时间序列数据库 Time Series Database (TSDB) 是用于存储、检索时间序列数据的数据库。时间序列数据就是数据格式里包含 timestamp 字段的数据。
概念&术语
为了深入理解 TSDB,您最好先了解一下 TSDB 的一些关键概念。在七牛 TSDB 产品中,常用到的术语有以下几个:
repo series point retentiontimestamp field key field valuetag key tag value 索引值组合
示例数据
以一个示例数据为例来解析一下以上概念,这些数据是伪造的,它们显示了 2017 年 12 月 29 日 上午 9:00 至 2017 年 12 月 29 日上午 10:12 期间 8 位顾客在某购物平台购买食物的记录,数据存在名为 food 的数据仓库中,其中,cookie 和 apple 是 field key,source 和 customer 是 tag key:
repo: foodseries: test_series----------time cookie apple source customer2017/12/29T09:00:00Z 4 2 mobile Mark2017/12/29T09:00:00Z 5 2 mobile Bin2017/12/29T09:06:00Z 8 5 website Hasson2017/12/29T09:06:00Z 6 4 mobile Paul2017/12/29T09:54:00Z 2 4 mobile Joey2017/12/29T10:00:00Z 5 4 website Mary2017/12/29T10:06:00Z 4 6 mobile Qian2017/12/29T10:12:00Z 10 3 website Loris
数据仓库(repo)
TSDB 里数据仓库类似于关系型数据库里数据库的概念。
序列(series)
记录同一个信息的数据点按照时间的先后排列形成的集合叫做序列。您可以将序列理解为类似于关系型数据库里表(table)的概念,在上述数据例子中,序列 test_series 包含 8 个数据点,每个数据点记录的是某个用户在某个时间点通过网站还是移动端购买苹果和饼干的数量的信息。
数据点(point)
数据点是存储数据的基本单位,每个数据点包含若干个索引(tag key)用于对数据点进行检索,包含若干个数据字段(field key)用于存储实际的数值,一个时间戳。一个 series 里面有多个 point。在上述例子中,数据点是一条由 time、 cookie、 apple、 source、 customer的值形成的记录。
存储时限(retention)
