Microsoft SQL Server重点知识提炼
添加数据库
create
database 凡猫学院;
引用某个数据库
use 凡猫学院;
添加新数据库表
create table 学生表
(
Id
int primary key,
姓名
varchar(30) not null,
年龄
int
);
比较常用的数据类型基本就是int,
char(20), varchar(100), float和date
插入数据
insert into
学生表 (Id, 姓名, 年龄)
values (1, “Jeremy”, 18);
查询表中所有数据(代表所有列的快捷键,使用号会把所有列全部显示,后面的例子如果没有特殊要求,为了方便起见,都会用*)
select
from 表名;
查询表中具体某几列的全部数据(多列之间以逗号隔开)
select 列1, 列2, 列n from 表名;
将所要查询的列进行个性化的别名(列2后面特意没加as关键字,因为可以省略不写)
select 列1 as别名1, 列2别名2 from 表名;
增加具体的条件来随意查询表中的数据,比如查询所有美国的香水,开始要加具体条件了,记住使用关键字是where
select
from 香水表 where 品牌 = “美国”;
SQL运算符(基本所有数据库产品都通用的)
等于 =
不等于
<>(有的数据库产品用!=表示)
大于 >
小于 <
大于等于 >=
小于等于 <=
在A和B之间 between A and B
像…一样 like “%Jere%”(可以不用把Jeremy打全也能搜索到Jeremy)
更新(修改)数据,支持多列修改的,同样以逗号隔开
update 表名 set 列1 = 新的值, 列n = 新的值 where 列 = 该列下某行数据的值
实例:update
香水表 set 系列 = “周末系列”, 价格 = 10086 where 系列
= “Weekend”;
分析:更新香水表,具体更新啥?我们倒过来讲,就是把“系列”是”Weekend”的一行或多行数据,它们所在的“系列”列和“价格”列分别修改成“周末系列”和10086元
查询某区间段之间的数据,比如下面两个例子:
(1)
查询学生表里,学生的年龄段在18~30岁之间的数据
select
from 学生表 where 年龄 between 18
and 30;
(2)
查询香水表里,香水的价格在100~500元之间的数据
Select from 香水表 where
价格 between
100 and 500;
当有的时候,你并不知道你想查询的值的具体值,完全不用害怕,可以用模糊查询,需要用到like关键字并和通配符搭配使用,最常用的通配符是%
(1) select
- from 香水表 where 价格 like “5%”;
解释:上面这句SQL语句的目的是为了查询出价格是5开头的数据,通配符摆放的位置很有讲究,也不难理解,你只要记住,通配符“代替”你“不敢肯定”的部分就可以了。在这里,我的目的是查询5开头的价格,只要是5开头的,具体后面是什么数字,用了通配符就不用再关心了
(2) select - from 香水表 where 价格 like “%5”;
解释:通配符的位置一换,意义就不同了,这句语句代表以5结尾的价格,前面的部分不关心,只要是5结尾就全部显示
运算符and和or,Jeremy老师总结了一个口诀:需要严格地锁定查询,用and,因为结果数据是符合所有条件的;需要多态的查询结果,用or,只要符合条件都会查询出来;那么问题来了,无论是用and或者用or,没有条件符合怎么办?那就查不出数据呗!这里强调下,“没有数据”也是一种查询,看以下2个实例:
select from 学生表 where 班级 = “终极一班” and 姓名 = “Jeremy”;
解释:上面这句SQL会查询学生表里“同时满足班级条件和姓名条件”的记录,有就显示,没有就不显示
我们假设终极一班里的确有Jeremy这位优等生,如果我们把and换成or,结果会查询出所有终极一班的学生以及所有叫Jeremy的童鞋,即使他们不一定是终极一班的
如果想要查询的条件是一个区间里的某些值,使用in关键字,比如我想查询价格分别是598,698和1088元的香水,当然,我可以用or运算符来完成,但是试想一下,如果有10个以上的条件,那用or的话,SQL语句会变得非常长,所以最好的办法是用in
select from 香水表 where 价格 in (598, 698, 1088);
那么问题来了,查询姓名分别叫陈冠希、钟欣桐和张柏芝的明星可以用in吗?Of course!
