- lesson 01
- lesson 02
- 1、thop包中FLOPs只计算相乘的次数,忽略相加(计算速度快)
- 3、报错: Cannot find rule for
. Treat it as zero Macs and zero Params. - 4、报错: windows 环境下相对文件路径加载出错,(文件和文件夹层级关系是对的,./ 表示当前路径)
- 5、原resnet18权重文件大小为44.6M,当转为onnx时为44.5M,大小变化不大。但在yolov5中,将训练好的权重文件转为onnx时,大小减少将近一半,这是有点疑惑的。
- 6、resnet18的前面几个卷积层,明明设置了bias=False,为什么转成onnx做可视化后依然可以看到B?BtachNorm层也是有参数的,为什么onnx可视化后见不到BatchNorm层?
- lesson 03
- Lesson04
- Lesson05
答疑链接:https://docs.qq.com/doc/DWGh0c2NCQmNNU0tk](https://docs.qq.com/doc/DWGh0c2NCQmNNU0tk](https://docs.qq.com/doc/DWGh0c2NCQmNNU0tk
lesson 01
1、个人深度学习工作站配置
- 安装顺序:装系统——>装CUDA——>(装GPU-docker——>装conda)——>装python——>装pytorch
- 安装教程:大神稚晖君的“保姆级教程:个人深度学习工作站配置”,里面包含了装CUDA,装python和装pytorch。链接:https://zhuanlan.zhihu.com/p/336429888
- 其中:
2、pip与pip3有什么区别?
答:本质上没有区别,它们都是用于为python安装扩展库的快捷指令。
但是当python2.与python3.同时存在时,pip默认为2.进行安装。
在Linux中,可以通过修改软链接的方式,将pip指向python3,或者反过来。(在Linux中,用命令which pip试试)。
又或者使用官方的脚本get-pip.py修改pip指向的 python版本(该方法也适用于多版本python3.之间的转换)【还未尝试过】
3、cuda怎么下载之前的版本
答:登入官网,点击previous cuda releases
4、静态图与动态图的区别
答:参考链接: https://zhuanlan.zhihu.com/p/398156122
静态图需要先构建再运行,
- 优势是在运行前可以对图结构进行优化,比如常数折叠、算子融合等,可以获得更快的前向运算速度。
- 缺点也很明显,就是只有在计算图运行起来之后,才能看到变量的值,像TensorFlow1.x中的session.run那样。
动态图是一边运行一边构建,
- 成熟的框架或组件的接口通常都会屏蔽掉平台的差异,就像python是跨平台语言,所以(以python为基础的)pytorch在使用时没有太大差异。
- 但是python也确实 也存在Linux和Windows下不一样的库,如获取屏幕分辨率的接口。且在算法部署阶段,还会涉及到很多其他的与平台有关的基础库。
- 不过更推荐Linux,因为
- ① linux下深度学习开发的资料更多;
- ② 大部分边缘计算设备上只能运行linux;
- ③ linux更稳定更适合商用部署,命令行也更好用。
6、推理框架
答:目前的深度学习框架(pytorch,tensorflow等)在模型推理中速度都不理想。
推理框架能极大提高推理速度,推理框架有很多种,例如:Nvidia TensorRT、Intel OpenVINO、 NCNN等。这里以TensorRT为例子,pytorch训练模型转为onnx,测试无误再转为TensorRT的engine用来推理。
除了python用pytorch,C++用libtorch。
lesson 02
1、thop包中FLOPs只计算相乘的次数,忽略相加(计算速度快)
2、使用TensorRT这类推理框架,用python还是c++去实现,速度差别大吗?(这个题的回答没看懂)
https://forums.developer.nvidia.com/t/tensorrt-python-vs-c/66004
虽然是trt5,但是可以推出来 > trt5 版本python开销忽略不计。真正拉开距离的是trt以外的东西。当然你可以尝试用c++和python载入engine测试,可以好好思考下为什么忽略不计。
3、报错: Cannot find rule for . Treat it as zero Macs and zero Params.

