前言
随着互联网的发展,用户规模和数据规模越来越大,对系统的性能提出了更高的要求,缓存就是其中一个非常关键的组件,从简单的商品秒杀,到全民投入的双十一,我们都能见到它的身影。
分布式缓存首先也是缓存,一种性能很好但是相对稀缺的资源,和我们在课本上学习的CPU缓存原理基本相同,CPU是用性能更好的静态RAM来为性能一般的DRAM加速,分布式缓存则是通过内存或者其他高速存储来加速,但是由于用到了分布式环境中,涉及到并发和网络的问题,所以会更加复杂一些,但是有很多方面的共性,比如缓存淘汰策略。计算机行业有一句鼎鼎大名的格言就指出了缓存失效的复杂性。
There are only two hard things in Computer Science: cache invalidation and naming things. 计算科学中最难的两件事是命名和缓存失效。 – Phil Karlton
缓存用途
- 提升性能
绝大多数情况下,select是出现性能问题最大的地方。一方面,select会有很多像join、group、order、like等这样丰富的语义,而这些语义是非常耗性能的;另一方面,大多数应用都是读多写少,所以加剧了慢查询的问题。
分布式系统中远程调用也会耗很多性能,因为有网络开销,会导致整体的响应时间下降。为了挽救这样的性能开销,在业务允许的情况(不需要太实时的数据)下,使用缓存是非常必要的事情。
- 缓解数据库压力
当用户请求增多时,数据库的压力将大大增加,通过缓存能够大大降低数据库的压力。分布式缓存是为了解决数据库服务器和Web服务器之间的瓶颈,如果一个网站流量很大这个瓶颈将会非常明显,每次数据库查询耗费的时间将不容乐观。对于更新速度不是很快的站点,可以采用静态化来避免过多的数据查询,可使用Freemaker或Velocity来实现页面静态化。对于更新数据以秒级的站点,静态化也不会太理想,可通过分布式缓存系统来解决,如Redis、MemCache、SSDB等。
缓存适用场景
- 对于数据实时性要求不高:对于一些经常访问但是很少改变的数据,读明显多于写,适用缓存就很有必要。比如一些网站配置项。
-
分布式缓存产品
实际开发中经常使用的分布式缓存系统主要有Redis、MemCache、SSDB,这三者都是KV存储方案,各有优缺,但Redis相比较而言实用性更加广泛。由于Redis特点突出,支持多种数据类型,如String、Hash、Set、List、StoredSet,并且有高可用的解决方案和集群方案,支持水平扩容。也就解决了大部分企业的需求,而MemCache、SSDB相对来说,解决方案并不算那么完善。Redis与MemCache的区别
线程操作
Redis使用单核而Memcache使用多核,也就是说,Redis属于单线程操作,MemCache属于多线程操作。在多个用户同时请求时,Redis是处理完一个请求以后再去处理下一个请求。而MemCache可以同时处理多个请求。
- 数据结构
Redis不仅支持简单的KV类型的数据,同时提供List、Set、Hash等数据结构的存储。
- 数据安全性
Redis和MemCache都是将数据存储在内存中,都属于内存数据库。但是MemCache服务宕机或重启后数据是不可恢复的,而Redis服务宕机或重启后可以恢复。因此Redis可以做持久化,它会将内存数据定期同步到磁盘中。
- 持久化策略
Redis提供两种持久化策略,默认支持的是RDB持久化以及需要手工开启的AOF持久化。而MemCache仅仅是将数据存储在内存中。
- 数据备份
Redis支持数据备份,需开启master-slave主从策略。
- 过期策略
MemCache在set时就指定了过期时间,而Redis可以通过expire设置Key的过期时间。
- 内存回收
MemCache有内存回收机制,当程序中为它设置的内存大小,一旦存储的数据超过时,它会去自动回收,也就是释放,不然会出现内存溢出的情况。这是因为MemCache的数据都是存储在内存中的。而Redis不会出现这种情况,因为Redis可以将数据持久化到磁盘上。
Redis和SSDB的区别