select from XX门 where 姓名 in (“陈冠希”, “钟欣桐”, “张柏芝”);
切记!字符串类型的要用一对引号,多条件的情况中间以逗号隔开
“去重”使用distinct关键字,比如我香水表里有N条香水品牌的数据,我只想查询出不重复的品牌,如下:
select distinct 香水品牌 from 香水表;
排序用order by关键字,默认升序(asc可以省略),如果要降序那么后面跟desc
select from 香水表 order by 价格 asc; 价格从低到高
select from 香水表 order by 价格 desc 价格从高到低
下面是有where条件句的,需要注意order by的位置
select from 学生表 where 班级 = “终极一班” order by 姓名;
上面这句SQL语句代表终极一班的学生,他们的姓名以首字母从a~z排列(asc已省略)
select from 学生表 where 班级 = “终极一班” order by 姓名 desc;
上面这句SQL语句代表终极一班的学生,他们的姓名以首字母从z~a排列
查询出抖音里点击量最高的10个视频
select top 10 from 抖音 where 分类 = “你懂得” order by 视频点击量 desc
先进行倒叙排序,排序后整张表格会以点击量从高到底排列,然后加上top关键字后面跟具体的数字就可以了;如果我想查询点击量最少的10个视频,其实也很简单,把desc改成asc,让表格正序排列就行了
删除数据,记住,数据库里的数据是以“行”作为单位的,所以要删除,一整行的数据就都没了,而不像Excel里,你可以只删除某个单元格的数据
delete from 王者荣耀 where 英雄姓名 = “不知火舞”;
我们执行了上面这句SQL语句后,不知火舞这行数据就会在表中被移除了,不仅仅是她的名字,包括它的皮肤、技能、模型等一切数据
最常用的函数无非就是max, min, avg和sum,需要注意的是,如果不给函数加别名,会以无列名显示,所以建议加别名,as可以省略
查询学生表的最大的年龄
select max(年龄) as 最大年龄 from 学生表;
查询学生表的最小年龄
select min(年龄) 最小年龄 from 学生表;
查询学生表的平均年龄
select avg(年龄) 平均年龄 from 学生表;
查询学生表的年龄总和
select sum(年龄) 年龄总和 from 学生表;
假设现在有一张表,里面记录着全世界不同专柜的香水的销售情况,现在要统计每个专柜的销售额怎么办?
select 商场专柜, sum(价格) as 总销售额 from 香水销售记录表 group by 商场专柜;
分析:先把总价算出来,然后以“商场专柜”进行分组,这样不就等于把“sum(价格)”这个聚合函数分配到不同的专柜里了吗?记住!如果想要使用聚合函数又同时想显示“列”就一定要配合group by使用,除了聚合函数本身,select了多少列,group by后面就要跟多少列,不然会报错的。当然,group by后面是可以跟多个列的,记得要以逗号隔开,而且要搞清分组的先手顺序的逻辑,比如下面这个例子:
select 商场专柜, 销售时间, sum(价格) 总销售额 from 香水销售记录表
group by 商场专柜, 销售时间 order by 总销售额 desc;
分析:上面这个例子就是先以商场专柜分组,在每个分出来的“商场专柜”里再以不同的“销售时间”分组,得出“总销售额”,当然,一样可以进行排序,例子中以“总销售额”降序排列
我们知道,当你想要给出“具体条件”的时候,我们可以用where关键字。但是如果是针对聚合函数的条件,就需要用having这个关键字了,其实不难记的,只要记住口诀“group by和having是连用的,可以没有having,但是一旦有,那么就必须跟随在group by后面”,比如下面这个例子:
select 班级, count(美女) as 美女总人头数 from 佳丽表 where 学校 = “凡猫学院”
group by 班级 having 美女总人头数 > 3;
分析:上面的SQL语句,我们玩的是一场“点美女的人头数”游戏,把“凡猫学院”的美女根据不同的班级进行分组,计算出每个班级的美女总人头数。当然,我们针对 “count(美女)”这个聚合函数设置了一个条件,就是“每个班级的美女总人头数要大于3位”才查询出来,以免“狼多肉少”的尴尬场面发生,嗯,就是这样…
关于子查询那些事?先看下面这个例子:
select from 天上人间 where 年龄 < (select avg(年龄) as 平均年龄 from 天上人间)
分析:嗯,男孩子们的福利来了。假设你去天上人间应酬,你总得想选个年轻貌美的吧?那么上面这条SQL语句就能完成这个夙愿,查询出年龄比平均年龄小的所有美女们,呵呵…那么问题来了,我怎么知道平均年龄是多少?请看后半句带括号的你就懂了~
多表间的内连接、左连接和右连接了解下?
