1)概念
Redis具有高可靠性,除了需要有持久化策略来保证之外,还需要保证服务不中断,如果我们只是单实例Redis显然是无法保证不中断的,这时就需要引入主从的概念。
简单来说就是将Redis部署成两种形式,主可以读写,从可以读【读写分离】,当然这种分布情况是基于一种理论依据:数据库的运行过程中总是读多写少。这样读取的操作就被分散到多台机器上了。
同时写操作只可以在主服务上进行,这是为了确保数据的一致性,否则会出现多台机器多个结果的情况。除了这些问题,还应该考虑主从数据同步的问题,即是对主服务的数据修改之后如何让从服务知道的问题。
2)主从连接
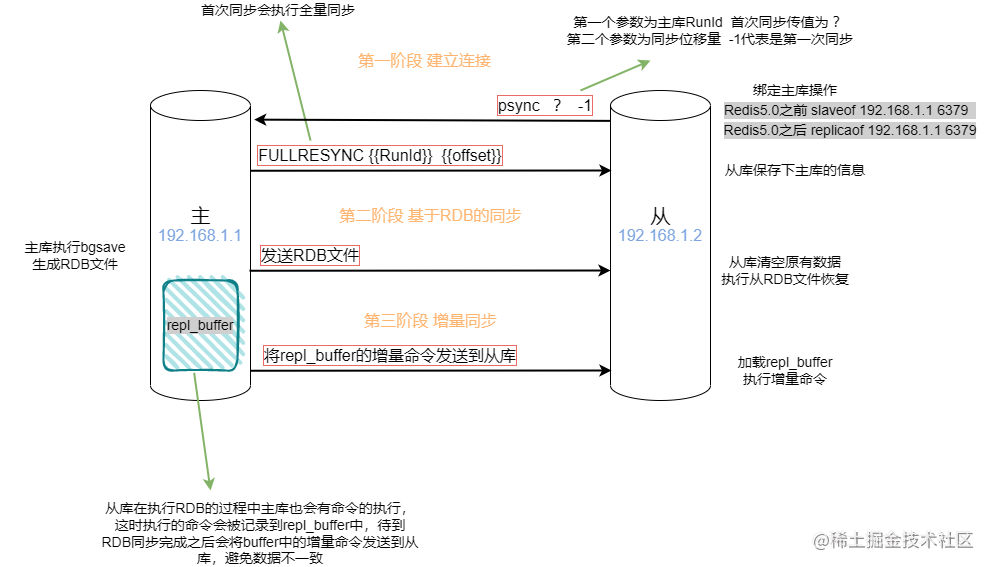
为什么要传输RDB而不是AOF呢?
① AOF存储的是执行过的命令,因此一般较RDB文件会大一些;
② RDB文件存储的是数据库中的kv信息,在恢复的时候会比较快,AOF还需要一条一条执行,效率上会低一些。
3)一主多从的问题
再进一步,如果全部从库都去主库那里请求数据,那么势必会造成主库的压力,压力问题主要出现在RDB的生成与传输上。
首先RDB生成需要fork一个进程去执行,这个fork过程会阻塞主线程,其次RDB文件的传输是需要网络IO的支持的,这也会一定程度上拉低网络IO速率。
4)主从级联模式
解决这两个性能问题,可以使用主从级联模式。
具体来说就是选择一个从库,让他在逻辑上作为其他部分从库的主库,这就可以在一定程度上分散主库的压力。这里需要注意即使是这种情况下,也是只有主库可以写操作。
这个操作讲白了,就是将其中的一台从机作为“主机二号“,其他部分从机就可以从它这里去获取数据,这里主机二号的概念只是相对这些从它获取数据的从机来说,并不是真正意义上的主机,因为它还是只支持读操作。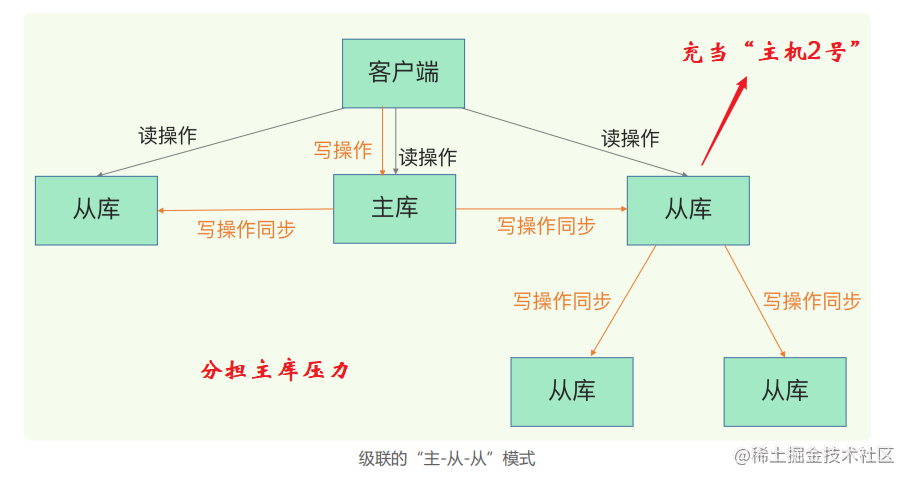
5)主从同步
在主从同步过程中,为了避免频繁的连接断开操作带来的开销,一般使用的是基于长连接的命令传播模式,也就是主库把发生的写操作的命令发送给从库。这个过程中主从都会维护一个offset值,分别记录自己发送/接受到的数据的位移值,也是根据这个值来判断数据是否到达,如果这两个值相同说明主从是一致的。
