1 雪花算法生成ID
2 TS报错-1
在编写对象Copy方法时报了一个关于Object类型的错误,具体如下:
Don't use `object` as a type. The `object` type is currently hard to use ([see this issue](https://github.com/microsoft/TypeScript/issues/21732)).Consider using `Record<string, unknown>` instead, as it allows you to more easily inspect and use the keys @typescript-eslint/ban-types
而报错的代码如下:
public static copy (obj:Object) {if (Tool.isNotEmpty(obj)) {return JSON.parse(JSON.stringify(obj));}}
从报错的内容我们可以粗略的得知这里有问题的是参数类型传入了Object,报错内容提供了一个github地址,我们跟进去看看。
通过issue的内容可以大概得知由于我们传入的是一个键值对的数据,那么如果使用Object去标注参数,类型推断也无法准确识别出这里面的键。
因而后面也有讲我们可以使用Record
那么落实到代码层面即是:
public static copy (obj: Record<string, any>) {if (Tool.isNotEmpty(obj)) {return JSON.parse(JSON.stringify(obj));}}
3 生成持久层之后启动项目报依赖错误
使用mvn运行代码生成器之后重新启动项目总是会包mybatis的相关依赖错误。
直接在pom.xml文件上reload一下项目依赖即可解决。
4 springboot集成redis写入键值乱码问题
springboot集成redis之后,可以使用RedisTemplate来操作对redis的读写,而在写入String数据时出现一个情况:在项目中存入数据之后,在服务提供商控制台登录redis查看时键值为乱码。
为了探测项目操作是不是真的把数据插入redis里面,我试着在项目中利用RedisTemplate查询了键对应数据,结果发现是可以正常查询到的,也就是说数据是正常写入redis了,但是在客户端上不能正确显示。
这时回想起项目中的数据时序列化之后再写入redis的,猜测跟序列化有关系,因此查阅了相关的资料,最终发现原因。
