基础处理
Pandas是什么?为什么用Pandas
pandas = panel + data + analysis
panel = 面板数据——计量经济学 用于存储三维数据
专门用于数据挖掘的python库
读取文件方便,封装了matplotlib和numpy的画图和数据运算
核心数据结构
DataFrame——既有含索引,又有列索引的数据结构
——如何让数据更有意义?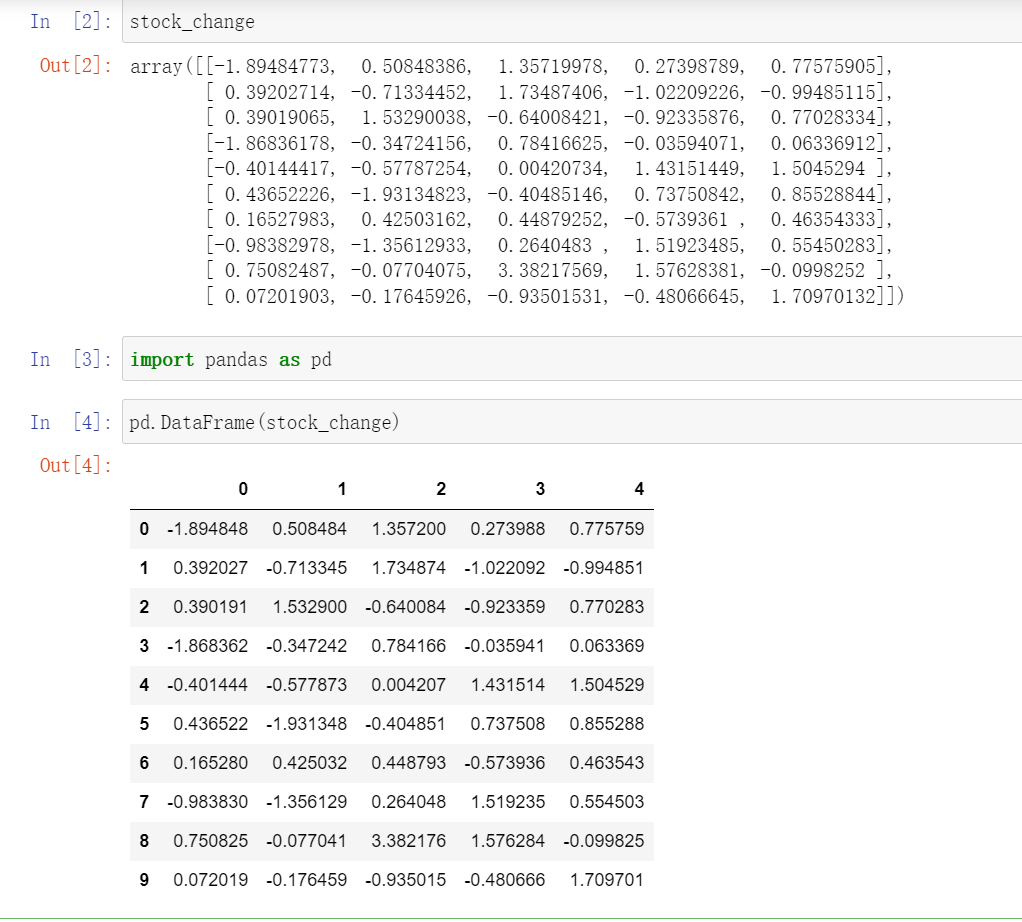