上面是乐观情况下,也就是主从之间的连接永远不出问题,那我们可以愉快的进行操作,但网络传输是不稳定的,必须考虑网络中断、网络异常等问题造成的数据不一致/不同步。
实际上在进行命令传播的时候从库会默认一秒一次往主库发送心跳检测命令 replconf ack 从库offset,探测主从连接的稳定性,也可以检测命令的执行情况。如果这时发现主从无法连接或者offset值不一致了,就需要进一步处理了。
情况一:
当网络出现异常时,在这段时间内,主从之间是无法同步的,对于主库来说,如果超过一秒没有收到来自从库的心跳检测,就会判定主从连接出现问题,然后会把这段时间的写操作命令都存储在 repl_backlog_buffer 中。如果后续从库上线了,会再发送psync命令带上offset到主库,这时主库会判断offset之后的数据是否存在buffer中,如果存在则进入增量同步模式,也就是将buffer中的命令都发送到从库,进而达成主从一致。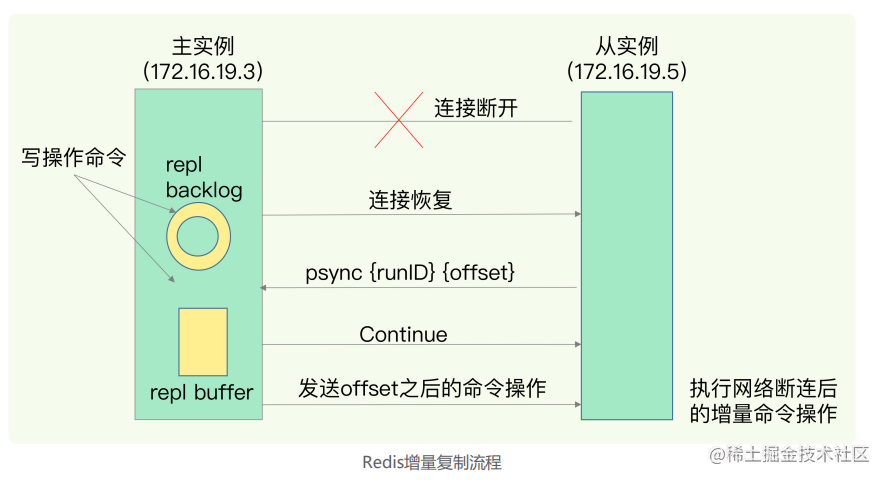
情况二:
当命令在传输中丢失时,从库的offset和主库的offset就会有差值,这时主库会意识到途中发生了命令丢失,进而会进入缺失命令恢复模式,同样是对照从库的offset值在buffer中找到缺失的数据,之后进行传输。
上面两种情况实际上都使用到了repl_backlog_buffer ,需要注意的是这块区域是环形的【固定长度的FIFO的队列】,如果超过固定大小则之后的写命令会将最开始的覆盖掉,这时如果需要恢复缺失命令或者增量同步,则会进行全量同步,效率就拉低了,因此这块区域的大小应该根据传输速率、写执行速率等信息综合考虑,一般计算公式为 缓冲空间大小 = 主库写入命令速度 操作大小 - 主从库间网络传输命令速度 操作大小,repl_backlog_size = 缓冲空间大小 * 2 ;

若有收获,就点个赞吧
0 人点赞