假设:有两张有关联的表,表A(左表)是男生表,表B(右表)是女生表;女生表有一个“外键”连接的是男生表的“主键”;男生表有12位男青年,女生表有10位美女;男生表里有2位单身汪,其余10位男生和女生表里的10位女生属于虐狗关系。言归正传,请看下面的实例:
内连接
select from 男生表 join 女生表 on 男生表.主键 = 女生表.外键
分析:上面的内连接SQL语句返回的是两张表的10条有联系的数据,2位单身汪男青年会被排除,因为内连接只匹配两表间有关系的数据,如下图的形象比喻: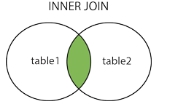
左连接(属于外连接类型)
select from 男生表 left join 女生表 on 男生表.主键 = 女生表.外键
分析:上面的左连接SQL语句考虑了2位单身汪男青年的感受,会显示男生表(左表)里所有的数据,即使还有2位汪没有找到另一半,但未来说不定是个潜力股,直接屏蔽总感觉不够厚道不是吗?那么问题来了,男生表有12条数据,女生表只有10条数据,不匹配怎么办?答案很简单,女生表为了和男生表的行数保持一致,不足的用null代替。最后,用专业术语总结下就是两张表在左连接以后,会返回左表中所有的数据,即使右表中无对应数据(用null代替),如下图的形象比喻: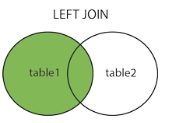
右连接(属于外连接类型)
最简单的理解就是方向反一下,想要达到(2)的效果,把男生表放到右边,女生表放到左边就可以了,无它…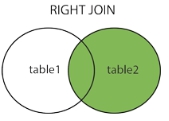
关于Microsoft SQL Server,MySQL和Oracle该学哪个?市面上哪个最火?
学啥都一样,都是一个妈生的,没有亲妈、后妈之分!三足鼎立,都是很火的。别再阿Q精神自慰了,觉得学Microsoft SQL Server没学好的话去学MySQL就能学好,又或者觉得Oracle是甲骨文公司的就感觉很高端、很牛X似的,不学就觉得自己走错路一样!记住,世界上你走过最长的路不是弯路,是被套路!酷暑其实不是很热,心静自然凉…
全文完
Designed by Jeremy
1,创建数据库 - 测试基础37期
create database 测试基础37期;
使用数据库-测试基础37期
use 测试基础37期;
2,创建表 - Perfume
create table Perfume
(
Id_P int,
Brand varchar(100),
Country char(100)
);
3. varchar char区别
varchar可变字符串 节省了空间 但查询速度比较慢(时间换空间)
char不可变字符串 (空间换时间)
4. SQL约束
非空not null 唯一unique primary key主键
create table Perfume
(
Id_P int primary key,
Brand varchar(100) not null,
Country char(100)
);
5. 插入数据 insert
insert into 表名(列1,列2,..)values(值1,值2,..); 插入指定列
insert into 表名 values(值1,值2,值3,…);按顺序全部插入
6. 删除表/删除数据 drop/delete - Perfure
drop table Perfure;
delete from Perfure;
truncate table Perfume;
delete from 表名 where 条件;
7. 查询数据 select
select from 表名;查询一张表所有数据
查询指定的列;
select from 表名 where 列 运算符 值;按条件查询
8. 修改数据
update 表名称 set 列名称=新值 where 列名称=某值(条件);
运算符
1. between … and 在某个范围内
not between … and 不在某个范围内
2. <> != 不等于
3. 通配符% _ like 模糊匹配
4. and or 运算符
5. in
6. distinct 关键字 去重
7. order by 排序 desc降序
8. top 查询条数
9. group by 列1,列2 having 条件 对一个或多个列分组/去重
select from 表名 where 列 运算符 值
group by 列1,列2 having 条件(聚合函数)
order by 列 desc;
函数
1. isnull()函数 处理空值
SELECT 姓名, (测试理论得分 + ISNULL(SQL得分, 0) + QTP得分 + Selenium得分) AS 各科考试总分
2. avg()函数 返回列的平均值
3. max()最大值
4. min()最小值
5. count()计数
count(distinct 班级)
6. sum()统计
7. len()求长度
8. round()处理小数点
round(圆周率,1)
select from 表名
where 条件(不能有聚合函数)
group by 列名 having 条件
order by 列名 DESC;
列的操作
1. 添加列
alter table 表名 add 列名 数据类型 [约束];
alter table Perfure add 50ml双11价 int null;
2. 修改列的属性
alter table 表名 alter column 列名 数据类型;
alter table Perfure alter column 50ml双11价 varchar(11);
3. 删除列的语法
alter table 表名 drop column 列名;