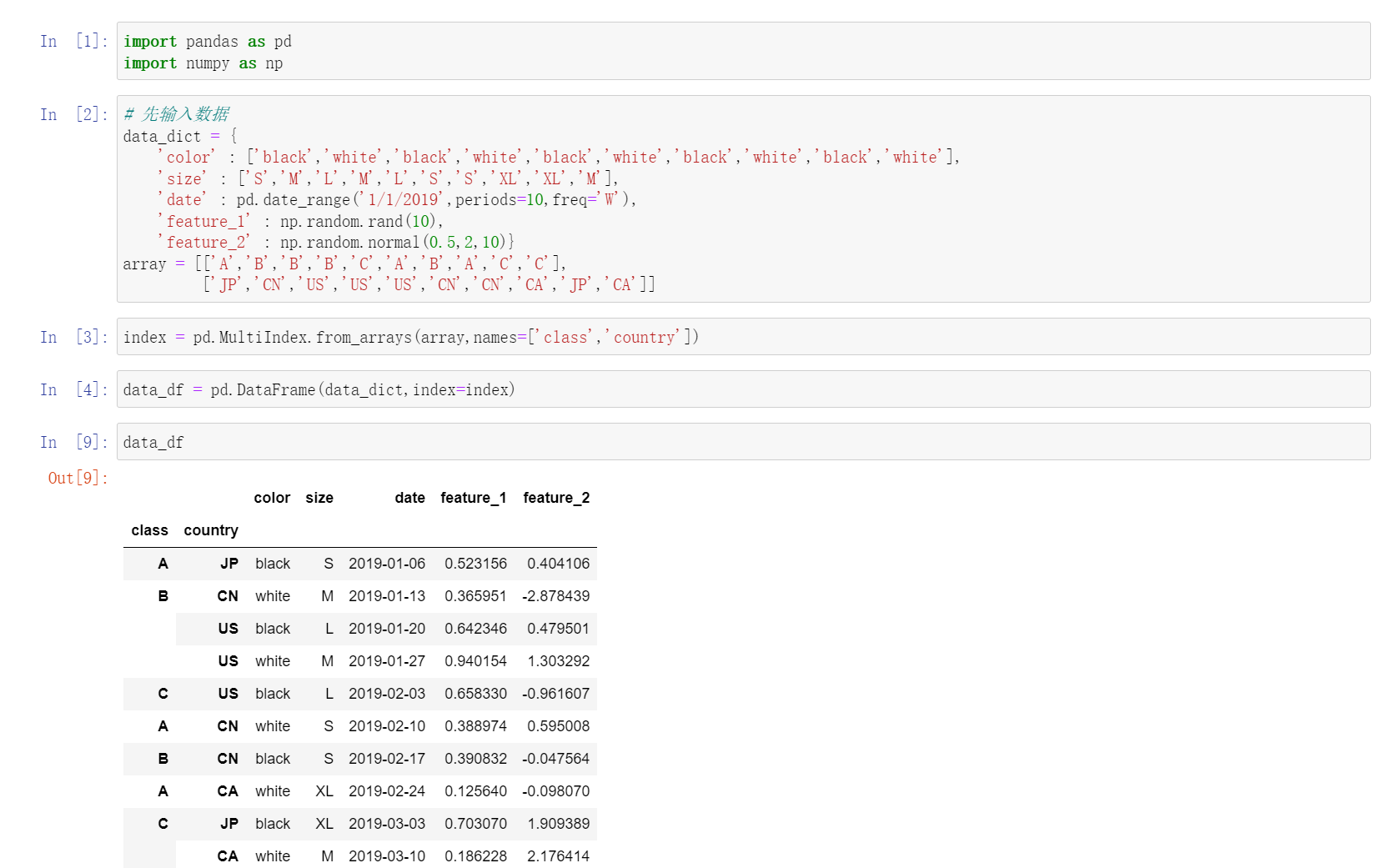
给股票添加行列索引
dataFrame的属性
shape
index
colums
values
T
pandas修改索引只能对全部进行修改,不能单独修改某个的索引值。
基本操作
运算
画图
文件的读取与存储
高级处理
索引
Pandas组合索引
DataFrame的运算

pandas实现逻辑运算
逻辑运算其实相当于是判断运算,判断pandas内置的值是大于还是小于又或者是其他操作于某个值