在 TSDB 创建序列时,我们需要指定 retention ,它的意思是指,任何一个数据点从写入序列开始,当存储的时间超过 retention 指定的时间后,这一条数据将会被自动删除。
时间戳(timestamp)
时间戳标识了在任何给定数据序列中的单个点,在上面的数据中用time表示时间戳, 这个时间戳以 RFC3339 格式展示了与特定数据相关联的UTC日期和时间,可精确到纳秒级。在 TSDB 中所有数据都有这一列。
数据字段(field key)& 数据值(field value)
我们通常用 field key 存储实际要查询的值,支持对 field key 进行函数运算(如 sum()、mean()、count()等)。
field value 就是您的数据,它们可以是字符串、浮点数、整数、布尔值。因为 TSDB 是时间序列数据库,所以 field value 总是和时间戳相关联。
索引字段(tag key)& 索引值(tag value)
tag key 一般用于对数据点进行检索(匹配、分组),tag value 以字符串的形式存储。
我们用一个例子来解释索引的好处:
假如您的查询集中在字段 cookie 上:
SELECT * FROM test_series WHERE cookie = 4
这种情况下,时序数据库会扫描所有 cookie 的值,然后返回结果。这样会造成请求时间很长,特别是在数据范围更大时;为了优化查询,提升效率,我们重新设计数据结构,把 cookie 改成 tag key。
那么 SQL 语句:
SELECT * FROM test_series WHERE cookie = 4
现在只扫描 cookie = 4 的值,大大提升查询效率。
除此之外,tag key 可以用来对查询结果分组。了解更多 field key , tag key , timestamp 的查询语法,请阅读 查询语法。
索引值组合
在 TSDB 中,我们提出索引值组合的概念。所有的 tag value 形成索引值组合。
索引值组合的计数方式为:
索引值组合的数量 = tag key 1 的 value 数量 * tag key 2 的 value 数量 * …… * tag key n 的 value 数量
上述例子的索引值为 8 * 2 = 16。
多个 series 的索引值组合即将多个 series 的索引值加起来。
例:
假设现在有 series1 和 series2 ,其中 series1 中包含 a,b,c 共3 个 tag key,每个 tag key 有 3 个 tag value,而 series2 中包含d,e,f,g 共 4 个 tag key,每个 tag key 有 2 个 tag value那么这个例子的索引值组合为:3 * 3 * 3 + 2 * 2 * 2 * 2= 43