4. 增加列的约束(已有此列 增加约束)
alter table 表名 add constraint 约束名 约束 (列名1,【列名2】);
alter table Perfure add constraint unique约束 unique (系列);
5. 删除列的约束
alter table Perfure drop constraint unique约束;
6. 更改列名
EXEC sp_rename ‘表名.原列名’, ‘新列名’,’column’;
create database _37期sql复习;
use _37期sql复习;
create table 表A(
姓名 varchar(10)not null,
科目 varchar(10),
分数 int,
性别 char(10),
是否及格 char(10),
评价 varchar (10)
);
select from 表A;
—insert into 表A values (‘测试1’,’语文’,99,’男’,null,null),(‘测试2’,’语文’,71,’男’,null,null),(‘测试3’,’语文’,58,’女’,null,null);
insert into 表A values (‘测试2’,’语文’,71,’男’,null,null);
insert into 表A values (‘测试3’,’语文’,58,’女’,null,null);
insert into 表A values (‘测试4’,’语文’,40,’男’,null,null);
insert into 表A values (‘测试5’,’语文’,93,’女’,null,null);
insert into 表A values (‘测试1’,’数学’,77,’男’,null,null);
insert into 表A values (‘测试2’,’数学’,84,’男’,null,null);
insert into 表A values (‘测试3’,’数学’,61,’女’,null,null);
insert into 表A values (‘测试4’,’数学’,60,’男’,null,null);
insert into 表A values (‘测试5’,’数学’,86,’女’,null,null);
/ 数据类型
int float char varchar
约束有哪些
null not null unique primary key(非空 唯一)
1. 插入某些字段(姓名,分数)/
—inset into 表名(姓名,分数)values(’测试1’,99);
—2. 按顺序插入所有所有字段
—insert into 表A values (‘测试1’,’语文’,99,’男’,null,null);
/
3. insert into 表A values
(‘测试1’,’语文’,99,’男’,null,null),(‘测试2’,’语文’,71,’男’,null,null),(‘测试3’,’语文’,58,’女’,null,null);
4. 姓名为测试1的记录全部删除
delete from 表名 where 条件;删除数据
truncate from 表名;删除所有数据
drop table 表名;删除表
5. 更新数据 测试5的语文成绩改为100
update 表名 set 列名=新值 where 条件;/
update 表A set 分数=100 where 姓名=’测试5’ and 科目=’语文’;
—运算符
—1. between and 查询数学成绩在60到90分之间的学生姓名
select 姓名 from 表A where 科目=’数学’ and 分数 between 60 and 90;
select 姓名 from 表A where 分数 between 60 and 90 and 科目=’数学’;
—2. and or
—3. in 查询测试1,测试2,测试3的语文成绩,要求展示姓名,分数
select 姓名,分数 from 表A where 姓名 in (‘测试1’,’测试2’,’测试3’) and 科目=’语文’;
—4. like 模糊匹配 通配符 %多个 一个 查询姓名中带测试的所有人的语文成绩
select from 表A where [姓名] like ‘%测试%’ and [科目]=’语文’;
select from 表A where [姓名] like ‘%测‘ and [科目]=’语文’;
—5. distinct 去重 查询表A中所有的姓名
select distinct 姓名 from 表A;
—6. sum(列名) 返回的是某一列值得总和 函数作用的是列
—求出所有人的sql的分的总和
select sum(SQL得分) SQL得分总和 from [dbo].[软件测试考试分数表重制版];
—求出一班的sql得分的总和
select sum(SQL得分) SQL得分总和 from [dbo].[软件测试考试分数表重制版] where 班级 = ‘一班’;
—8. sum(列名) 测试1语文跟数学成绩总和
select sum(分数) from 表A where 姓名=’测试2’;
—9. count() 返回符合条件得数据的条数 一班共有多少名学生
select count(姓名) from [dbo].[软件测试考试分数表重制版] where 班级=’一班’;
select count(*) from [dbo].[软件测试考试分数表重制版] where 班级=’一班’;
— 查询这张表共有多少条数据
select count() from [dbo].[软件测试考试分数表重制版];
select count(python得分) from [dbo].[软件测试考试分数表重制版];