SSDB是基于Google性能极高的LevelDB作为存储引擎去架构的,特性与Redis基本一致,而且可以和Redis完美整合。SSDB完全可以替换Redis,它与Redis的API兼容并支持Redis的客户端,也就是说,在redis-cli上的所有操作在SSDB中同样适用。由于SSDB该性能的写特性,所以很多时候可以通过Redis+SSDB实现分布式缓存的策略,即”用SSDB写用Redis读”。
缓存的更新模式
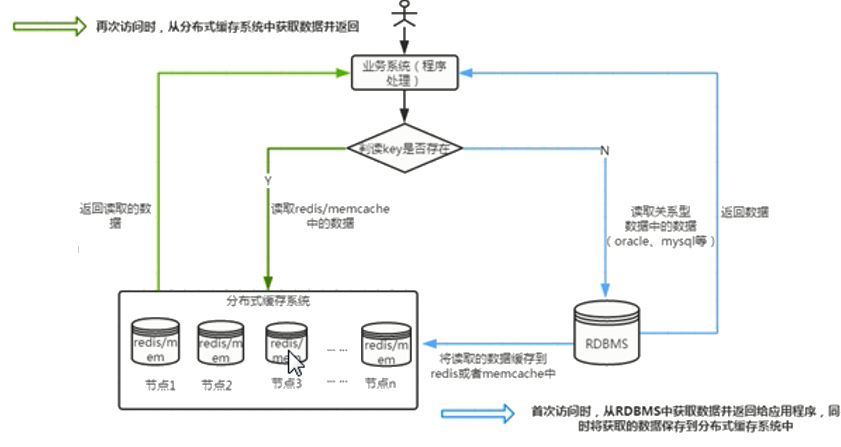
Cache Aside模式
- 读取失效:cache数据没有命中,查询DB,成功后把数据写入缓存。
- 读取命中:读取cache数据。
- 更新:把数据更新到DB,失效缓存。

// Readdata = cache.get(id);if (data == null) {data = db.get(id);cache.put(id, data);}// Writedb.save(data);cache.invalid(data.id);// 123456789101112
问题:为什么更新不直接写缓存?
原因:为了降低并发情况下的数据不一致发生概率(Cache Aside无法完全避免数据不一致,只能降低发生的概率,如果需要数据强一直可以考虑使用分布式锁),如下所示。
Thread-A: Write DB Version(A)Thread-B: Write DB Version(B)Thread-B: Write Cache Version(B)Thread-A: Write Cache Version(A) -- 数据库结果是B,缓存里面变成A了1234
这种情况下如果改为失效的话数据不一致的情况能够避免。
Thread-A: Write DB Version(A)
Thread-B: Write DB Version(B)
Thread-B: Expire Cache
Thread-A: Expire Cache -- 两种情况只失效缓存,下次读操作会把db的最新值刷新到缓存中。
1234
Read/Write Through模式
缓存代理了DB读取、写入的逻辑,可以把缓存看成唯一的存储。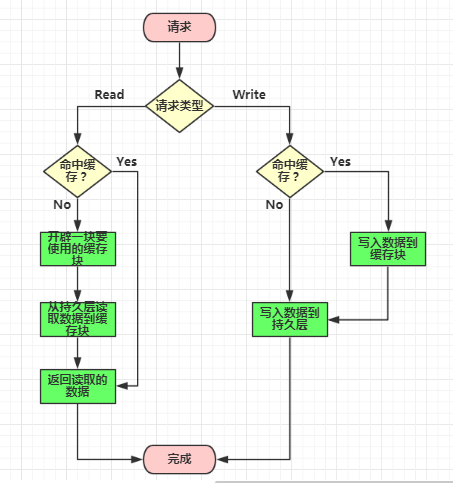
# [xxx] 表示一个组件
# 箭头表示数据方向
Read:
Client <-- [Cache <-- DB]
Write:
Client --> [Cache --> DB]
1234567
Write Behind Caching(Write Back)模式
这种模式下所有的操作都走缓存,缓存里的数据再通过异步的方式同步到数据库里面。所以系统的写性能能够大大提升了。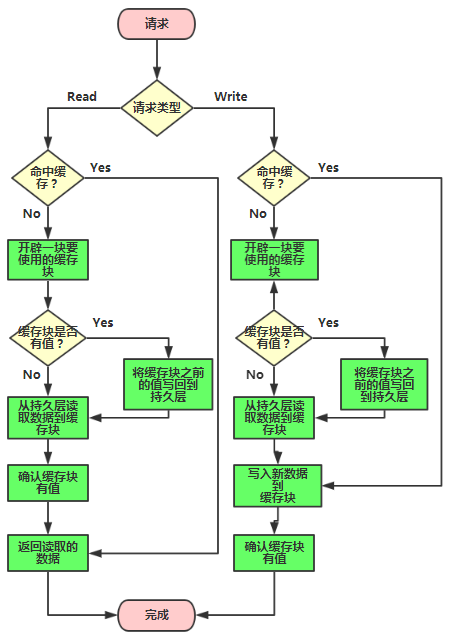
缓存失效策略
一般而言,缓存系统中都会对缓存的对象设置一个超时时间,避免浪费相对比较稀缺的缓存资源。对于缓存时间的处理有两种,分别是主动失效和被动失效。
主动失效
主动失效是指系统有一个主动检查缓存是否失效的机制,比如通过定时任务或者单独的线程不断的去检查缓存队列中的对象是否失效,如果失效就把他们清除掉,避免浪费。主动失效的好处是能够避免内存的浪费,但是会占用额外的CPU时间。
被动失效
被动失效是通过访问缓存对象的时候才去检查缓存对象是否失效,这样的好处是系统占用的CPU时间更少,但是风险是长期不被访问的缓存对象不会被系统清除。
缓存淘汰策略
缓存淘汰,又称为缓存逐出(cache replacement algorithms或者cache replacement policies),是指在存储空间不足的情况下,缓存系统主动释放一些缓存对象获取更多的存储空间。
对于大部分内存型的分布式缓存(非持久化),淘汰策略优先于失效策略,一旦空间不足,缓存对象即使没有过期也会被释放。这里只是简单介绍一下,相关的资料都很多,一般LRU用的比较多,可以重点了解一下。
FIFO
先进先出(First In First Out)是一种简单的淘汰策略,缓存对象以队列的形式存在,如果空间不足,就释放队列头部的(先缓存)对象。一般用链表实现。
LRU
最近最久未使用(Least Recently Used),这种策略是根据访问的时间先后来进行淘汰的,如果空间不足,会释放最久没有访问的对象(上次访问时间最早的对象)。比较常见的是通过优先队列来实现。