索引值组合的数量是 TSDB 的计费标准之一,您在设计 schema 的时候需要考虑到这一点。
一个序列里并不一定需要 tag key,但是使用 tag key 总是大有裨益。关于如何设计序列的 schema,请阅读 schema 设计。
操作指南
写入数据
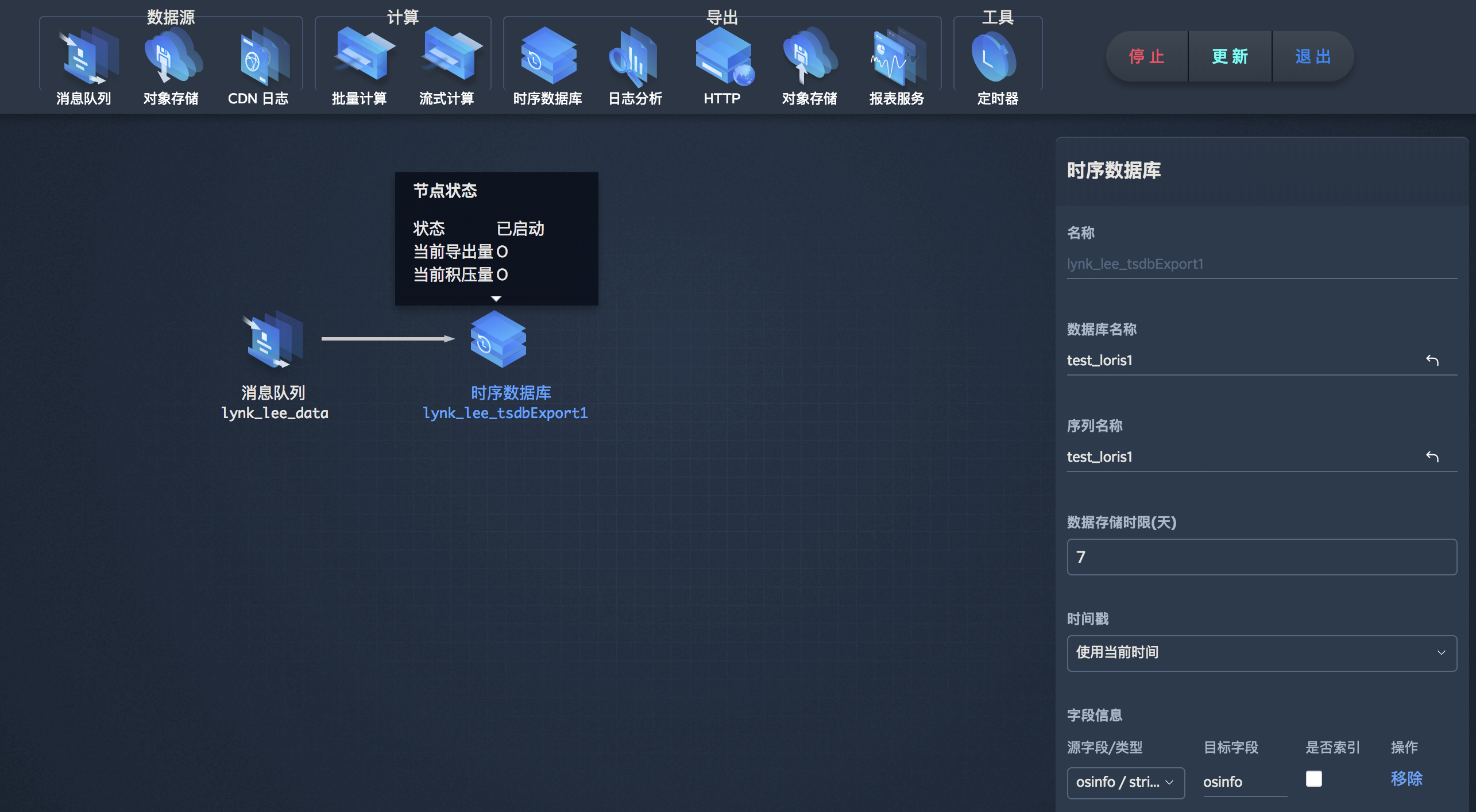
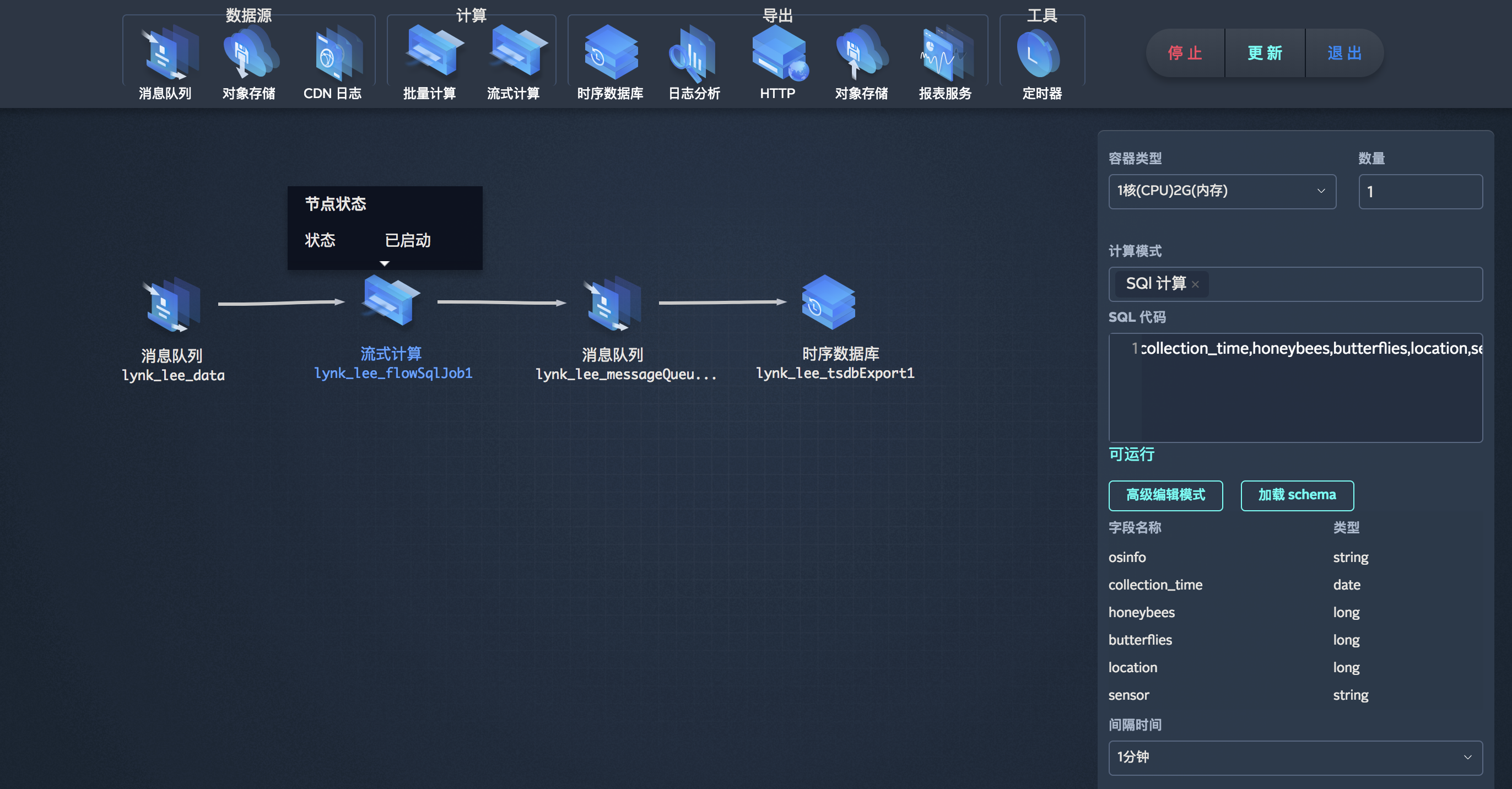
向 TSDB 写入数据首先需要将数据打入 workflow 的消息队列节点,直接或者经过数据计算再通过 TSDB 数据导出节点将数据打入 TSDB。关于具体使用工作流打入数据到 TSDB 的用法,请阅读工作流。
直接导出
经过数据计算导出
创建仓库和序列
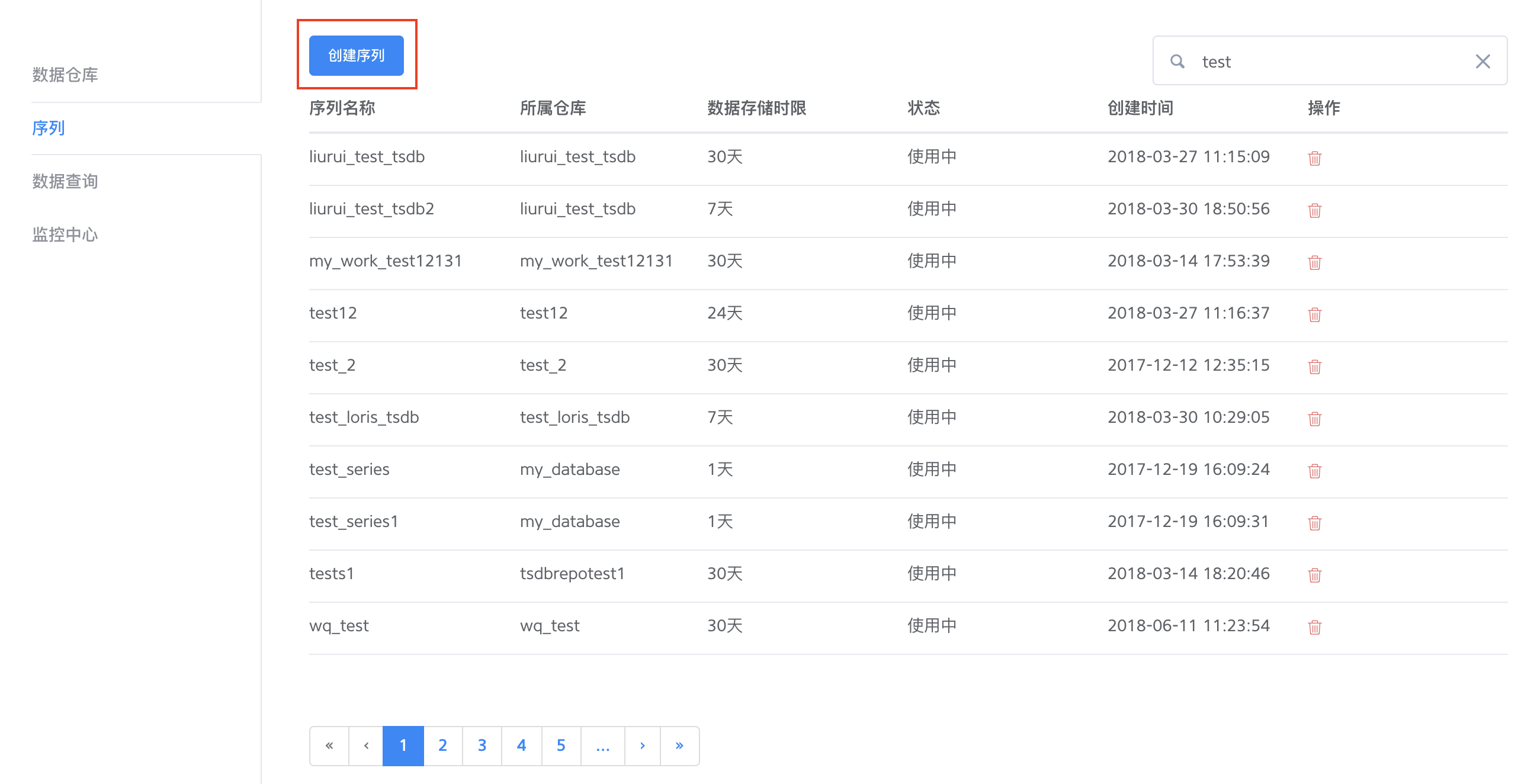
通过 TSDB 查询数据,首先您需要有用来存放数据的仓库和序列。通过七牛开发者平台的时序数据库进入创建仓库和序列入口。
将数据打入 TSDB 时,在 workflow的 TSDB 数据导出节点,选择已有的仓库和序列即可。

或者,在workflow中将数据导出到 TSDB 时,直接创建新的数据仓库和序列,输入您想创建的仓库和序列名即可。
由于 TSDB 的数据的时序特点,您可以随时向仓库中打入新的序列、field key、tag key。
建立索引
您可以根据查询需要将指定字段设置为索引(tag key),提高查询效率。在workflow的 TSDB 数据导出节点,输入好仓库名和序列名以后,您可以看到打入到序列中的数据点的字段及其类型,并且可以直接通过勾选设置字段为索引,非常直观。建立好索引以后,任务需要重新运行索引才会生效。

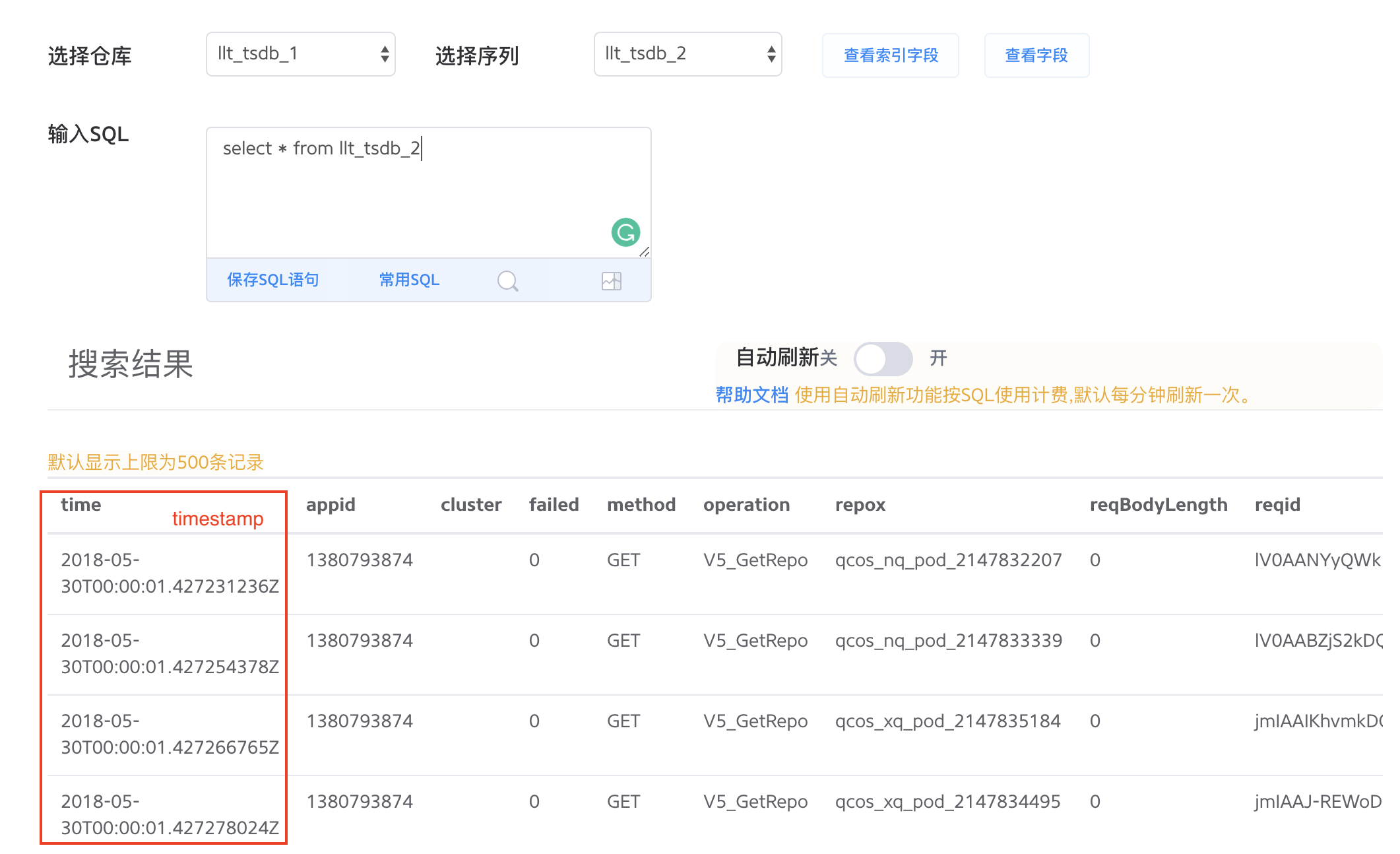
查询数据
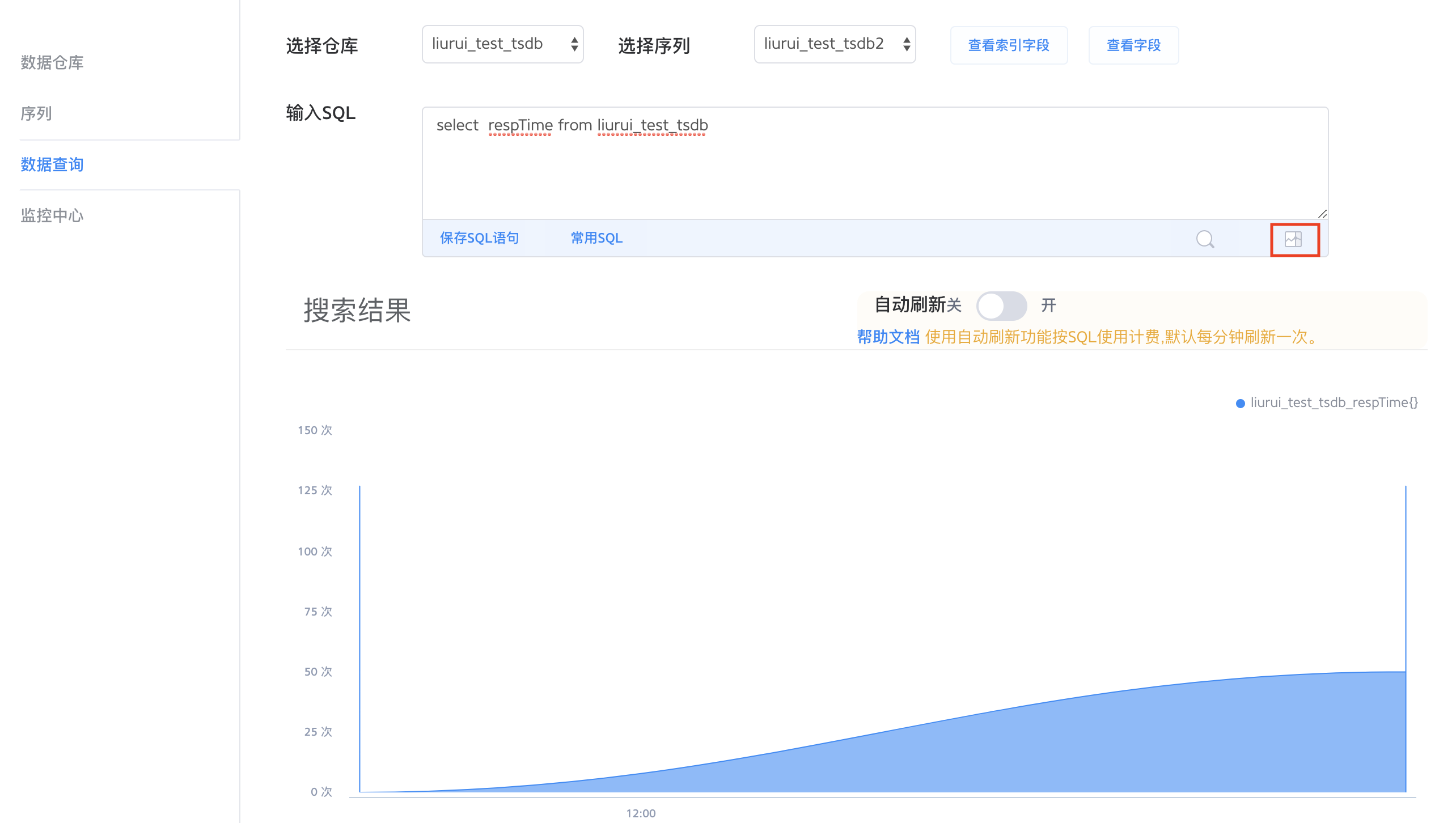
在 TSDB 的数据查询页面,通过选择仓库和序列,输入类 SQL 查询语句,点击输入框右下角的搜索图标即可查询到您关心的数据。
TSDB 提供普通字段和索引字段预览,通过点击 查看索引字段、 查看字段 来预览该序列里面的索引字段和普通字段。当您想查询数据却遗忘序列里的数据结构时可以使用这个功能,您可以根据字段预览正确地使用查询语句。

在这个例子中,clientIP、 hitMiss、 method、 userAgent 是 tag key。
我们查询以 field key respTime 为查询主体,tag key clientIp 为分组条件的数据:

结果如图,数据已经按照 clientIp 分好组,每个分组下面显示详细 respTime 的值。

