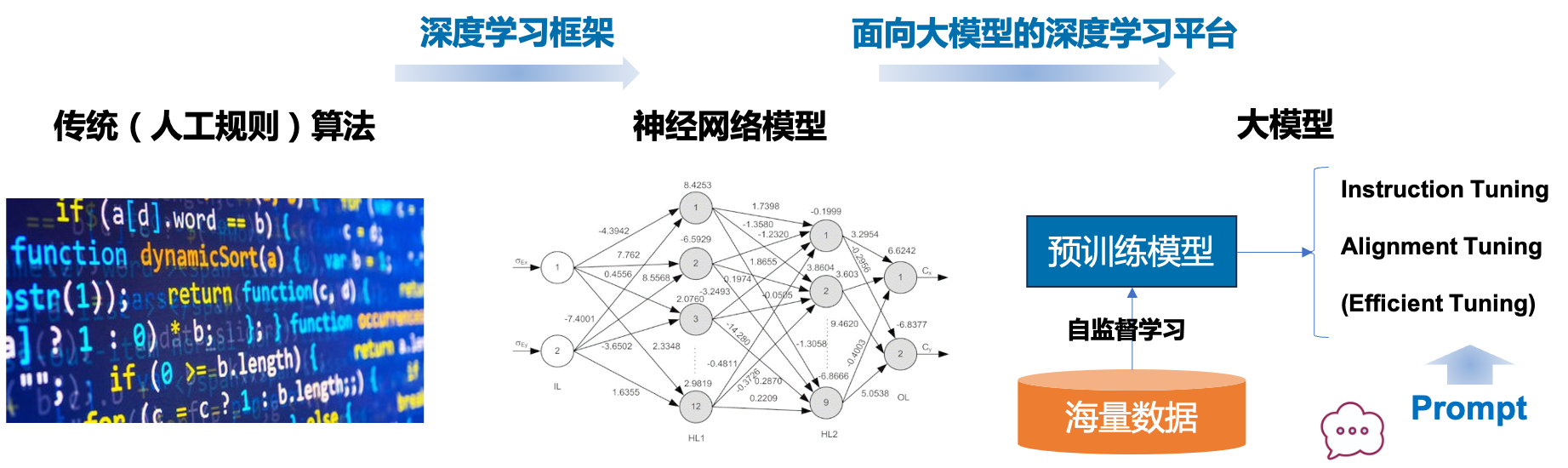
飞桨 PaddlePaddle 以百度多年的深度学习技术研究和业务应用为基础,是中国首个自主研发、功能完备、开源开放的产业级深度学习平台,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体。飞桨助力开发者快速实现AI想法,快速上线AI业务。帮助越来越多的行业完成AI赋能,实现产业智能化升级。

模型训练
AI 模型训练是一个复杂的过程,即使有深度学习框架的为我们解决了训练中复杂的计算图构建和优化问题,不同的训练数据集、算法模型结构、参数设置、优化方向和训练策略仍旧会对 AI 模型产生至关重要的影响。
为了进一步降低模型训练的操作门槛,飞桨基于核心框架构建出数十个开源的端到端开发套件,包括自然语言处理套件 PaddleNLP、跨模态大模型套件 PaddleMIX、文字识别套件 PaddleOCR、图像分类套件 PaddleClas、目标检测套件 PaddleDetection、图像分割套件 PaddleSeg 等,汇聚各领域的热门模型,并提供从训练到推理的全流程代码库,使得开发者能以更加高效的方式进行 AI 模型训练。
模型部署
通常我们会按照 AI 任务的应用场景差异来划分不同的部署场景,如人脸识别任务需要部署在端侧,而个性化推荐任务则需要部署在服务器侧。AI 模型部署主要可以分为服务器侧部署和边缘端侧部署两大类。在各自的类别下,开发者可以根据 AI 应用场景的个性化差异,细化成更多的分支方案。无论哪种细分场景,飞桨都提供了相应的工具支撑,具体如下:
1)高性能的数据中心场景:性能强大,追求高精度模型和高并发、实时响应的服务质量。
- 模型融入业务系统:业务系统本身是一个服务架构,某个环节依赖模型实现。
- 模型独立作为服务:模型的预测服务可以直接被其它模块在线调用,可以把模型单独部署为一个服务 API 调用。
2)端侧场景:模型大小和性能受限于硬件能力,需要使用更轻量的网络结构并进行模型压缩。
- 移动端场景:模型部署在 APP/H5 小程序中,需要更小的模型体积和更快的模型推理速度。
- 物联网场景:如工控机、工业相机等处于生产线和智能设备,要求离线推理。
学习提示 🐝恭喜你完成了本节课程的学习!在这节课程中,我们学习到深度学习框架和平台对深度学习模型开发的重要性,以及大模型时代对深度学习平台提出了新的要求。飞桨 PaddlePaddle 正是其中之一。使用框架进行开发虽然已经大大降低了对编程能力的要求,但仍要求开发者具备基础的 python 语言使用和调试能力。有没有更加简单易上手的开发工具?下一节我们将会学习基于飞桨框架的低代码开发工具 PaddleX,及其与星河社区结合的交互平台——零代码产线。

若有收获,就点个赞吧
0 人点赞
