日志分析服务(LogDB)提供针对日志类数据的存储、检索与分析服务,同时具备监控与报警功能,帮助用户提升运维、运营效率,快速查找和定位问题,如排查服务器障碍、在线业务监控、应用程序Bug跟踪分析等。
概念&术语
repo fields analyzer retention
日志仓库(repo)
日志仓库集中保存了我们从实时数据仓库导入的日志,支持多种数据类型以及多种索引方式,支持基于文本的搜索、过滤和分析。
字段(fields)
在日志分析服务中,数据字段支持的类型有以下几种:
| 类型 | 解释 | 数据样例 |
|---|---|---|
| long | 64位整数 | 998 |
| float | 单精度64位浮点 | 10.24 |
| date | 日期类型,默认格式为RFC3339,可自定义格式 | 2017-01-01T15:00:25Z07:00 |
| string | 字符串类型,可设置分词器和主键 | “qiniu.com” |
| boolean | 布尔类型,值为true或false | false |
| object | json格式 | - |
| ip | ip地址 | 127.0.0.1 |
| geo_point | 经纬度坐标 | [ -71.34, 41.12 ] |
索引方式
日志分析服务最大的优势在于可以对字符串类型的数据进行倒排索引,可以使用搜索引擎的技术对于日志进行索引,并且支持各种灵活的搜索方式。其中索引的方式包括两种:
分字段索引
分字段索引可以允许用户挑选字符串字段,选择灵活的分词和索引方式。可以参考文末的Lucene语法(如 log:Error 代表在log字段中搜索Error单词) 对数据进行搜索、过滤和分析。使用分字段索引的时候可以指定仅仅对某些字段进行分词,降低存储成本,提高写入和检索效率。

全文索引
全文索引表示指定固定的分词索引方式,为所有的字段创建跨字段的索引。
使用全文索引使您在检索的时候直接输入文本即可搜索,如直接在搜索框中输入:
"writepoints"
当然,也可以像分字段索引一样指定查询字段,进行检索,如:
operation:"writepoints"
如果您的字段特别多,或者字段是非常复杂的嵌套结构,此时我们非常推荐您选择全文索引,会使搜索更加便利和灵活。 不过要注意:全文索引会增加存储成本,而且无法在存储时挑选部分字段索引,也无法单独为某些字段设置分词器。

分词方式(analyzer)
您可以根据自己的搜索习惯和需求,对日志中的field设置分词方式,目前日志分析服务提供以下几种分词方式:
不分词
不分词的含义其实是“keyword分词”,意思就是,你必须完整的输入某一个field的内容,才能被搜索到,我们举个例子来说明:
假设目前有1个field为A,它的内容是"abcdefg"假设我们选择了不分词方式,那么如果想搜索到这一条内容,需要在条件框输入:A:"abcdefg"这样才能搜索到,如果我们按照以下几种方式,则无法搜索到:A:"a"A:"abc"A:"edf"
不分词不索引
不分词不索引的含义是指:在任何情况下,输入任何条件,都不会搜索到该field的内容,但在搜索其他field时,如果是整条搜索,那么这个field的内容也会显示出来。
假设现在有2个field,分别为:A:"abcdefg",B:"12345678"其中,B设置了不分词不索引,无论我们在条件框输入有关B的任何条件,都不会搜索到
标准分词
以unicode字符作为结束的标识,过滤掉大部分标点符号,将所有字母变为小写,搜索时只要符合搜索条件的词语出现,就会被搜索到。
假设现在有1个field为A,它的内容是"linux-chrome,what's your&name?"那么使用标准分词,将会被分为:"linux,chrome,what's,your,name"我们的搜索条件包含这些词时,会被搜索到
!> 注意:标准分词只适用于全英文字符的field。
空白分词
以单词头部和尾部的空格作为分割条件,输入两个空格内的完整内容,即可搜索到相应内容。
例:A="张三 李四 王五"需要输入以下条件,均可搜到内容:A:"张三"A:"李四"A:"王五"如果输入以下条件,则无法搜索到内容:A:"张"A:"张三 李四"
