0x00 写在前面
参考资料,fireeye2017年的报告:https://www.fireeye.com/blog/threat-research/2017/12/recognizing-and-avoiding-disassembled-junk.html
奈沙夜影大佬博客:https://blog.csdn.net/whklhhhh/article/details/88677670
0x01 概念
花指令(Junk code)可以理解为无效指令,指会出现在程序中,但是程序并不需要真正执行或者执行之后不会产生结果也不会影响程序正常运行的指令。
花指令的存在就是为了增加反编译难度,对真实指令进行混淆保护,让人在逆向过程中不能很好的定位到真实的指令。
0x02 原理
刚接触花指令,目前来看分为两种,1是手动加入一些无效的指令,干扰分析,2 是利用反编译软件的逻辑漏洞使得反编译软件解析错误,从而得到错误的汇编指令。
介绍花指令之前,先介绍一下目前反汇编的两种思路:
- 线性扫描(od)
也就是从开头到结尾依次读取机器码进行反汇编
- 递归下降
从程序入口向后反汇编,遇到条件条件跳转则分别从分支的地方进行反汇编,无条件跳转则尝试从目的指令继续反汇编。
我们先来说说第一种。
在反汇编的时候,首先会确定指令开始的首地址,然后根据这个指令推断是哪个汇编指令,然后依次的将后面的指令全反汇编出来。在这个过程中,如果有人故意将错误的机器指令放在了错误的位置,那么在反汇编的时候就很有可能从这个点开始将后面的数据全部的错误反汇编出来。
举个🌰:机器码E8对应的指令是call,如果我们手动嵌入一条指令E8xxxx,这样反编译解析的时候就会把E8解析为call,然后后面的四个字节解析为地址。由于call指令的本质也是跳转,不过是作为子程序或是函数的跳转指令,所以IDA一般会将call的地址当做一个函数的起始地址,如果这个地址不是函数的起始地址,那么call之后就会破坏函数的完整性。
编写这种花指令,我们需要记住exe原本的程序入口点,在程序中找一个地方写一段保持堆栈平衡的花指令,然后跳转回原始的入口点,再使用工具将程序入口点改写为花指令开始的地方,这样就能让反编译软件反编译出错误的汇编指令。
0x03 分类
最常见的一种花指令是 jx + jnx方式构建一个绝对跳转
比如上图的指令中,JNZ表示可能跳转,反编译软件解析的时候后面会预留,导致破坏后面的指令解析。
还有一种比较常见的是call + pop
上面已经说过,call的本质也是指令跳转,和jmp不同的是,call之后ip会变,所以call实际上等同于jmp + push ip。因为如果通过add esp,4 来降低栈顶即可抵消push ip,使得call完全等同于jmp,这个时候可以用call来实现jmp的跳转,但是IDA识别的时候,依旧会把这里设备为函数分界,从而导致函数范围识别错误。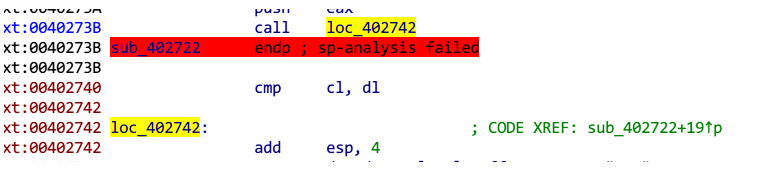
还有一种是stx和jx的组合
原理和call相似
0x02 常见指令