快速查询
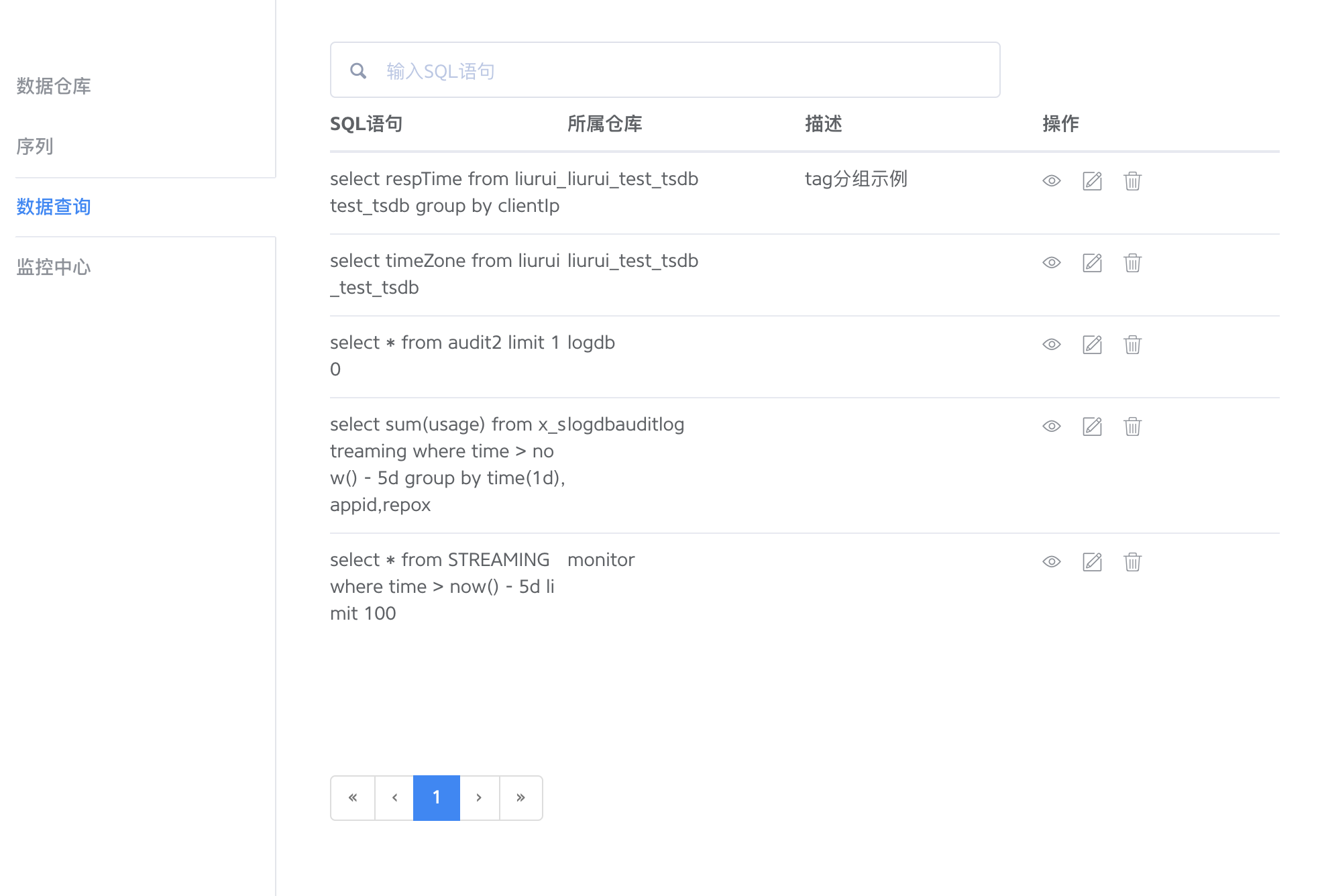
通过 TSDB 的保存SQL语句和常用SQL两个按钮,您可以实现快速查询。点击保存SQL语句将输入过的查询语句保存,下次查询时点击常用SQL选择记录即可快速查询,避免重复输入工作。
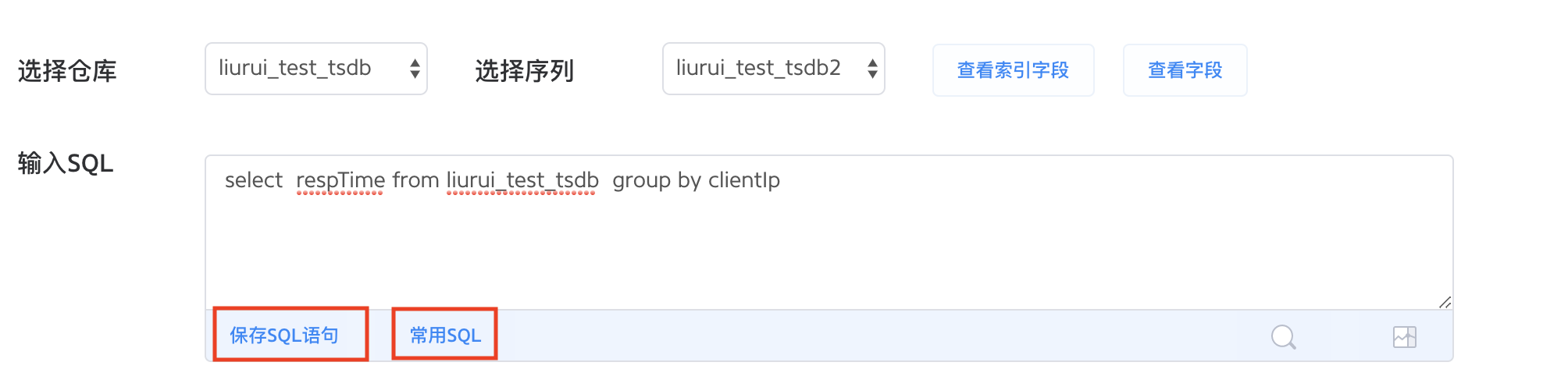
您可以对记录里的查询语句进行编辑或者删除操作。
统计图表
TSDB 提供查询结果的可视化功能,点击输入框右下角的图表图标,您可以看到指定字段的数据在某个时间范围内的滚动情况。在某些场景下您需要快速地获得数据在一定时间范围内的变化情况,如:节日高峰期交警要依据各个路口的车流量统计图来安排出警。
schema 设计
schema 设计没有固定的标准,但是在使用过程中,遵循以下建议可以给您省去一些麻烦。
哪些情况下可以使用 tag
- 将可以枚举字段作为 tag
- 如果您要对某字段使用 GROUP BY(),将其作为 tag,参考购物示例数据
哪些情况下使用 field
- 如果您要对某字段使用函数运算,将其作为 field
- 如果您需要存储的值不是字符串,最好将其作为 field,因为 tag value 以字符串存储
避免 TSDB 中关键字作为标识符名称
在时序数据库中,我们有很多系统关键字,在命名的过程中,我们应该避免使用这些关键字(包括大小写)。
系统关键字
| server | repo | view | tagKey | ILLEGAL |
|---|---|---|---|---|
| EOF | WS | IDENT | BOUNDPARAM | NUMBER |
| INTEGER | DURATIONVAL | STRING | BADSTRING | BADESCAPE |
| TRUE | FALSE | REGEX | BADREGEX | ADD |
| SUB | MUL | DIV | AND | OR |
| EQ | NEQ | EQREGEX | NEQREGEX | LT |
| LTE | GT | GTE | LPAREN | RPAREN |
| COMMA | COLON | DOUBLECOLON | SEMICOLON | DOT |
| ALL | ALTER | ANY | AS | ASC |
| BEGIN | BY | CREATE | CONTINUOUS | DATABASE |
| DATABASES | DEFAULT | DELETE | DESC | DESTINATIONS |
| DIAGNOSTICS | DISTINCT | DROP | DURATION | END |