data.query
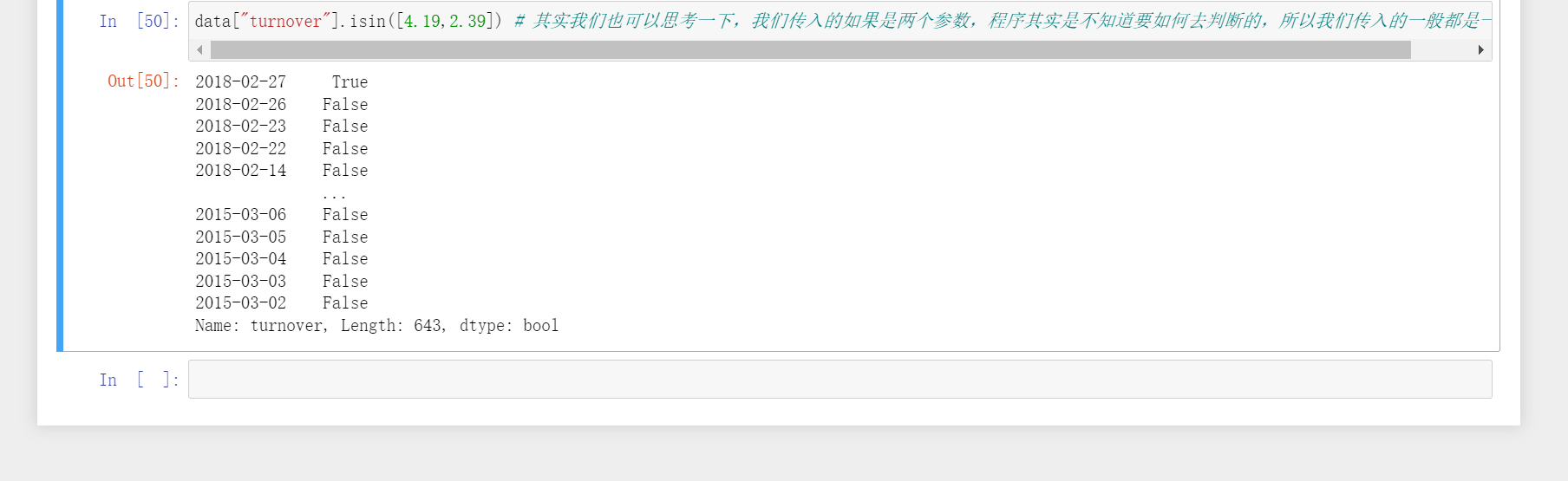
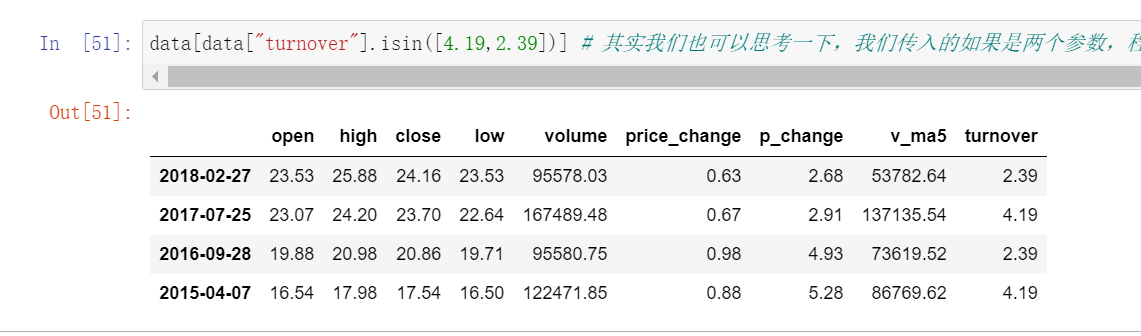
data.isin(values)
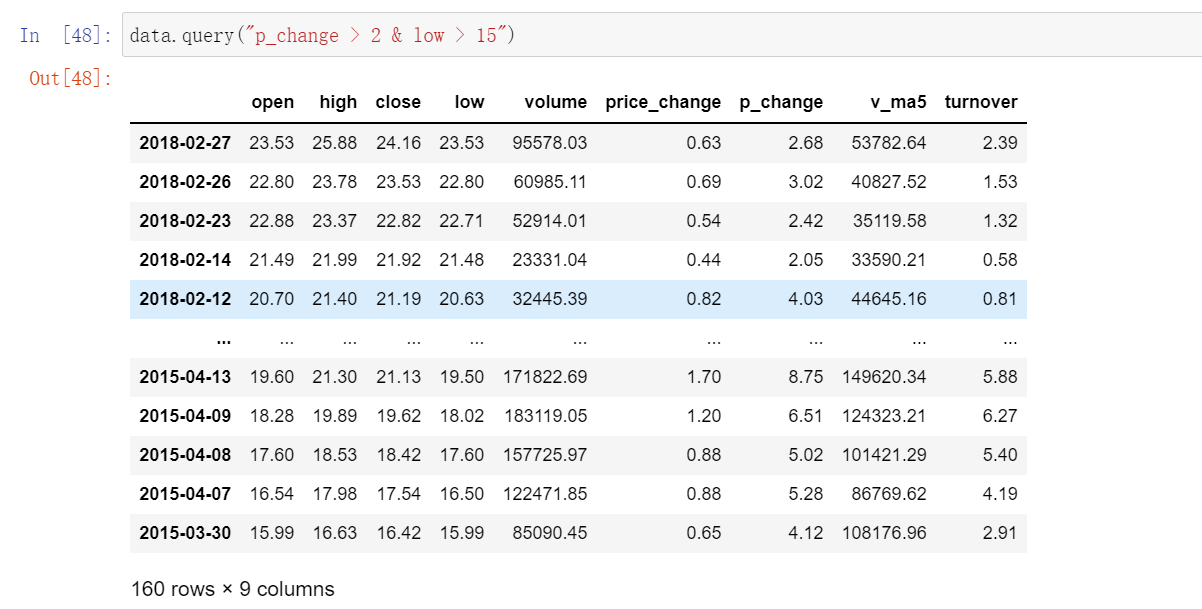
我们可以利用query查询数据
缺失值处理
两种思路:
1,删除缺失值样本
2,替换、插补
如何处理NaN?