path分词
以linux系统路径来进行分词,当搜索时,可以输入完整的路径或者路径前缀来进行匹配,如果输入的条件不是一个正确的前缀,那么将无法正确呈现日志内容。
例:filed A="/usr/local/action.log"那么需要输入以下条件,均可搜到内容:A:"/usr"A:"/usr/local"A:"/usr/local/action.log"如果输入以下条件,则无法搜索到内容:A:"/u"A:"usr"A:"/action.log"
中文分词
logdb 支持中文语义分词。即输入一段汉字序列里的词组,就可搜索到相应内容。
例:A="我爱杭州"输入以下条件,均可搜到内容:A:"我"A:"我爱"A:"杭州"A:"爱杭州"
存储时限(retention)
创建仓库时,我们需要指定这个属性,它的意思是指这个仓库内的每一条日志都会被存储和retention一致的天数,超过这个时间的数据会被自动删除,当retention指定为0时,表示永久存储。
数据接收
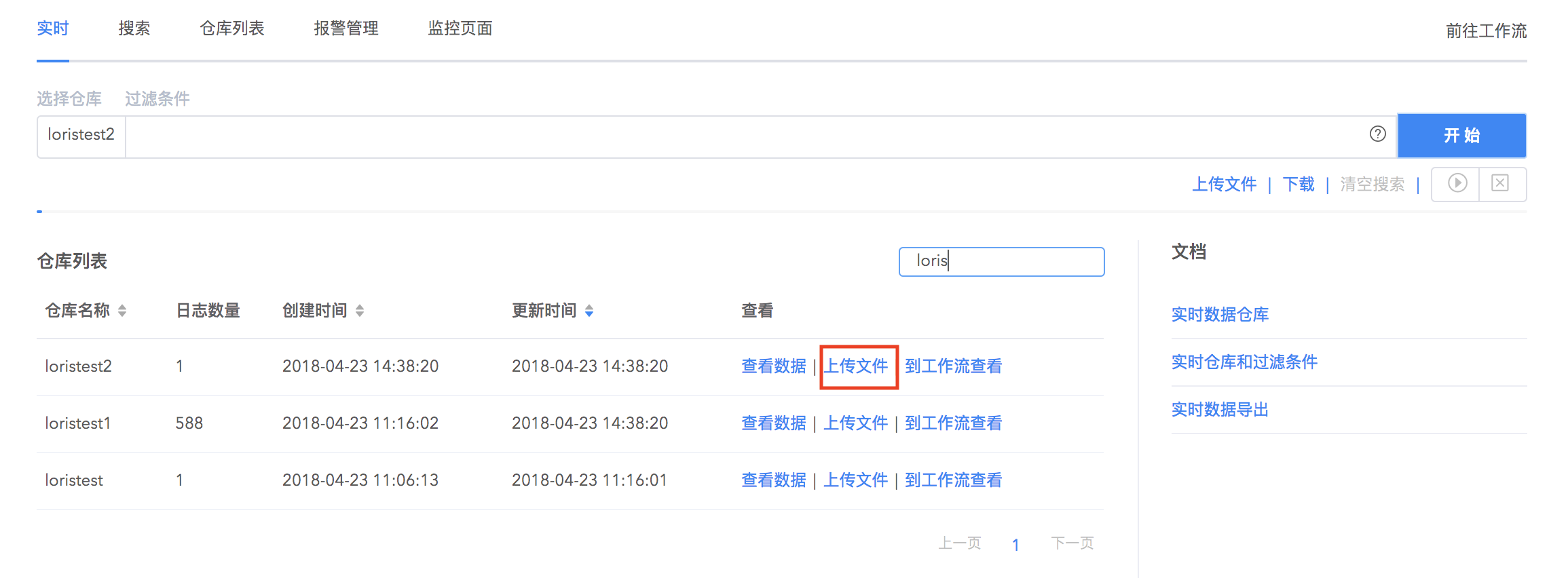
文件上传
logdb 支持直接上传本地日志文件到实时仓库中,并对上传数据进行解析,结构化日志内容,方便您在实时仓库中对数据进行搜索。无需借助第三方工具打入数据,直接对已有存量数据快速接入。
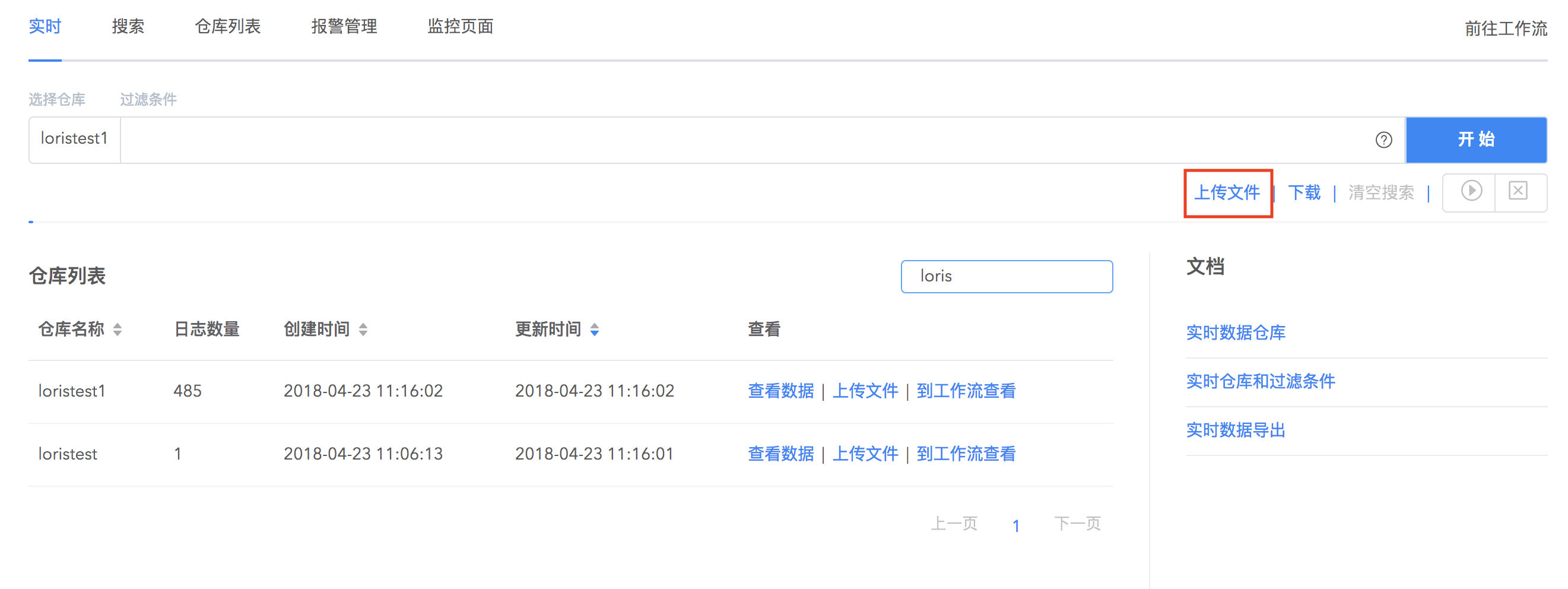
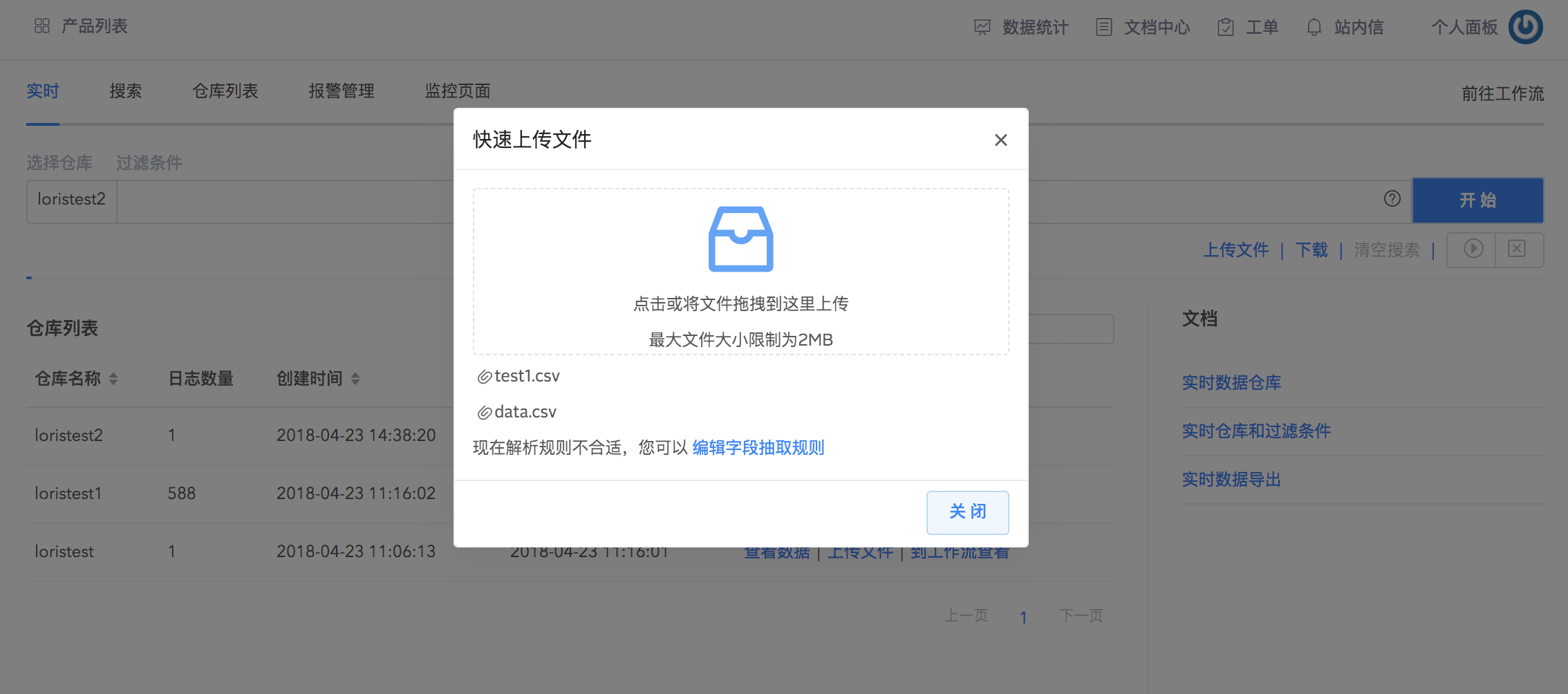
1.点击搜索栏下面的上传文件按钮,开始上传本地文件(不超过 2MB)到目的仓库中并配置解析规则,可以选择已有仓库或者创建新的仓库。文件上传完成后,点击下一步。
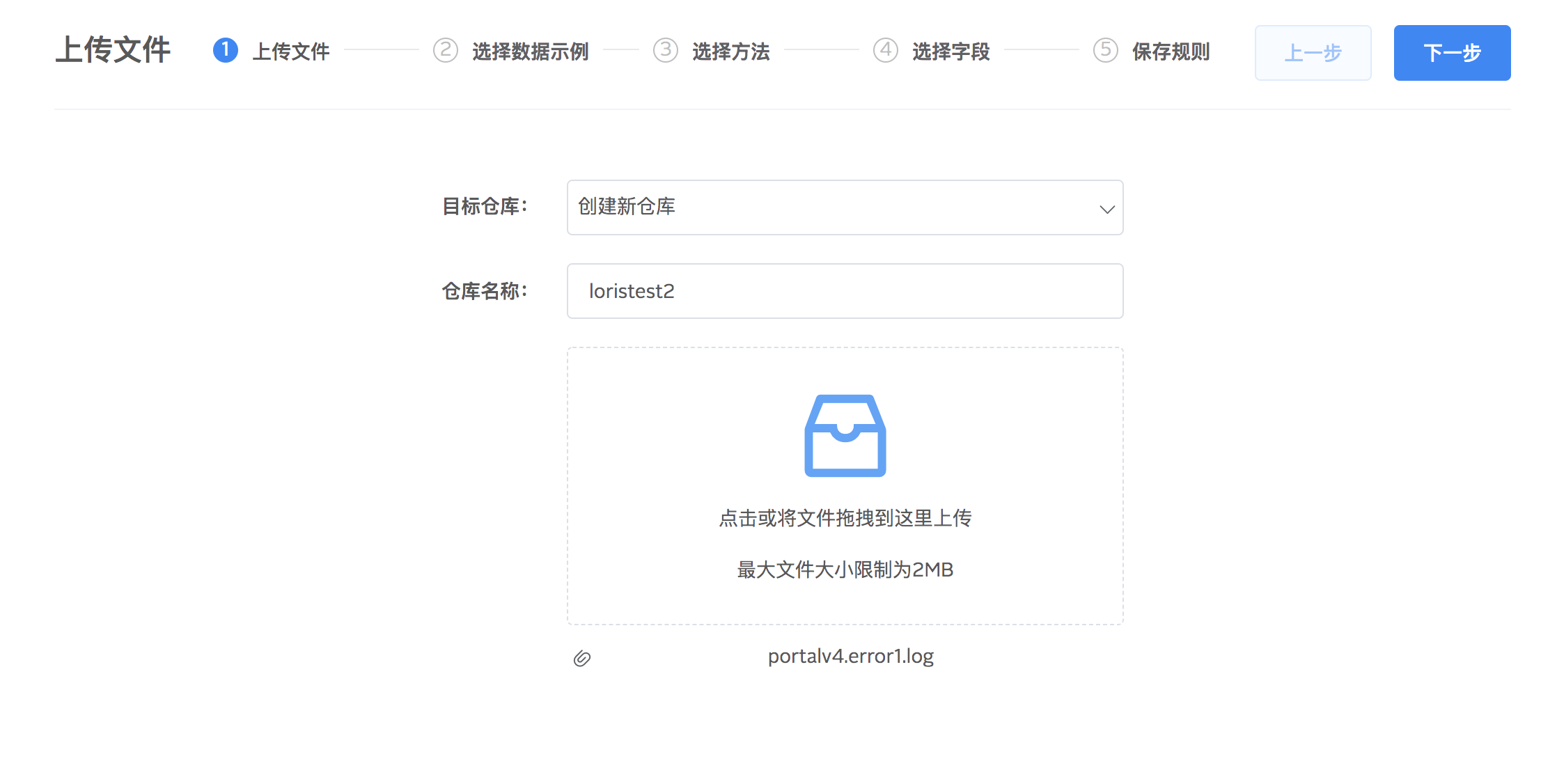
2.在日志列表点选一条当作示例数据进行解析,选择对日志读取解析模式:单行、多行。
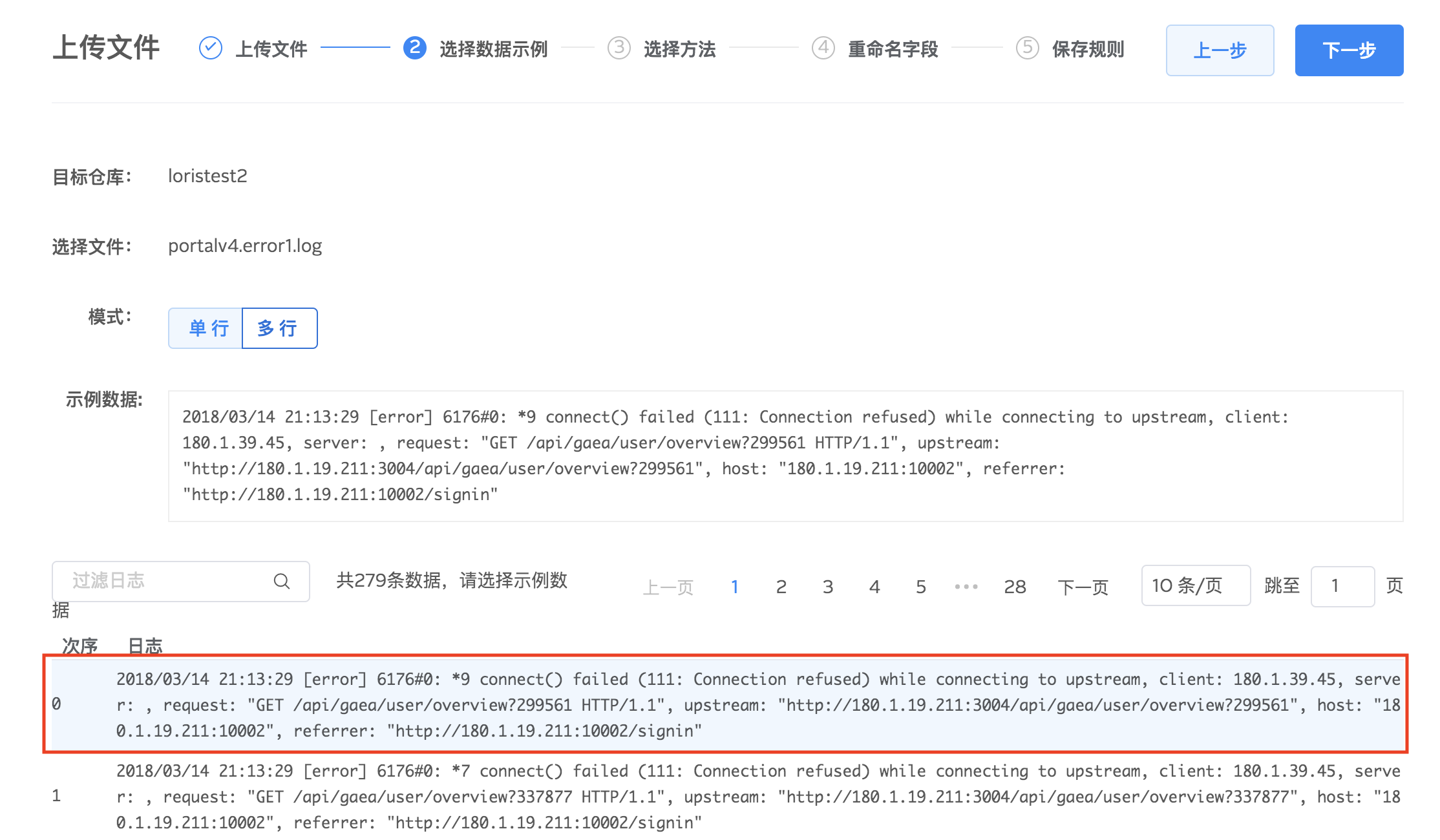
3.对示例数据选择解析方法,logdb 提供按正则表达式、固定分隔符两种字段提取方式提取日志里面的字段,方便后续分析。点击下一步进行具体字段提取设置。
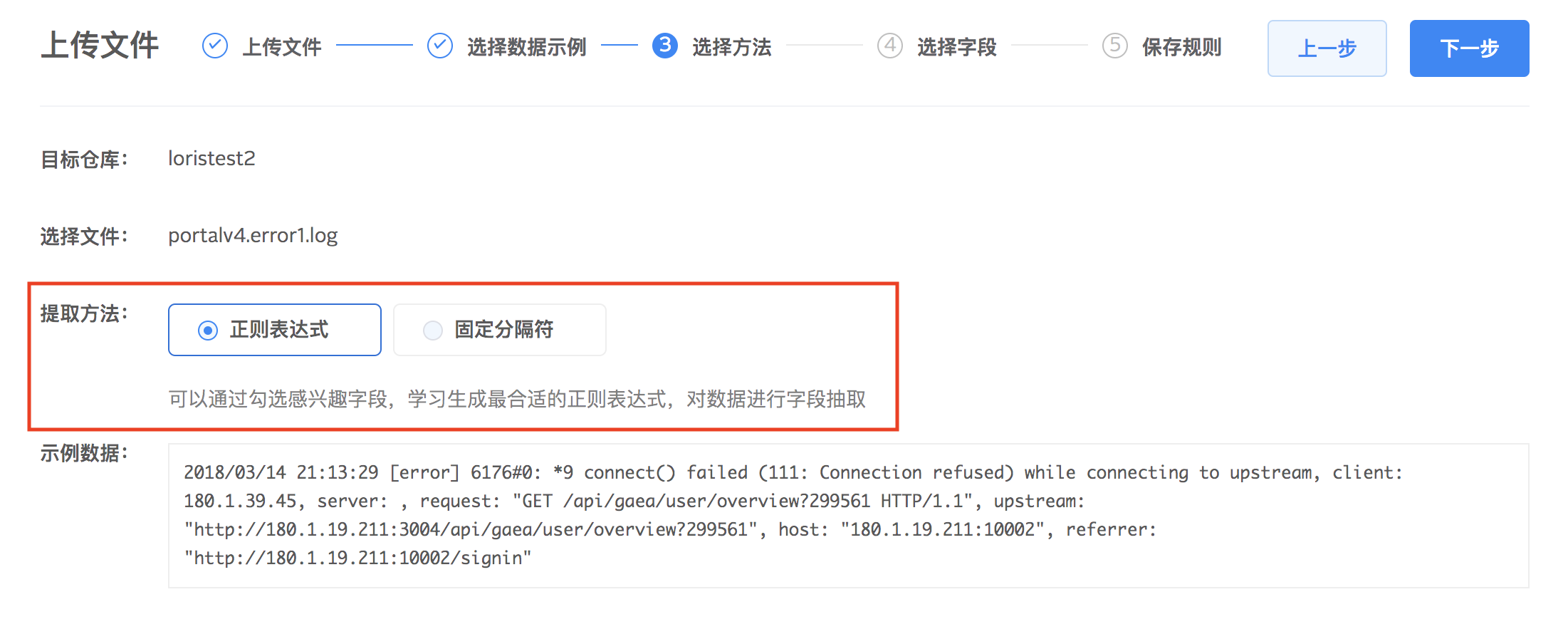
正则表达式提取字段
通过鼠标在示例数据上点选想要抽取的字段,并对字段设置名称和类型。字段提取好之后,系统会自动生成正则表达式,尝试对全部原始文件进行解析。您可以通过匹配数量查看设置的提取规则是否匹配全部日志,根据自身需求对提取规则做调整。
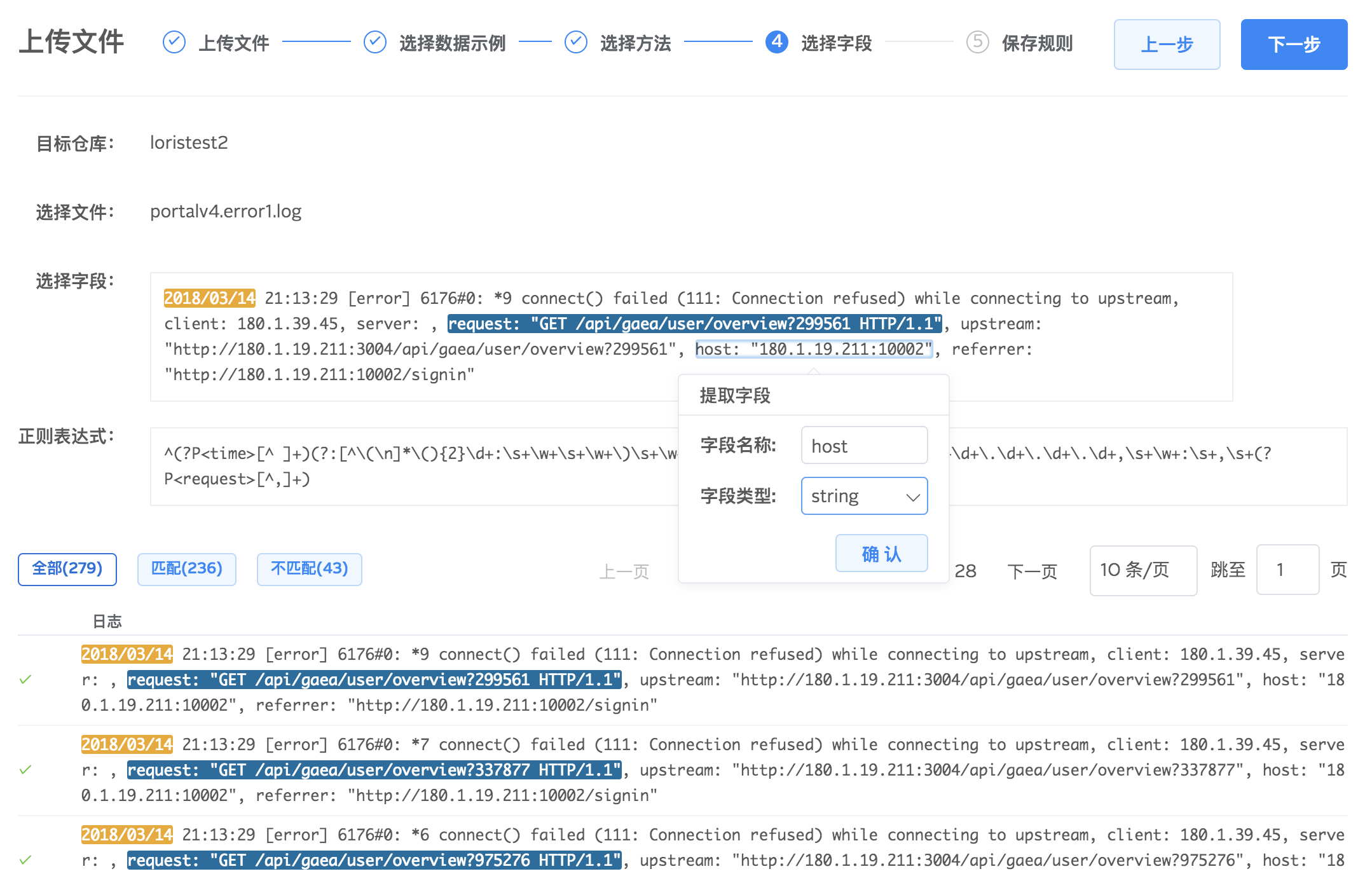
固定分隔符提取字段
我们的系统会根据您选择的分隔符(如逗号,空格,制表位)解析数据,生成默认的字段名和类型,并将字段与字段名一一绑定显示。默认字段名称与类型可以编辑。通过固定分隔符方式提取字段方便快捷,但只适用于 csv 等格式比较简单的文件。
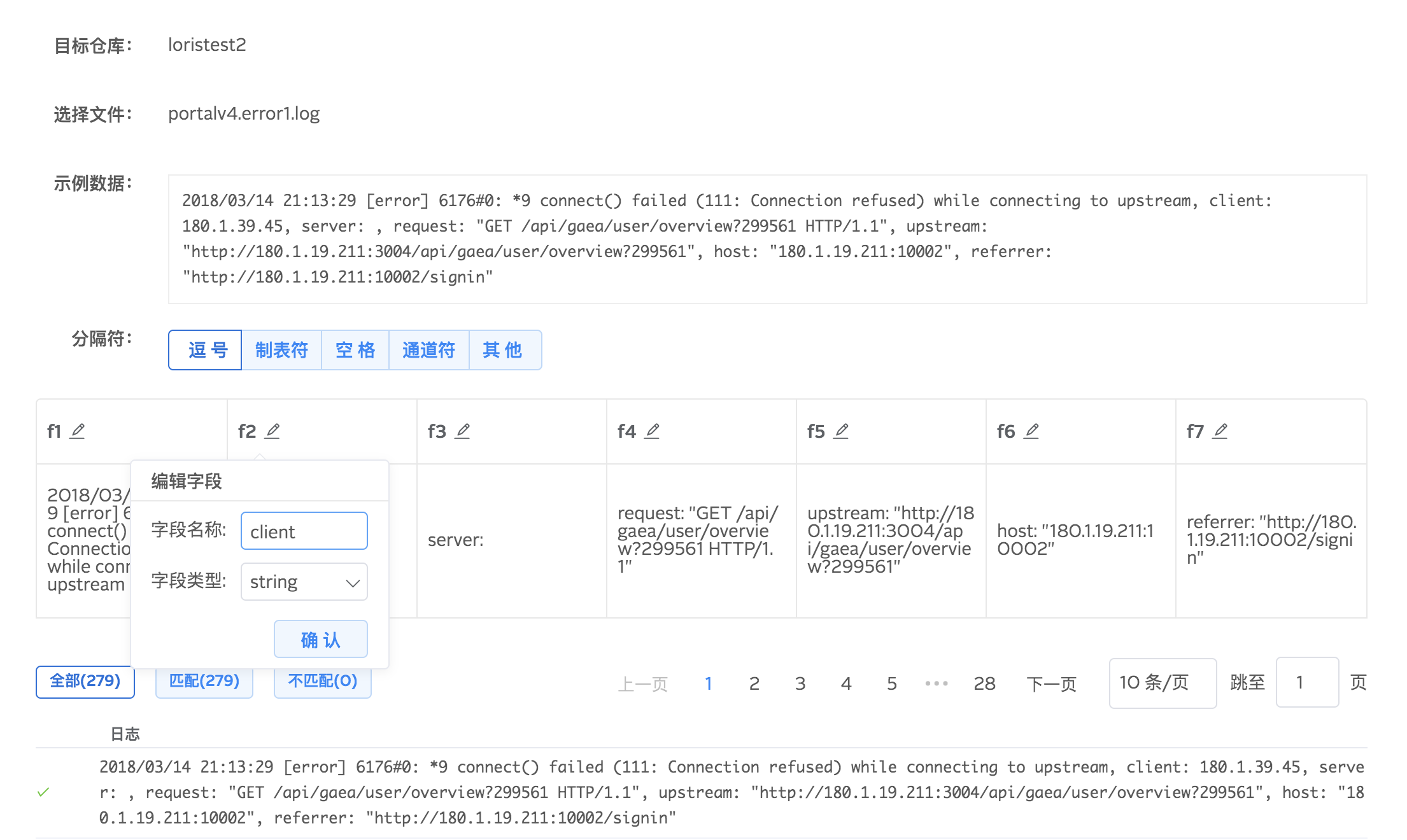
4.保存字段提取规则
为仓库保存字段解析规则,可设置为默认解析规则,在仓库有多个解析规则的情况下,默认解析规则优先级最高。您还可以根据自身需求选择是否保存原始日志。建议保存原始日志,这样即便在解析规则不匹配全部数据的时候,仍然可以将数据入库。
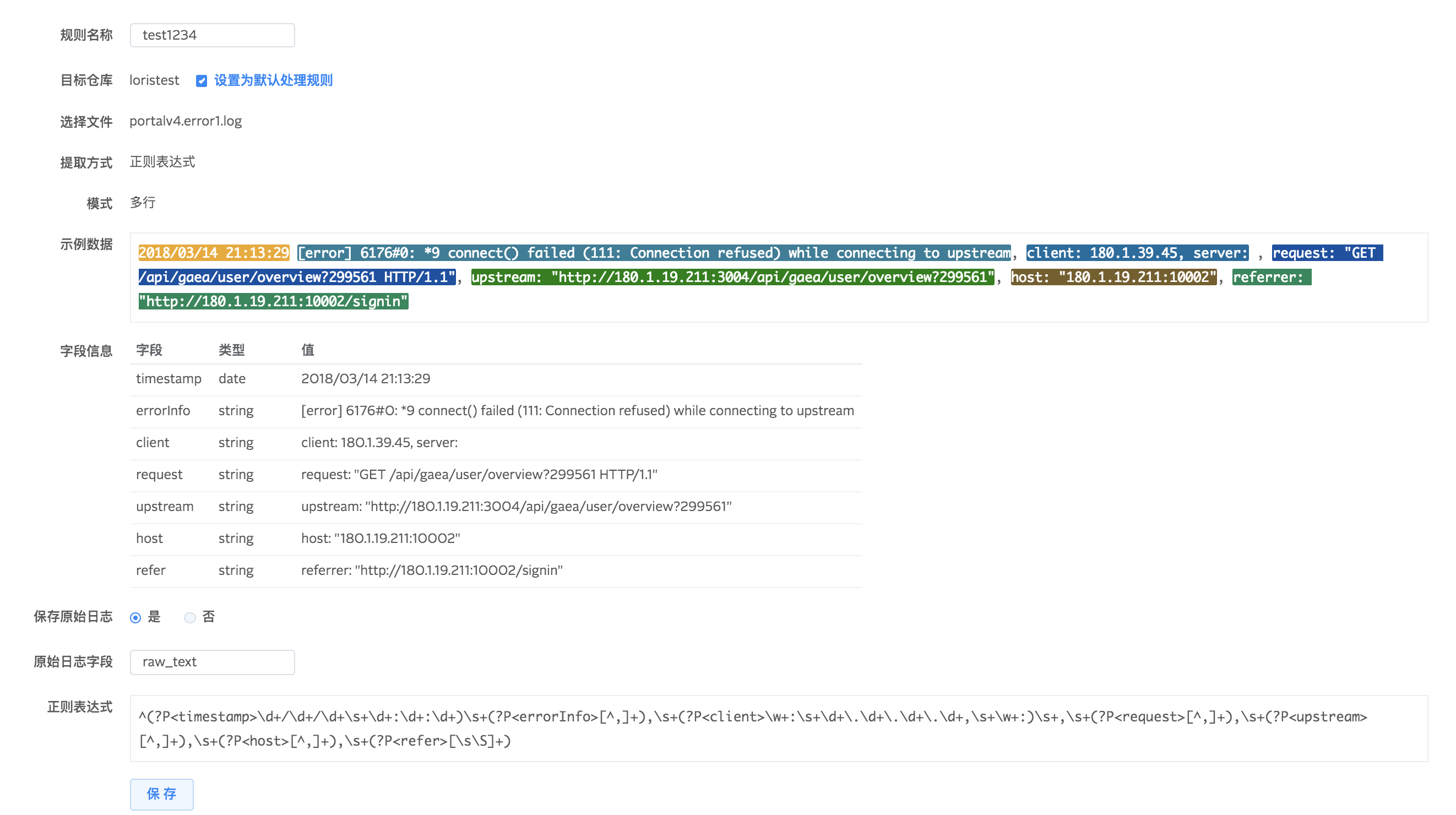
在解析规则列表可以查看所有解析规则及其详情。

文件批量上传
对于已经配置好数据解析规则的仓库,可以一次上传多个日志文件到仓库中。在实时搜索界面的仓库列表,选择上传文件,拖拽本地文件到上传框中即可快速上传多个文件并应用已经设置好的解析规则。
开放 API
通过 API 直接将数据文本置于请求体中,可以在服务端进行数据解析、字段提取和数据入库。