答: warning not error. 激活函数不计入。
4、报错: windows 环境下相对文件路径加载出错,(文件和文件夹层级关系是对的,./ 表示当前路径)
FileNotFoundError: [Errno 2] No such file or directory: ‘./weights/mobilenet_v2-b0353104.pth’

 答: 把lesson2文件夹作为项目的根目录。另一个方法就是将当前路径设置为工作路径。
答: 把lesson2文件夹作为项目的根目录。另一个方法就是将当前路径设置为工作路径。
5、原resnet18权重文件大小为44.6M,当转为onnx时为44.5M,大小变化不大。但在yolov5中,将训练好的权重文件转为onnx时,大小减少将近一半,这是有点疑惑的。
答:torch保存的pt或者pth文件,不仅包含模型推理时需要的参数,还有其他一些“无效”参数。我举个简单的例子,如果我在class resnet18(nn.Module) 这个模型类的init部分,添加 self.layernew=nn.Conv2d(xxxxx),即使正向推理的forward函数并没有用到self.layernew 这个卷积层,torch.save保存时依然会将该层的权重保存进pt或pth,继而在model.state_dict()中找到。
而保存为onnx时,我们是要用一个dummy inputs切切实实地跑一遍推理,此时它只会保存推理时会用到的网络层,像上面的self.layer_new的权重是不会被保存下来的。
总结一下就是,保存torch模型时,为了避免不必要的bug,我们一般只保存nn.Module的子类中出现的模型权重,而不保存模型结构,从而它不知道你推理时实际用了哪些层,所以只要出现在__init模块就保存。保存onnx时,是有模型结构信息的,所以只保存有用的模型权重。
6、resnet18的前面几个卷积层,明明设置了bias=False,为什么转成onnx做可视化后依然可以看到B?BtachNorm层也是有参数的,为什么onnx可视化后见不到BatchNorm层?
答:以上问题是因为torch版本>=1.7.0导致的。
我们先看下现象:同样是resnet18,我用torch1.2转成onnx再可视化时,前几层长这样
而我用torch1.7.1转成onnx再可视化时,前几层长这样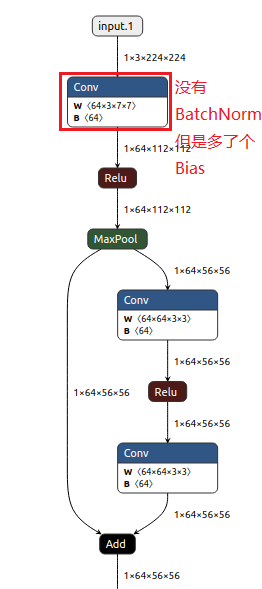
原因如下:torch>=1.7.0后,torch.onnx.expot 函数,会将Conv层和BatchNorm层进行融合,做成一个新的Conv层。根据BatchNorm的计算方式(减去mean,除以std,乘以 beta,加上gema),这种融合自然会将不带Bias的Conv变为带Bias的Conv。这种融合为后续模型量化加速是很有帮助的,毕竟原先的两层缩减为现在的一层。
lesson 03
1、思考题1中有 CUDA 的同学,改下代码:self.device=torch.device(‘cuda’)。用上述相同方法测试时间开销。出现下面这个错误,是否是因为安装的时候版本是cpu ?
AssertionError: Torch not compiled with CUDA enabled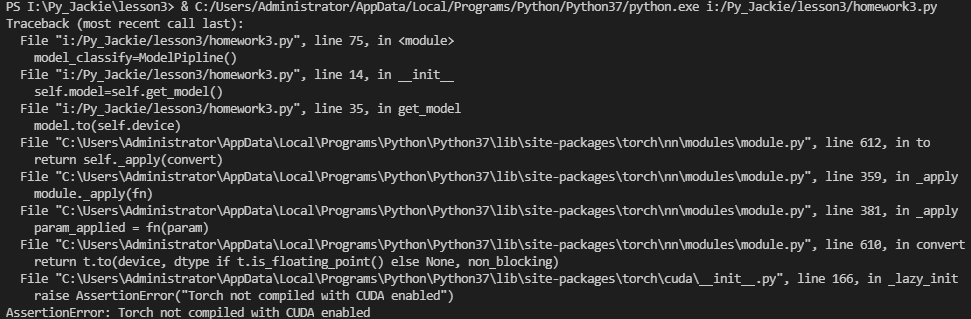
2、为什么使用GPU推理速度比CPU慢?