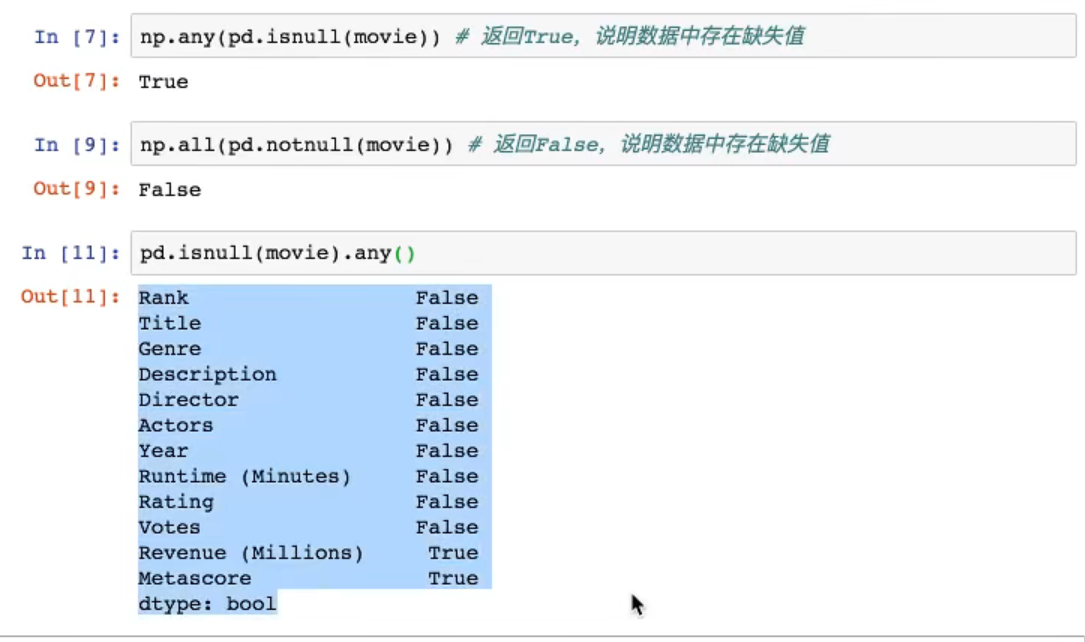
判断是否存在NaN?
pd.isnull/pd.notnull
用的是pd的方法
2) 处理
df.dropna()删除含有缺失值的样本
df.fillna(value,inplace=False)
就地填补
inplace的意思是,要不要创建一个新的df来接住我们修改后的东西
不是缺失值NaN如何处理
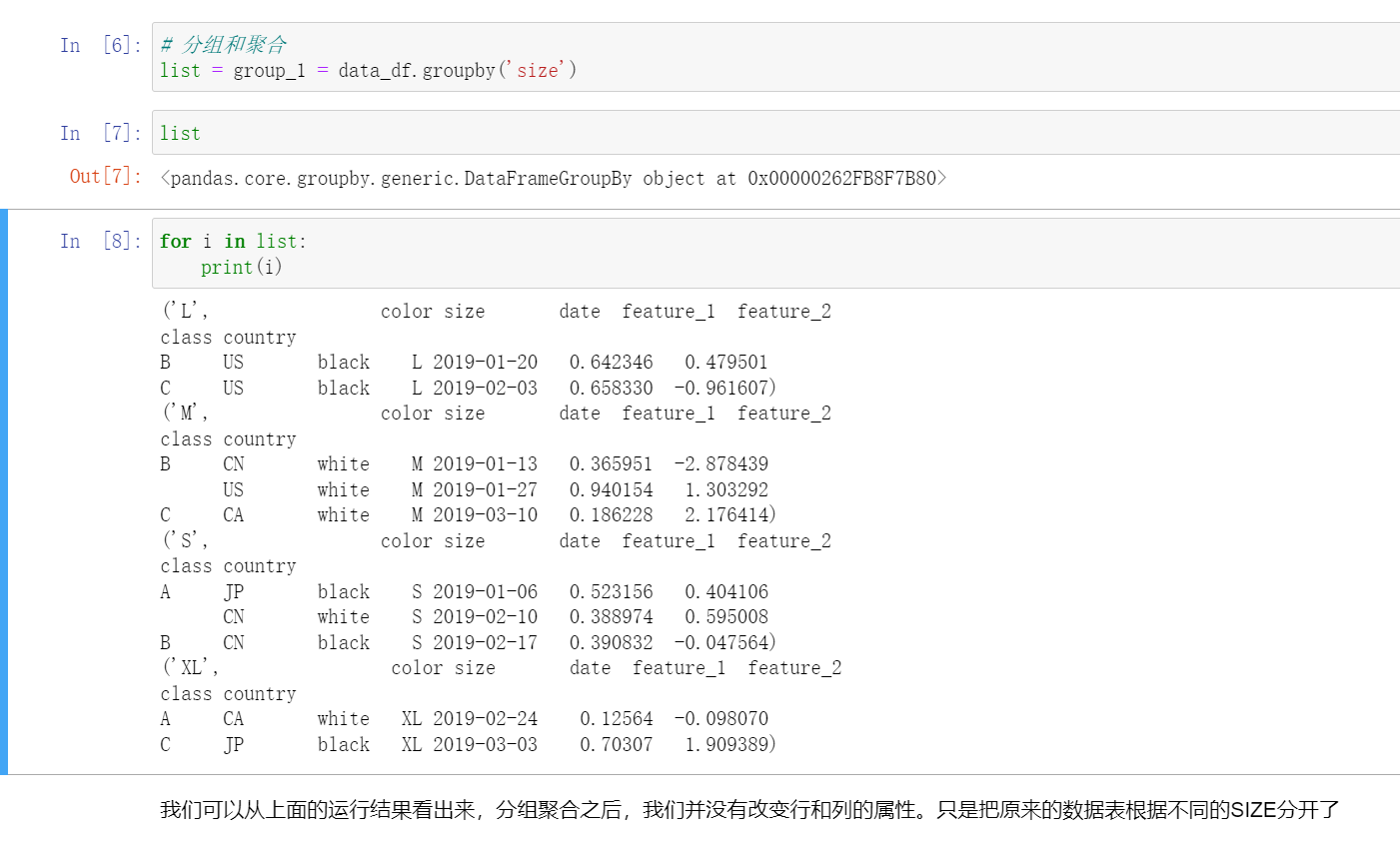
分组和聚合
数据的分组和聚合是关系型数据库中,比较常见的术语。
使用数据库时,我们利用查询操作对各列或各行中的数据进行分组,可以针对其中每一组数据进行不同的操作。