POST /v2/stream/{REPO_NAME}/dataContent-Type: text/plain[2017-12-21 05:36:26,917][WARN ][cluster.routing.allocation.decider] [Master Mold] high disk watermark [90%] exceeded on [gXIMYOjpQ0SmV-vvUpnaKw][Master Mold][/Users/jason/Development/elasticsearch-2.3.3/data/elasticsearch/nodes/0] free: 1.8gb[1.6%], shards will be relocated away from this node
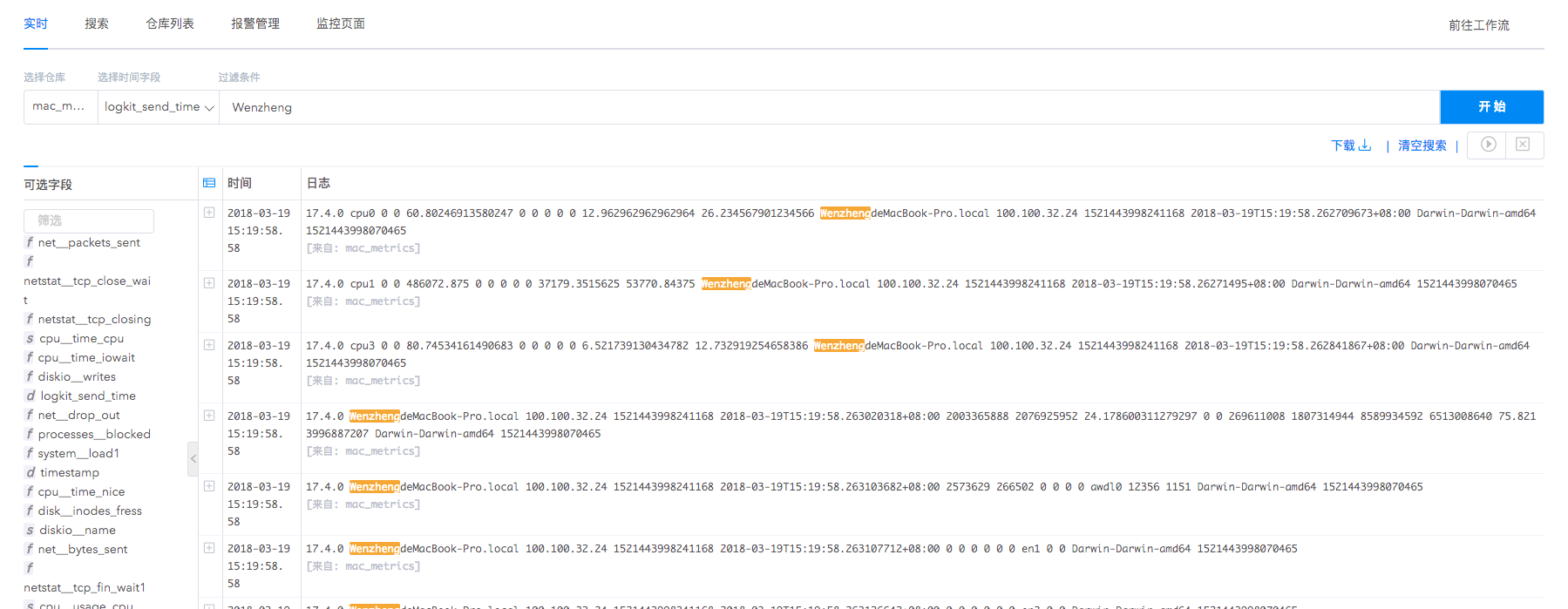
实时日志输出
实时数据仓库集中存储了从服务器、终端设备、日志收集器等多种途径收集来的日志,我们支持对收集日志进行实时滚动输出,毫秒级延迟支持用户第一时间获得信息。
同时实时输出功能支持条件过滤,在海量实时日志中筛选核心数据,滚动展示。
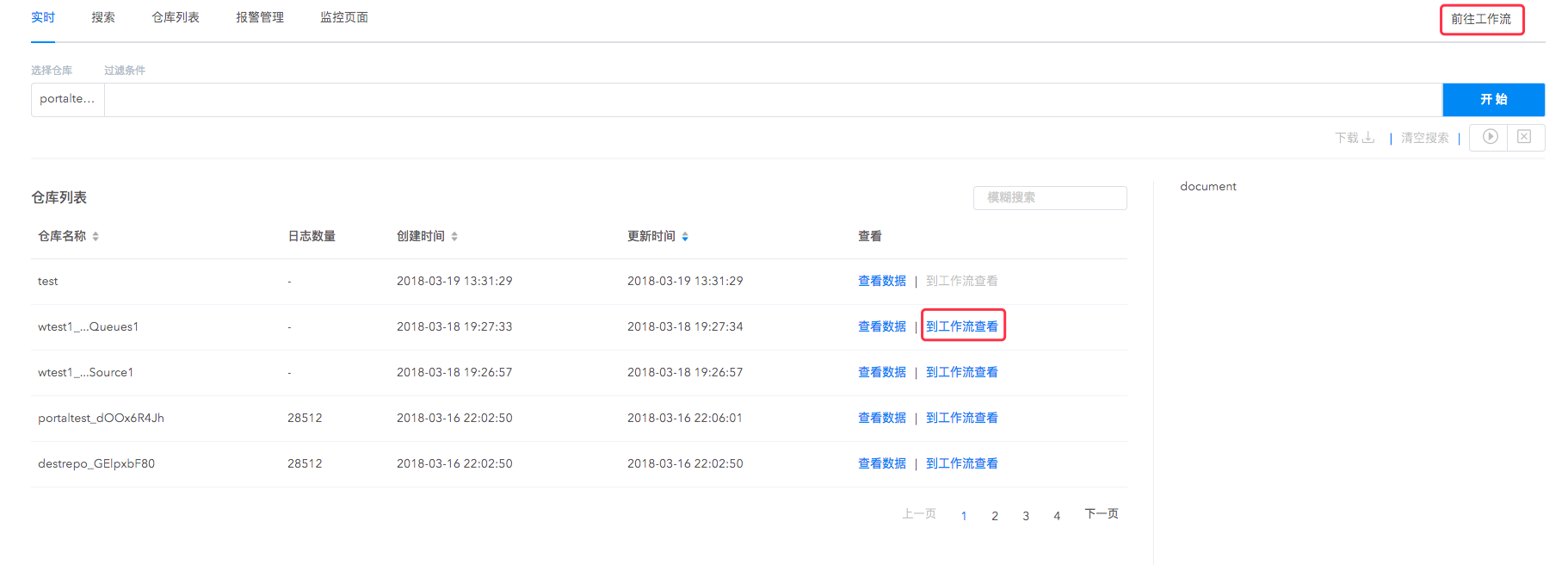
同时实时仓库支持前往工作流(pipeline)进行数据导出,支持将实时数据导出到日志仓库、云存储、时序数据库等多种下游数据仓库,与工作流(pipeline)协同工作,您可以高效地进行实时日志的查询与计算,一鼓作气完成实时日志的整个分析流程。
注意:如果实时日志数据量过大,每次滚动输出日志的时候会限制在1000条进行展示。避免页面数据过大导致无法展示。
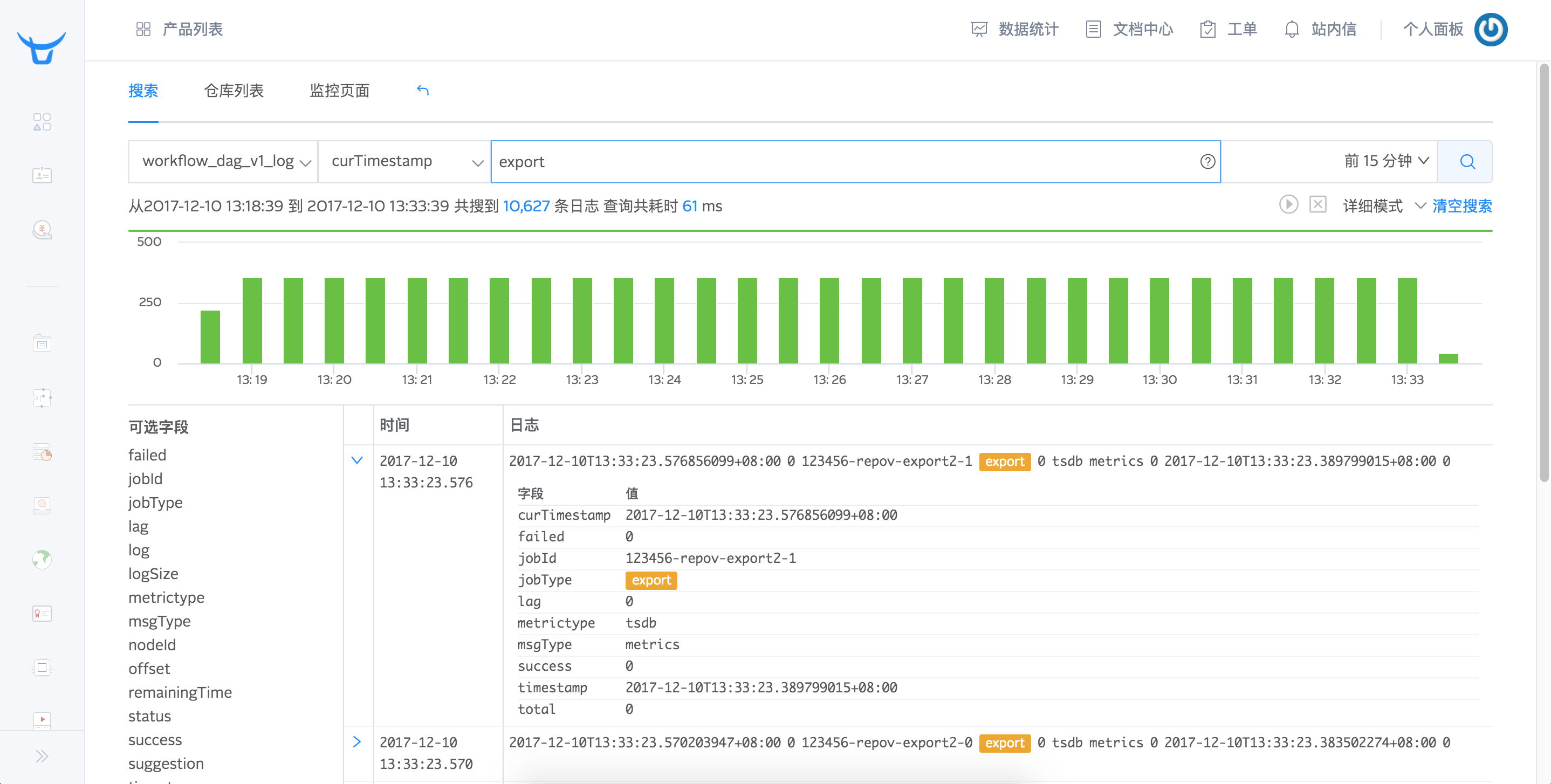
搜索
搜索界面由搜索栏、仓库列表栏、搜索历史栏组成,通过这三大块您可以完成高效又精细的搜索。
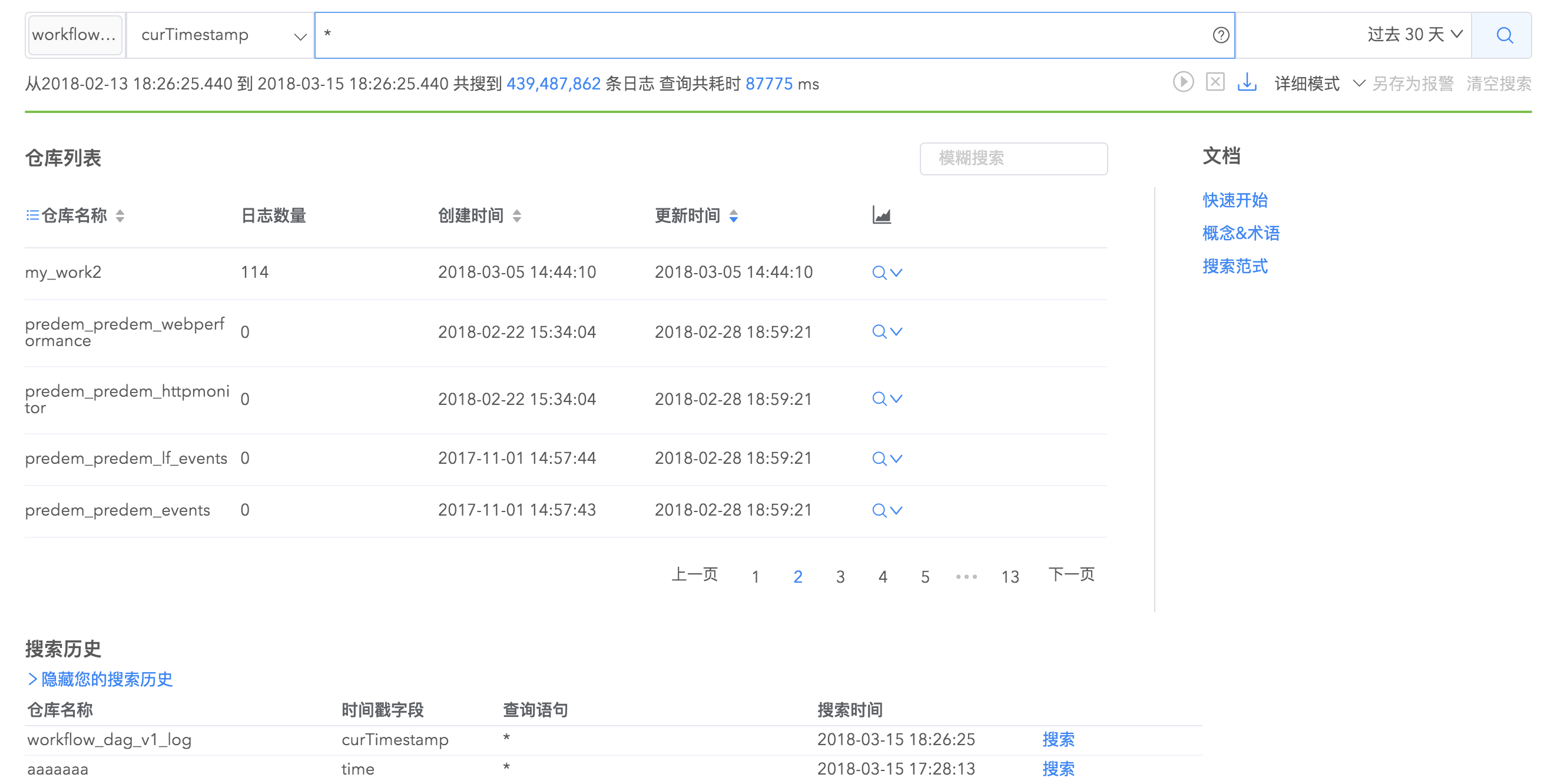
在搜索栏您可以通过选择日志仓库、输入查询语句、选择时间范围来搜索日志。如果日志仓库里面包含时间字段,您可以通过选择时间字段来过滤搜索结果。
快速搜索
搜索历史
您可以通过搜索界面的仓库列表快速查询具体某个仓库的全部日志,也可以通过搜索历史快速定位已经做过的搜索,避免重复工作。

搜索结果分享
您可以将已有搜索页面链接分享给其他人,对方可以基于您的页面直接查看搜索结果或者再搜索,不需要重复输入相关查询条件,方便团队内部进行沟通,提高效率。
搜索结果
搜索模式分为两种,极速模式和详细模式。当您想要看到日志结果随时间的具体统计图时,可以选择详细模式搜索。统计视图显示随时间统计的日志事件数量。点击直方图的任何部分都可以选择那个时间段以查看选定时间范围内的事件。
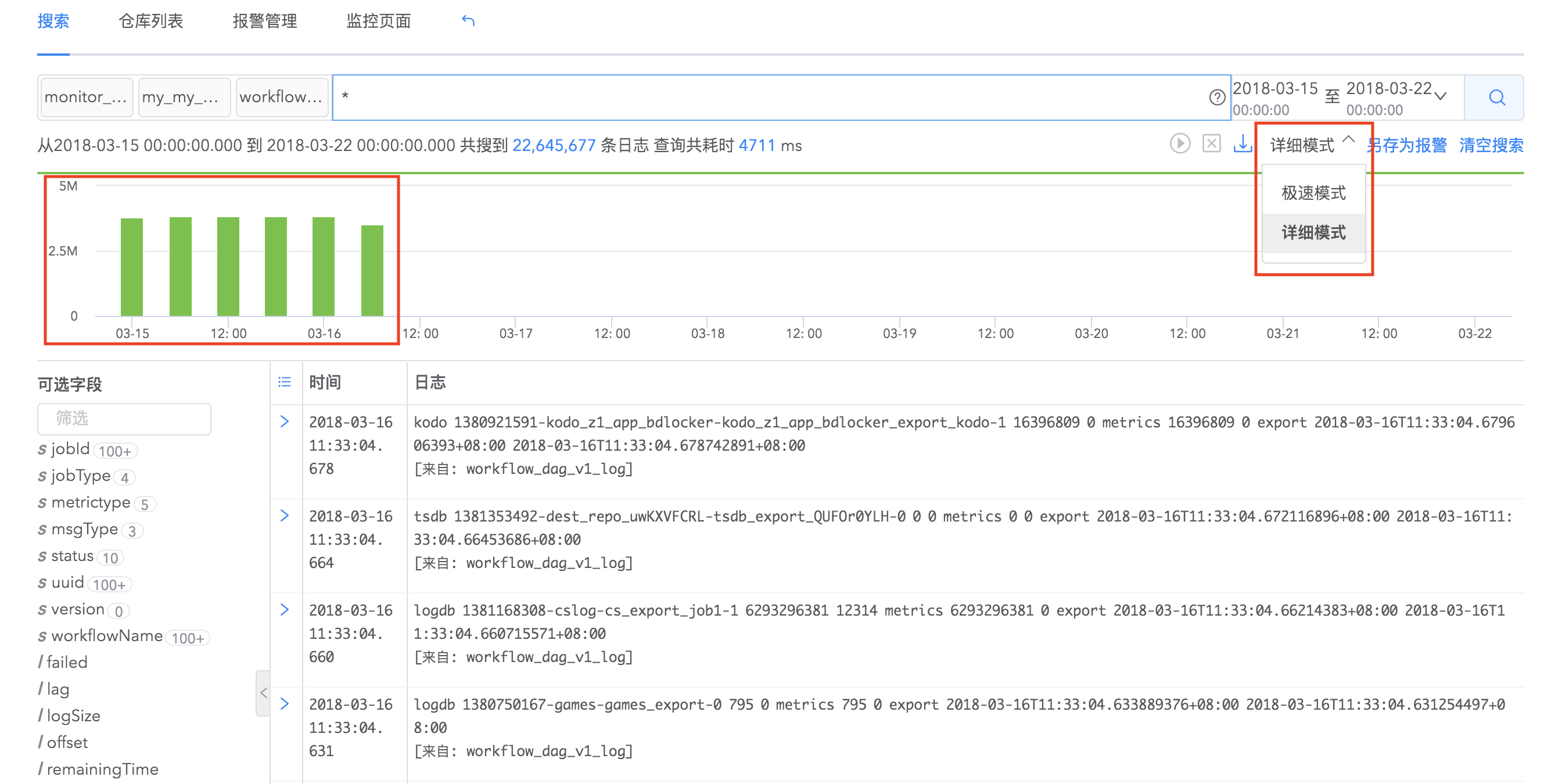
字段过滤
日志的field列表显示在搜索结果的左侧,默认情况下搜索结果会显示日志的全部字段,您可以通过字段筛选添加您想查看的字段显示到右侧的日志详细内容中。
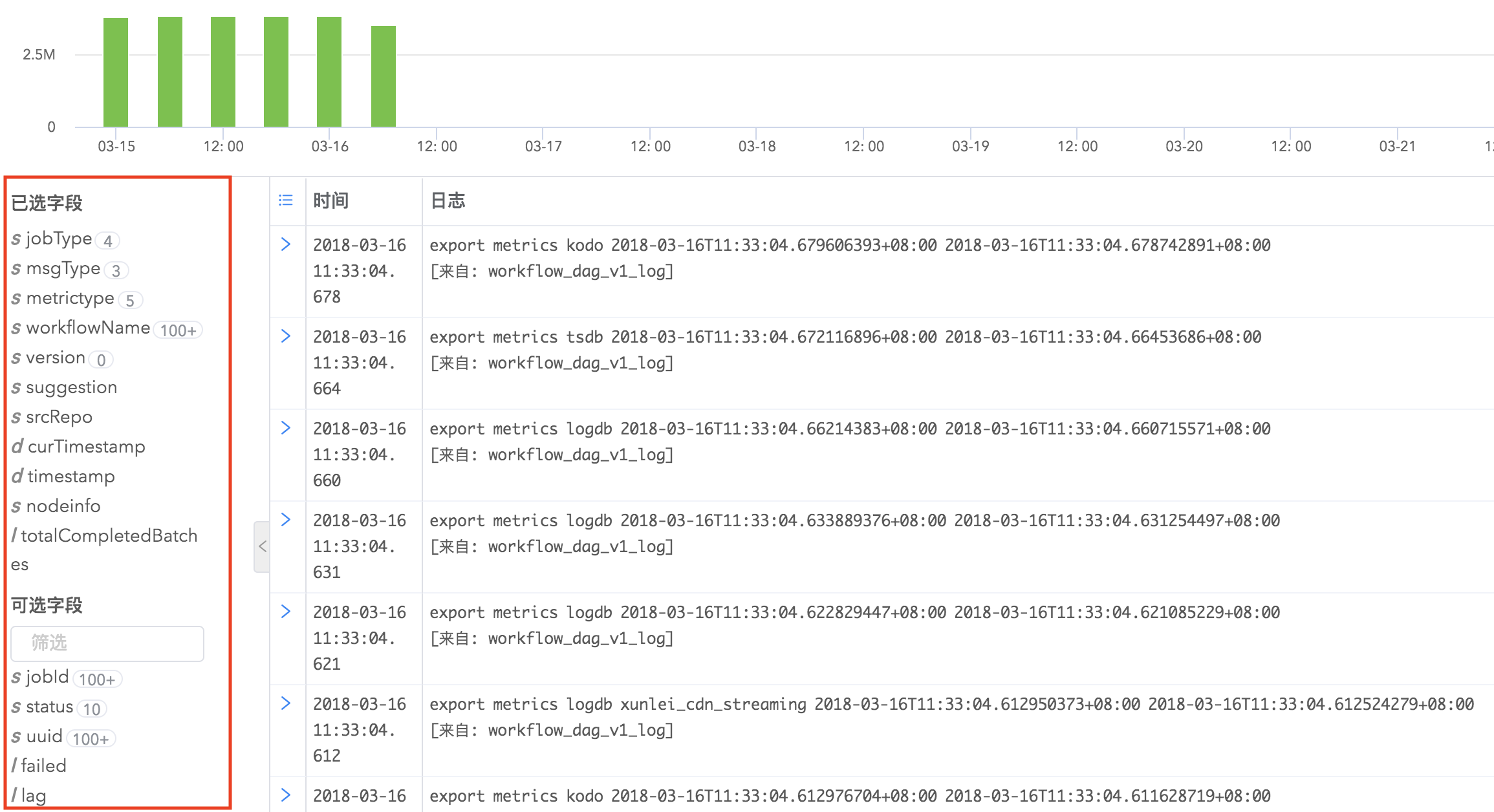
字段统计分析报表
Logdb支持字段统计分析,在搜索结果左侧字段列表,每个字段会有统计基数显示,点击以后您可以看到字段的具体统计信息,如最大值、最小值、平均值、字段覆盖率、出现频率为TOP10的值的相关信息等,并推荐您可能感兴趣的关键值,点击关键值即可快速搜索出包含该关键值的日志。
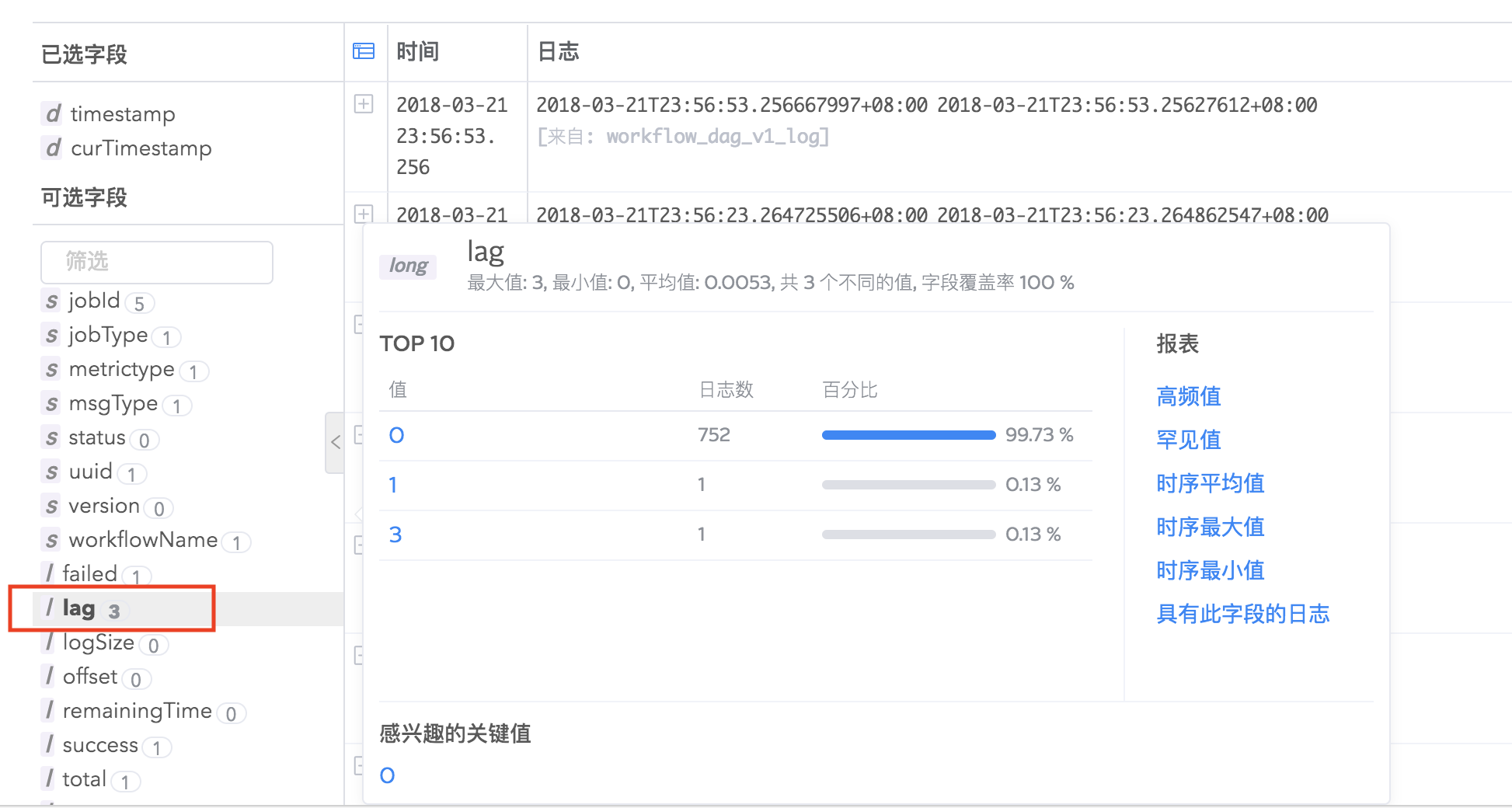
并且,您可以看到字段的罕见值(出现次数比较少的值)、高频值(出现次数比较多的值)、时序平均值(字段平均值随时间的统计图)、时序最大值、时序最小值等几种值的统计图表以及查看包含某具体字段的全部日志。
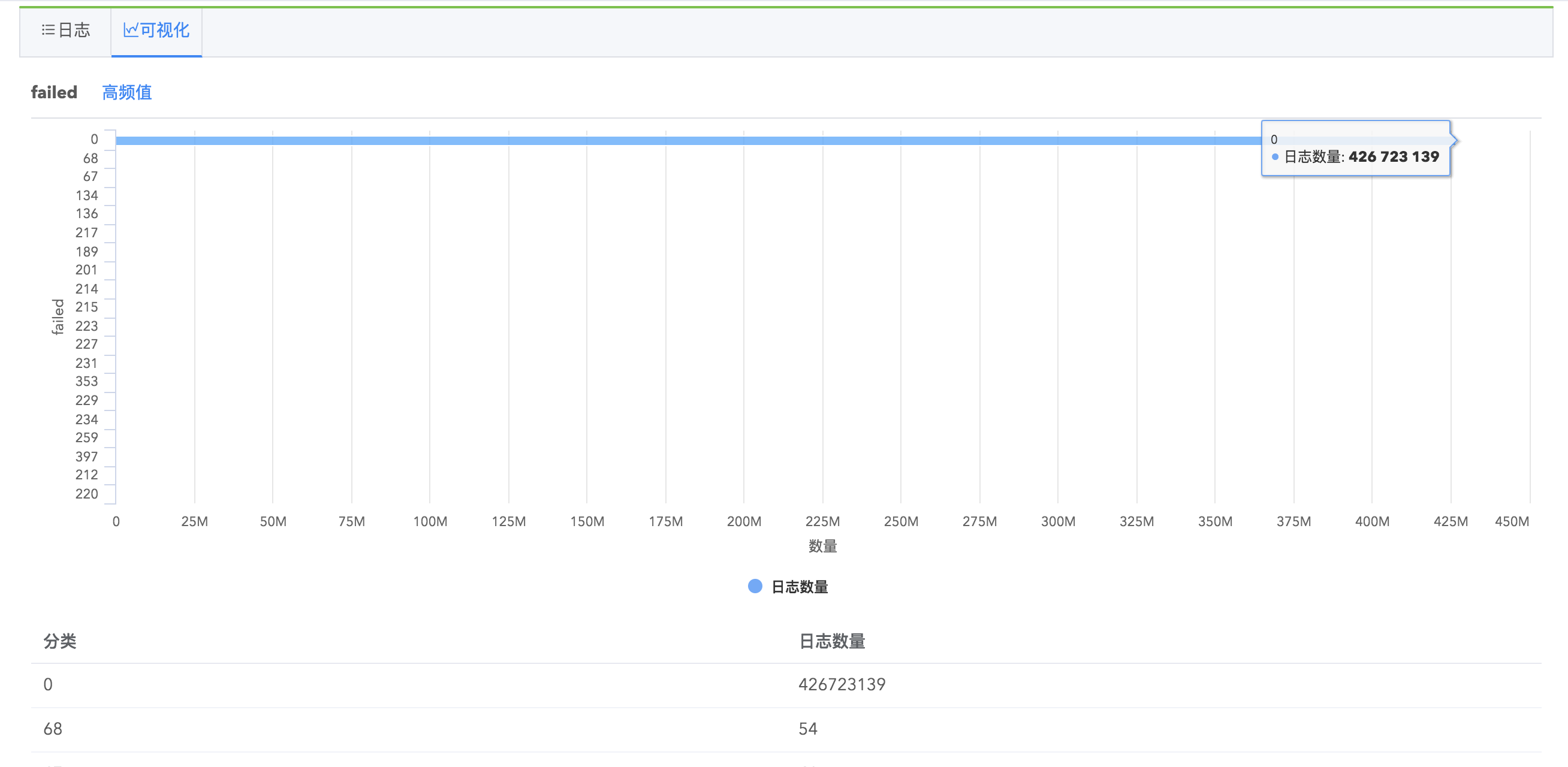
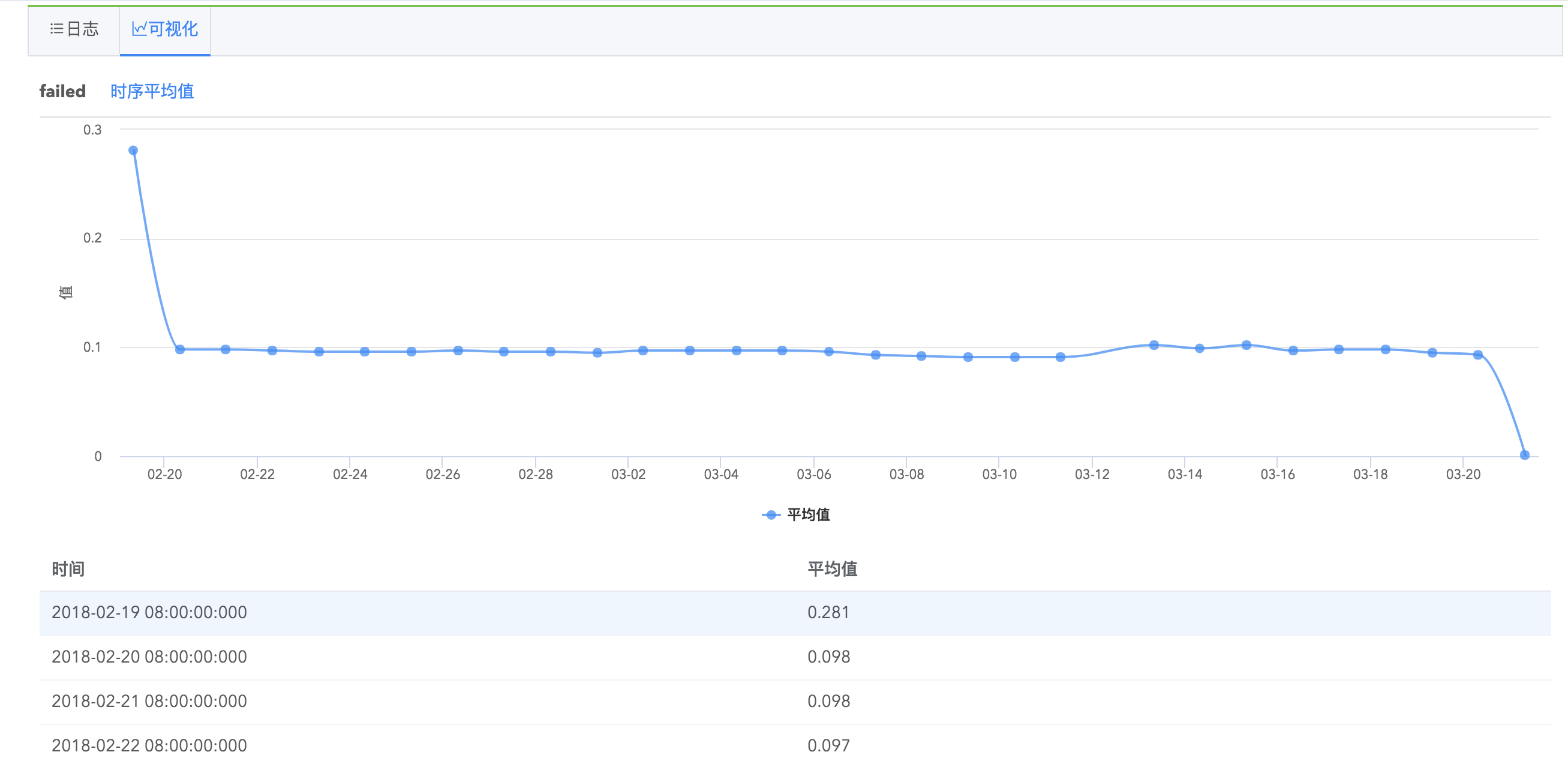
字段统计分析功能帮助您高效地进行日志查询,指引您挖掘更有价值的日志信息。
日志结果显示
Logdb支持三种日志显示模式,JSON、文档和表格,您可以根据自己的阅读习惯任意切换。
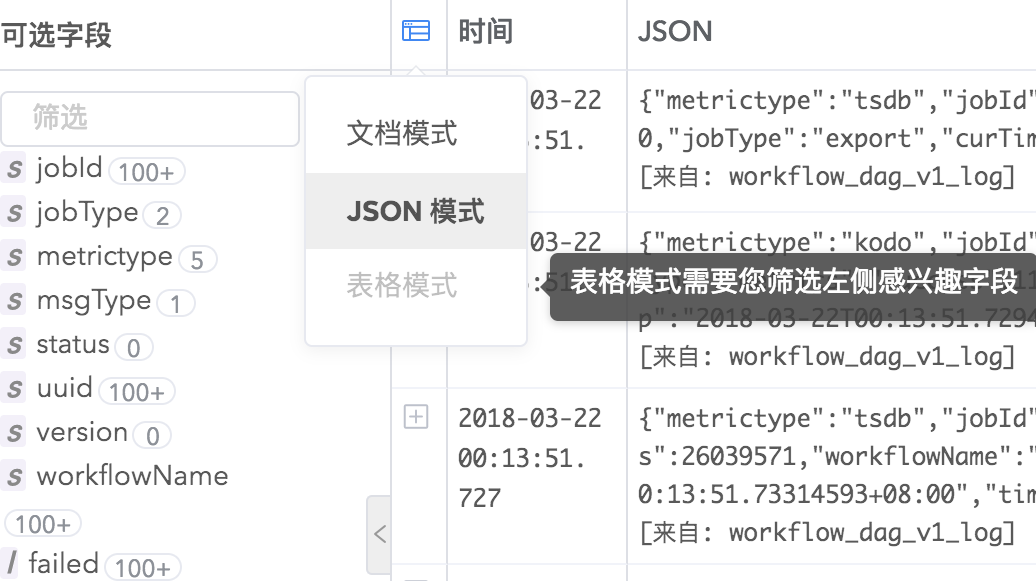
划词分析
logdb支持搜索结果的划词分析,对搜索结果进行过滤。您可以提取日志结果里的关键字段,选择“加入搜索”,结果会过滤出包含这些关键字段的日志事件,可以同时对多个关键字段划词分析。您可以看到搜索框自动出现了查询语句,大大节省了您的工作量。