| EVERY | EXISTS | EXPLAIN | FIELD | FOR |
| FROM | GROUP | GROUPS | IF | IN |
| INF | INSERT | INTO | KEY | KEYS |
| KILL | LIMIT | MEASUREMENT | MEASUREMENTS | NAME |
| NOT | OFFSET | ON | ORDER | PASSWORD |
| POLICY | POLICIES | PRIVILEGES | QUERIES | QUERY |
| READ | REPLICATION | RESAMPLE | RETENTION | REVOKE |
| SELECT | SERIES | SET | SHOW | SHARD |
| SHARDS | SLIMIT | SOFFSET | STATS | SUBSCRIPTION |
| SUBSCRIPTIONS | TAG | TO | TIME | VALUES |
| WHERE | WITH | WRITE |
查询语法
TSDB 提供类 SQL 语句来实现查询。
示例数据
数据来源:国家海洋和大气管理局(NOAA)海洋作业和服务中心的公开数据。
repo: NOAA_water_reposeries: waterLevelInfo----------time level description location water_level2015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.122015-08-18T00:00:00Z below 3 feet santa_monica 2.0642015-08-18T00:06:00Z between 6 and 9 feet coyote_creek 8.0052015-08-18T00:06:00Z below 3 feet santa_monica 2.1162015-08-18T00:12:00Z between 6 and 9 feet coyote_creek 7.8872015-08-18T00:12:00Z below 3 feet santa_monica 2.028
waterLevelInfo 这个序列中的数据以六分钟的时间间隔进行收集。序列有一个tag key(location),它具有两个 tag value : coyote_creek 和 santa_monica。序列中还有两个 field key:level description:字符串类型和 water_level:浮点型。所有这些数据都在 NOAA_water_repo 数据仓库中。