pandas的DataFrame也为我们提供了类似的操作。
我们可以非常方便的对DataFrame进行变换
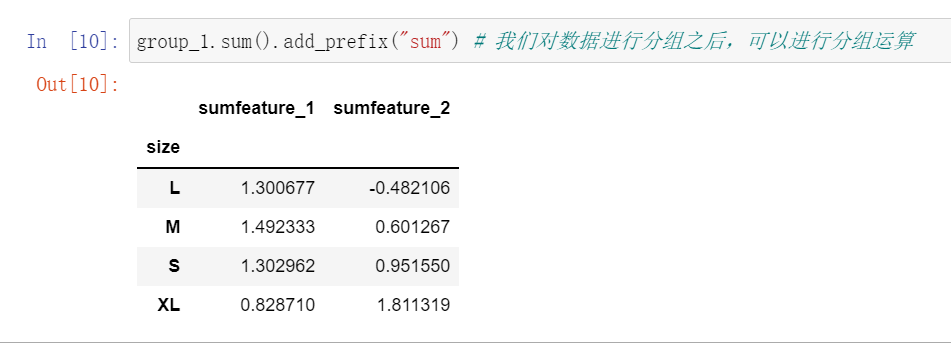
- 分组后的运算

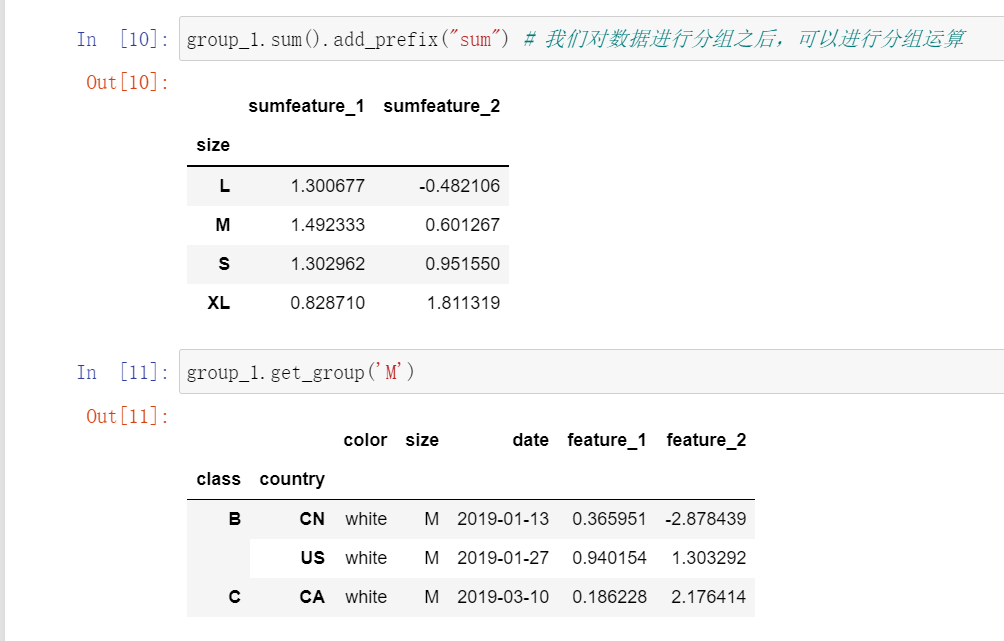
3.利用Pandas进行多重分组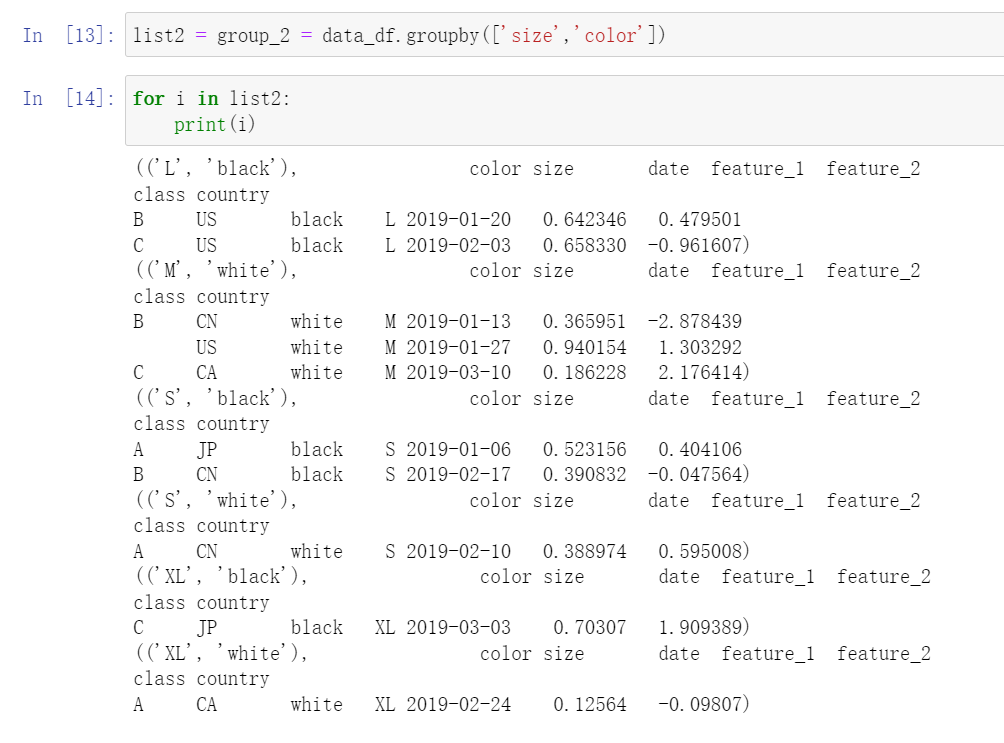
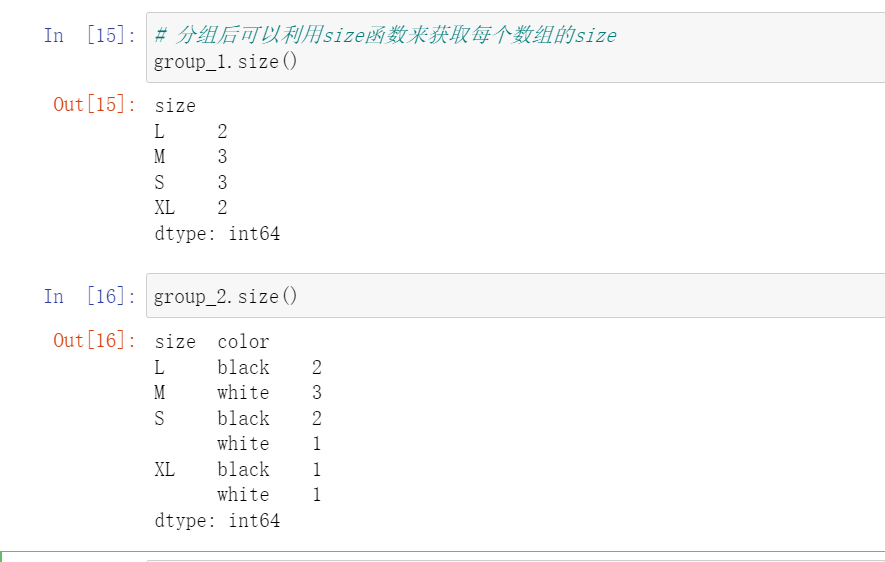
聚合
聚合就是在对数组进行分组之后,再根据需要对数据进行一系列的操作。
比如说,求和、转换等