—我想查询出一共有几个班级
select count(distinct 班级) 班级数 from [dbo].[软件测试考试分数表重制版];
— 函数
— avg() 求满足条件的某一列的平均值
— max() min() 求一班的python得分的最高分
select max([Python得分]) as 一班Python得分最高分 from 软件测试考试分数表重制版
where [班级]=’一班’;
—len() 求长度 请查询出张三所在的考点名称有多长
select len(考点) from [dbo].[软件测试考试分数表_重制版] where 姓名=’张三’;
select from [dbo].[表A];
—9. count(列名) sum(列名) 测试1语文跟数学成绩总和(假如科目中还有英语科目)
— 1. in 2. <> 英语 3. or
alter table 表A alter column 分数 int;
select sum(分数) from [dbo].[表A] where 姓名=’测试1’ and (科目=’语文’ or 科目=’数学’);
select sum(分数) from [dbo].[表A] where 姓名=’测试1’ and 科目 in (‘语文’,’数学’);
select sum(分数) from [dbo].[表A] where 姓名=’测试1’ and 科目 != ‘英语’;
—列的操作
—1. 添加一列 添加一列班级 char(6)
—alter table 表名 add 列名 数据类型 属性;
alter table 表A add 班级 char(6);
—2. 修改列的数据类型 分数的int改为float
—alter table 表名 alter column 列名 数据类型;
alter table 表A alter column [分数] float;
—3. 删除列的语法 删除班级列
—alter table 表名 drop column 列名;
alter table 表A drop column [班级];
—4. 更改列名
EXEC sp_rename ‘表名.原列名’, ‘新列名’,’column’;
— 1. 按分数倒序排列显示出姓名,科目,分数
select 姓名,科目,分数 from 表A order by 分数 desc;
— 2. 查询出语文分数大于70分的人数
select count() from 表A where 科目 = ‘语文’ and 分数>70;
— 3. 查询出数学最高分的姓名,分数
select 姓名,分数 from 表A where 分数 in (select top 1 分数 from 表A where 科目 = ‘数学’ order by 分数 desc) and 科目=’数学’;
select [姓名],[分数] from 表A where 分数=(select max([分数]) as 数学最高分 from 表A where [科目]=’数学’) and [科目]=’数学’;
— 4. 查询出所有科目评价为良好的男生姓名,科目,分数
select 姓名,科目,分数 from 表A where 姓名 in (select 姓名 from 表A where 性别=’男’
group by 姓名 having min(分数)>61 and max(分数)<85);
— 聚合函数会跟group by having 结合使用
update 表A set 分数=50 where 姓名=’测试3’ and 科目=’语文’;
select 姓名,科目,分数 from 表A where 姓名 in (select 姓名 from 表A where 性别=’男’ and 分数 between 61 and 85
group by 姓名); —分组 不对的
insert into 表A values (‘测试1’,’语文’,90,’男’,null,null);
select from 表A;
update 表A set 分数=50 where 姓名=’测试3’ and 科目=’语文’;
select 姓名,科目,分数 from 表A where 性别=’男’ and 分数>61 and 分数<85;
— group by对某一列重复的数据分组,去重
— 求出表A中一共多少个科目
select 科目 from 表A group by 科目;
— 5. 一条查询中分别输出男女生的数学最低分
select from 表A where 评价=’良好’ group by 科目;
select from 表A where [分数] in
((select min([分数]) As 男生数学最低分 from 表A where [性别]=’男’ and [科目]=’数学’),
(select min([分数]) As 女生数学最低分 from 表A where [性别]=’女’ and [科目]=’数学’));
SELECT FROM 表A WHERE 分数 in (SELECT top 1 分数 FROM 表A where 性别= ‘男’ and 科目= ‘数学’ order by 分数 asc)
or 分数 in (SELECT top 1 分数 FROM 表A where 性别= ‘女’ and 科目= ‘数学’ order by 分数 asc);
— 6. 一条查询中分别输出语文和数学前两名的姓名,科目,分数
select 姓名,科目,分数 from 表A where 分数 in
(select TOP 2 分数 from 表A where 科目=’语文’ order by 分数 desc ) or 分数 in