声明:
level description字段不是原始NOAA数据的一部分
基本 SELECT 语句
select *:返回所有 tag key 和 field key;但一般不建议这么写,非常消耗性能,并且费用很高;select "<field_key>":返回一个特定的 field key;select "<field_key>","<field_key>":返回多个特定的 field key;select "<field_key>","<tag_key>":返回特定的 field key 和 tag key;
!>注意1:tag key 不能单独作为查询主体,任何一个查询主体至少包含 1 个 field key;
!>注意2:如果标识符号包含除了[A-z,0-9,_]之外的符号,或者包含时序数据库的关键字,又或者以数字开头,那么必须用双引号""括起来。
函数运算
函数运算只能作用于field key。
目前 TSDB 支持的函数有以下几种:
| 函数名 | 解释 |
|---|---|
| count | 求总数 |
| sum | 求总和 |
| mean | 求平均值 |
| distinct | 去除重复内容 |
| max | 取最大值 |
| min | 取最小值 |
| bottom(filed key,N) | 取最小的N个值 |
| top(filed key,N) | 取最大的N个值 |
| first | timestamp 最新的值 |
| last | timestamp 最老的值 |
| difference(filed key,time interval) | 指定一个字段隔一段时间,比较其内容,此函数不保证精确 |
difference举例:select difference(water_level,6m) from waterLevelInfo
WHERE 语句
WHERE 语句允许使用 field key,tag key,timestamp 来对数据进行筛选。
WHERE 语句中使用field key时,支持以下运算符:
| 运算符 | 解释 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
WHERE 语句中使用tag key时,支持以下运算符:
| 运算符 | 解释 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
WHERE 语句中使用timestamp时,支持以下运算符:
| 运算符 | 解释 |
|---|---|
| = | 等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