聚合通常是数据处理的最终目的,分组也是为了更好的服务聚合。
比如说,我们想要知道——在一组数据中,挑出出现频率最高的数据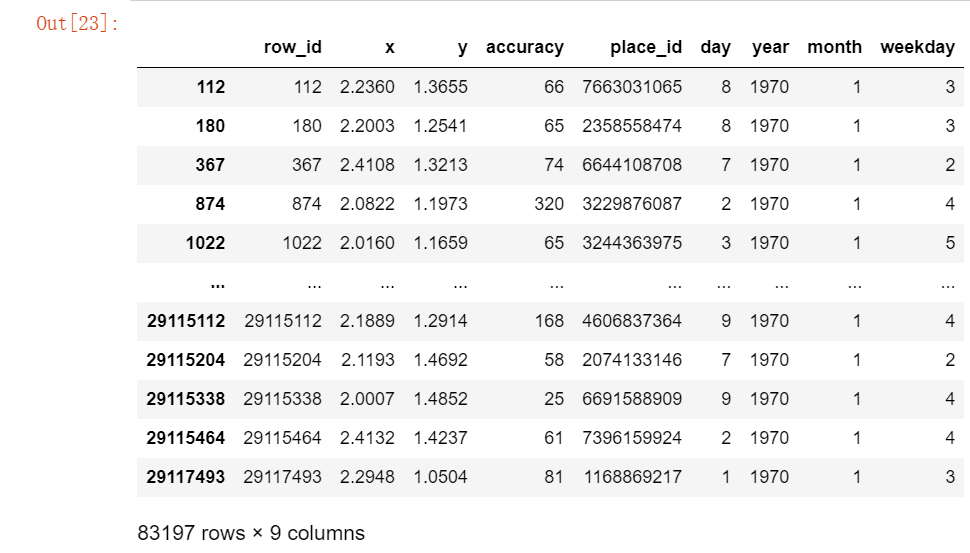
现在我们有这样一组数据,我们想要统计place_id出现的频率,我们可以采用 分组和聚合 的方法
data_narrow.groupby('place_id') # 对DataFrame进行分组place_id = data_narrow.groupby('place_id').count() #再对分组进行聚合
只是分组没有聚合,输出的是一个迭代器,里面是分好组的DataFrame
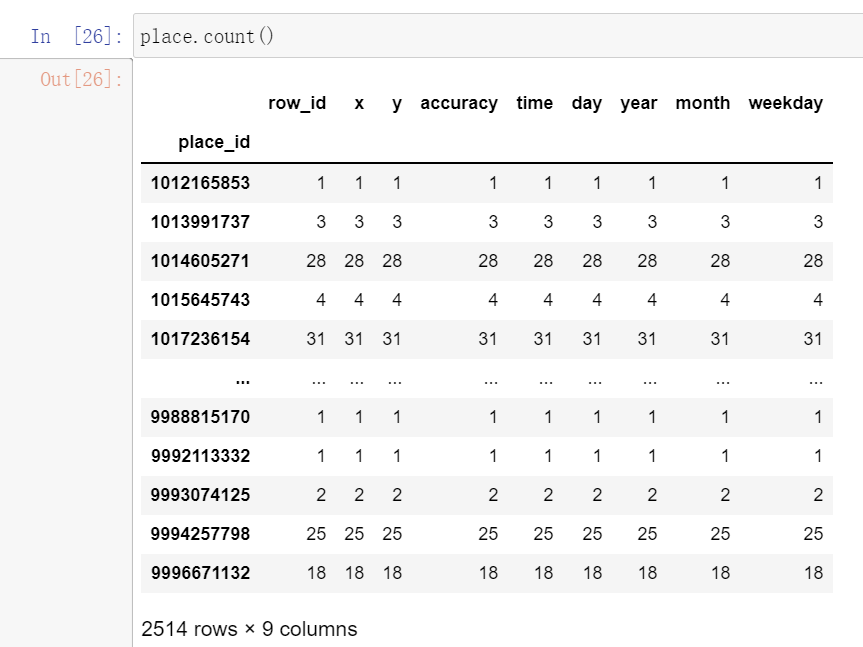
