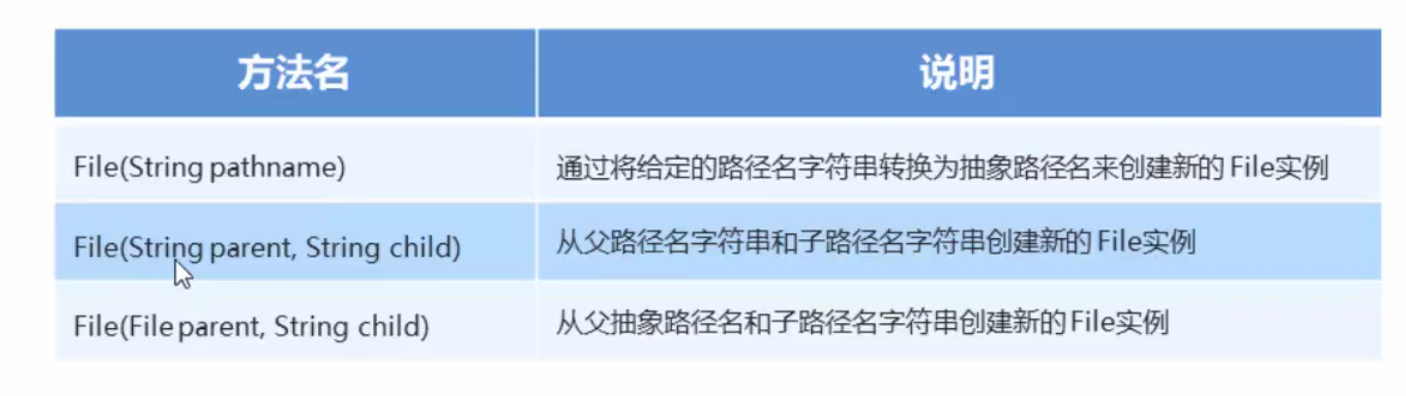
- File
- File类的删除功能
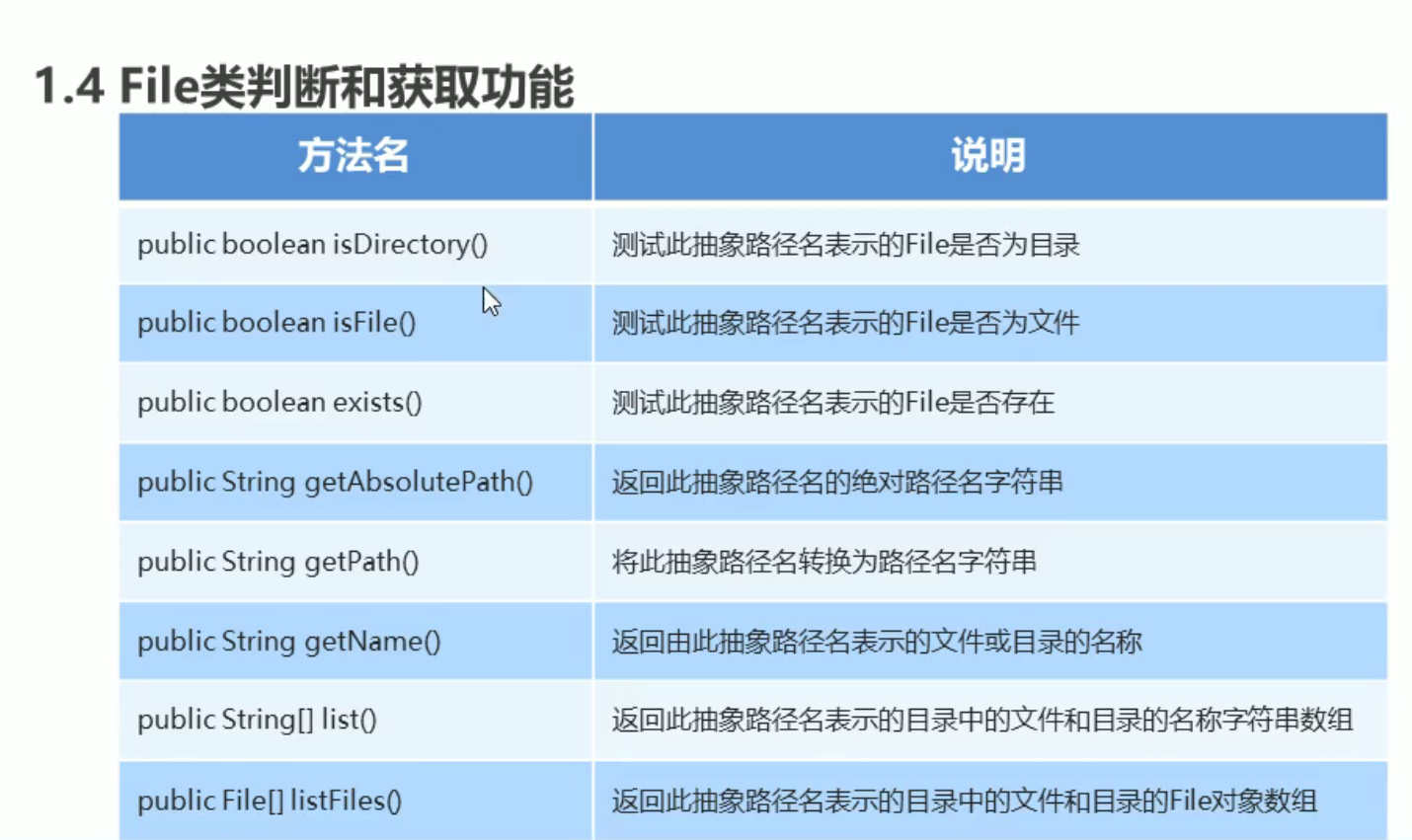
- File类的判断和获取功能
