基础知识篇:深度学习模型训练与部署
lesson3️⃣ 开启产业级深度学习模型开发之旅
上一节课中我们了解到飞桨 PaddlePaddle 深度学习框架大大降低了开发深度学习模型对编程能力的要求,但仍要求开发者具备基础的 python 语言使用和调试能力。为了进一步降低模型开发和部署的门槛,低代码开发工具 PaddleX 应运而生。
PaddleX 是一个飞桨全流程开发工具,以低代码甚至零代码的形式支持开发者快速实现产业实际项目落地。星河零代码产线是 PaddleX 的云端产品形态,通过图形交互界面点选的方式即可完成产业级模型开发,并支持在线和离线部署。

我们首先通过一段视频,快速掌握如何使用 PaddleX(星河零代码产线)四步完成模型训练,两步完成模型部署。
立即体验 - 飞桨星河零代码工具:https://aistudio.baidu.com/pipeline/mine
🎈零代码产线详解
- 精选模型汇聚:为满足产业实践在模型效率与效果上的双重要求,新版本聚焦7大领域的39个飞桨优质模型,汇聚为16条模型产线,高效解决不同领域的业务需求。
- 便捷的任务作业:提供基于图形用户界面(GUI)的任务提交,旨在简化资源启动的步骤,使之更为直接和轻松。
- 新增在线部署:除了离线部署到本地,本次升级新增支持模型在线部署到飞桨星河社区,满足模型更多的使用场景。
- 模型产线重构:提供从数据到部署的完整AI开发体验,仅需6步即可完成全流程开发。


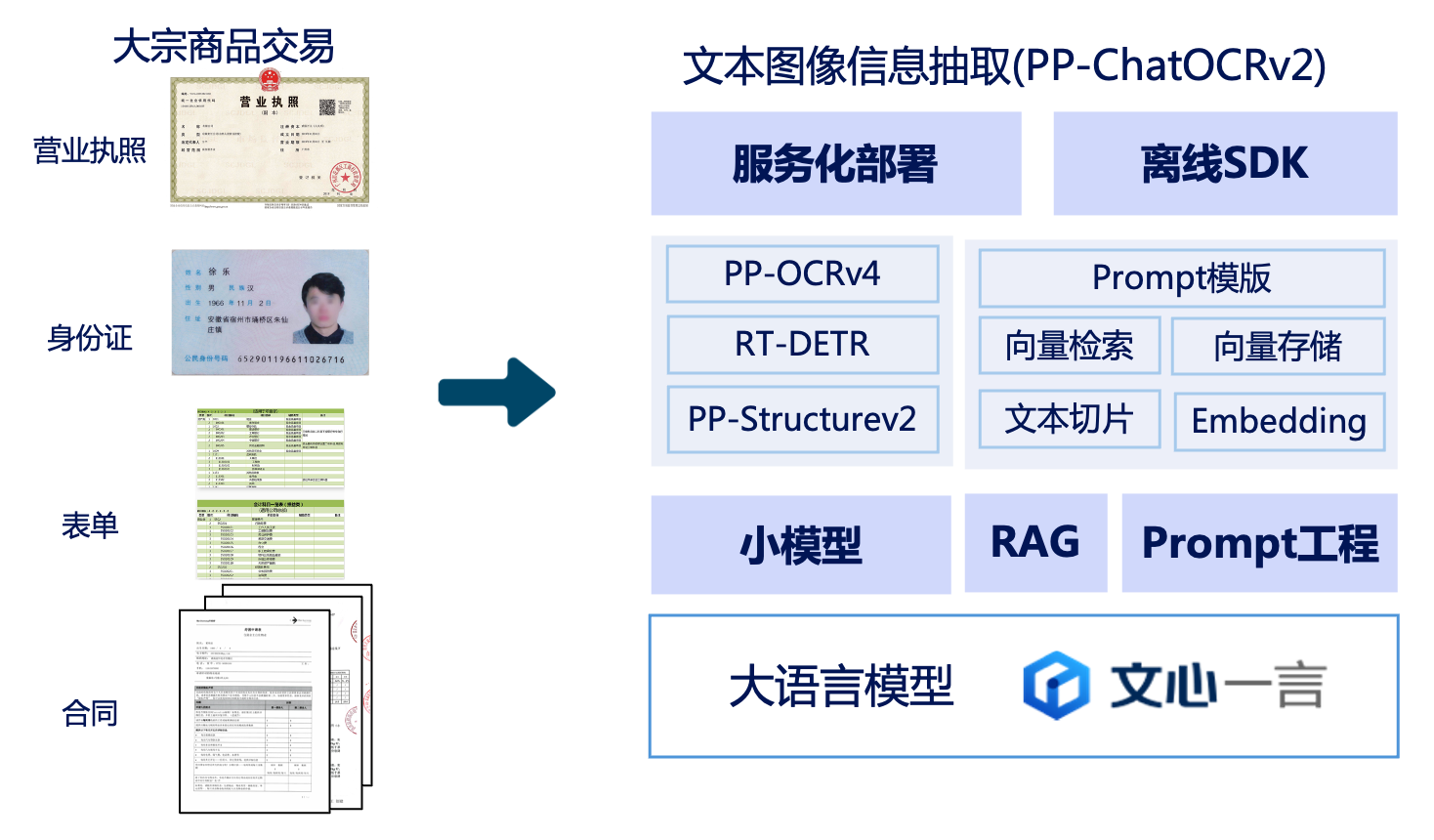
🤖 特色模型产线 - 文档图像信息抽取 PP-ChatOCRv2
文心一言与 PP-OCR 强强结合的通用文本图像智能分析系统,一站式解决包括生僻字、表格和多页 PDF 等复杂场景的各类 OCR 信息抽取问题。PP-ChatOCRv2 针对多种需求场景提供了不同的模型产线,可以点击链接跳转应用体验模型功能:
通用场景信息抽取 | 文档场景信息抽取 | 通用OCR | 通用表格识别

结合了 LLM 和 OCR 技术,文心大模型将海量数据和知识相融合,准确率高且应用广泛。
学习提示 🐝恭喜你完成了本节课程的学习!在这节课程中,我们学习到如何借助星河零代码产线低门槛进行产业级深度学习模型训练与部署,并了解到其背后的低代码开发工具 PaddleX。现在,你已经掌握了基础知识篇,下一章我们会从产业实践的角度进行一些进阶的开发经验分享,正式开启你的深度学习模型开发之旅!🤖✨

若有收获,就点个赞吧
0 人点赞
