Kafka & ZooKeeper
Kafka

极客时间专栏笔记
Kafka 属于分布式的消息引擎系统,它的主要功能是提供一套完备的消息发布与订阅解决方案。在Kafka中,发布订阅的对象是主题(Topic),你可以为每个业务,每个应用甚至是每类数据都创建专属的主题。
生产者Producer;消费者Consumer;统称为客户端Clients。
Kafka 的服务端由被称为Broker 的服务进程组成,即一个Kafka集群由多个 Broker组成,Broker负责接收和处理客户端发送过来的请求,以及对消息进行持久化。通常是将不同的Broker 分散运行在不同的服务器上。
备份机制 Replication,副本 Replica;领导者副本 Leader Relica 和 追随者副本 Follower Relica;前者对外提供服务,与客户端进行交互,后者只是被动的追随领导者副本。
副本的工作机制也很简单:生产者总是向领导者副本写消息;而消费者总是从领导者副本读消息。至于追随者副本,它只做一件事:向领导者副本发送请求,请求领导者把最新生产的消息发给它,这样它能保持与领导者的同步。
伸缩性 Scalability ; 分区 Partitioning
Kafka 的三层消息架构:
第一层是主题层,每个主题可以配置 M 个分区,而每个分区又可以配置 N 个副本。
第二层是分区层,每个分区的 N 个副本中只能有一个充当领导者角色,对外提供服务;其他 N-1 个副本是追随者副本,只是提供数据冗余之用。
第三层是消息层,分区中包含若干条消息,每条消息的位移从 0 开始,依次递增。
最后,客户端程序只能与分区的领导者副本进行交互。
Kafka 使用消息日志(Log)来保存数据,一个日志就是磁盘上一个只能追加写(Append-only)消息的物理文件。因为只能追加写入,故避免了缓慢的随机 I/O 操作,改为性能较好的顺序 I/O 写操作,这也是实现 Kafka 高吞吐量特性的一个重要手段。
日志段(Log Segment)机制
两种消息模型,即点对点模型(Peer to Peer,P2P)和发布订阅模型
重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。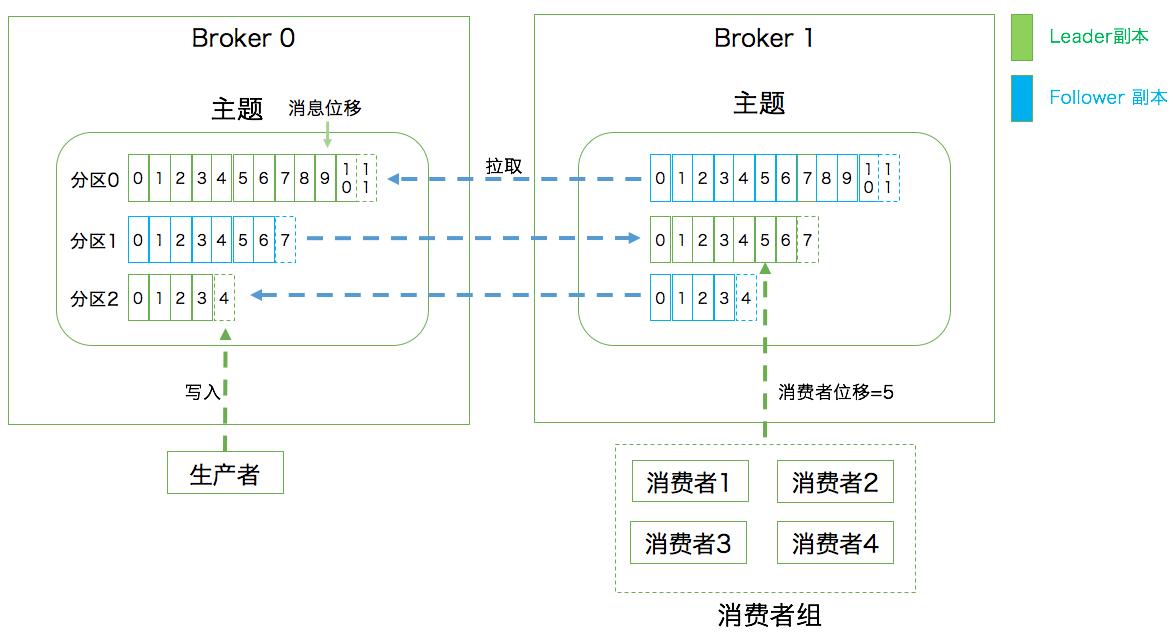
Zookeeper
zookeeper 是什么?
zookeeper 是一个分布式的,开放源码的分布式应用程序协调服务,是 google chubby 的开源实现,是 hadoop 和 hbase 的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
zookeeper 都有哪些功能?
- 集群管理:监控节点存活状态、运行请求等。
- 主节点选举:主节点挂掉了之后可以从备用的节点开始新一轮选主,主节点选举说的就是这个选举的过程,使用 zookeeper 可以协助完成这个过程。
- 分布式锁:zookeeper 提供两种锁:独占锁、共享锁。独占锁即一次只能有一个线程使用资源,共享锁是读锁共享,读写互斥,即可以有多线线程同时读同一个资源,如果要使用写锁也只能有一个线程使用。zookeeper可以对分布式锁进行控制。
- 命名服务:在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。
zookeeper 有几种部署模式?
zookeeper 有三种部署模式:
- 单机部署:一台集群上运行;
- 集群部署:多台集群运行;
- 伪集群部署:一台集群启动多个 zookeeper 实例运行。
zookeeper 怎么保证主从节点的状态同步?
zookeeper 的核心是原子广播,这个机制保证了各个 server 之间的同步。实现这个机制的协议叫做 zab 协议。 zab 协议有两种模式,分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,zab 就进入了恢复模式,当领导者被选举出来,且大多数 server 完成了和 leader 的状态同步以后,恢复模式就结束了。状态同步保证了 leader 和 server 具有相同的系统状态。
集群中为什么要有主节点?
在分布式环境中,有些业务逻辑只需要集群中的某一台机器进行执行,其他的机器可以共享这个结果,这样可以大大减少重复计算,提高性能,所以就需要主节点。
集群中有 3 台服务器,其中一个节点宕机,这个时候 zookeeper 还可以使用吗?
可以继续使用,单数服务器只要没超过一半的服务器宕机就可以继续使用。
说一下 zookeeper 的通知机制?
客户端端会对某个 znode 建立一个 watcher 事件,当该 znode 发生变化时,这些客户端会收到 zookeeper 的通知,然后客户端可以根据 znode 变化来做出业务上的改变。
有时候真的很无奈,分布式系统设计就像是一个追着自己尾巴咬的喵喵,兜兜转转回到开头。
关于 CAP 原理,更准确的说法是,在分布式系统必须要满足分区耐受性的前提下,可用性和一致性无法同时满足。

若有收获,就点个赞吧
0 人点赞