- IO流的概述和分类
- 字节流写数据
- 字节流复制图片
- 字节缓冲流
- 字符流
- 字符缓冲流
- 标准输入输出流
- 对象序列化
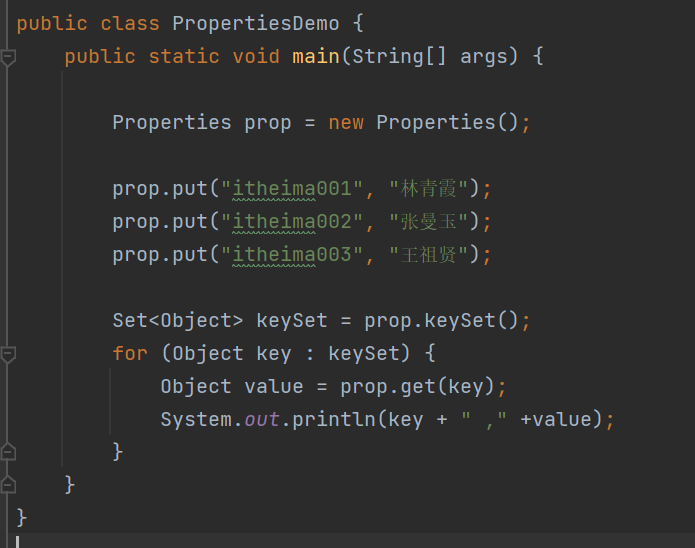