这样我们就得到了,分好组的place.count()
现在我们只需要第一列就行了
place_count = place_count['row_id']
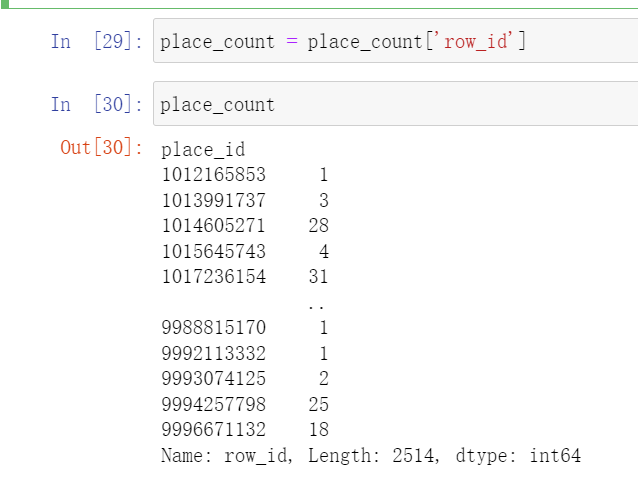
Pandas的索引条件,必须是索引值对应 True 或 False
如果是True或者False说明,我们已经经过了一次判断了。
place_count_index = place_count[place_count > 3] # 这样就可以把所有频率大于3的找出来
place_count = place_count[place_count_index]