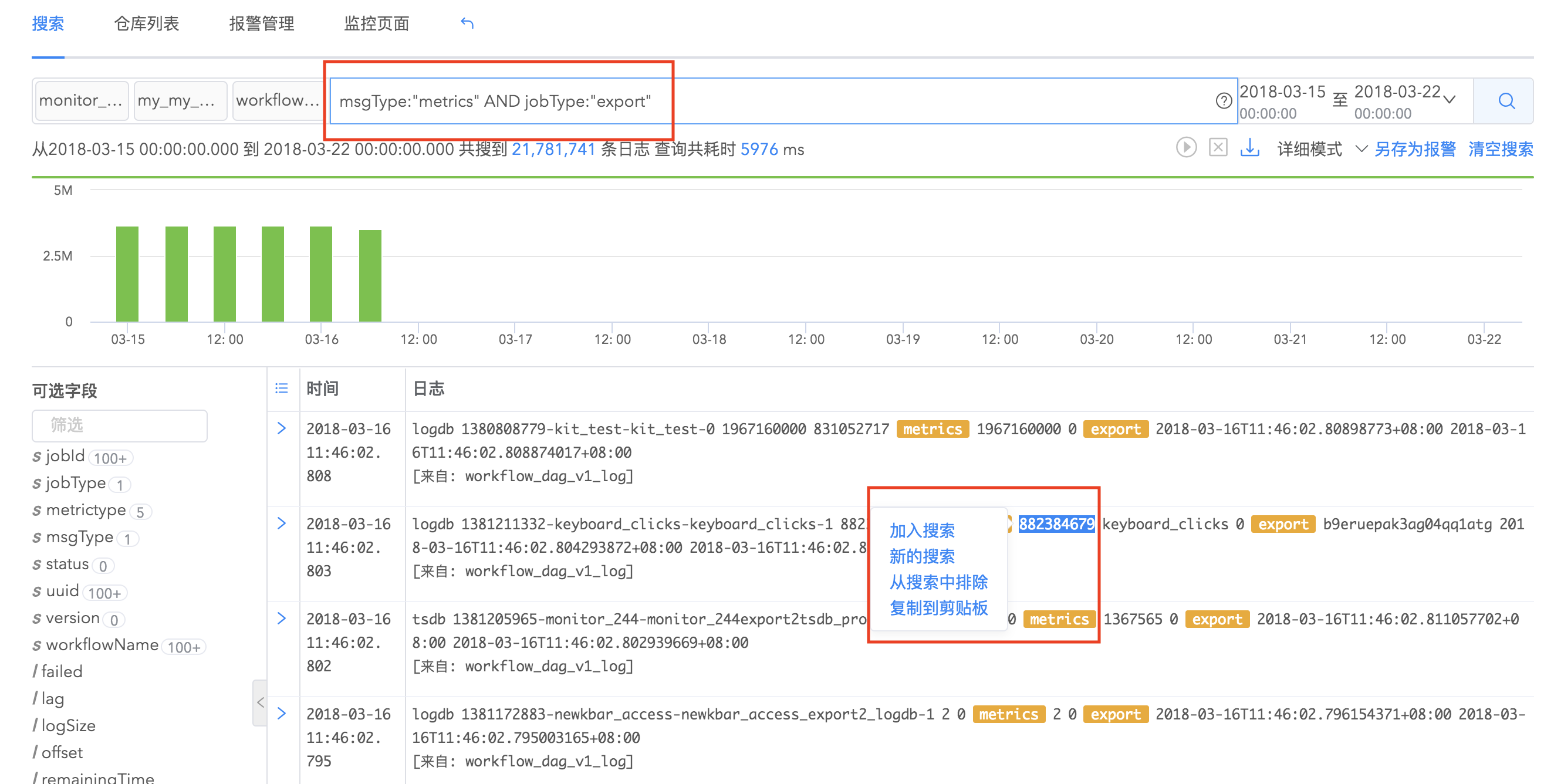
上下文搜索
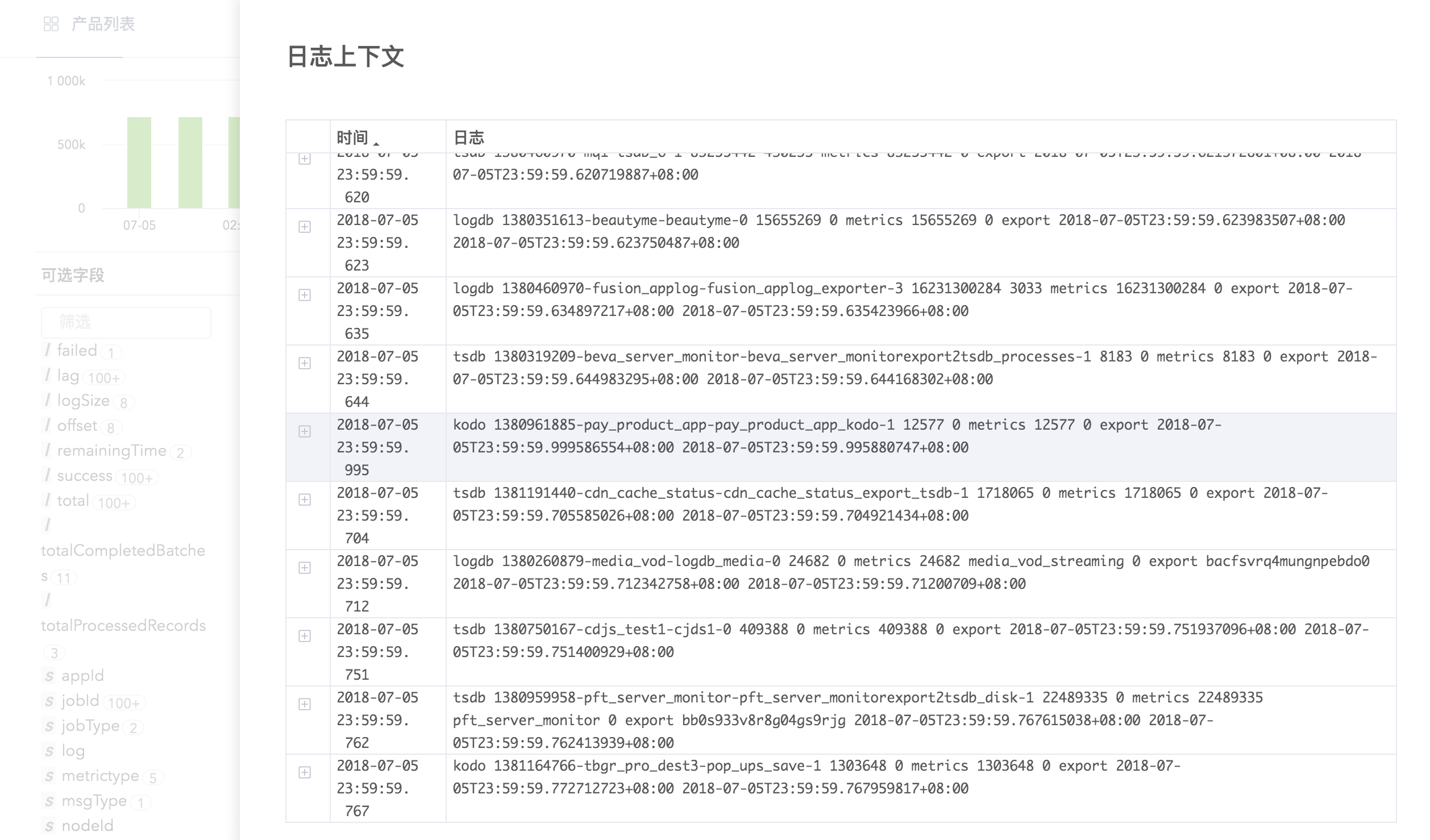
通过上下文功能查看某条日志前后 N 条日志,通常使用上下文搜索功能对异常日志进行分析。
联合搜索
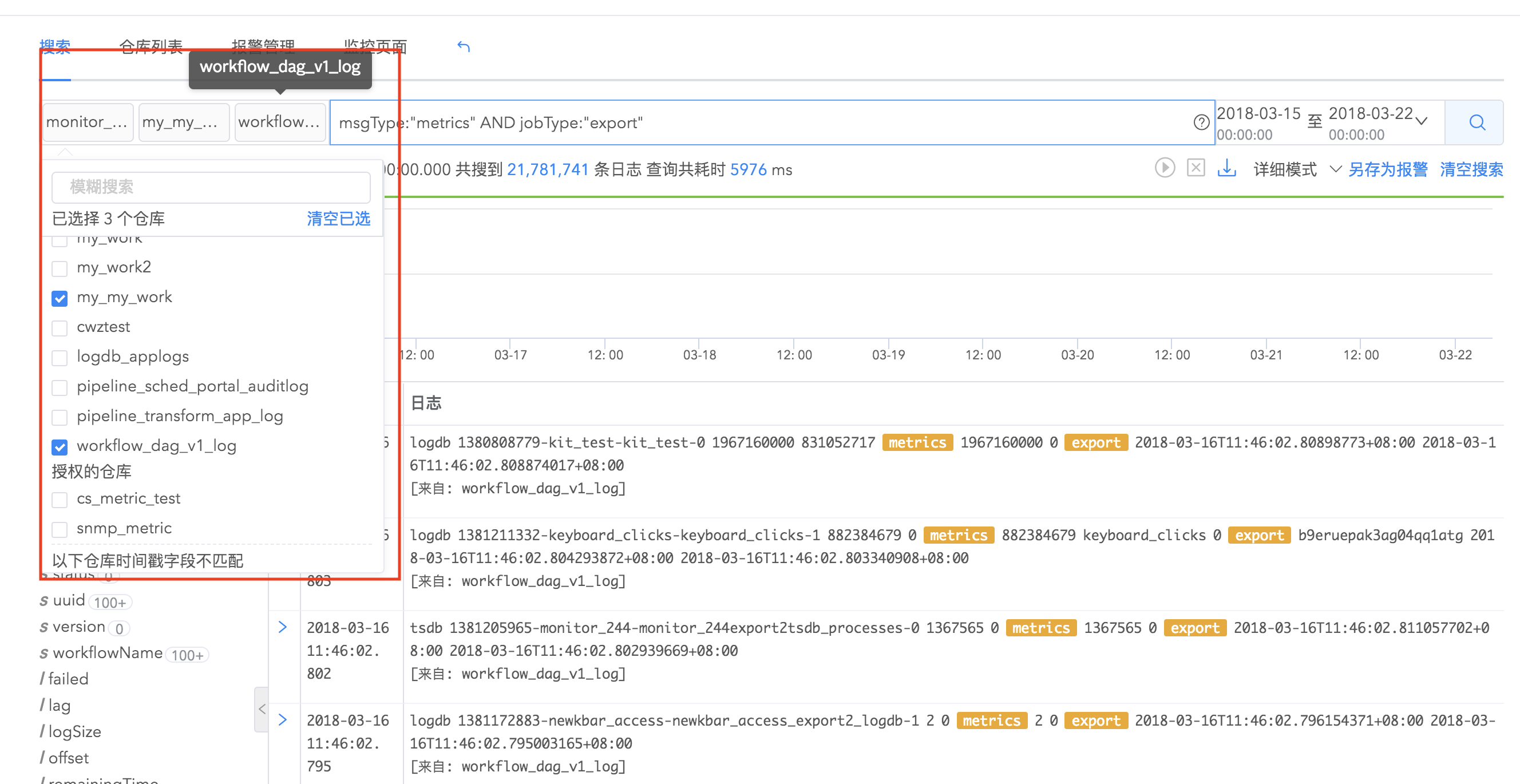
logdb支持多个日志仓库联合搜索,如果您拥有多个日志仓库,这几个仓库里的数据彼此关联,您可以同时选择若干个仓库进行联合搜索,获得更全面的分析结果。
搜索语法
日志分析服务提供Lucene、SQL共2种语法来进行日志搜索,但需要注意,一旦有任何数据包含以下符号,无论使用哪种语法,在搜索时,需要以双引号("")包含起来:
+ -&& || !( ) { } [ ]^ ” ~ * ? : \
使用 lucene 语法搜索
条件编写规范
| 名称 | 语义 |
|---|---|
| * | 查询所有内容 |
| AND | query1 AND query2,查询交集 |
| OR | query1 OR query2,查询并集 |
| NOT | query1 AND NOT query2,表示符合query1,不符合query2的结果 |
| () | 把一个或多个query合并成一个query,提升优先级 |
| [] | 区间查询,包括边界 |
| {} | 区间查询,不包括边界 |
| \ | 转义字符 |
| >,=,<,<=,>= | 区间查询 |
正则表达式查询
正则表达式查询条件编写时,以"/"开头和结尾。
比如:name:/joh?n(ath[oa]n)/
通配符查询
使用?代替一个字符,*代替0或者多个字符
比如:qu?ck bro*
- 注意使用这个查询会消耗大量资源,并且速度会降低。
查询举例:
字段名称name,类型string,包含内容a的记录:
?>name:a
字段名称ip,类型string,包含内容a或b的记录:
?>ip:a OR ip:b
字段名称hosts,类型string,包含内容a或者b,不包含c的记录:
?>(hosts:a OR hosts:b) AND (NOT hosts:c)
字段名称ip,类型string,包含内容a或b,同时字段名称hosts,类型string,包含内容c的记录:
?>(ip:a OR ip:b) AND (hosts:c)
字段名称createTime,类型date,包含内容2016-1-1到2016-1-2的记录:
?>createTime:[2016-01-01 TO 2016-01-02]
字段名称count,类型long或者float,内容大于5的记录:
?>count:>5
更多高级语法和使用方式请参考Lucene Query。
统计报表
快速报表
日志分析平台自动统计日志里字段的高频值、低频值、时序平均值、时序最大值、时序最小值等,在搜索结果页,点击具体字段即可看到字段相关的统计信息。
详情请阅读字段统计分析报表。
自定义配置报表
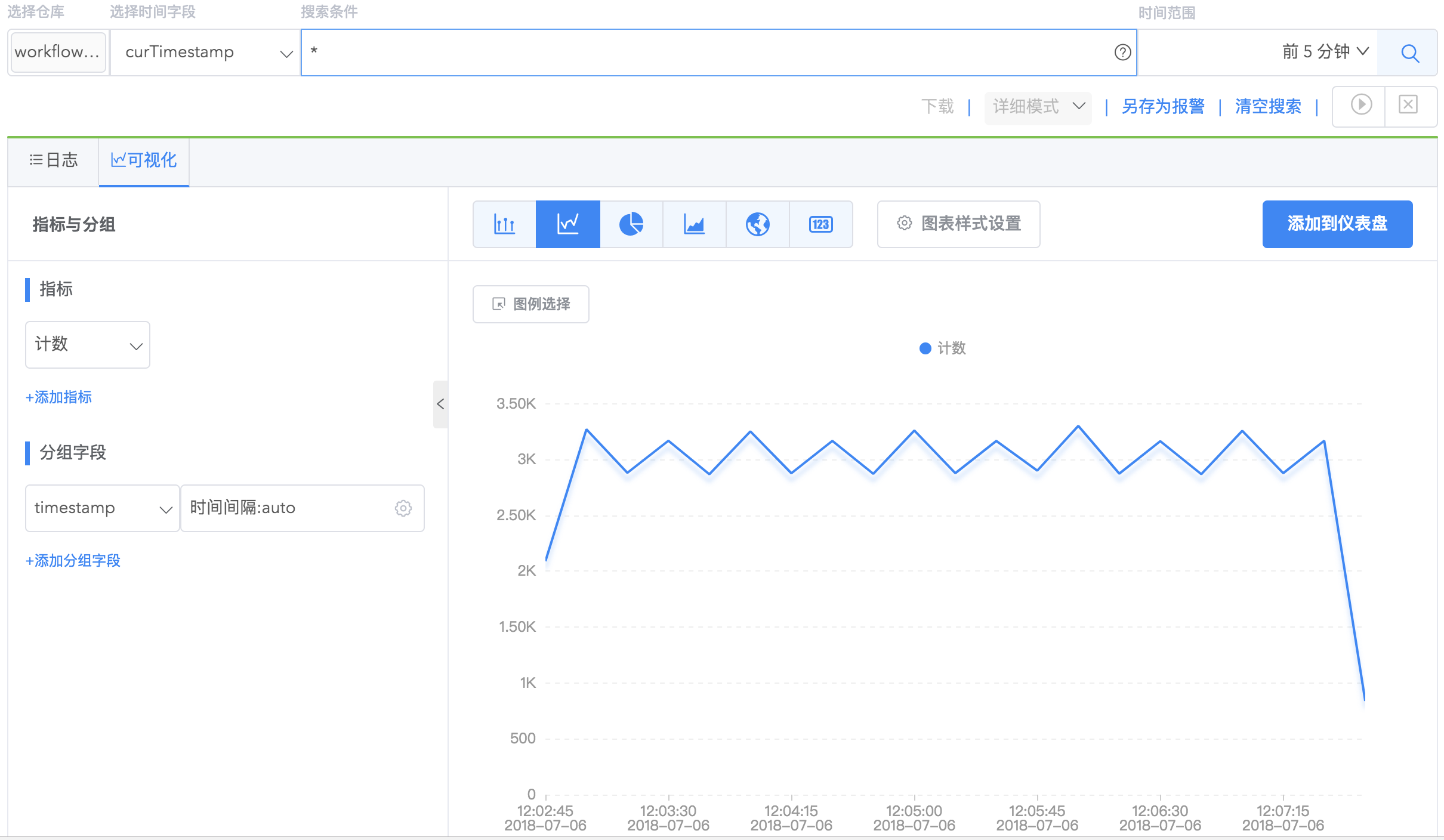
logdb 支持统计报表功能对日志搜索结果进行深度分析。统计报表操作方式非常简单,搜索出日志结果之后,您会看到可视化tab,通过在可视化页面左侧栏选择指标与分组字段,即可基于搜索结果配置分析报表,无需编程语言。
指标与分组字段的说明如下:
指标:
支持对日志计数、字段的去重计数、平均值、中位数、平均值、最大值、最小值、分位数、变化率进行统计。
去重计数支持 string,long,boolean 字段,其他指标只能选择数值字段。
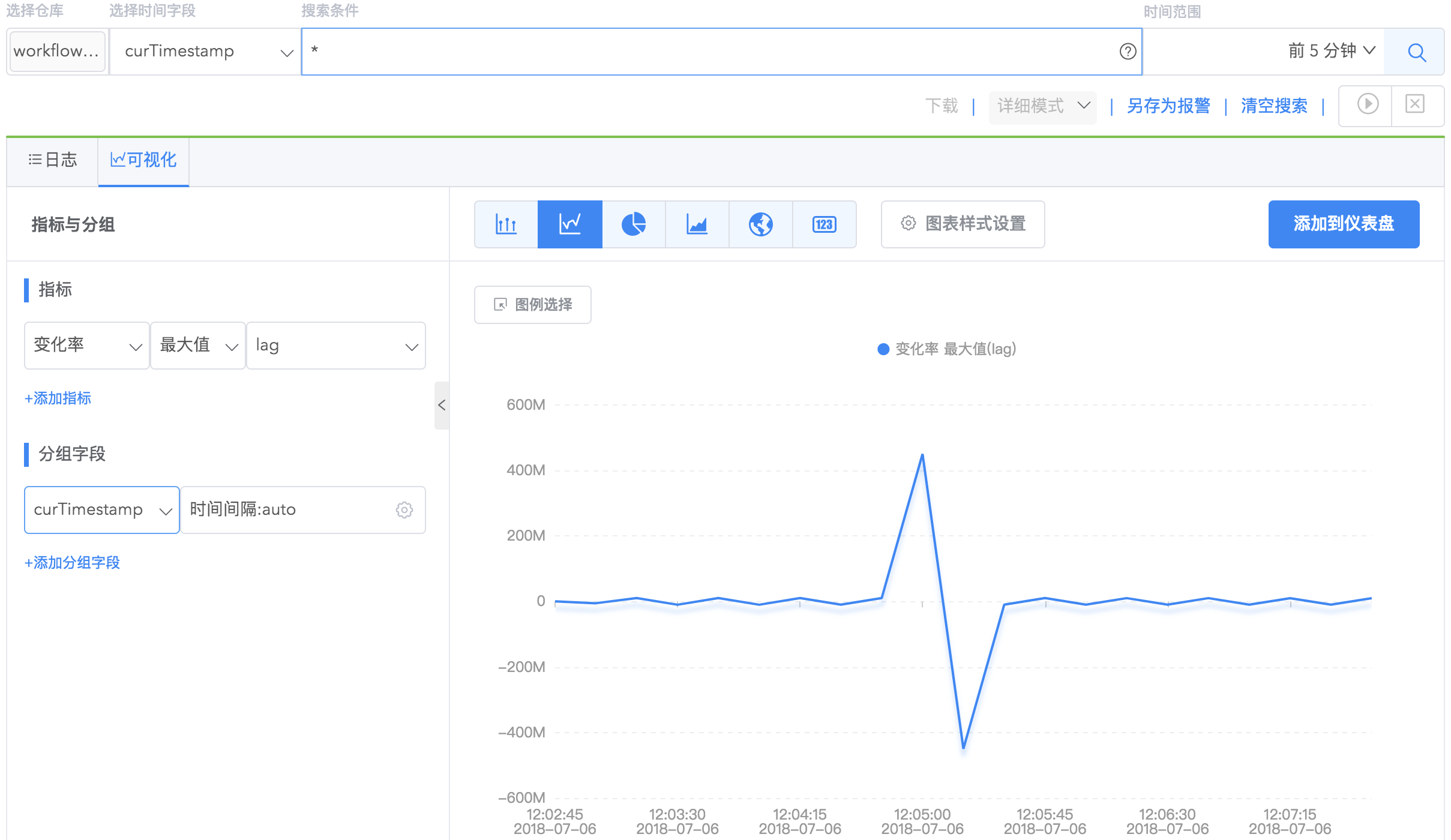
支持对指标的平均值、最大值、最小值、总和再统计变化率。
- 可添加多个指标。
分组字段:
1.支持时间字段与普通字段。
2.分组字段可以添加多个。
3.当分组字段里出现时间字段时,时间字段呈现为 x 轴,即事件首先按照时间粒度聚合,其他分组字段呈现为多系列数据。
4.若分组字段里没有时间字段,则第一个添加的字段呈现为 x 轴,事件按照第一个添加的字段分组显示。