以fireeye给出的例子举例,fireeye生成了一个16kb的随机数据后进行反汇编,得到的反汇编部分代码如下: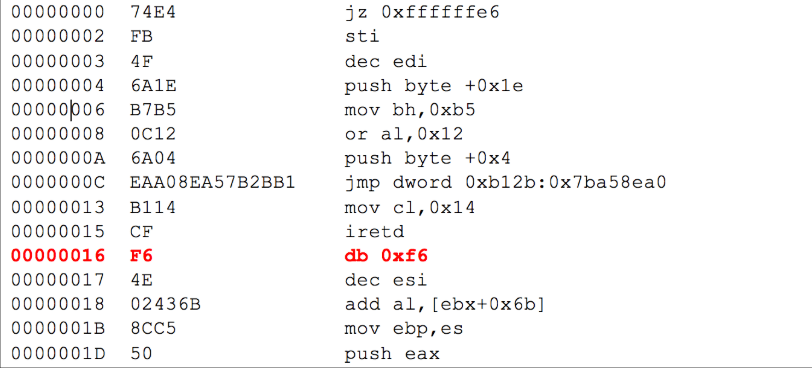
如图所示,随机数据反汇编得到的指令中,大部分是有效指令,只有db 0xf6 这一条被视作了无效指令,因为db指令表示字节变量的定义,但由于它与后面的0x4E(dec esi)组合并没有形成有效的操作数,所以这里的db 0xf6属于无效指令。
接着,fireeye使用了一段英文文本进行反汇编,得到的指令如下: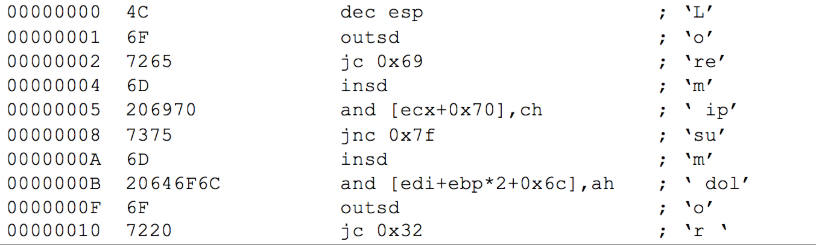
这里可以看到,本来的三个单词 lorem ipsun dolor 已经被反汇编成了10条指令,这次的指令看起来没有像db这样的无效指令了,但其实还是有很多问题。
我们都知道,x86处理器有级别限制,用户态在R3,内核态在R0,如果在用户态使用了内核态的指令,那么程序就会抛出异常,再来回过头看上面的这些指令:
标红的这些指令都是内核指令,不应该在用户态被调用,所以其实这些也是无效指令。
所以辨别花指令的第一个方法是:在没有内核操作的时候使用了内核指令,那么这些反汇编代码应该是花指令。
- 特权指令
常见的R0级别指令如下:(虚拟机检测也经常会使用内核指令来检测,因为在真实的环境中,在R3层调用内核指令程序会抛出异常,而在虚拟机中调用R0指令不会)
IN(INS,INSB,INSW,INSD)
OUT(OUTS,OUTSB,OUTSW,OUTSD)
IRET
IRETD
ARPL
ICEBP/INT 1
CLI
STI
HTL
- 不常见指令
在R3下也有一些合法但不常见的指令,这些指令又分为三类:
(1) 过于便捷的指令
ENTER
LEAVE
LOOP(LOOPE/LOOPZ、LOOPNE/LOOPNZ)
PUSHA
POPA
在上面的指令中,ENTER和LEAVE指令经常用来表示函数的开始和结束,但是这一组命令并不实用,不能喝PUSH、MOVE、SUB这些指令一起完成,所以大多数情况下,编译器都不会选择使用ENTER和LEAVE,绝大部分程序员也不会使用,所以这一组命令经常被用作花指令。
LOOP(LOOPZ、LOOPNZ)也是编译器通常不会使用的语句,遇到循环,编译器一般情况下会创建自己的循环,然后使用JMP以及其他跳转指令。
我们都知道,PUSH和POP是常见的栈操作指令,出了PUSH和POP,还有PUSHA和POPA这一组指令可以进行栈操作,但是由于这两个指令可以存储或回复堆栈指针本身,所以这一组指令非常复杂,编译器通常情况下不会选择在函数一开始存储堆栈指针,并在函数结尾的地方恢复,所以编译器通常情况下不会产生这一组指令,这一组指令也属于常见的花指令。
(2) 不常见指令
浮点指令
F*
WAIT/FWAIT
浮点指令通常以字母”F”开始,通常情况下,大部分程序都不会使用浮点指令,由于浮点指令在操作码范围中有较大的比列,所以浮点指令也是特别常见的花指令。
举一个🌰:如果是涉及作图的3D程序,那么存在大量浮点指令应该就是正常的,如果是一个正常的程序,出现了大量浮点指令,那么这些浮点指令通常情况就是花指令。