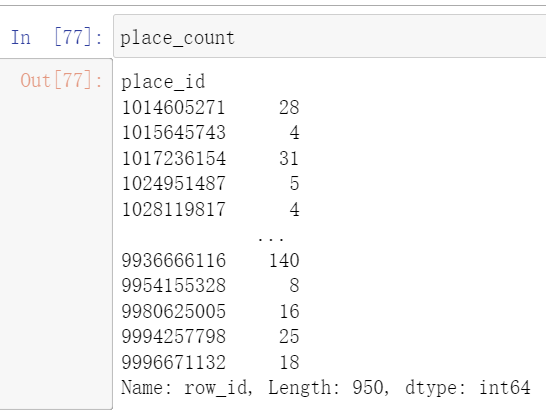
这样我们就去除了一些小的不满足签到次数的地点。
现在,我们要再创建一个index去删除data_narrow里面的数据
index_new = data_narrow['place_id'].isin(place_count)
这样我们就会得到一个index_new的索引判断
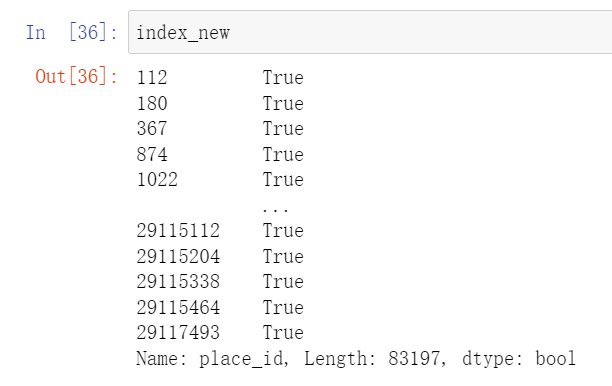
index_new有个特点,就是前面是index,后面对应了Boolean值。
data_narrow[index_new]

若有收获,就点个赞吧
0 人点赞