当使用时间字段(timestamp 或者序列里面的其他时间字段)作为过滤条件时,我们可以使用now()函数,它表示当前时间,并且支持运算;
例:
select mean(water_level),location from waterLevelInfo where time > now() - 5mselect mean(water_level),location from waterLevelInfo where time > now() - 3d and time < now() - 1dselect mean(water_level),location from waterLevelInfo where time > '2017-01-01T13:00:00Z'
!> 注意1: now()表示当前时间, '-'符号的左右两边都必须至少包含一个空格。
!> 注意2:s=秒,m=分,h=小时,d=天
!> 注意3: 字符串类型的值要用单引号括起来。具有无引号字符串字段值或双引号字符串字段值的查询将不会返回任何数据,并且在大多数情况下也不会返回错误。
GROUP BY 语句
GROUP BY 语句可以作用于tag key和timestamp。
GROUP BY
语法规则:
| 语法 | 解释 |
|---|---|
group by * |
根据所有tag key进行分组 |
group by <tag_key> |
根据指定tag key进行分组 |
group by <tag_key>,<tag_key> |
根据多个tag key进行分组 |
GROUP BY 时间间隔
group by time()返回按指定的时间间隔聚合的结果。
语法规则:
| 语法 | 解释 |
|---|---|
group by <timestamp> |
将查询结果按指定时间间隔聚合 |
group by <timestamp>,<tag_key> |
将查询结果按指定时间间隔聚合并根据 tag key 分组 |
例:
select mean(water_level) from waterLevelInfo where time >= '2015-08-18T00:00:00Z' and time <= '2015-08-18T00:42:00Z'group by time(5m)select count(water_level) from waterLevelInfo where time >= '2015-08-18T00:00:00Z' and time <= '2015-08-18T00:30:00Z' group by time(12m),location
第一条查询语句的意思是返回在指定的时间范围内将查询结果按五分钟间隔聚合分组的 water_level 均值。