答:可能哪出问题了吧。我用老师的方式做测试,CPU上开销7秒,CUDA上开销0.22秒。但是如果只是用时接近的话,可以考虑是否为GPU预热所需要的时间。
3、如何更好的了解学习不同网络本身的结构特点。除了看论文,老师还有什么其他好的建议吗?
答:可以看整理好的中文综述,横向比较不同网络结构的特点。
也可以看江大白的视频课程,https://m.ke.qq.com/course/3454999?_bid=167&_wv=2147487745&term_id=103592742&taid=11130635384305687,其中的第四节课程。
老师可以解释一下图像的标准化吗?inputs = (inputs - np.array([0.485, 0.456, 0.406])) / np.array([0.229, 0.224, 0.225])
答: 像素值的变化范围是0到255,除以255是把像素值压缩成0到1范围。如果想进一步做标准化,需要减去均值,除以标准差。上面的两个np.array分别是ImageNet数据集的像素值除以255后,按RGB通道计算出来的均值和标准差。
Lesson04
1、什么是BGRA图片,为什么要保存成这种格式的图片呢?
答:顾名思义,一张BGRA图片有四个通道,前三个通道是BGR,提供了图片通常的像素信息。第四个阿尔法通道,是一张二值图(只包含0和255),其中255的位置代表了前景(分割出的物体),0的位置代表了背景。这种保存方式很适合语义分割任务的输出保存。
比如你在本地有一张 1.png 的BGRA四通道图,加载下
image=cv2.imread(‘1.png’, -1)
print(image.shape)
别漏了-1(-1是读rgba图的flag,默认读取彩色图像)。然后再把BGR通道和阿尔法通道分离开,单独show出来看看。
a)cv.IMREAD_COLOR,对应值为 1,表示以彩色图方式读取图片。忽略图像的透明度。该模式为默认模式。
b)cv.IMREAD_GRAYSCALE,对应值为 0,以灰度图方式读取图片。
c)cv.IMREAD_UNCHANGED,对应值为 -1,以含Alpha通道的方式加载图像。Alpha通道:“非彩色”通道,指一张图片的透明和半透明度。
2、假设目标对象中一些像素点的概率值小于0.5这个阈值,那么分割出来的目标会出现空洞现象。后期是否有方法解决?
回答:目前没有一个模型可以把所有图片都准确识别的,只能慢慢提高模型的泛化能力。实际应用中,一般也是针对特定场景的图片finetune出一个准确率高的模型,保证该场景下尽量不要出现“空洞”。(如果空洞不大,那么可以考虑用膨胀和腐蚀的方法做结果优化)
3、上课时老师要求“把 load_state_dict 中 strict 改为 False”,实际上测试strict True 或者False,对结果没有影响,如何理解?我们的model与预训练模型结构是否完全匹配?
回答:如果把“ aux_loss=True” 改为 “ aux_loss=False” ,则我们的model就会比预训练模型结构少一个 auxiliary blcok,两者就会不完全匹配,因此strict需改为False。
Lesson05
(1)图像BGR转RGB转换方式
之前采用的是opencv的语法:image=cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
第五讲的代码中,将上述方法改成了列表位置互换形式:padded_img = padded_img[:, :, ::-1]
答: 两种方法没有任何区别。为了讲课方便,就照搬源代码了。
(2)yolox能在检测头增加一个检测框的角度回归信息实现旋转框的检测吗?
答: 可以的,需要自己手动添加。

若有收获,就点个赞吧
0 人点赞