5.对于时间字段分组,系统支持自动 interval 或者用户输入 interval 对搜索结果聚合。
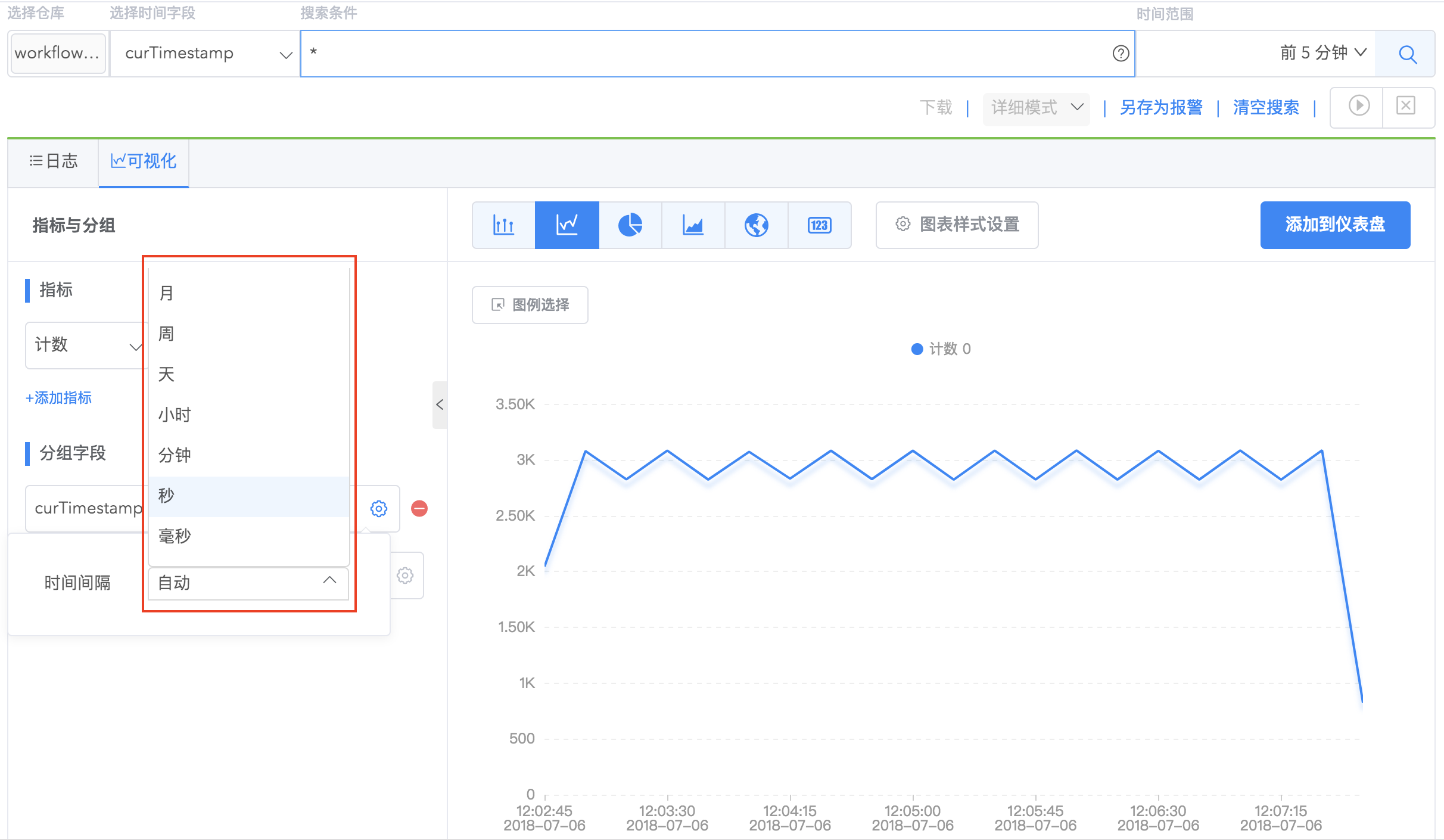
6.普通字段分组支持 string、long、boolean 字段类型,支持对普通字段分组排序。
- 可选排序依据,支持按照统计指标、分组字段的值、分组字段的事件总数排序。
- 可以选择升序或者降序排列。
- 可选呈现的分组数量。
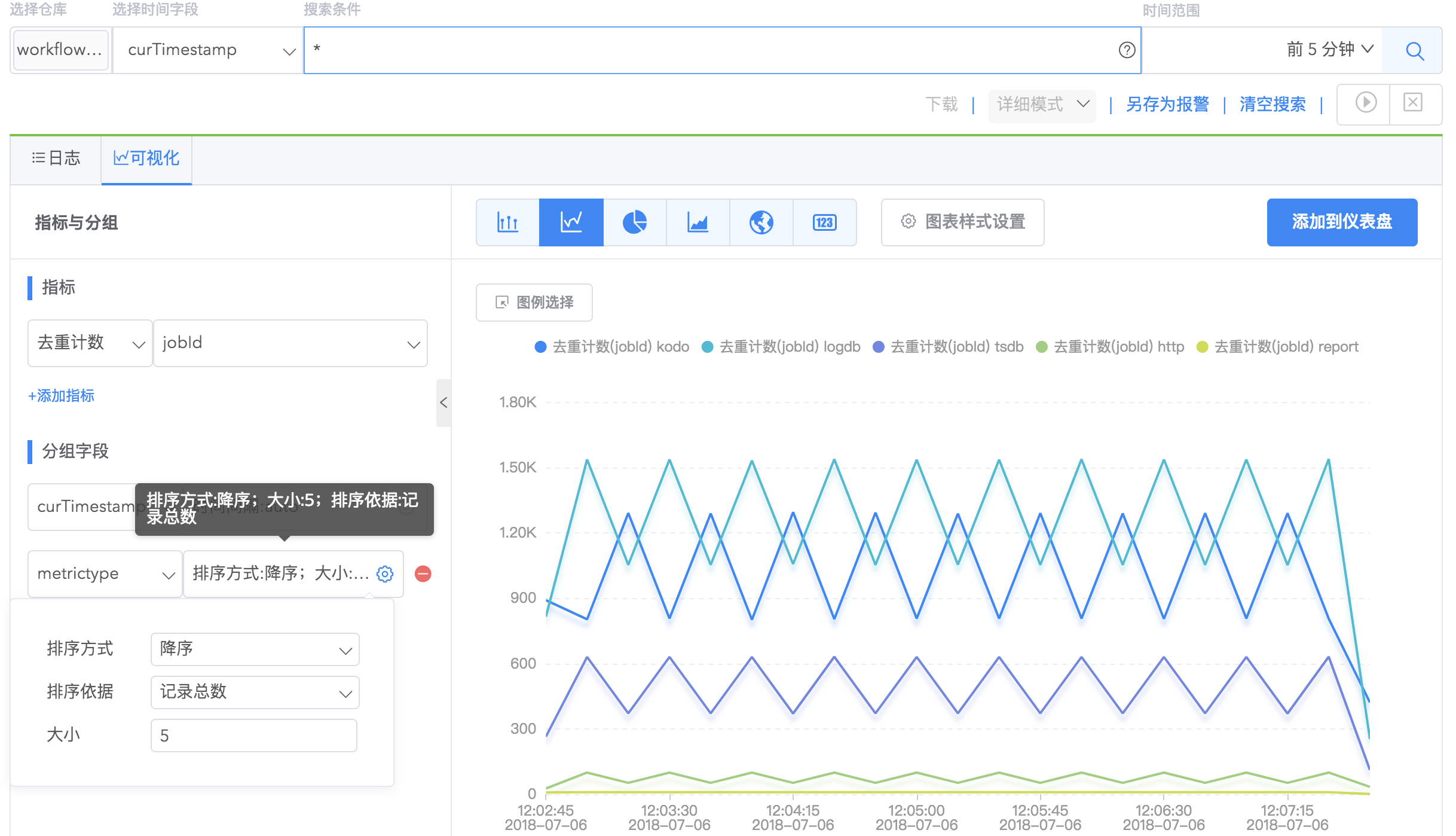
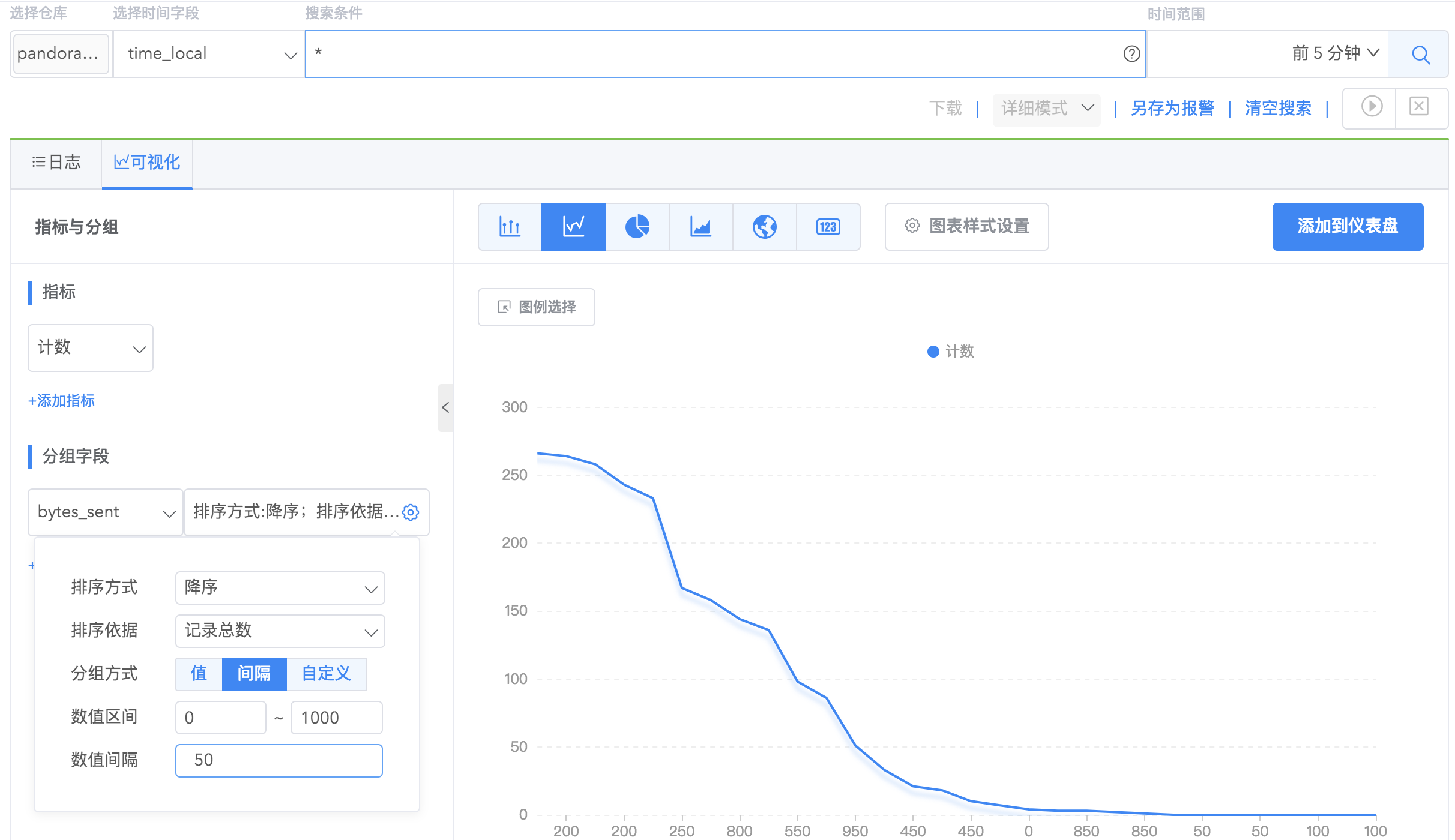
7.对 long 字段类型的字段分组,支持对分组字段设置分组方式,包括按字段值分组、按指定间隔分组、自定义间隔分组。
您可以通过添加多个指标与分组字段并自由组合配置更为复杂的图表。
图表类型
目前 logdb 提供了如下图表类型:
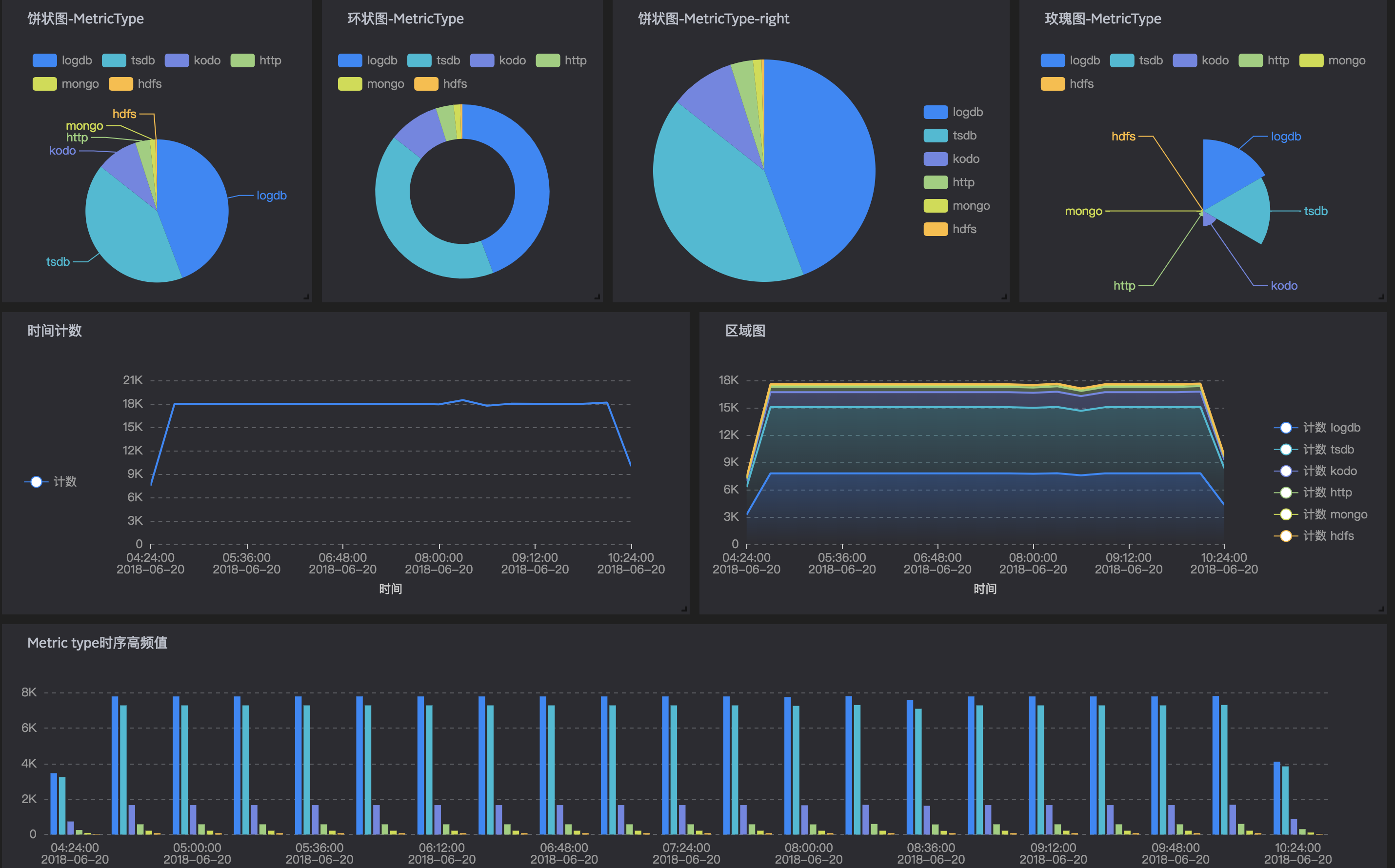
柱状图、折线图、饼图、区域图、统计地图、单值图。

每种图表使用方式如下:
柱状图
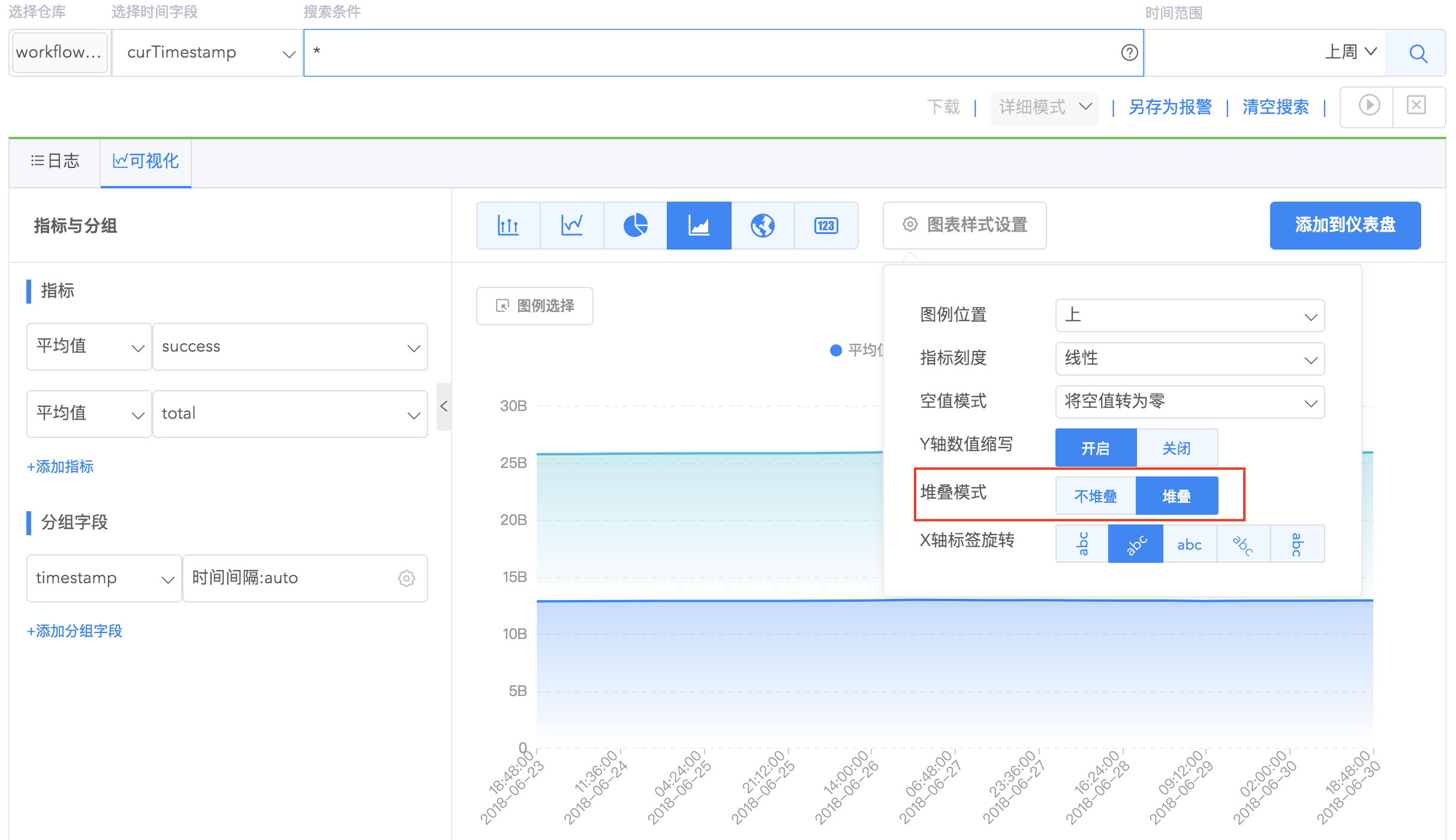
柱状图使用垂直或水平的柱子显示类别之间的数值比较,其中一个轴表示需要对比的分类维度,另一个轴代表相应的数值。 通过样式设置用户可以配置水平柱状图、分组柱状图、堆叠柱状图,样式说明如下:
图表样式设置
| 配置项 | 说明 |
|---|---|
| 图例位置 | 图例在图表中的位置,可以配置为上、下、左、右和无 |
| 指标刻度 | y 轴指标单位刻度,使用对数指标单位刻度在轴值⾮常⼩或⾮常⼤时⾮常有⽤ |
| y轴数值缩写 | 指标值特别大的情况下使用 y 轴数值缩写来优化图表显示样式 |
| 堆叠模式 | 对于有分类的数据字段可相邻显示各类的值,也可堆叠显示 |
| 方向 | 水平即显示为水平柱状图 |
| x轴标签旋转 | x 轴标签可设置显示方式,在 x 轴标签特别长的情况下可用来优化图表显示 |
示例
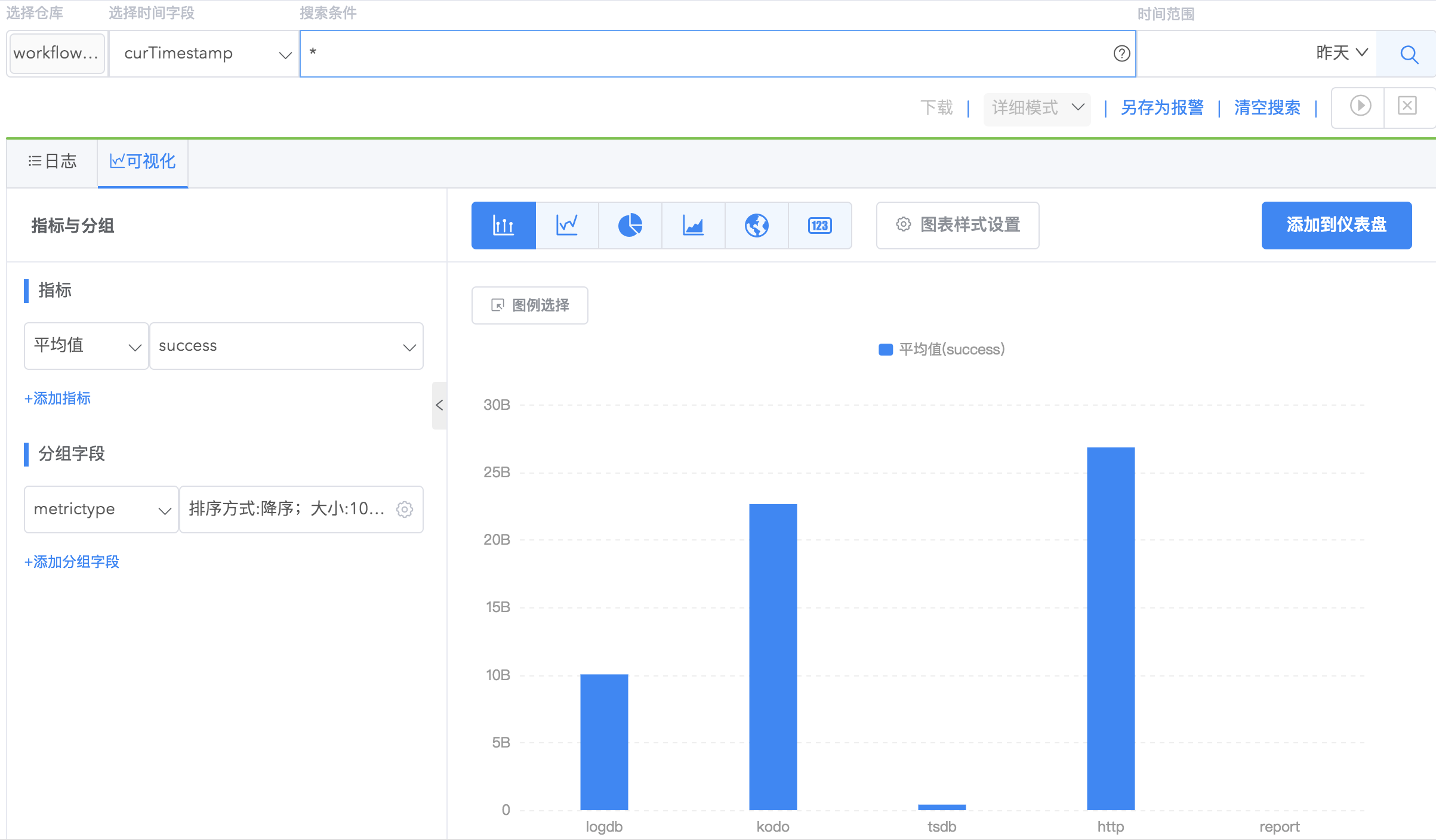
简单柱状图
应用场景:适合应用到分类数据对比。
比较不同 metrictype 的 success 平均值。
分组柱状图(不堆叠)
应用场景:对比不同分组内相同分类的大小,对比相同分组内不同分类的大小。
每个时间点的 metrictype 事件总数对比分析。

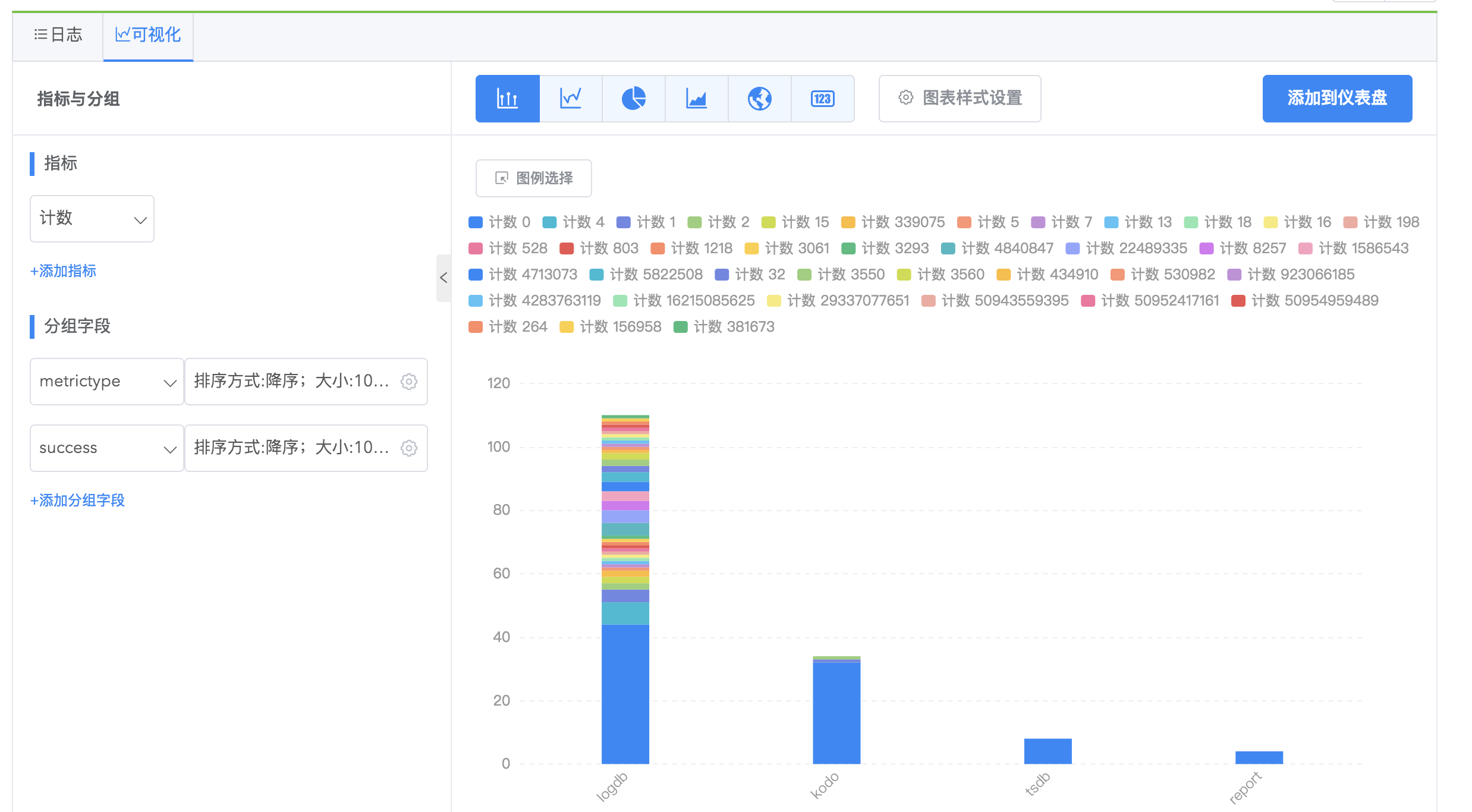
堆叠柱状图(堆叠)
应用场景:对比不同分组的总量大小,同时对比同一分组内不同分类的大小。
每种 metrictype 下的 success 事件总量对比与同类 metrictype 内部 success 事件对比。
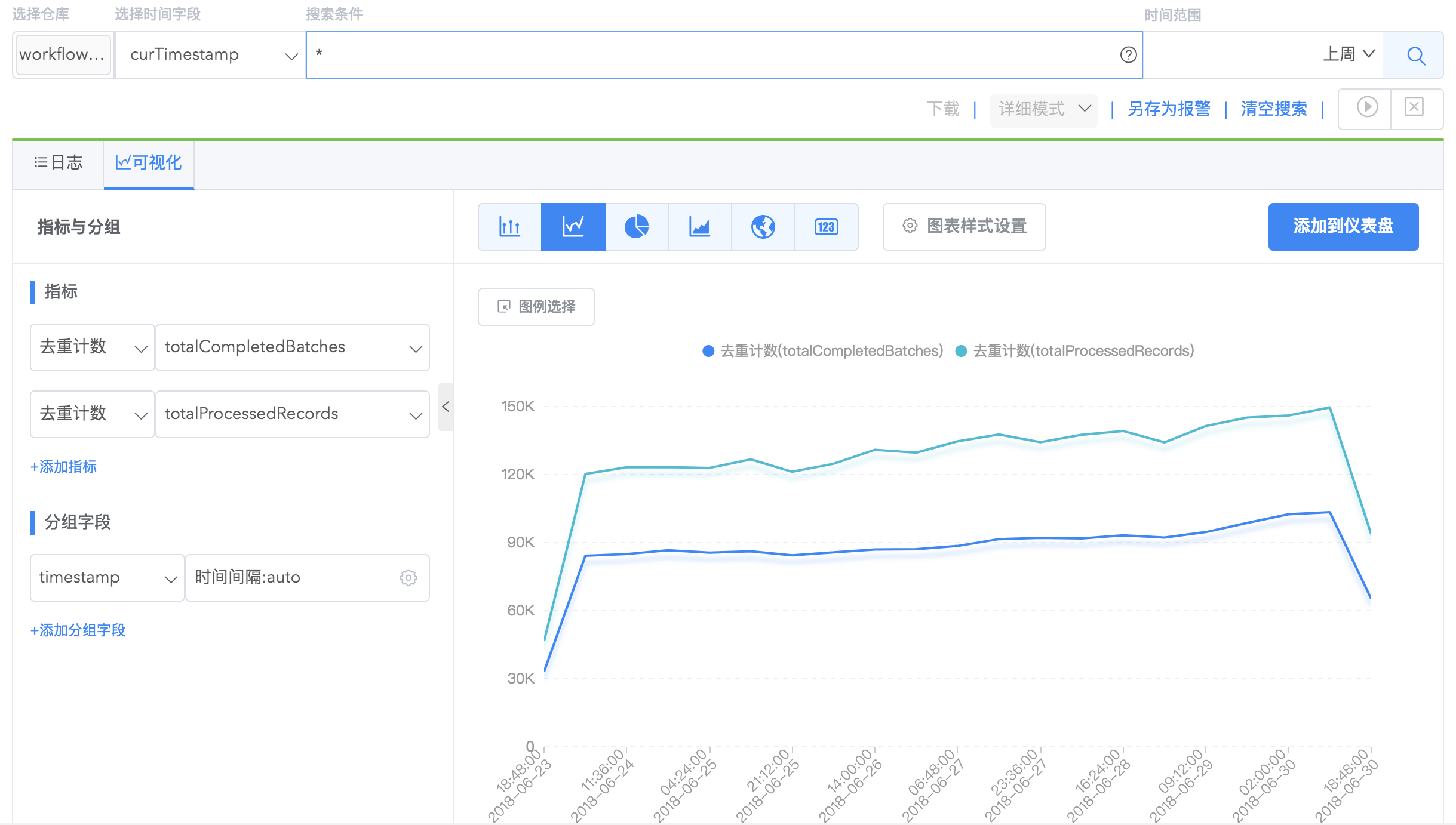
折线图
折线图用于显示数据在一个连续的时间间隔或者时间跨度上的变化,也可用来分析多组数据随时间变化的相互作用和相互影响。
图表样式设置
| 配置项 | 说明 |
|---|---|
| 图例位置 | 图例在图表中的位置,可以配置为上、下、左、右和无 |
| 指标刻度 | y 轴指标单位刻度,使用对数指标单位刻度在轴值⾮常⼩或⾮常⼤时⾮常有⽤ |
| 空值模式 | 将空值的数据点转为零点;将空值的数据点显示为间隙;越过空值的数据点连接前后数据点 |
| y轴数值缩写 | 指标值特别大的情况下使用 y 轴数值缩写优化图表显示样式 |
| 堆叠模式 | 对于有分类的数据字段可相邻显示各类的值,也可堆叠显示 |
| x轴标签旋转 | x轴标签可设置显示方式,在x轴标签特别长的情况下可用来优化图表显示 |
示例
查看 totalCompletedBaches 和 totalProcessedRecords 事件的去重计数随时间变化趋势。
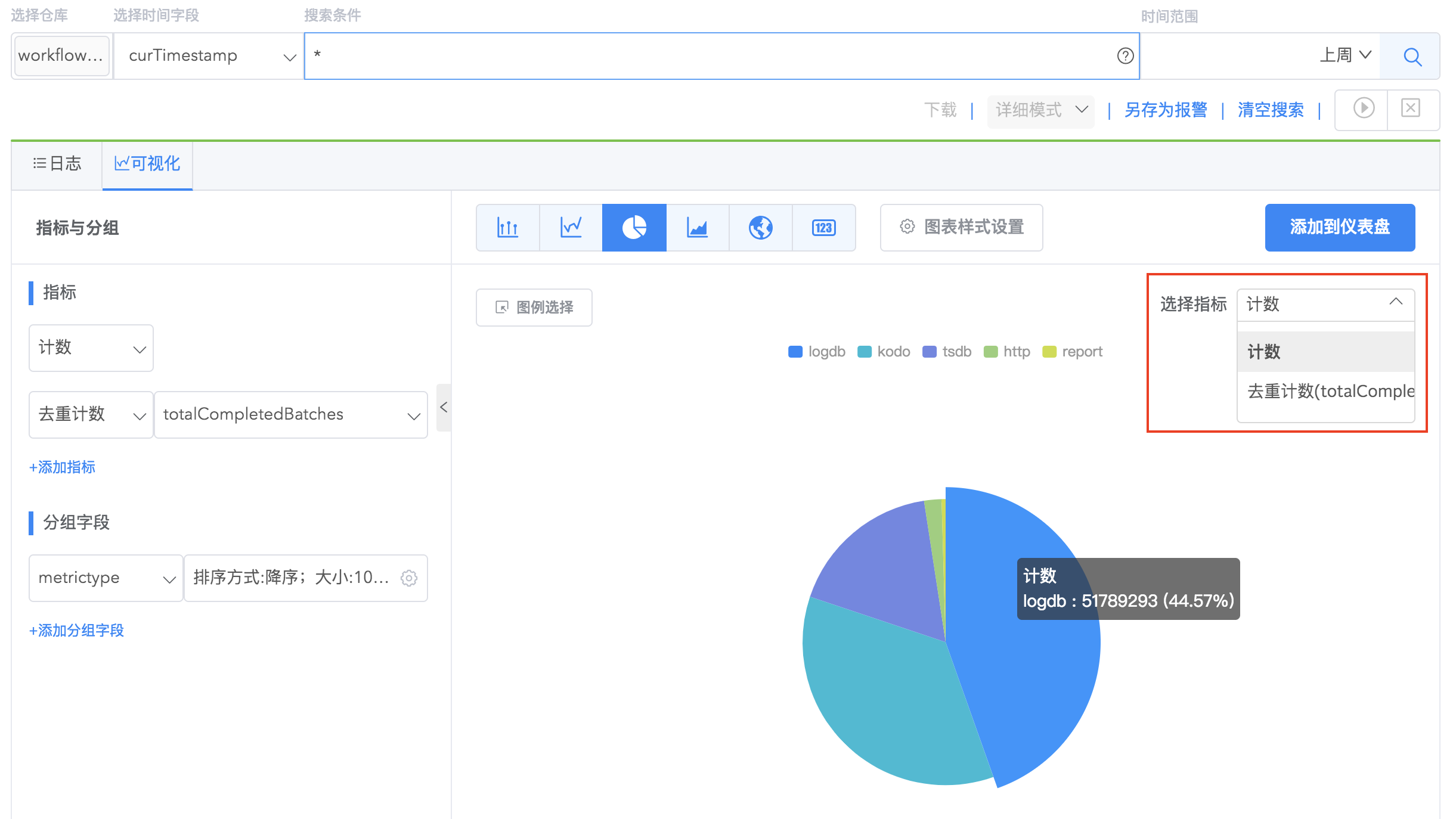
饼图
用于表示不同分类的占比情况,通过样式设置可以配置饼图、环形图、玫瑰图,样式说明如下:
图表样式设置
| 配置项 | 说明 |
|---|---|
| 图例位置 | 图例在图表中的位置,可以配置为上、下、左、右和无 |