LFU
最近最少使用(Least Frequently Used),这种策略根据最近访问的频率来进行淘汰,如果空间不足,会释放最近访问频率最低的对象。这个算法也是用优先队列实现的比较常见。
常见问题
缓存穿透
- 问题描述:DB中不存在数据,每次都穿过缓存查DB,造成DB的压力。一般是网络攻击。
- 解决方案:放入一个特殊对象(比如特定的无效对象,当然比较好的方式是使用包装对象)。
代码示例:
// 我们先看看最简单的青铜姿势
value = cache.get(key)
if value is None:
value = db.get(key)
// 由于value为空,实际上缓存并没有写进去,一旦这个key成为热点,db的压力将会极大
cache.put(key, value, expire)
return value
else:
return value
// 简单优化一下,升级成为白银姿势
wrapped_value = cache.get(key)
if wrapped_value is None:
value = db.get(key)
// 即使是空对象也通过包装对象放到缓存,当然考虑到空间还可以采用特殊值(比如-1代表不存在)的方式
cache.put(key, wrapped_value(value), expire)
return wrapped_value.value
else:
return wrapped_value.value
缓存击穿
- 问题描述:在缓存失效的瞬间大量请求,造成DB的压力瞬间增大。
- 解决方案:更新缓存时使用分布式锁锁住服务,防止请求穿透直达DB。 ```c // 白银姿势 wrapped_value = cache.get(key) if wrapped_value is None: value = db.get(key) // 在写入缓存之前,大量的请求突然涌入,db瞬间被打垮 cache.put(key, wrapped_value(value), expire) return wrapped_value.value else: return wrapped_value.value
// 在白银姿势的基础上我们再优化成黄金姿势 wrapped_value = cache.get(key) if wrapped_value is None: // 查db之前加一把锁 while wrapped_value is None: if try_lock(key): value = db.get(key) cache.put(key, wrapped_value(value), expire) return wrapped_value.value else: // 等待10毫秒之后重试 sleep(0.01) wrapped_value = cache.get(key) return wrapped_value.value else: return wrapped_value.value
<a name="b901facc"></a>
## 缓存雪崩
- **问题描述**:大量缓存设置了相同的失效时间,同一时间失效,造成服务瞬间性能急剧下降。
- **解决方案**:缓存时间使用基本时间加上随机时间。
```c
// 通过随机失效时间登上王者姿势
wrapped_value = cache.get(key)
if wrapped_value is None:
// 查db之前加一把锁
while wrapped_value is None:
if try_lock(key):
value = db.get(key)
// 嗯,就是一个随机失效时间,最好是在某个区间
cache.put(key, wrapped_value(value), random_expire())
return wrapped_value.value
else:
// 等待10毫秒之后重试
sleep(0.01)
wrapped_value = cache.get(key)
return wrapped_value.value
else:
return wrapped_value.value

若有收获,就点个赞吧
0 人点赞
