不再纠结什么路线,什么架构图了,就从一个点开始发散吧,螺旋螺旋…
预热>>>
所以,首先,什么是Hash?
:::info 朽木说:就是一个int值吧,通过某种算法得到的,hash函数?我不是很确定哎。 :::
我还是google一下吧:
散列函数?摘要,貌似勾起了我大学的一丁点回忆,开始螺旋了吗?我选择知乎,Go!
:::info
针对第一条回答,稍微提取一些重点吧:
hash 函数,是将任意长度的数据映射到有限长度的域上,作为这段数据的特征(指纹);
抗碰撞能力 :对于任意两个不同的数据块,其hash值相同的可能性极小;对于一个给定的数据块,找到和它hash值相同的数据块极为困难。
抗篡改能力 :对于一个数据块,哪怕只改动其一个bit位,其hash值得改动也会非常大。
在用到hash进行管理的数据结构中,比如 HashMap , hash 值(key)存在的目的是 加速键值对的查找 ,key的作用是为了将元素适当地放在各个桶里,对于抗碰撞的要求没那么高。hash出来的key,只要保证value大致均匀的放在不同的桶里就可以…….
:::
关于hash密码那段的就不看…先大致了解下就好。
根据答主的提示,翻了下JDK8中String的 hashCode() 方法:
/*** Returns a hash code for this string. The hash code for a* {@code String} object is computed as* <blockquote><pre>* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]* </pre></blockquote>* using {@code int} arithmetic, where {@code s[i]} is the* <i>i</i>th character of the string, {@code n} is the length of* the string, and {@code ^} indicates exponentiation.* (The hash value of the empty string is zero.)** @return a hash code value for this object.*/public int hashCode() {int h = hash;if (h == 0 && value.length > 0) {char val[] = value;for (int i = 0; i < value.length; i++) {h = 31 * h + val[i];}hash = h;}return h;}
再来学习下 Object 类中对hashCode方法的注释:
/*** Returns a hash code value for the object. This method is* supported for the benefit of hash tables such as those provided by* {@link java.util.HashMap}.* <p>* The general contract of {@code hashCode} is:* <ul>* <li>Whenever it is invoked on the same object more than once during* an execution of a Java application, the {@code hashCode} method* must consistently return the same integer, provided no information* used in {@code equals} comparisons on the object is modified.* This integer need not remain consistent from one execution of an* application to another execution of the same application.* <li>If two objects are equal according to the {@code equals(Object)}* method, then calling the {@code hashCode} method on each of* the two objects must produce the same integer result.* <li>It is <em>not</em> required that if two objects are unequal* according to the {@link java.lang.Object#equals(java.lang.Object)}* method, then calling the {@code hashCode} method on each of the* two objects must produce distinct integer results. However, the* programmer should be aware that producing distinct integer results* for unequal objects may improve the performance of hash tables.* </ul>* <p>* As much as is reasonably practical, the hashCode method defined by* class {@code Object} does return distinct integers for distinct* objects. (This is typically implemented by converting the internal* address of the object into an integer, but this implementation* technique is not required by the* Java™ programming language.)** @return a hash code value for this object.* @see java.lang.Object#equals(java.lang.Object)* @see java.lang.System#identityHashCode*/public native int hashCode();
简单翻一下三条协定:
- 同一个Java程序执行中,多次调用hashCode方法返回值必须一致;如果是程序的多次执行,则每一次可以不同。
- equals方法声明相等的对象必须具有相等的哈希代码。
- 如果两个对象equals返回false,hashCode 则不是必须相同。It is not required that…
equals 方法的说明
:::danger
Note that it is generally necessary to override the hashCode method whenever this method is overridden, so as to maintain the general contract for the hashCode method, which states that equal objects must have equal hash codes.