| 图表形式 | 可用饼图、环形图、玫瑰图来展示分类占比情况 |
| 最大区域数量 | 饼图切片最大数量,若分组数量超过设定的最大区域数量,剩余分组归类到其他组 |
环形图优点:在进行同种分类下不同指标的对比时,两个饼图直接进行比较是非常不直观的,两个环图间可以通过环状条长度进行简单的对比。
玫瑰图:使用圆弧的半径长短表示数据的大小,玫瑰图的优点如下:
- 饼图适用于不超过 10 条的分类数据,玫瑰图则适用于分类较多的场景(10-30条数据)。
- 由于半径和面积是成平方的关系,玫瑰图放大了各个分类数据之间值的差异,尤其适合对比大小相近的数值。
- 由于圆形有周期的特性,玫瑰图也适用于表示一个周期内的时间概念,比如星期、月份
饼图里您可以切换关心的指标展示。
!> 注意: 目前饼状图只对最新选择的那个分组字段生效。
区域图
区域图是在折线图的基础之上形成的,它将折线图中折线与坐标轴之间的区域使用颜色进行填充,这个填充即为我们所说的面积,颜色的填充可以更好的突出趋势信息。和折线图一样,区域图也用于强调数量随时间而变化的程度,用于突出总值趋势。
图表样式设置
| 配置项 | 说明 |
|---|---|
| 图例位置 | 图例在图表中的位置,可以配置为上、下、左、右和无 |
| 指标刻度 | y 轴指标单位刻度,使用对数指标单位刻度在轴值⾮常⼩或⾮常⼤时⾮常有⽤ |
| 空值模式 | 将空值的数据点转为零点;将空值的数据点显示为间隙;越过空值的数据点连接前后数据点 |
| y轴数值缩写 | 指标值特别大的情况下使用 y 轴数值缩写优化图表显示样式 |
| 堆叠模式 | 对于有分类的数据字段可相邻显示各类的值,也可堆叠显示 |
| x轴标签旋转 | x 轴标签可设置显示方式,在 x 轴标签特别长的情况下可用来优化图表显示 |
- 一般区域图:所有的数据都从相同的零轴开始。

此时两组数据重叠显示,不利于观察。
- 堆叠区域图:每一个数据集的起点不同,都是基于前一个数据集。用于显示每个数值所占大小随时间或类别变化的趋势线,堆叠起来的区域图在表现大数据的总量分量的变化情况时格外有用。
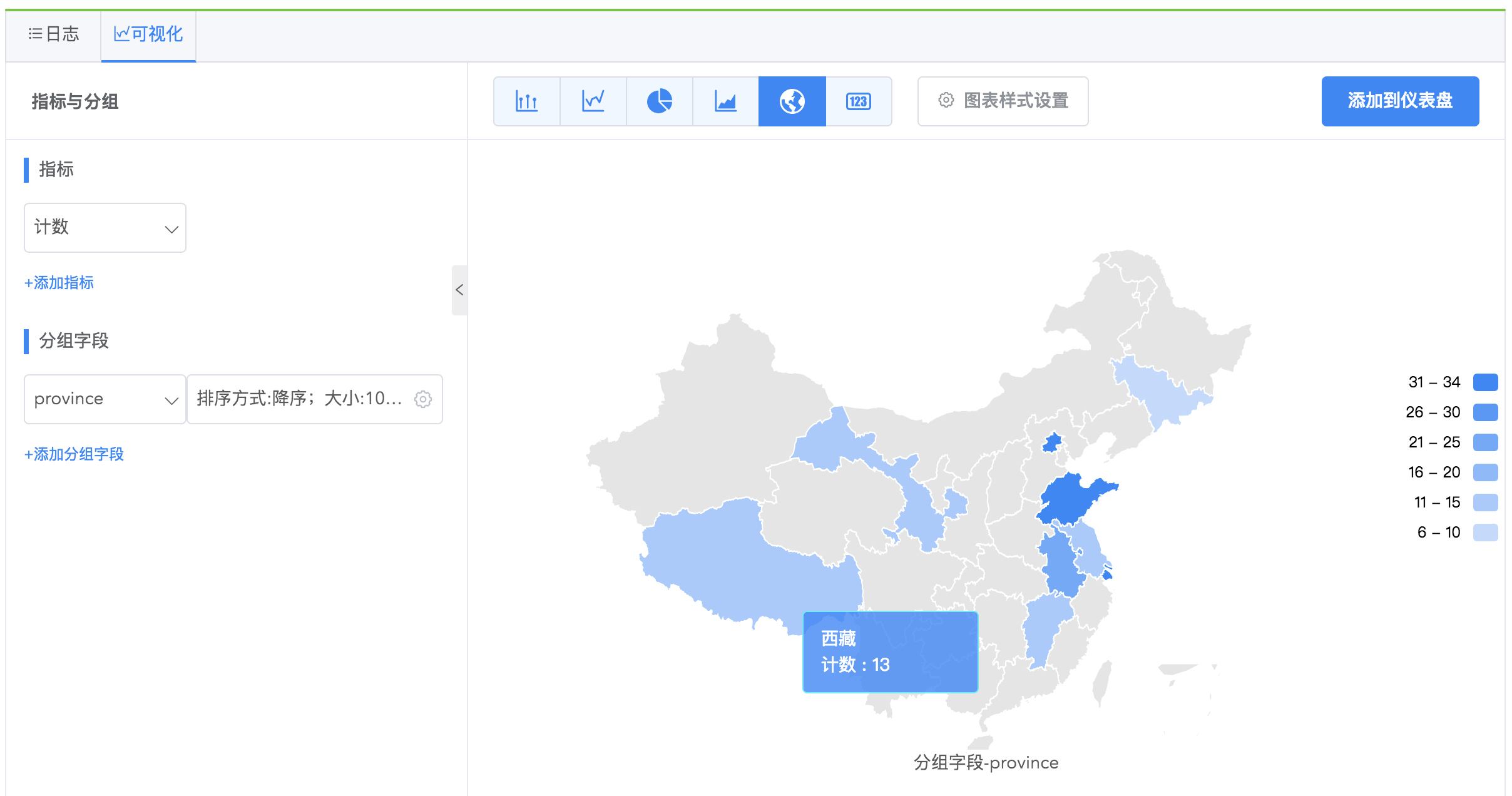
统计地图
统计地图通过在地图分区上使用视觉符号(在这里是颜色渐变)来表示一个范围值的分布情况,颜色深表示数据量大。颜色浅表示数据量小。日志分析服务现在提供中国地图,其他地图类型正在开发中,敬请期待。
图表样式设置
| 配置项 | 说明 |
|---|---|
| 颜色选项 | 预设多种色系来表现数据在地图上的分块情况,用户根据个人倾向自由选择 |
| 分块数量 | 对数据量设置分级显示,每一级对应一个数值范围 |
示例
查看不同区域的事件总数。
单值图
使⽤单值可视化显⽰⼀个指标及其趋势。
示例
统计指定仓库在指定时间范围的日志数量:
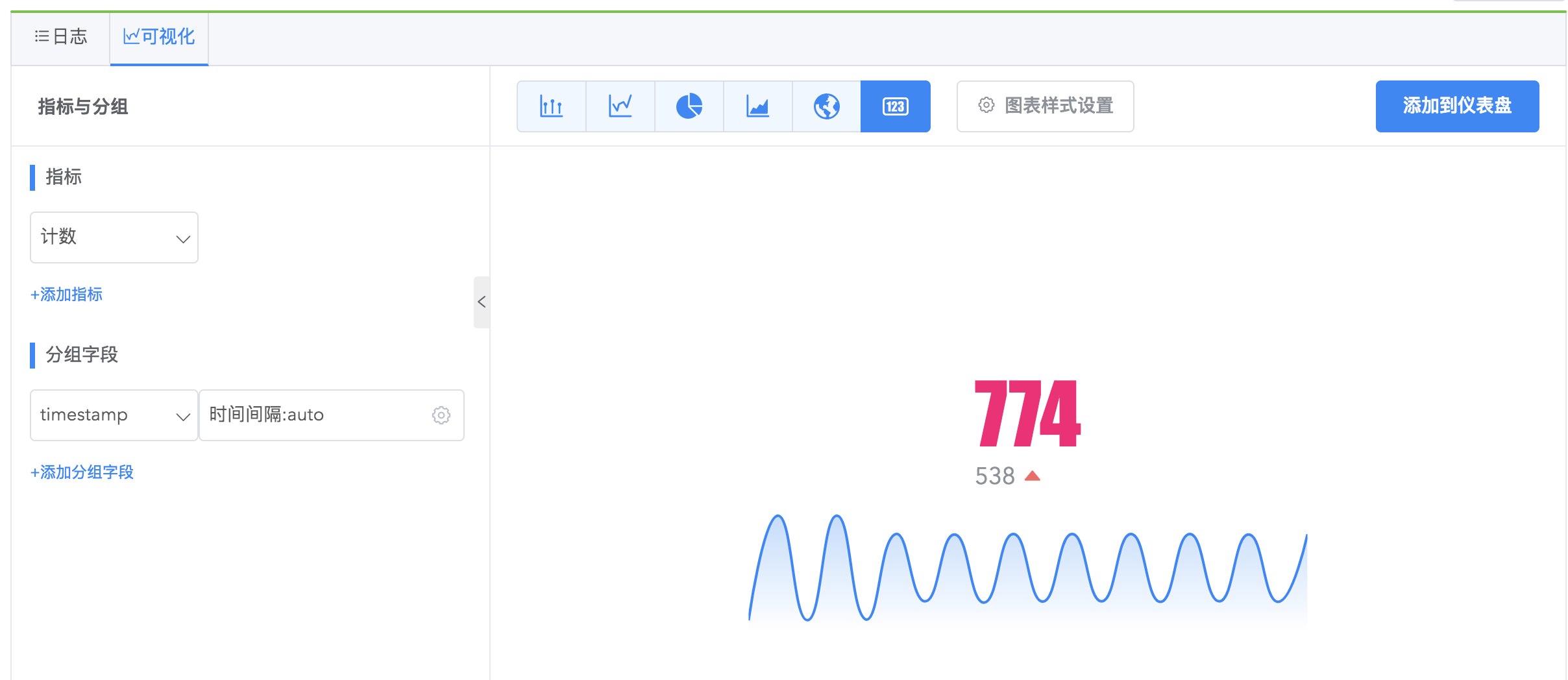
此单值图信息包括当前时间的日志数量、指定时间范围内的日志数量变化趋势、相比上一个时间点的变化值。
除了统计当前指标以外,单值图还可以统计一段时间范围内的聚合指标。具体说明如下:
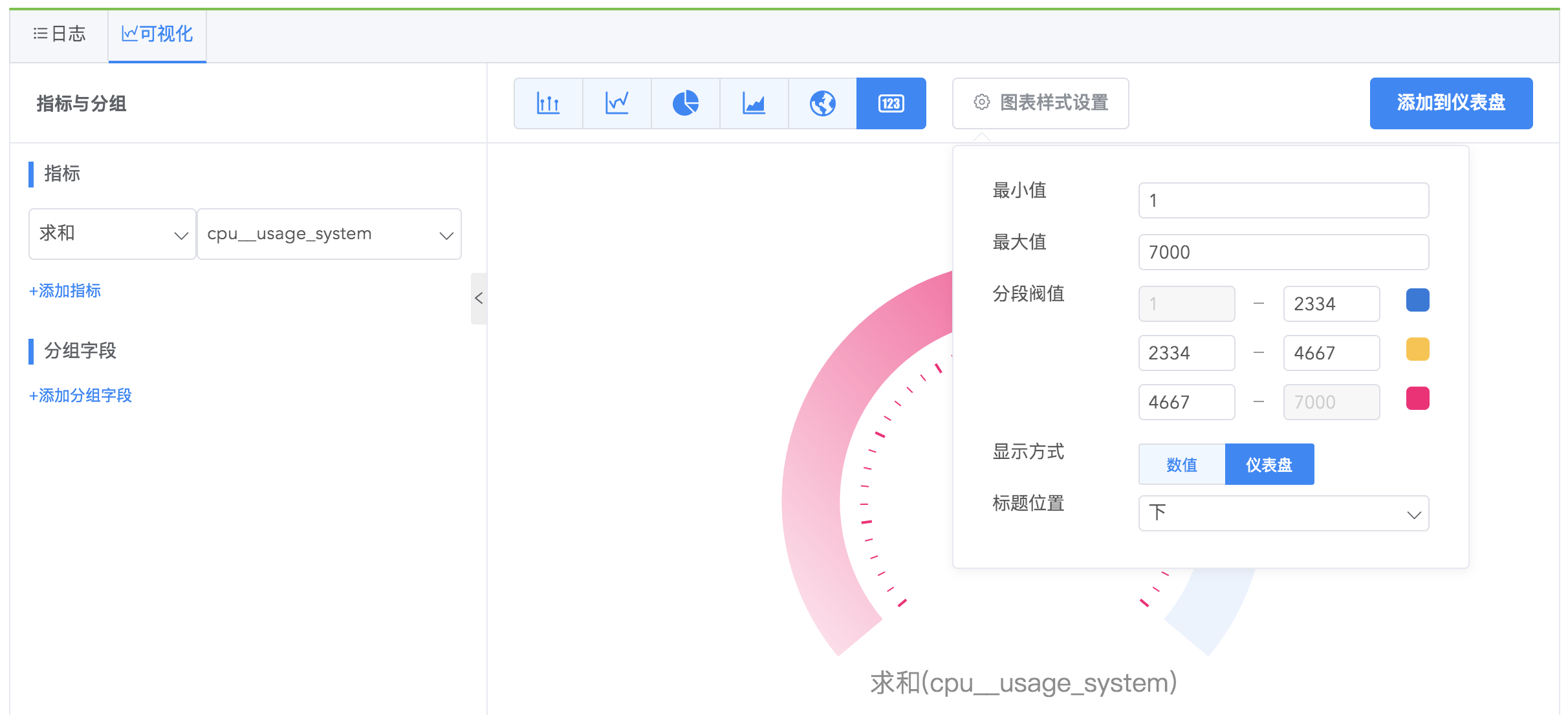
图表样式设置
| 配置项 | 说明 |
|---|---|
| 统计选项 | 可以选择统计当前值/一段时间范围内的数据总和/平均值/最大值/最小值 |
| 最大值、最小值、分段阈值 | 用来确定数值在不同的范围显示不同的颜色,通过颜色强调数值的范围值或者趋势,通常用在仪表单值图里 |
| 显示方式 | 数字单值图或者仪表单值 |
| 标题 | 对于仪表单值图,用来确定标题在图表中的位置 |
| 时序折线 | 对于数字单值图,是否显示时序折线图 |
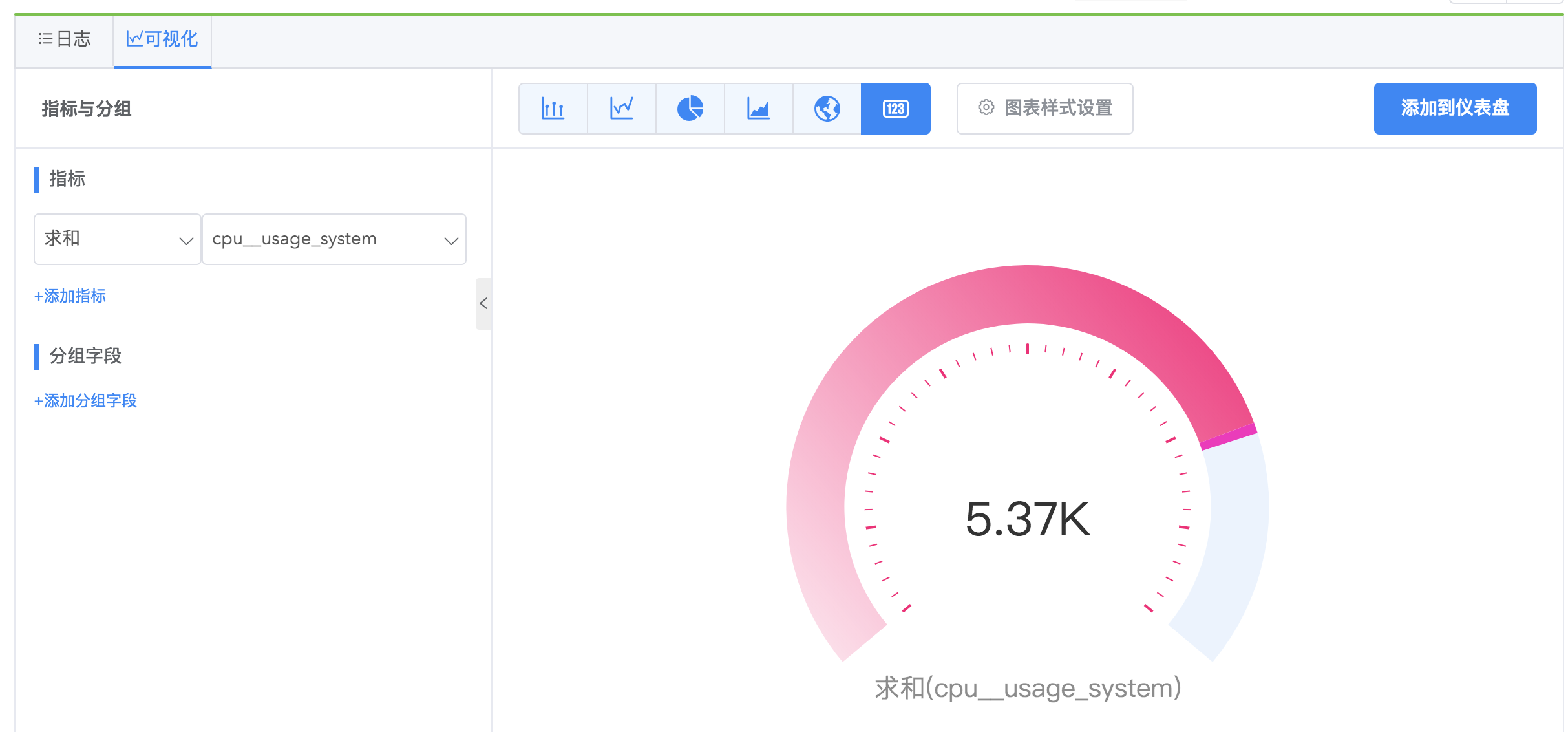
仪表单值图
使⽤仪表单值图一般用来统计指标状态和范围信息,设置好颜色对应的数值范围,您可以快速读出数值意义,如蓝色代表数值处于正常范围,黄色代表数值偏高,红色代表数值过高,可能触发告警。
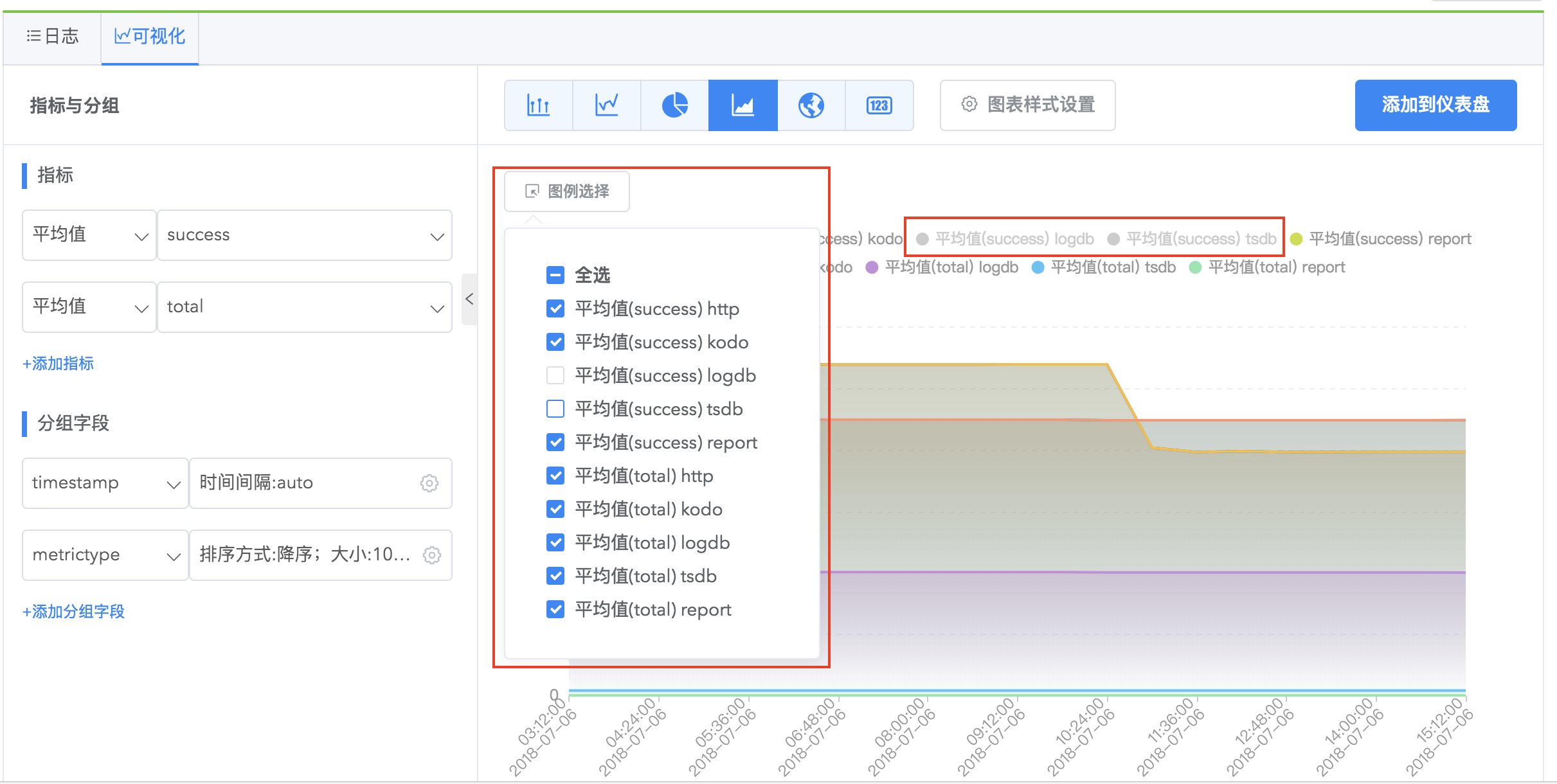
如何观察感兴趣的数据?
