在深度学习中,使用GPU会大大加快训练速度,因此配置GPU计算环境十分重要。目前大多文档描述的都是针对linux系统而言的GPU配置步骤,本文分享了在windows10如何一步步配置,将你的显卡用于加速深度学习计算。
我的台式机GPU深度学习配置概述:
- 系统:Windows10
- GPU:NVIDIA GeForce RTX 2060
- Anaconda3
- Python 3.6
- cudatoolkit 9.0
- cudnn 7.1.4
- tensorflow-gpu 1.12.0
查看NVIDIA GPU型号 (硬件支持)
本文配置步骤仅仅适用于拥有NVIDIA GPU的电脑,对于有NVIDIA GPU的Windows10系统,可以在CMD中输入nvidia-smi·,可以获得GPU的型号,使用情况等信息,本机型号为NVIDIA GeForce RTX 2060。
之后需要到NVIDIA官网上(https://developer.nvidia.com/cuda-gpus)查看该GPU型号是否支持CUDA加速计算。如下图所示,本机GPU型号在支持列表中。
使用Anaconda创建Python虚拟环境
使用Anaconda进行python包和版本的管理十分方便,官网地址(https://www.anaconda.com/),可以到清华大学开源软件镜像站(https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/)下载Anaconda3安装包,下载速度更快。
安装成功后,打开Anaconda Prompt,使用conda-V,查看conda是否安装成功以及版本号。
创建Python虚拟环境,版本号选择3.6,命令为conda create -n gpu python=3.6。
激活Python虚拟环境,命令为activate gpu,再使用命令python --version,可以查看python的版本号是否是我们需要的。之后我们将在该虚拟环境中配置使用tensorflow-gpu所需要的一些依赖package。
在新建的Python虚拟环境中,我们可以使用pip install或conda install命令安装需要使用的package。一个加速安装速度的tip是使用国内镜像安装。在windows中的配置如下:
- 更改pip源
在C:\Users\用户名 位置上创建名为pip的文件夹,然后在文件夹下创建pip.ini
将以后内容复制进去保存即可
[global]index-url = http://mirrors.aliyun.com/pypi/simple/[install]trusted-host = mirrors.aliyun.com
若仅在一次pip安装中使用另一个源,可以使用如下命令-i https://pypi.tuna.tsinghua.edu.cn/simple或-i http://mirrors.aliyun.com/pypi/simple/
- 更改conda源
在CMD中输入如下命令:
conda config --add channels http://mirrors.aliyun.com/pypi/simple/conda config --set show_channel_urls yes
查看现在的conda源:
conda config --get channels
conda换回默认源
conda config --remove-key channels
安装tensorflow GPU支持所需要的软件(CUDA & cuDNN)
该步骤中常出现的问题是安装的tensorflow,CUDA以及cuDNN三者的版本号不匹配,在该种情形下,python是检测不到GPU设备的,进而也无法运用GPU加速深度计算。因此需要先前往tensorflow的官网查询匹配的版本号。前往https://tensorflow.google.cn/install/source_windows,如下图所示,版本号的严格对应十分重要,否则无法使用GPU加速计算。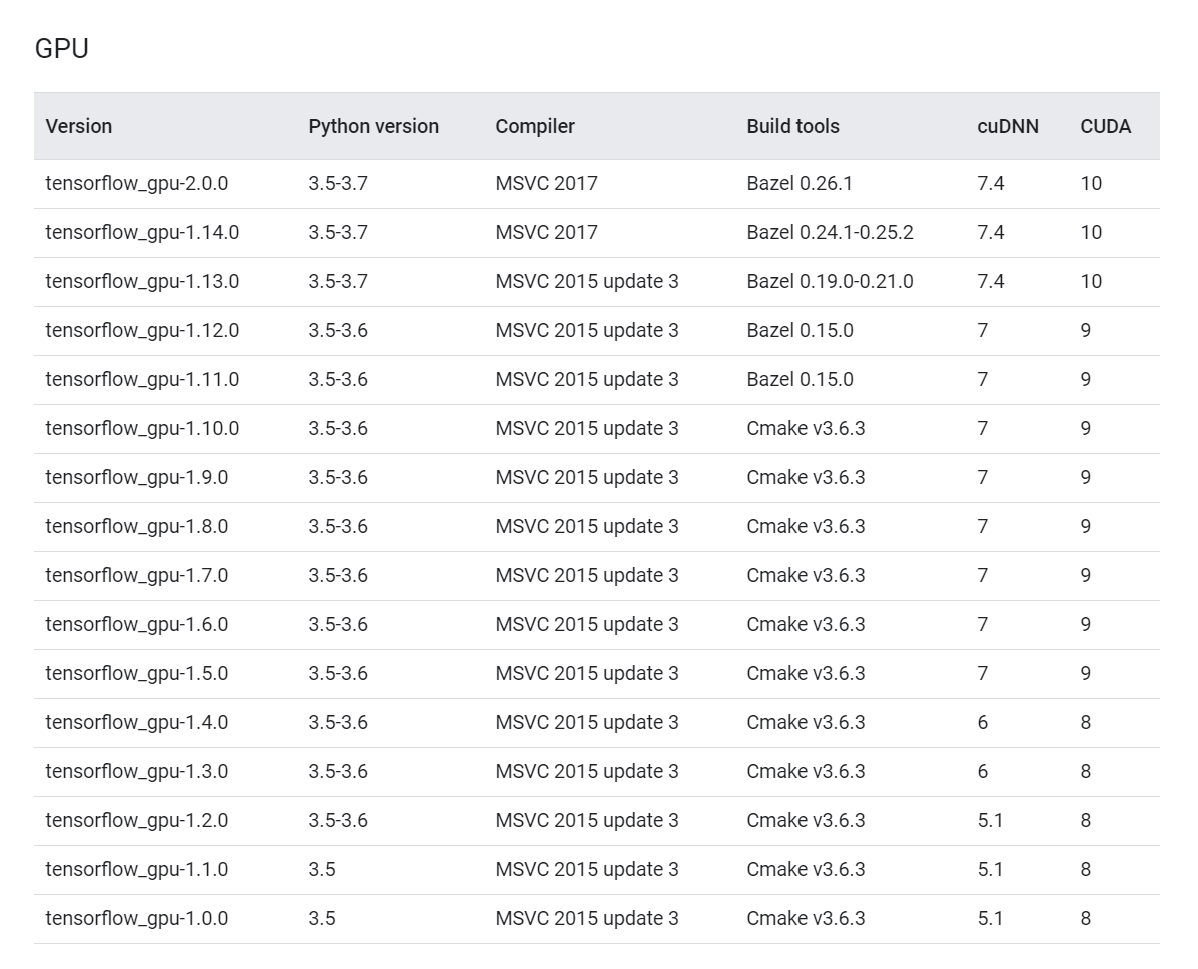