项目中使用的RedisTemplate对HashValue和Value的序列化采用的是JDK默认的序列化策略,而不是String类型的序列化策略,所以在项目中存入String类型的数据之后,在客户端中看到的value会因为序列化策略的问题出现乱码。
既然是序列化机制问题,那么就有两种解决方法:
①直接重新配置RedisTemplate的序列化策略,让他使用String的序列化策略,当然一般情况下不推荐这样修改;
②springboot集成redis的包中还有一个StringRedisTemplate类,它继承于RedisTemplate,这两者的数据是不共通的,也就是说StringRedisTemplate只能管理StringRedisTemplate里面的数据,RedisTemplate只能管理RedisTemplate中的数据。而这两个最重要的区别就是StringRedisTemplate默认使用的是String的序列化策略,最后选用它来解决客户端乱码问题。
5 前后端分离登录token不同步问题
在项目部署到服务器运行之后测试登录时,发现偶发地后端存入redis的token与前端拿到的token不一致【且token值差不大】,在查看代码之后尝试对存redis以及生成响应结果的操作做对调之后问 题仍未解决,排除这种可能性;
项目中token使用的是Long存储,因此怀疑是Token与string之间的转换问题,故将token修改为string, token不同步的情况得到解决;但这还没完,后续添加电子书时【电子书id为Long】发现仍然会出现前后端数值不一致的问题,结合每次的差值不大,怀疑是Long精度问题,后面查阅了资料,发现Java中的Long精度与JS中的Long精度不一致,因此在后端往前端传Long数据时会出现精度丢失问题,因此token才会不一致;
明确了问题之后就应该考虑解决方案了,最直观的方法就是将Long数据修改为String,但这种修改牵一发而动全身,实在麻烦;后面在搜索引擎search一番发现可以使用jackson的@JsonSerialize注解搭配ToStringSerializer使用可以让系统在序列化时保留相关精度,这种方法需要在各个对象的属性上标注@;
@JsonSerialize(using = ToStringSerializer.class)private Long token;
也可以使用这种方法全局设置:
public void configureMessageConverters(List<HttpMessageConverter<?>> converters) {MappingJackson2HttpMessageConverter jackson2HttpMessageConverter = new MappingJackson2HttpMessageConverter();ObjectMapper objectMapper = new ObjectMapper();SimpleModule simpleModule = new SimpleModule();simpleModule.addSerializer(Long.class, ToStringSerializer.instance);simpleModule.addSerializer(Long.TYPE, ToStringSerializer.instance);objectMapper.registerModule(simpleModule);jackson2HttpMessageConverter.setObjectMapper(objectMapper);converters.add(jackson2HttpMessageConverter);}
6 dubbo服务调用异常捕获问题
1)背景:
项目中的登录校验服务分为服务模块和 API 模块,一旦用户调用对应的登录 API 之后,会通过Dubbo远程调用到校验服务,之后返回对应的结果到 API 模块。在服务模块中为了方便对业务异常进行处理,使用了自定义的登录异常,这一块逻辑封装在枚举类中,作为外部包导入。
public enum BusinessExceptionCode {// 在这里声明业务异常PHONE_NUMBER_EXIST("手机号已存在"),STUDENT_NOT_EXIST("学员不存在"),LOGIN_FAIL("登录失败,用户名或密码错误"),BE_BAN_FAIL("该账号处于封禁状态,请联系管理员");private final String desc;BusinessExceptionCode(String desc) {this.desc = desc;}public String getDesc() {return desc;}}
这里还要提一下全局异常处理的类,这里主要是将业务异常进行特殊处理,以便前端展示:
@ControllerAdvicepublic class ControllerExceptionHandler {private static final Logger LOG = LoggerFactory.getLogger(ControllerExceptionHandler.class);/*** 业务异常处理** @param e : 异常信息* @return : cn.gpnusz.ucloudteachentity.common.CommonResp<java.lang.Object>* @author h0ss*/@ExceptionHandler(value = BusinessException.class)@ResponseBodypublic CommonResp<Object> businessExceptionHandler(BusinessException e) {CommonResp<Object> commonResp = new CommonResp<>();LOG.warn("业务异常:{}", e.getCode().getDesc());commonResp.setSuccess(false);commonResp.setMessage(e.getCode().getDesc());return commonResp;}}
也就是说理想效果是,在登录校验失败之后前端应该是要能收到对应的业务异常的提示的,这在单体项目中是可以实现的。而在服务拆分之后测试中却发现前端并不能收到对应的业务异常提示,也就是根本就没走到自定义异常的处理逻辑。
2)探究与解决
首先查看登录 API 模块的日志,可以发现在日志中抛出的是 RuntimeException ,日志也显示是系统异常,也就是说根本就没封装成业务异常传出来。
接着尝试在服务模块中对应业务代码块中加断点调试,最终发现确实是抛出了自定义的业务异常信息。
最终回到 API 模块中查看日志信息,可以发现这里抛出的异常信息实际上是经过dubbo的filter之后的结果: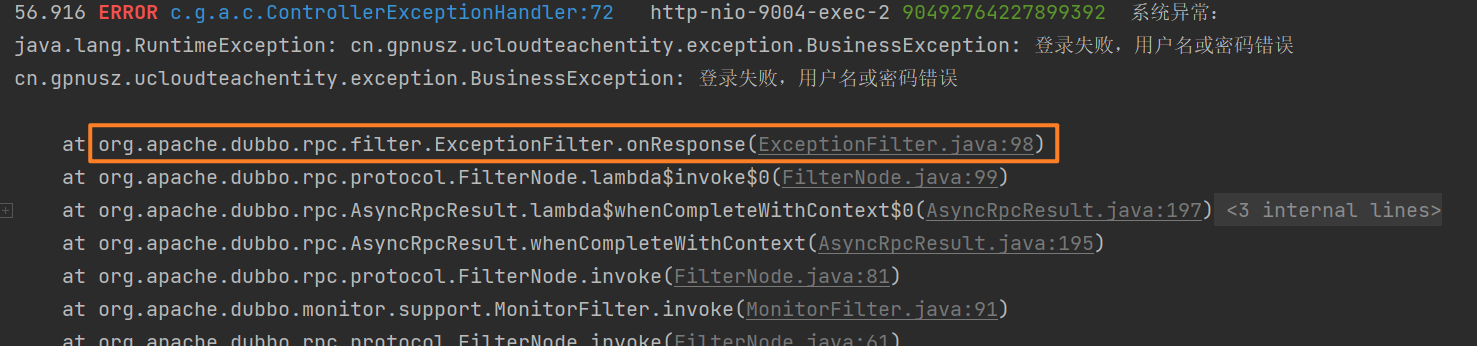
跟进去这个异常类的 onResponse 方法看看:
重点关注第98行代码,可以看到这里重新new了一个 RuntimeException 去包装捕获到的异常信息,这也就可以解释为什么在日志中输出的是运行时异常了。
那么dubbo为什么要将异常封装呢?先看看这个类的注解信息:
/*** Wrap the exception not introduced in API package into RuntimeException.* Framework will serialize the outer exception but stringnize its cause* in order to avoid of possible serialization problem on client side*/