在分组太多的情况下,您可以通过我们的图例选择功能,只观察您感兴趣的分组。
如果您感兴趣的分组是少数,您可以点击取消全选,再点击自己感兴趣的图例即可将它们显示在报表中。
如果您感兴趣的分组是大多数,您可以点击全选,再点击图例即可以取消显示不感兴趣的图例。
仪表盘
配置好报表之后,可以将常用的报表保存到仪表盘,方便对图表进行管理以及实时监控数据。
仪表盘页面包含以下几个组件:
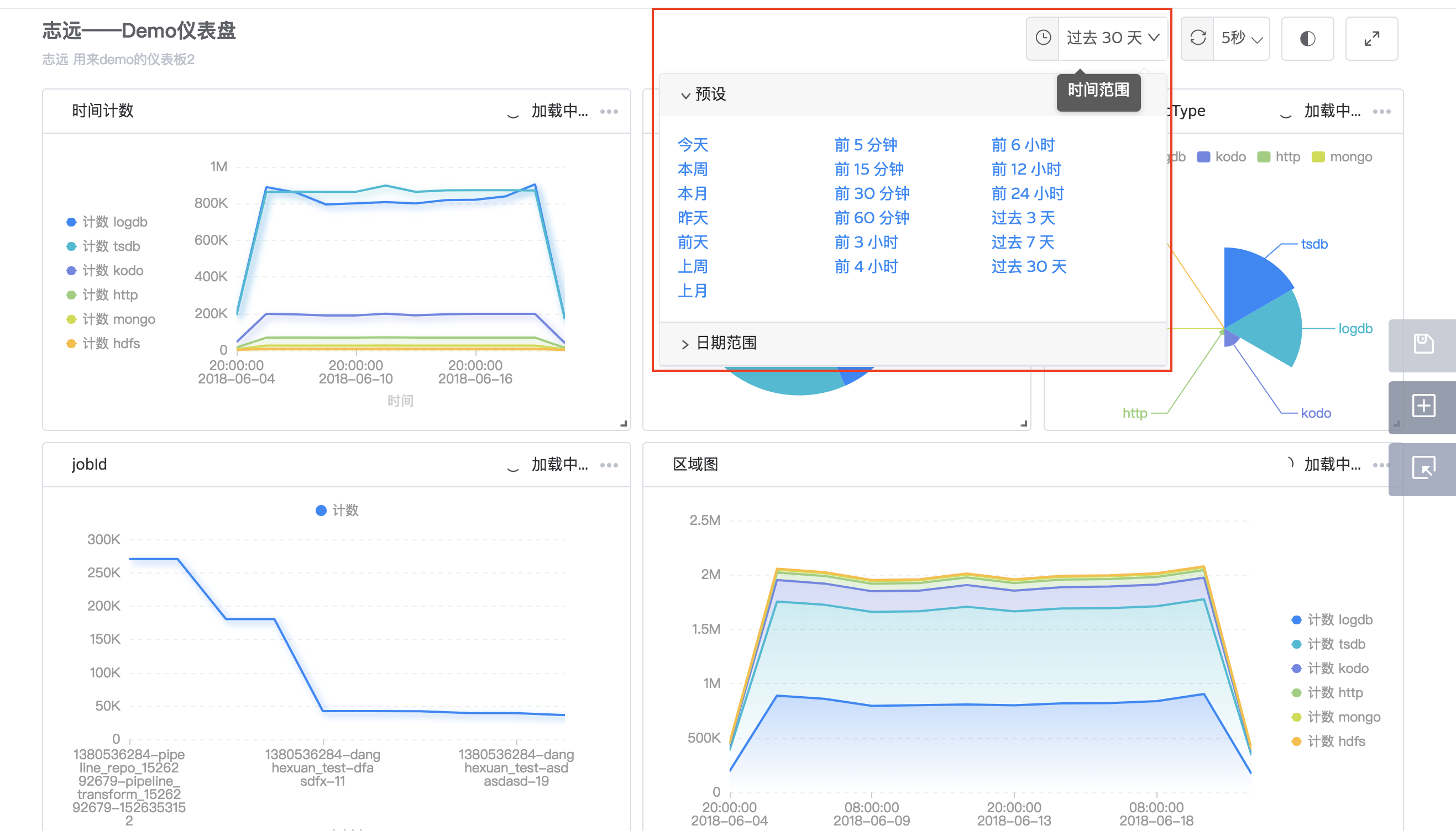
时间范围
选择时间范围对当前仪表盘内的所有图表的显示时间进行统一控制。
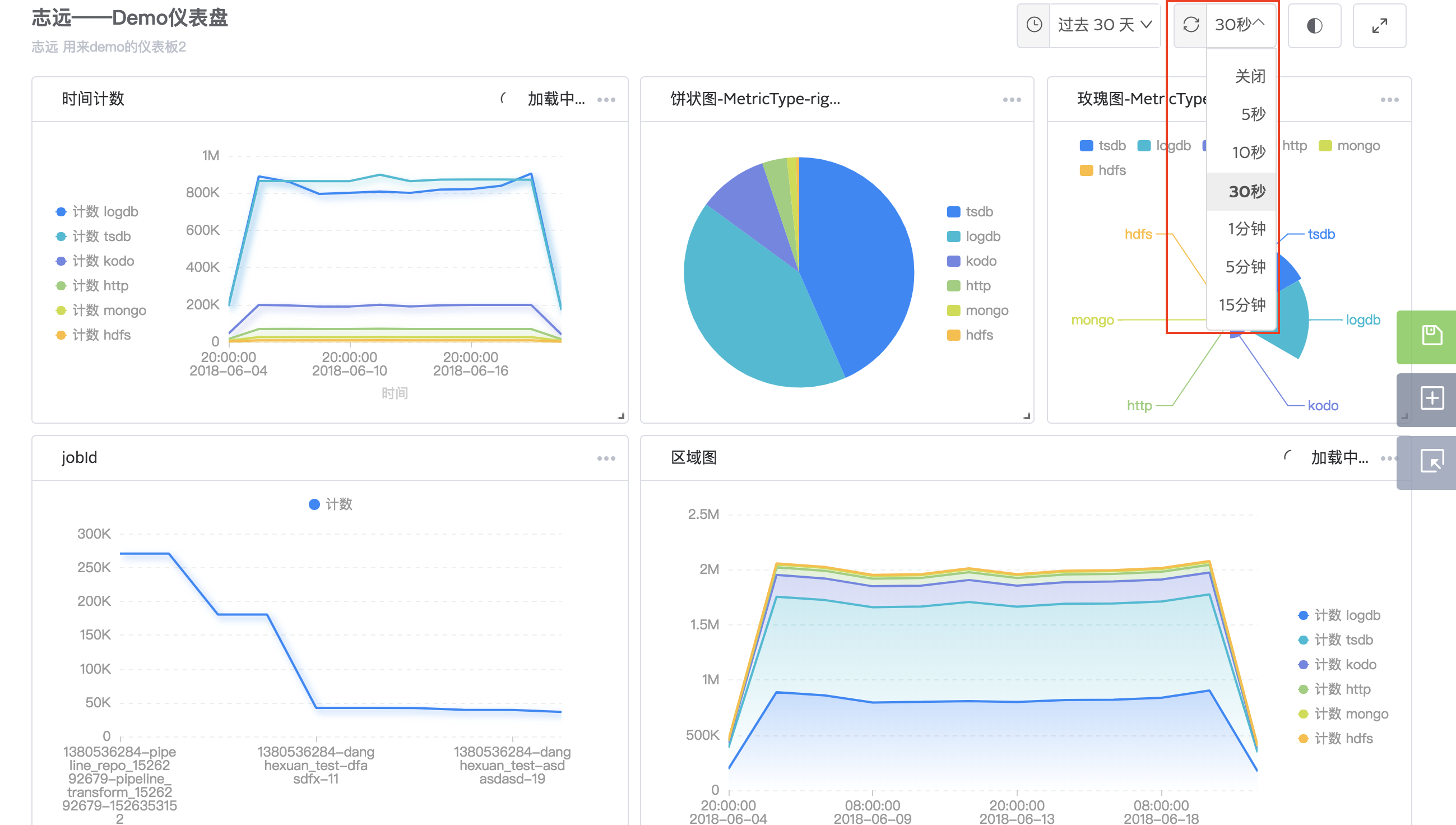
刷新
选择刷新频率,当前仪表盘的所有图表将按照此频率自动刷新。
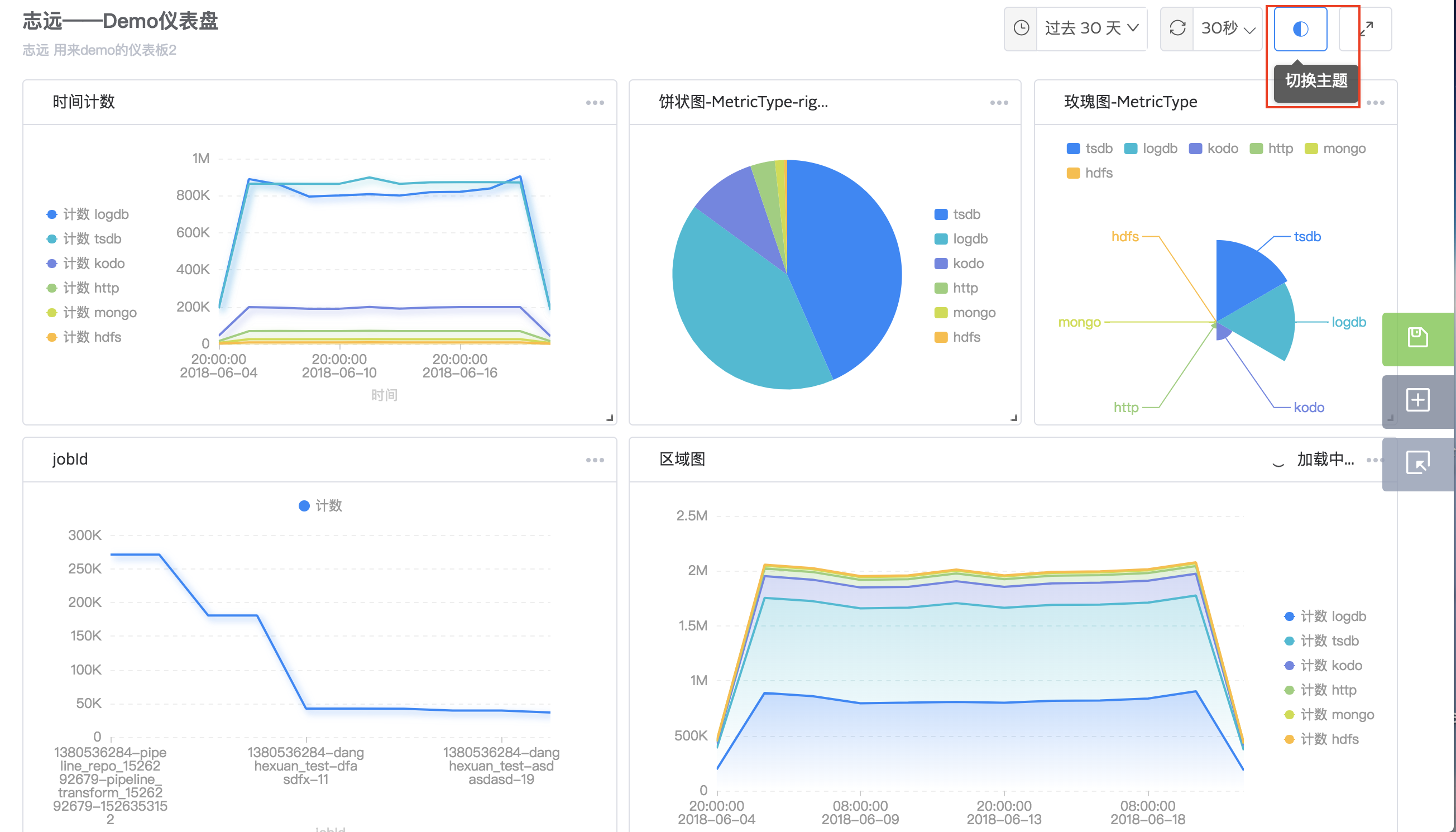
仪表盘风格
自定义仪表盘显示风格,目前支持黑、白两种背景色。
全屏显示
支持仪表盘内容全屏显示。
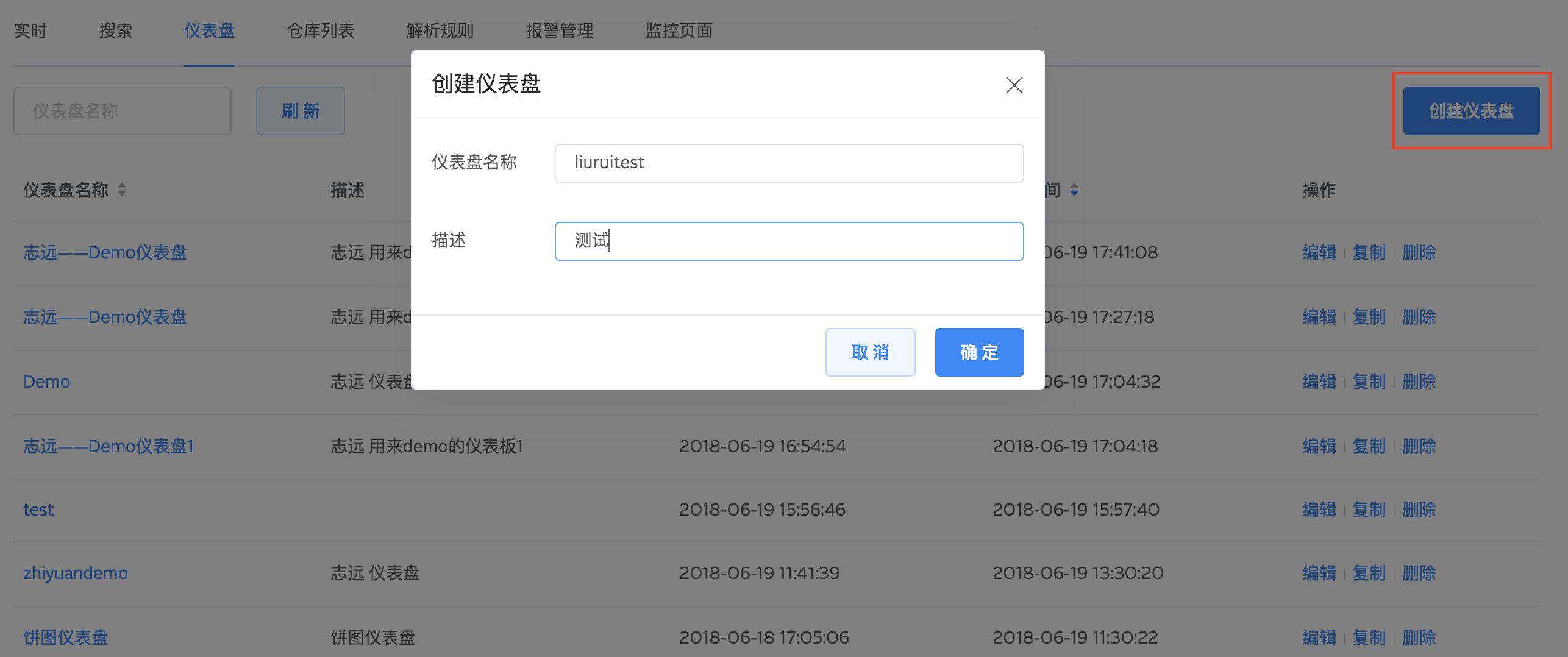
创建仪表盘
企业的运营团队、开发团队、营销团队有不同的指标查看需求,用户可根据不同的需求定制仪表盘,在团队内部共享。
进入仪表盘列表页,点击 创建仪表盘输入仪表盘名称与描述创建一个新的仪表盘。
您也可以通过复制按钮直接复制仪表盘。
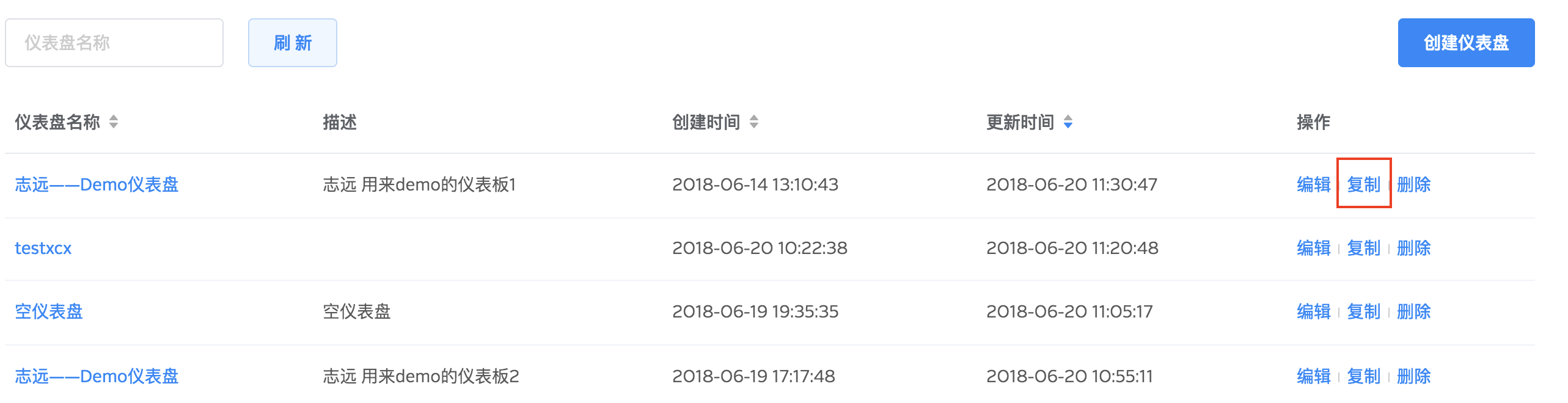
点击仪表盘名称或者编辑按钮可进入仪表盘编辑页面。

添加图表到仪表盘
您可以选择创建图表加入当前仪表盘,或者从已有仪表盘导入图表到当前仪表盘,免去配置图表工作。
创建图表
点击创建图表或者页面右侧的添加图表 icon,进入图表配置页面,配置图表操作参考配置报表。

配置好以后点击添加到仪表盘,将图表添加到当前仪表盘,也可以添加到新建仪表盘。
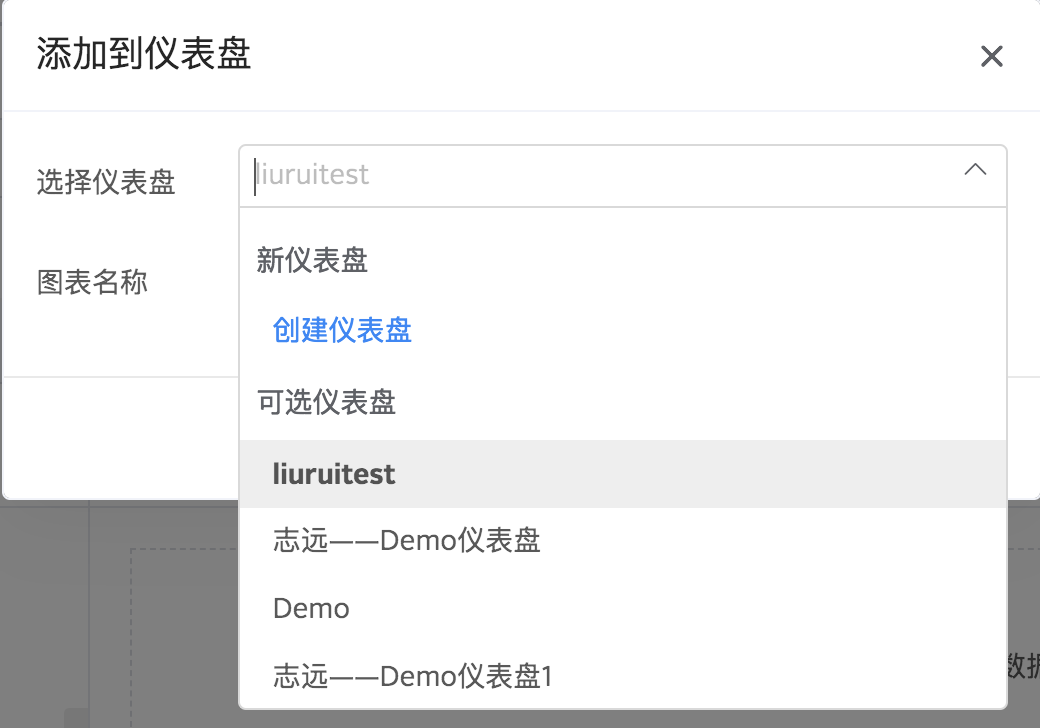
从已有仪表盘导入图表
点击从其他仪表盘导入或者页面右侧的的导入图表 icon,滑出已有仪表盘列表。
点击任意图表名称即可将图表添加到当前仪表盘。
!>注意:添加图表、导入图表、删除图表、修改图表或仪表盘名称均需要在页面右侧点击保存按钮保存操作。
编辑仪表盘
仪表盘的名称、描述可编辑,通过鼠标滑入即可看到编辑按钮。
编辑图表
- 图表名称可编辑
通过鼠标滑入即可看到编辑按钮。
- 图表内容可编辑,点击图表右上角的设置按钮,可选删除图表或编辑图表。
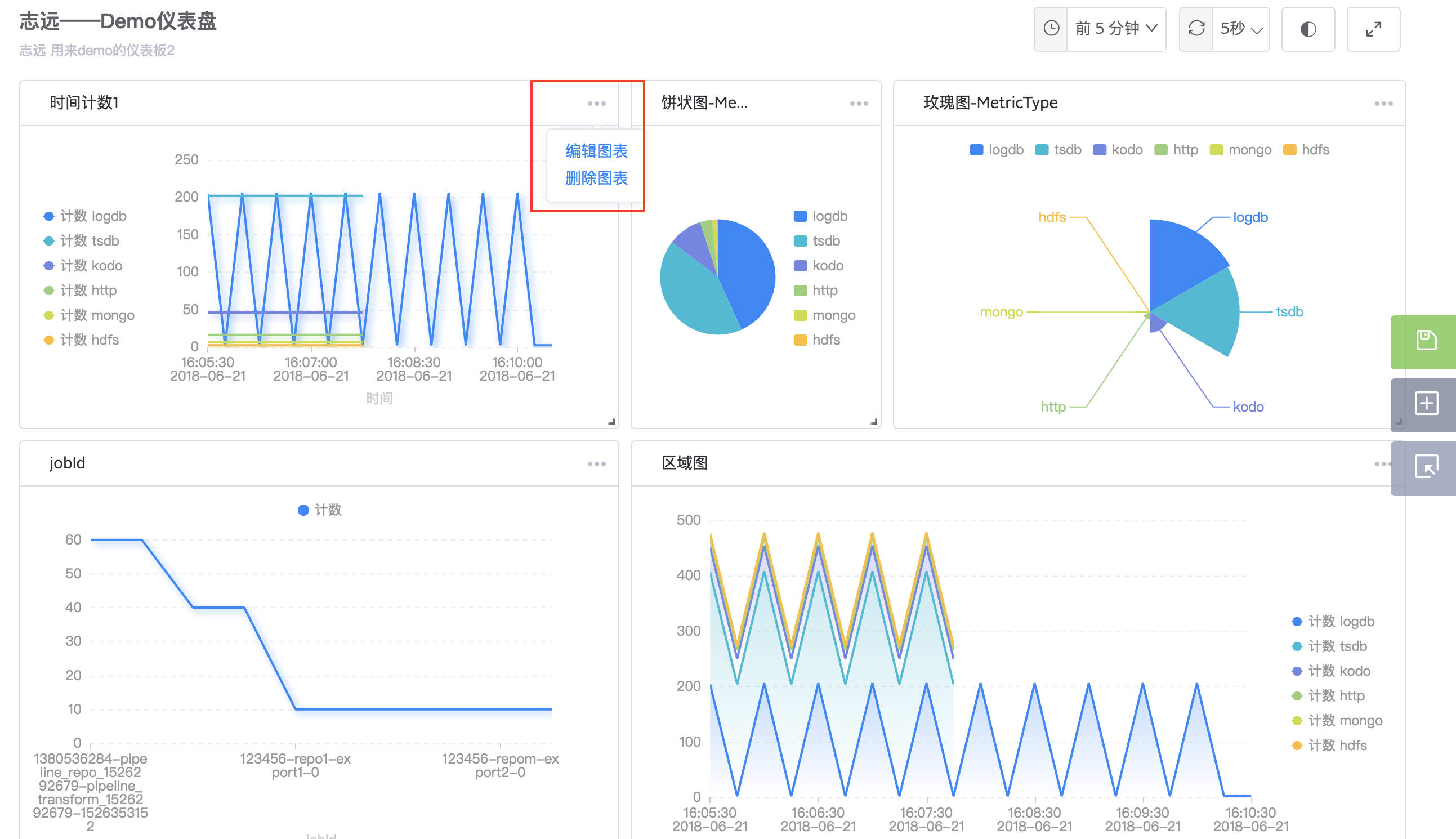
点击编辑图表按钮,进入图表配置状态。
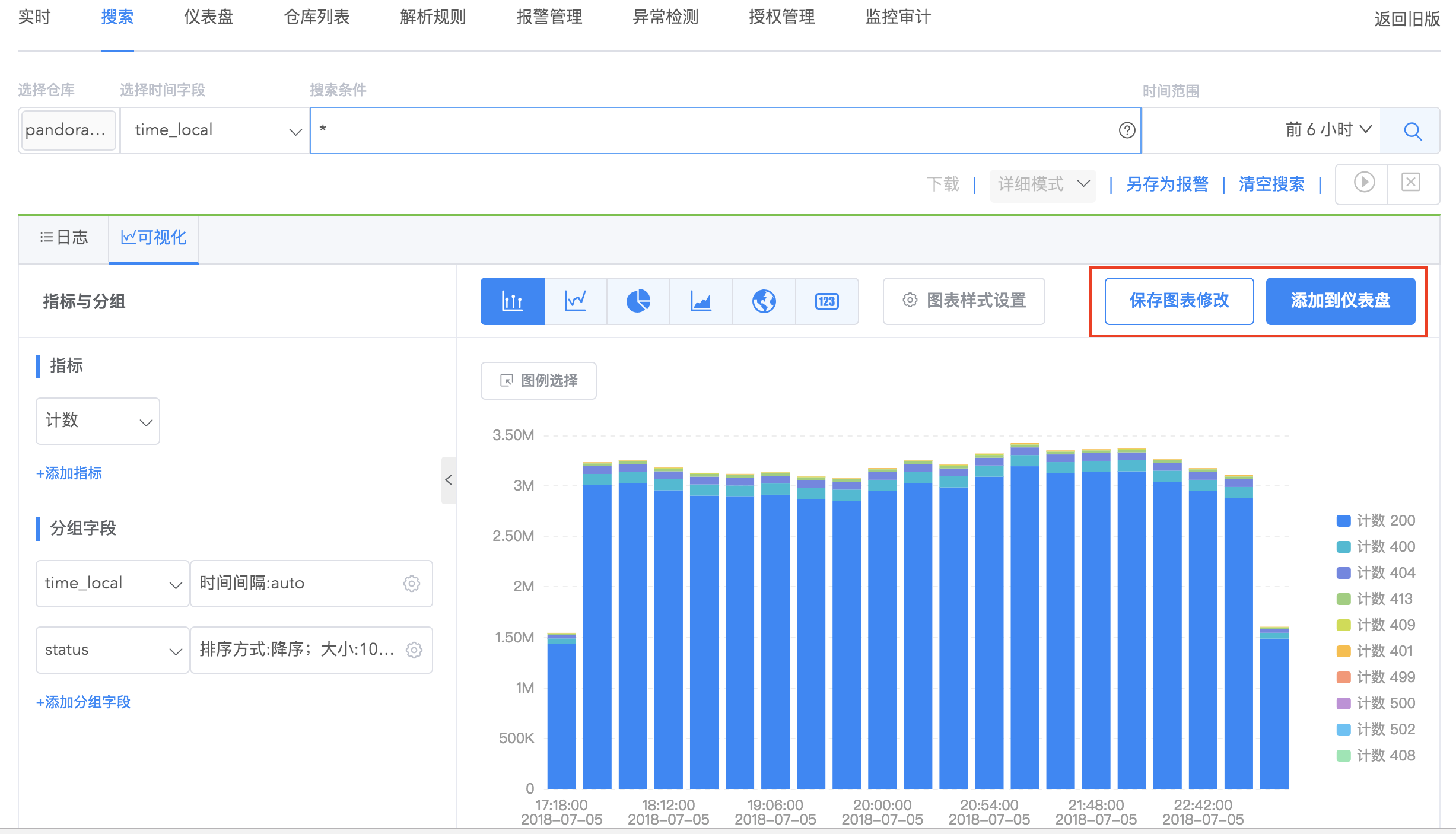
点击保存图表修改:在原有图表上进行改动。
点击添加到仪表盘:原来的图表依然保留,另外将当前改动的图表添加到仪表盘。
仓库管理
logdb 支持日志仓库和实时仓库的管理。
实时仓库解析规则绑定
创建实时仓库支持对实时仓库设置解析规则,每个实时仓库最多绑定 5 个规则,规则的解析顺序是从前到后。您可以自由切换解析规则优先级,仓库的解析结果为所有规则解析出来字段的并集。对于绑定了解析规则的实时仓库,可以直接批量上传文件到实时仓库查看。参考文件批量上传
仓库配置导入导出
支持导入 json 文件创建仓库。导入成功以后系统会自动打开创建仓库页面,并且字段全部自动添加。
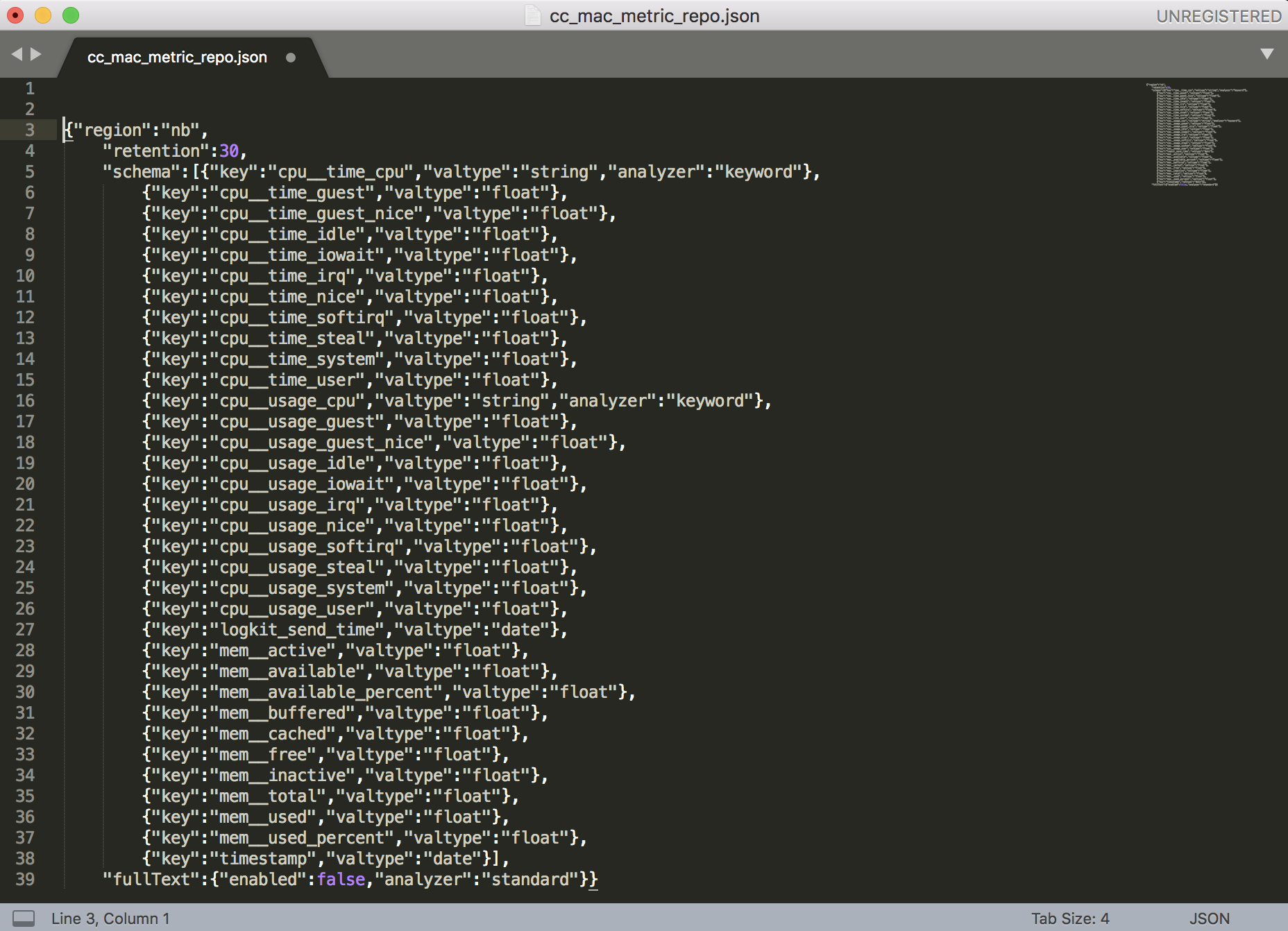
同样,您也可以导出仓库的配置到本地保存,下次如果您想创建同类型 Schema 的仓库,使用导入功能即可。
通过导入和导出功能相结合,您可以精准快速地创建数据仓库,省去重复工作。
报警
报警是logdb新上线的功能,帮您监控日志数据。您只需要设置好报警指标、报警阈值等,当满足触发条件时,通过HTTP接口回调、邮件提醒、短信提醒这三种方式,系统会给您发送报警相关信息,提醒您日志哪里出现了异常。
配置报警