在本流程中,我们安装的是1.12版本的tensorflow-gpu,在CMD中输入conda install tensorflow-gpu==1.12,此时会自动安装与1.12tensorflow-gpu相应的7.6.4版本cudnn。

此时使用conda list,惊奇地发现cudatoolkit 9.0和cudnn 7.6.4都一并安装在本环境中。接下来我们来测试是否可以检测到GPU。
有一个易于忽略的小细节,当我使用jupyter-notebook打开jupyter notebook时,发现连import tensorflow as tf命令都会报错,百思不得其解,因为conda list显示已经成功安装了。最终发现新的python虚拟环境kernel没有添加到jupyter notebook/jupyter lab之中,此时jupyter lab调用的是默认环境base的内核。解决该问题的对策如下:首先需要确保该环境下已经安装了ipykernel,使用命令pip install ipykernel,之后使用ipykernel将当前激活环境添加到jupyter之中,python -m ipykernel install --name new_env, —name之后指定的是该环境在jupyter中显示的名称,通常我会将其设为和conda的虚拟环境名称保持一致,方便一一对应。之后打开jupyter lab新建一个文件时便可以选择该kernel作为运行代码的环境。使用jupyter kernelspec list可以查看当前所有添加到jupyter之中的环境,使用jupyter kernelspec remove kernelname可以删除已添加的kernel.
若安装完tensorflow-gpu后并没有自动安装对应版本的cuda和cudnn,可以使用conda命令手动安装。例如,安装与tensorflow-gpu1.12相对应版本的CUDA9。使用命令行conda search cudatoolkit查找能检测到哪些版本的cudatoolkit,可以得到如下图结果。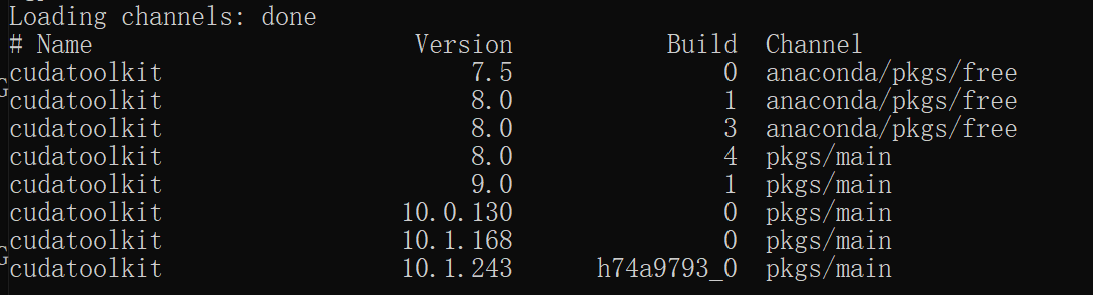
9.0版本与安装的tensorflow版本相符,使用conda install cudatoolkit==9.0进行安装。
检测tensorflow能否检测到GPU设备
在jupyter notebook中输入:
import tensorflow as tfprint(tf.test.is_gpu_available())
若返回值为TRUE,说明可以检测到GPU设备,之后就可以用GPU加速深度学习计算。
from tensorflow.python.client import device_libprint(device_lib.list_local_devices())
还可以获取能检测到的机器上CPU和GPU的详细信息,在使用的台式机中,得到的返回结果为:
[name: "/device:CPU:0"device_type: "CPU"memory_limit: 268435456locality {}incarnation: 3610006549183647212, name: "/device:GPU:0"device_type: "GPU"memory_limit: 4849074176locality {bus_id: 1links {}}incarnation: 9616442880454089906physical_device_desc: "device: 0, name: GeForce RTX 2060, pci bus id: 0000:09:00.0, compute capability: 7.5"]

若有收获,就点个赞吧
0 人点赞