第二条查询语句的意思是返回在指定的时间范围内将查询结果按十二分钟间隔聚合分组的 water_level 总和,并按照 location 分组显示。该条语句的查询结果如下:
tags: location=coyote_creektime count---- -----2015-08-18T00:00:00Z 22015-08-18T00:12:00Z 22015-08-18T00:24:00Z 2tags: location=santa_monicatime count---- -----2015-08-18T00:00:00Z 22015-08-18T00:12:00Z 22015-08-18T00:24:00Z 2
!> 注意1:对于大多数 select 语句,默认时间范围为UTC的 1677-09-21 00:12:43.145224194 到 2262-04-11T23:47:16.854775806Z。对于按时间聚合 即 group by time()条件语句的 select 语句,默认时间范围在UTC的 1677-09-21 00:12:43.145224194 和 now() 之间。
ORDER BY 语句
默认情况下,TSDB 以时间升序返回结果; 返回的第一个点具有最早的时间戳,返回的最后一个点具有最新的时间戳。ORDER BY time DESC反转该顺序,使得 TSDB 首先返回具有最新时间戳的点。
如果查询语句同时包含 WHERE 语句、GROUP BY 语句、ORDER BY 语句,它们的出现顺序是:
SELECT_clause FROM_clause [WHERE_clause] [GROUP_BY_clause] ORDER BY time DESC
例:
select mean(water_level) from waterLevelInfo order by time DESCselect mean(water_level) from waterLevelInfo where time >= '2015-08-18T00:00:00Z' and time <= '2015-08-18T00:42:00Z'group by time(5m) order by time DESC
第一条查询语句从 waterLevelInfo 序列返回按时间戳降序排列的 water_level 的平均值。
第二条查询语句从 waterLevelInfo 序列返回在指定时间范围内按时间戳降序排列的每5分钟间隔的 water_level 均值。
!>注意:在 TSDB 里 ORDER BY 只能作用于timestamp,不能作用于tag key和field key。

若有收获,就点个赞吧
0 人点赞