大意就是:dubbo会将API包中没有引入的异常包装到RuntimeException中,框架将序列化外部异常,但对其原因进行字符串化,以避免客户端可能出现的序列化问题。
明确了这一点之后就要考虑如何解决了,先返回去看 onResponse 方法,会发现有这么两段代码:

也就是说 ① 如果异常类和接口类在同一个 jar 包中,那么不会走封装的逻辑,会直接返回;② 如果异常类是以java. 或者 javax. 开头的那么也会直接抛出。解决方案可以针对这两点处理,第二点对于异常类的要求有点苛刻了,我们考虑从第一个点入手。
将异常类复制一份存到公共接口模块中,然后再看看效果。
奇怪了,并没有预期的显示业务异常的效果,而是抛出了一个新的异常信息,大意是业务异常类无法实例化,对应的是 Hessian 序列化协议的信息。我们跳到异常类去看看: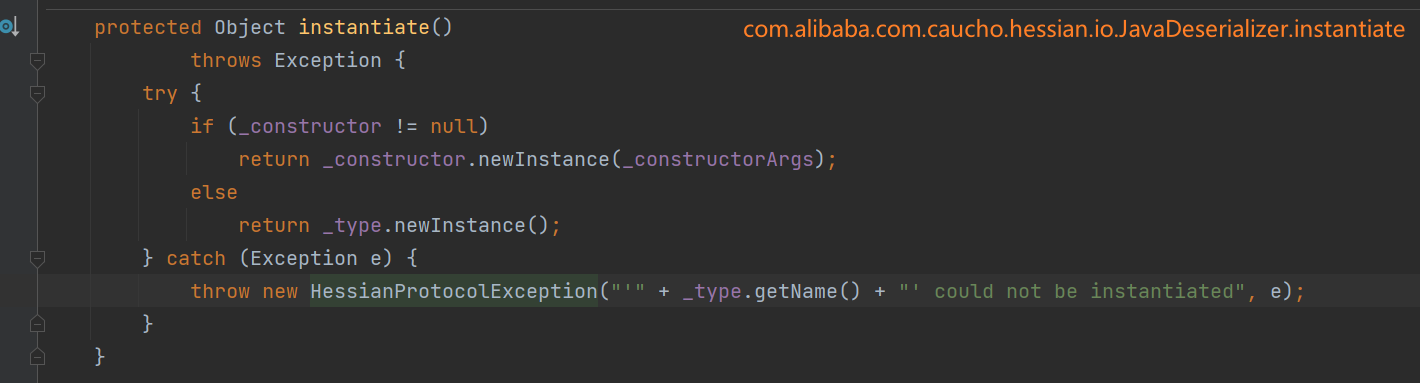
可以看到这里应该是实例化抛异常了,我们再跟进去 newInstance 方法中看看: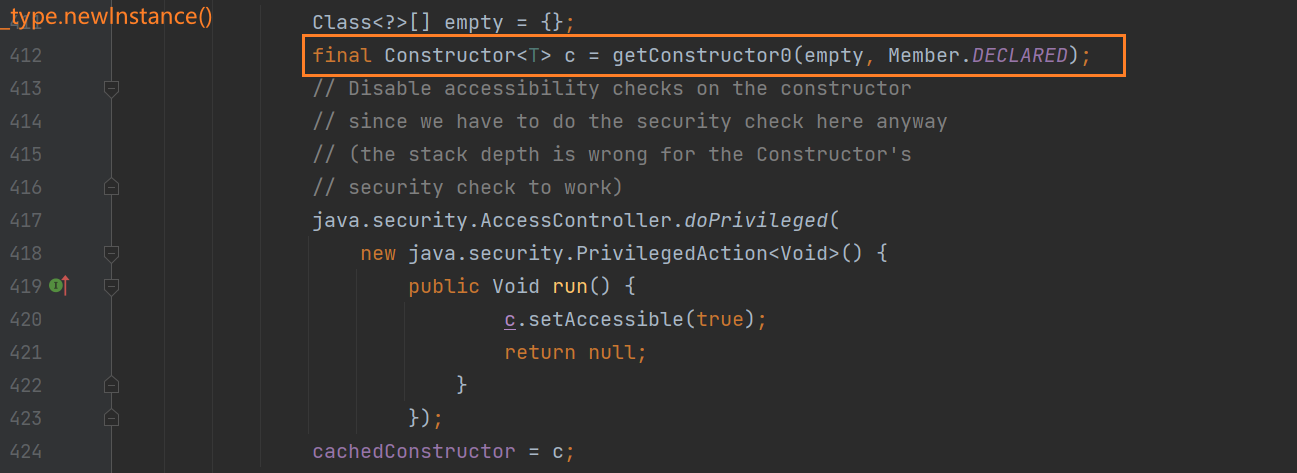
可以看到这里开始获取构造器,并且传入的参数为空,我们跟进去 getConstructor0 这个方法看看: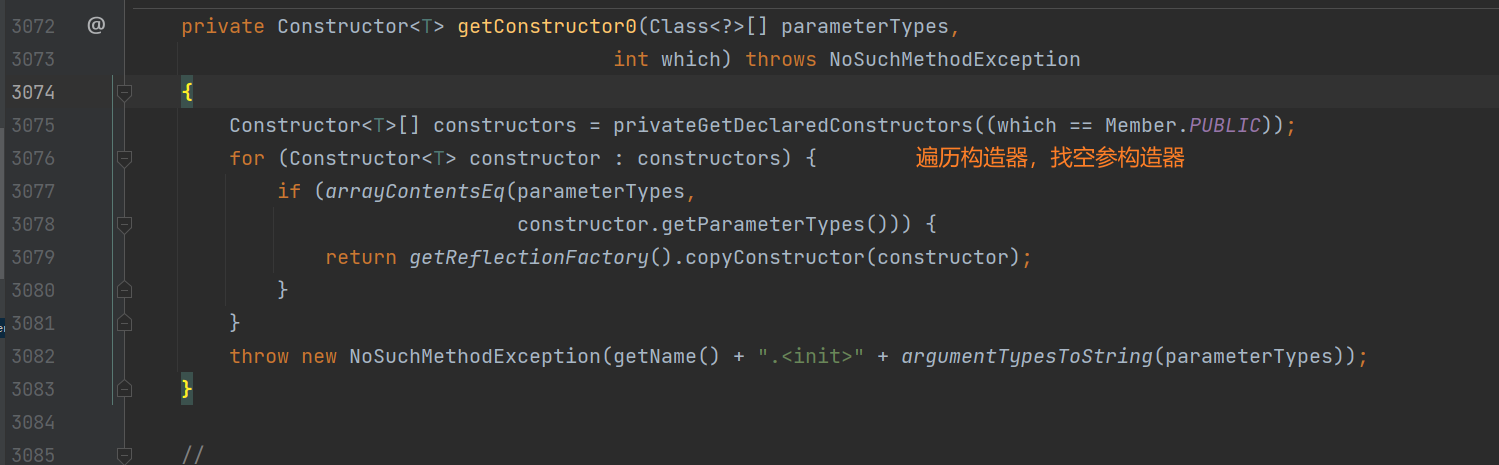
到这里基本明朗了,这里应该是遍历时没有找到无参构造器,导致实例化失败。我们回过头去看看异常定义类,确实定义少了空参的构造器: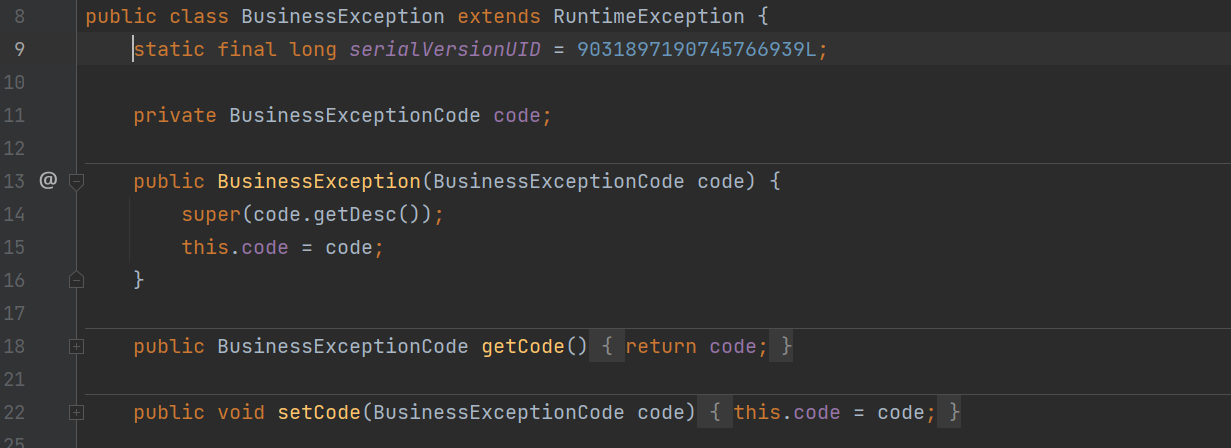
补上之后我们再运行看看结果,可以看到已经正常可以处理业务异常了:
3)总结
实际上对于dubbo的异常处理还有多种解决方案,在上面第二点中只写了其中一种,也是我认为的开发人员可以通过日志、源码信息找到的一种解决方案,尽管这样做需要定义额外的自定义异常类。
这里再介绍几种解决方案:
① 重写dubbo的异常过滤类,加上一个判断:对于以自定义异常类包名开头的异常都不进行拦截,而是直接抛出。这种解决方案的好处是无需定义冗余的自定义异常类,直接从源码级别上进行增补;
② 在dubbo配置文件中直接忽略掉对于异常的过滤,对应的yml配置如下: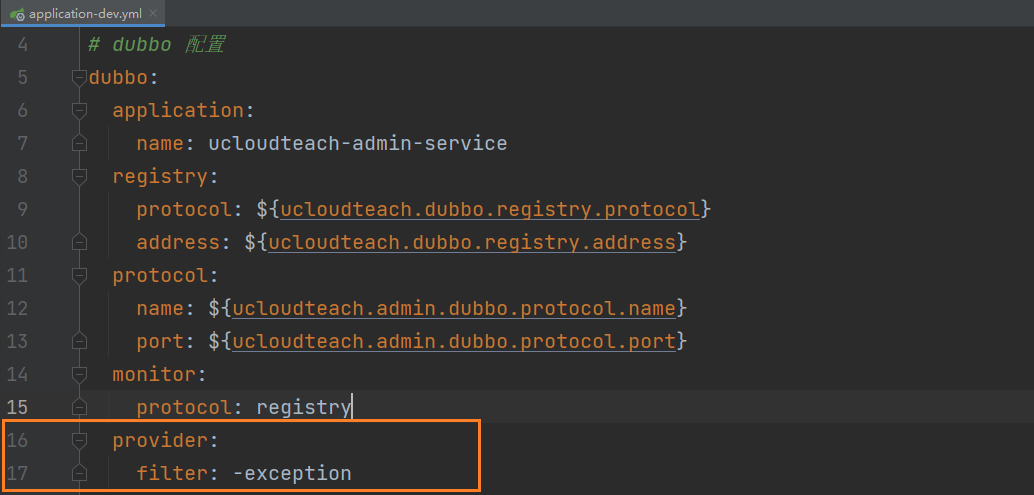
这种方案实际上并不是一个很好的选择,因为这相当于对异常过滤一棍打死,可能会隐含着异常类序列化的问题,建议慎用。

若有收获,就点个赞吧
0 人点赞