(select TOP 2 分数 from 表A where 科目=’数学’ order by 分数 desc) order by 分数 desc;
select 姓名,科目,分数 from 表A where
分数 in(select TOP 2 分数 from 表A where 科目=’语文’order by 分数 desc ) and 科目=’语文’ or
分数 in(select TOP 2 分数 from 表A where 科目=’数学’ order by 分数 desc) and 科目=’数学’
order by 分数 desc;
select 姓名,科目,分数 from 表A where 姓名 in
(select TOP 2 姓名 from 表A where 科目=’语文’ order by 分数 desc ) or 姓名 in
(select TOP 2 姓名 from 表A where 科目=’数学’ order by 分数 desc) order by 分数 desc;
insert into 表A(姓名,科目,分数) values(‘测试6’, ‘数学’, 86);
select from 表A;
delete from 表A where 姓名=’测试6’;
/
select from 表名
where 条件(不能有聚合函数)
group by 列名 having 条件
order by 列名 DESC;
*/
select 姓名,科目,分数 from 表A
where
姓名 in (select 姓名 from 表A where 性别=’男’ and 评价=’良好’
group by 姓名 having count(姓名) in (select count(distinct 科目) 科目 from 表A));
1,创建数据库 - 测试基础37期
create database 测试基础37期;
使用数据库-测试基础37期
use 测试基础37期;
2,创建表 - Perfume
create table Perfume
(
IdP int,
Brand varchar(100),
Country char(100)
);
3. varchar char区别
varchar可变字符串 节省了空间 但查询速度比较慢(时间换空间)
char不可变字符串 (空间换时间)
4. SQL约束
非空not null 唯一unique primary key主键
create table Perfume
(
Id_P int primary key,
Brand varchar(100) not null,
Country char(100)
);
5. 插入数据 insert
insert into 表名(列1,列2,..)values(值1,值2,..); 插入指定列
insert into 表名 values(值1,值2,值3,…);按顺序全部插入
6. 删除表/删除数据 drop/delete - Perfure
drop table Perfure;
delete from Perfure;
truncate table Perfume;
delete from 表名 where 条件;
7. 查询数据 select
select from 表名;查询一张表所有数据
查询指定的列;
select from 表名 where 列 运算符 值;按条件查询
8. 修改数据
update 表名称 set 列名称=新值 where 列名称=某值(条件);
运算符
1. between … and 在某个范围内
not between … and 不在某个范围内
2. <> != 不等于
3. 通配符% like 模糊匹配
4. and or 运算符
5. in
6. distinct 关键字 去重
7. order by 排序 desc降序
8. top 查询条数
9. group by 列1,列2 having 条件 对一个或多个列分组/去重
select * from 表名 where 列 运算符 值
group by 列1,列2 having 条件(聚合函数)
order by 列 desc;
函数
1. isnull()函数 处理空值
SELECT 姓名, (测试理论得分 + ISNULL(SQL得分, 0) + QTP得分 + Selenium得分) AS 各科考试总分
2. avg()函数 返回列的平均值
3. max()最大值
4. min()最小值
5. count()计数
count(distinct 班级)
6. sum()统计
7. len()求长度
8. round()处理小数点
round(圆周率,1)
列的操作
1. 添加列
alter table 表名 add 列名 数据类型 [约束];
alter table Perfure add 50ml双11价 int null;
2. 修改列的属性
alter table 表名 alter column 列名 数据类型;
alter table Perfure alter column 50ml双11价 varchar(11);
3. 删除列的语法
alter table 表名 drop column 列名;
4. 增加列的约束(已有此列 增加约束)
alter table 表名 add constraint 约束名 约束 (列名1,【列名2】);
alter table Perfure add constraint unique约束 unique (系列);
5. 删除列的约束
alter table Perfure drop constraint unique约束;
6. 更改列名
EXEC sp_rename ‘表名.原列名’, ‘新列名’,’column’;

若有收获,就点个赞吧
0 人点赞
