本节课主要内容:
① 计算机视觉四类任务
② 对目标检测算法的原理进行学习
③ 人脸墨镜特效的原理学习
(1) 计算机视觉四类任务
四大任务:图像分类、目标定位、目标检测和图像分割
① 图像分类
图像分类是给定一张图片,直接判断图像里包含什么类别的目标,解决“是什么”的问题。
② 目标定位
目标定位则是给定一张图片,可以将目标的位置找出来,解决”在哪里“的问题。
小疑惑:如果不知道是什么物体,那模型怎么知道这里可能有个目标对象?还是说先给定模板,然后去图中找模板出现的位置?那这就是模板匹配问题了。
③ 目标检测
然而目标检测,是在目标定位的基础上进一步升级。既要定位出图片上所有目标的位置,也要输出目标的类别。解决的“是什么?在哪里?”的问题。
该算法应用广泛,是很多项目的前置任务。
④ 图像分割
图像分割这个方向,在生活中也是很重要的应用方向,主要解决“每一个像素是什么”的问题。【这个是基于像素的分类问题,本质还是分类】
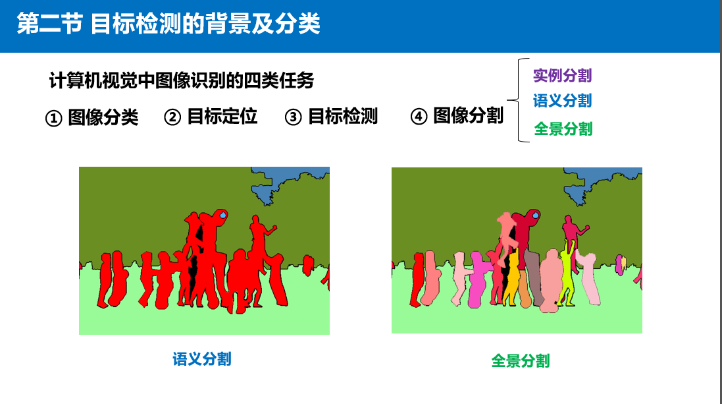
分割算法还分为三种:实例分割、语义分割、全景分割。
- 通过实例分割,我们可以区分出不同的个体。(忽略背景类)
- 语义分割只能判断类别,无法区分个体。(将背景与不同对象分别分割出来,并用不同的颜色进行可视化)
- 全景分割是实例分割和语义分割的结合,当出现一种类别中有多个实例的时候,会有不同的颜色进行区分。(在分割出不同类物体的前提下,针对每个物体用不同的颜色进行标注以作区分。)
(2) 目标检测
由于各类物体的外观,形状,姿态,加上成像时的光照,遮挡等因素的干扰,目标检测一直是计算机视觉领域非常具有挑战性的问题。
不过因为CV领域,各种项目的第一步都是目标检测,所以目标检测算法非常重要。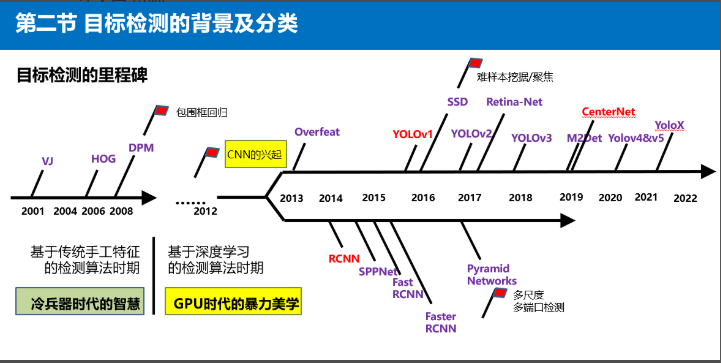
从图上可以看到,以中间黄色CNN卷积神经网络,为分水岭。
在2012年以前属于冷兵器时代,主导的算法主要是基于传统手工特征的检测算法。
而到了2012年之后,随着GPU的发展,图像数据的增加,开始进入GPU时代,主要通过大量数据深度学习来进行目标检测。
其中比较代表性的算法,就是YOLO系列,RCNN系列,这两种算法都是基于anchor锚框的。
不过这里简单的说一下,Yolo算法是端到端直接输出目标物体的位置和类别,属于One-stage算法。
而Faster-Rcnn算法属于Two-stage算法,主要分成两个阶段:
- 第一阶段首先产生候选区域,包含大量的可能存在目标的框。
- 然后第二阶段对候选区域进行分类和位置精修,因为有两步,所以属于two-stage算法。
而在19年以后,其实还产生了另一种无锚框的方式,以Centernet为代表,但因为也是直接输出目标物体的信息,因此也属于one-stage算法。
后面在2020年又出现了Yolov4、Yolov5目标检测算法。
大白的学习建议
a.视频方面
① 《 Yolov3相关算法的原理及实现(上)》链接: https://www.jiangdabai.com/video/%e5%8f%91%e5%b8%83%e8%a7%86%e9%a2%91%e6%b5%8b%e8%af%95-2-2-2-2-2-3② 《 Yolov3相关算法的原理及实现(下)》链接: https://www.jiangdabai.com/video/%e5%8f%91%e5%b8%83%e8%a7%86%e9%a2%91%e6%b5%8b%e8%af%95-2-2-2-2-2-2-3③ 《 Yolov4相关算法的原理及实现(上)》链接: https://www.jiangdabai.com/video/%e5%8f%91%e5%b8%83%e8%a7%86%e9%a2%91%e6%b5%8b%e8%af%95-2-2-2-2-2-2-2-3④ 《 Yolov4相关算法的原理及实现(下)》链接: https://www.jiangdabai.com/video/%e5%8f%91%e5%b8%83%e8%a7%86%e9%a2%91%e6%b5%8b%e8%af%95-2-2-2-2-2-2-2-2-2⑤ 《 RCNN相关算法的原理及实现(上)》链接: https://ke.qq.com/webcourse/index.html#cid=3454999&term_id=103592742&taid=11130734168553495&type=1024&vid=5285890816097062907⑥ 《 RCNN相关算法的原理及实现(下)》链接:https://ke.qq.com/webcourse/index.html#cid=3454999&term_id=103592742&taid=11130738463520791&type=1024&vid=5285890816097182436
b.文章方面
① 《深入浅出Yolo系列之Yolov4核心基础完整讲解》链接: https://zhuanlan.zhihu.com/p/143747206② 《深入浅出Yolo系列之Yolov5核心基础完整讲解》链接: https://zhuanlan.zhihu.com/p/172121380Yolov4和Yolov5都是2020年提出的,2021年旷视科技在此基础上,又发布了Yolox算法③ 《深入浅出Yolo系列之Yolox核心基础完整讲解》链接: https://zhuanlan.zhihu.com/p/397993315此外,大家如果有显卡的话,可以使用自有数据集,训练Yolox模型。④《深入浅出Yolox之自有数据集训练超详细教程》链接: https://zhuanlan.zhihu.com/p/397499216
(3)学习墨镜特效的原理
三个阶段实现该项目:
第一阶段:眼镜区域的算法处理
这一步的目的,是将眼镜从左图中抠取出透明图,这样才能便于在人脸图片上贴图。
所以第一步:先将彩色图像转换成灰度图像,便于通过灰度图进行阈值化处理。

若有收获,就点个赞吧
0 人点赞