请注意,通常需要在重写此方法时覆盖hashCode方法,以便维护hashCode方法的常规协定, 该方法声明相等的对象必须具有相等的哈希代码 。意思就是 equals 方法返回true,hashCode要相等,反正不成立,因为hash碰撞/冲突无法避免。 :::
HashMap的使用
HashMap是应用更加广泛的哈希表实现,非同步, 支持null键和值 。通常情况下,HashMap进行put/get操作可以达到常数时间的性能,所以它是绝大部分利用键值对存取场景的首选。
初始化对象
新增,删除
遍历方法等
Map整体架构
HashMap 深入分析
HashMap内部结构,可以看做是数据和链表组合成的复合结构,数组被分为一个个桶 bucket,通过哈希值决定了键值对在在这个数组的寻址;哈希值相同的键值对,则以链表形式存储。这里需要注意的是,如果链表大小超过阈值(TREEIFY_THRESHOLD, 8),图中的链表就会被改造为树形结构。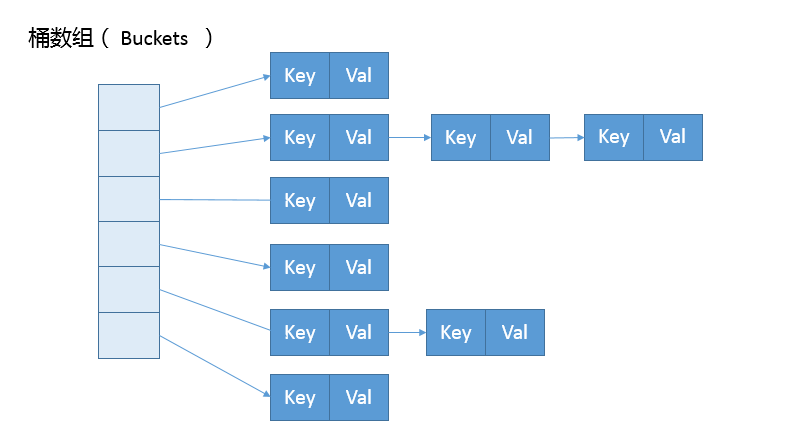
构造方法之一:
/*** Constructs an empty <tt>HashMap</tt> with the specified initial* capacity and load factor.** @param initialCapacity the initial capacity* @param loadFactor the load factor* @throws IllegalArgumentException if the initial capacity is negative* or the load factor is nonpositive*/public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);}
从实现来看,这个表格(数组)并没有在最初就初始化完成,仅仅设置了一些初始值而已。put 方法
/*** Associates the specified value with the specified key in this map.* If the map previously contained a mapping for the key, the old* value is replaced.** @param key key with which the specified value is to be associated* @param value value to be associated with the specified key* @return the previous value associated with <tt>key</tt>, or* <tt>null</tt> if there was no mapping for <tt>key</tt>.* (A <tt>null</tt> return can also indicate that the map* previously associated <tt>null</tt> with <tt>key</tt>.)*/public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}/*** Implements Map.put and related methods.** @param hash hash for key* @param key the key* @param value the value to put* @param onlyIfAbsent if true, don't change existing value* @param evict if false, the table is in creation mode.* @return previous value, or null if none*/final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}
resize() 方法初始化,扩容
hash 值的方法:将高位数据移位到低位进行异或运算。
有些数据计算出的哈希值差异主要在高位,而HashMap里的哈希寻址是忽略容量以上的高位的,那么这种处理就可以有效避免类似情况下的哈希碰撞。
很难理解…
_
/*** Computes key.hashCode() and spreads (XORs) higher bits of hash* to lower. Because the table uses power-of-two masking, sets of* hashes that vary only in bits above the current mask will* always collide. (Among known examples are sets of Float keys* holding consecutive whole numbers in small tables.) So we* apply a transform that spreads the impact of higher bits* downward. There is a tradeoff between speed, utility, and* quality of bit-spreading. Because many common sets of hashes* are already reasonably distributed (so don't benefit from* spreading), and because we use trees to handle large sets of* collisions in bins, we just XOR some shifted bits in the* cheapest possible way to reduce systematic lossage, as well as* to incorporate impact of the highest bits that would otherwise* never be used in index calculations because of table bounds.*/static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
继续深入方向:
- 梳理几个方法的逻辑流程,如
resize()putVal()treeifyBin - 为什么要树化,如何构造hash相等的对象?
困的不行了,肝不动了,睡了,明天继续!…
6-8 pm
10-12.30 pm
4.5h
老师我想问一下,hashmap明明继承了abstractmap,而abstractmap已经实现了map接口,为什么hashmap还要实现map接口呢?
https://stackoverflow.com/questions/2165204/why-does-linkedhashsete-extend-hashsete-and-implement-sete

若有收获,就点个赞吧
0 人点赞