还有一点需要说明,就是恶意代码分析中,shellcode经常会使用浮点指令用于获取指向自身的指针。
SAHF
LAHF
SAHF的作用是将寄存器AH的值传送到标志寄存器PSW,LAHF相反,将PSW的值保存到AH。这一组指令只能通过编程时明确的语句来实现,所以不会由高级语言翻译而来,所以编译器通常情况不会产生这组指令,并且这组指令也是单操作码范围内的单字节指令,所以常被用作花指令。
ASCII调节指令
AAA
AAS
AAM
AAD
这一系列的AA指令,作用是在汇编语言中以十进制的形式来处理数据,这些指令早期比较流行,现在已经几乎不使用了,所以理论上不应该出现。
SBB
SBB指令功能和SUB相似,但是SBB指令有9个以上的操作码,占比3.5%,所以虽然SBB不是单字节指令,单由于它有多种形式和众多操作码,SBB也常被作为花指令使用。
XLAT
XLAT是汇编语言查表命令,由于该指令不能直接翻译成某个特定的高级语言的结构,所以编译器也通常不会使用该指令,XLAT属于单字节指令,所以相对来讲,XLAT作为花指令的情况比人工使用的情况要大。
CLC
STC
CLD
STD
这些指令可以清除或设置进位标志以及目的标志,这些指令可能会在流操作附近出现,可以在REP前缀的地方看到它们,同样,由于单字节指令的特性,也经常被用作花指令。
(3) 远指针指令
LDS
LSS
LES
LFS
LGS
ummm,这个不是很懂,单记住就行了。
- 频繁出现的指令前缀
x86的指令可以带有前缀。指令前缀的作用是修改后面指令的行为,最常见的一种就是改变操作数的大小。
比如我们在32位下想要使用16位寄存器或操作数,可以通过前缀标识,告诉CPU这是一个16位指令,应该使用16位寄存器或操作数。
指令前缀有很多,其中大部分都属于ascii范围内,所以就想最开始fireeye举的例子一样,如果反汇编一个英文文档,就会出现特别多的指令前缀。
所以如果在对32位的代码进行反汇编,但是发现使用了大量的16位寄存器(AX BX CX DX Sp BP)而不是32位寄存器(EAX EBX ECX EDX ESP EBP),这种情况下可能就是花指令。
反汇编器会在指令助记符前面添加特定的符号来标识其他前缀,如果在反汇编代码中看到如下的关键字,可能就是花指令:
LOCK
BOUND
WAIT
段选择器:
FS
GS
SS
ES
在16位模式下,会使用段寄存器(CS、DS FS GS SS ES)进行寻址的存储。
程序的代码通常是通过 CS “代码段” 来实现引用的,而程序处理的数据是DS”数据段” 寄存器引用的。ES FS GS是额外的数据段寄存器,用于32位代码。
段选择器的前缀字节可以添加在指令之前,从而强制其基于特定的段来引用内存,而不是基于其默认的段。
由于上面的这些指令都是单字节操作码,所以也常用作花指令。
相比普通的代码来说,花指令会频繁的使用这些段寄存器,并且编译器并不会产生输出,比如:
pop ss
根据指令来讲,这个命令会从堆栈中弹出SS”堆栈段”寄存器,是一个有效的命令,但是由于这是32位的程序,SS并不会像16位那样进行改变。

若有收获,就点个赞吧
0 人点赞