单击搜索栏下面的“另存为告警”,开始配置报警项。
在报警设置页面,您需要填写以下信息:
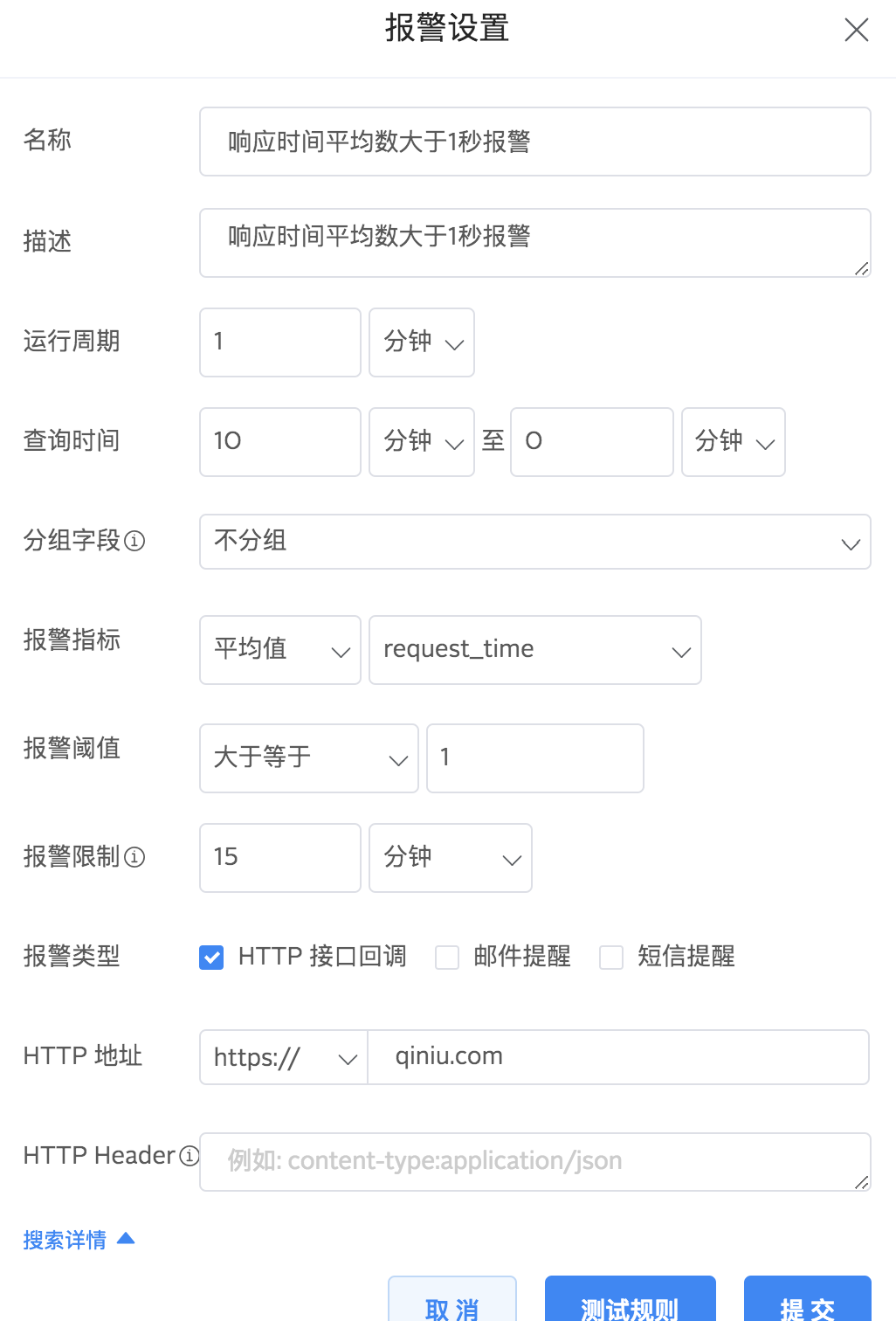
这是一条名称是“响应时间平均数大于1秒报警“的报警配置,它的意思是:每隔1分钟检测最近10分钟内的日志内容,request_time这个字段的平均值如果超过1就触发报警,且15分钟内即使满足报警条件也只触发一次报警。
运行周期
您可以设置每隔多久检测一次日志内容报警。
查询时间
设定一个查询的时间范围,只针对这个时间范围内的日志检测报警。
分组字段 报警指标 报警阈值
您可以通过这三条信息创建报警触发条件,其中您可以通过分组字段对数据进行分组,对每个分组的数据分别监控报警指标。通过自由组合,您可以创建以下两种报警触发条件:
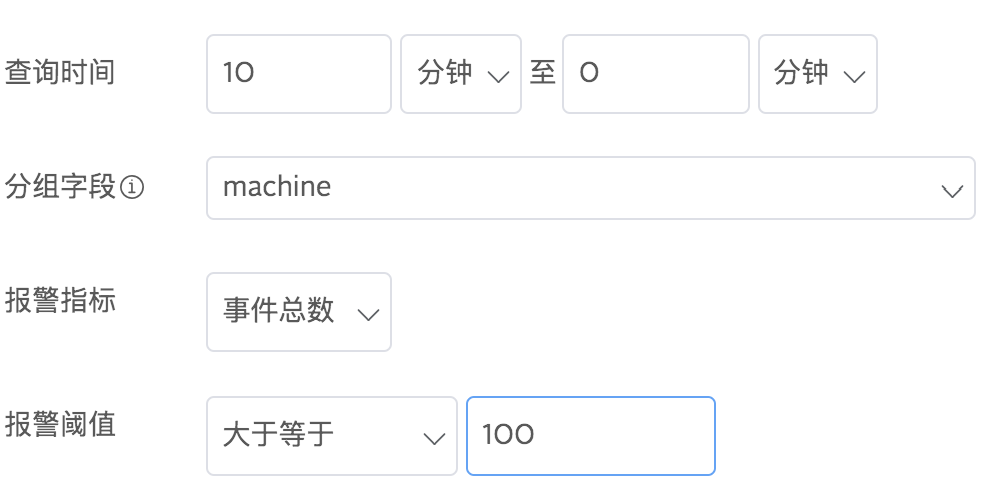
1.按事件总数报警
报警指标选择事件总数,给定一个触发报警的阈值。例如,您可以设置报警条件为10分钟内根据machine分组的日志事件总数超过100:
2.按字段统计数报警
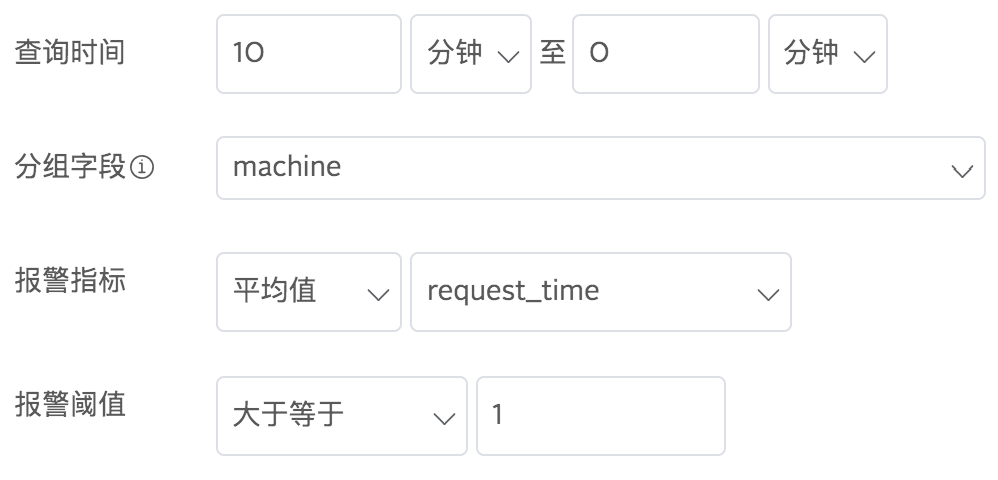
在报警指标里选择统计方式(总和、平均值、最大值、最小值、中位数、分位数),紧跟其后选择字段名,例如,告警触发条件为:根据machine字段分组的日志数据里,request_time在10分钟之内的平均值大于1:
报警限制
防止您在短时间内遭遇报警轰炸,您可以设置一个固定时间段,在该时间段内出发告警后,系统不再重复发送同类告警信息。
报警类型
- logdb支持HTTP接口回调报警方式,添加能接受请求的地址,logdb会发送告警内容到该地址,提醒您日志哪里出现了异常。同时可以在HTTP请求中增加自定义的Header,用来完成例如鉴权等多种高级需求。请求方式为HTTP POST请求,请求体格式如下:
{"alert": "alert", // alert 名字"time": "2018-03-06 14:15:52", // 报警时间"metrics": [{"buckets": { // 每个分组的详细信息"groupId": "分组1" // groupId 字段为 分组1},"value": 137543.0, // 分组的统计值"abnormal": true // 是否出现异常,true为异常,false为正常}, {"buckets": {"groupId": "分组2"},"value": 69610.0,"abnormal": true}]}
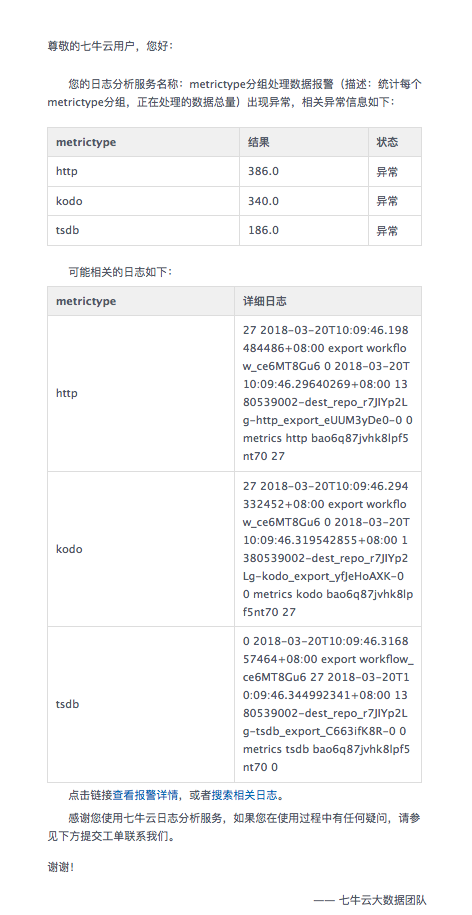
- 邮件报警:支持发送邮件到指定多个邮箱内进行报警。邮件包含了报警的异常信息,以及可能的相关日志。
- 短信报警:短信报警可以指将报警时的简略信息发送到用户手机上,随时随地掌握系统健康状况。
尊敬的七牛云用户,您的日志服务名称:metrictype分组处理数据报警(描述:统计每个metrictype分组,正在处理的数据总量)出现异常。metrictype分组含有3个异常分组,例如分组值为http的当前指标【sum(success)】值为 386.0 小于等于报警阈值【3000.0】。详情敬请登录七牛云查看。【七牛云服务】
测试
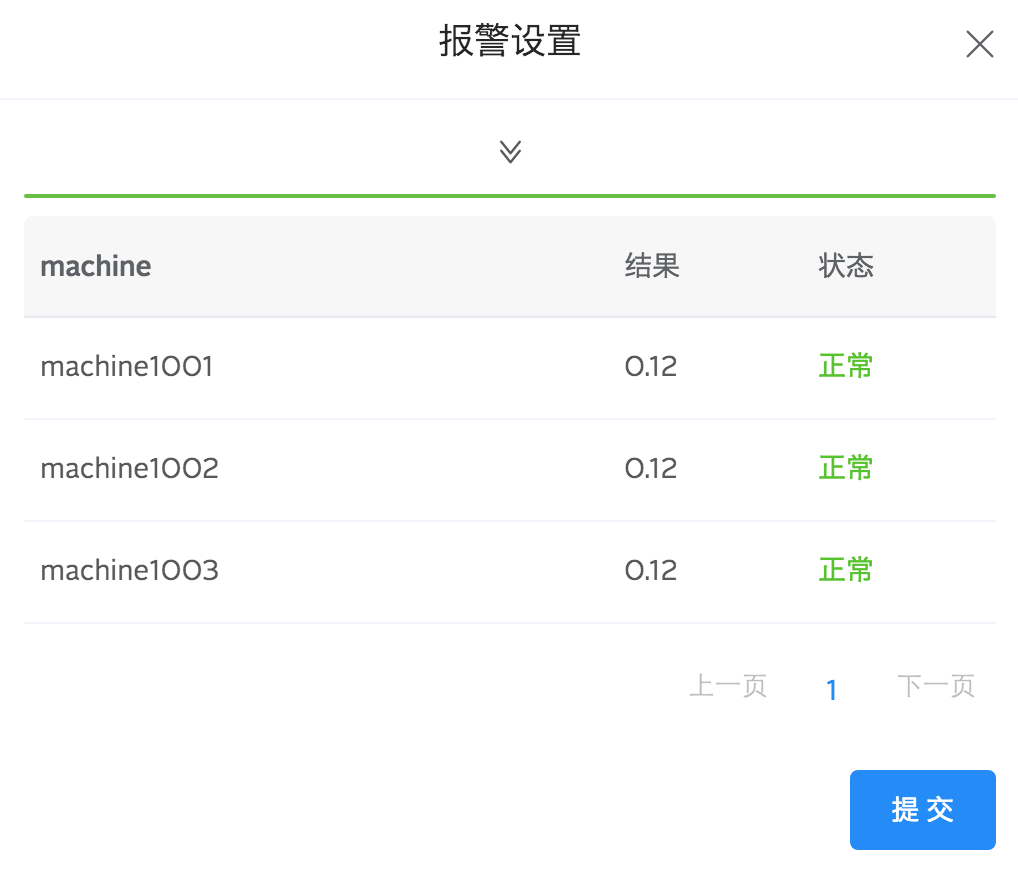
填好配置项以后,您可以点击测试规则测试一下报警设置是否生效。
!> 注意:每个账号暂时最多只支持创建5条报警。如果需要额外创建报警,请与管理员联系。
都设置好以后,您就可以让logdb帮您监控数据啦!
logdb 系统关键字
在 logdb 系统中,我们有一些系统关键字,在命名的过程中,我们应该避免使用这些关键字(包括大小写)。
index, _type, _id, _uid, _size, _source, _all, _routing, _parent, _meta

若有收获,就点个赞吧
0 人点赞