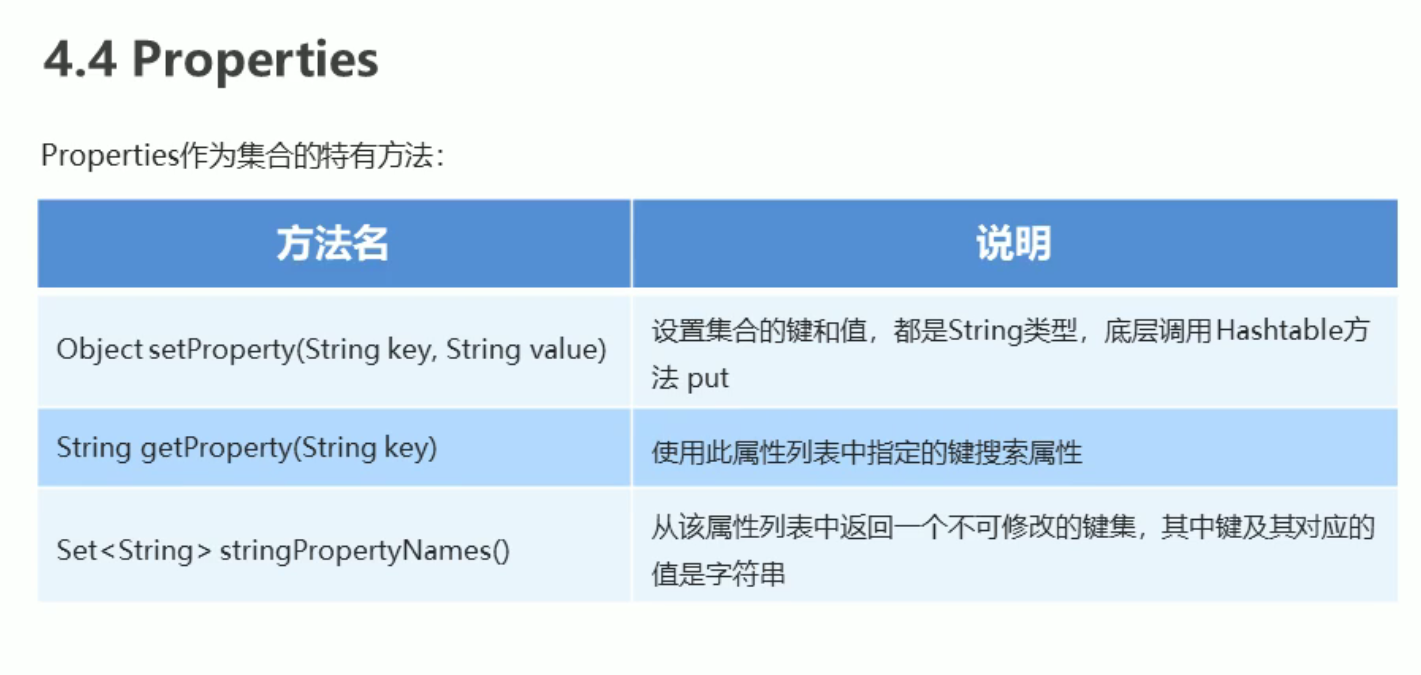
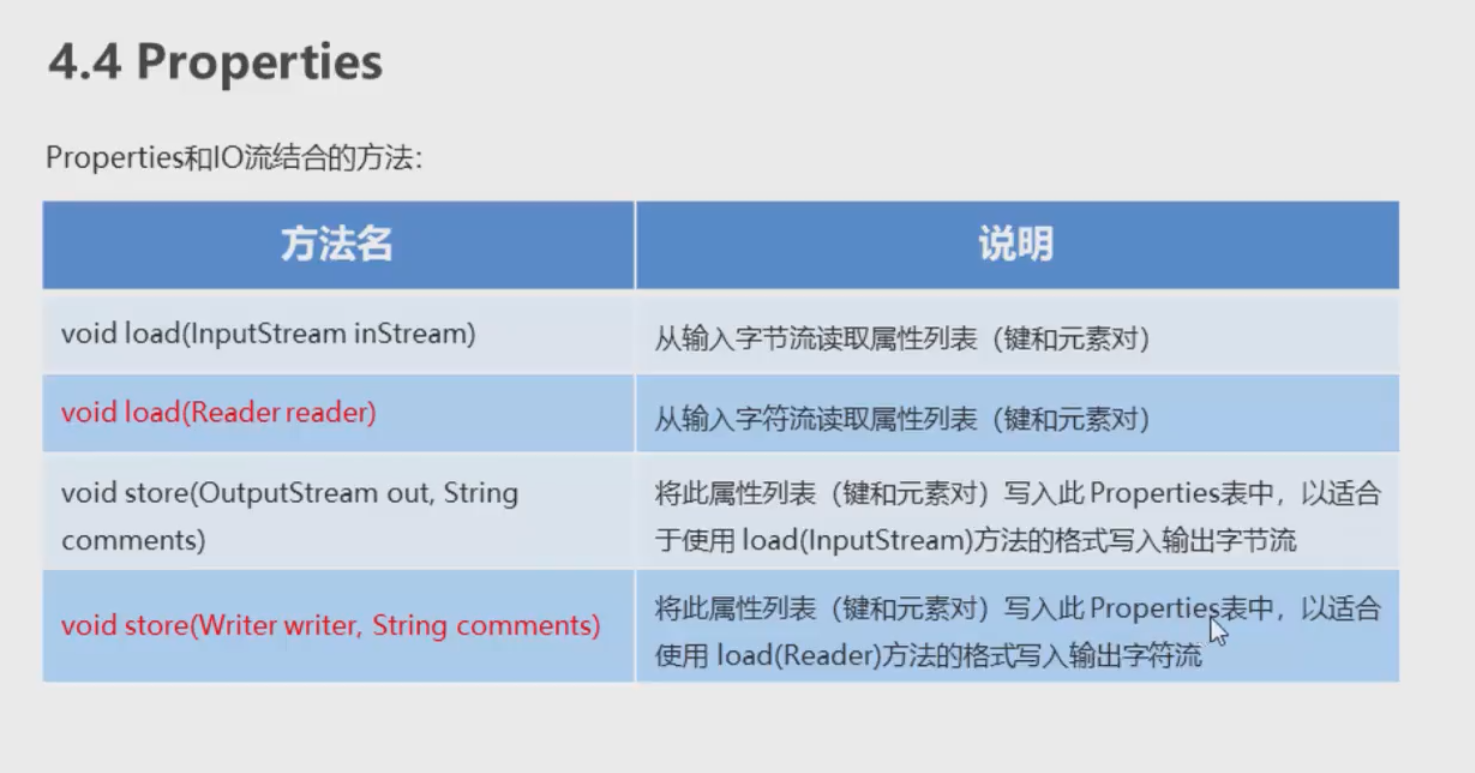
- Properties 特殊操作流



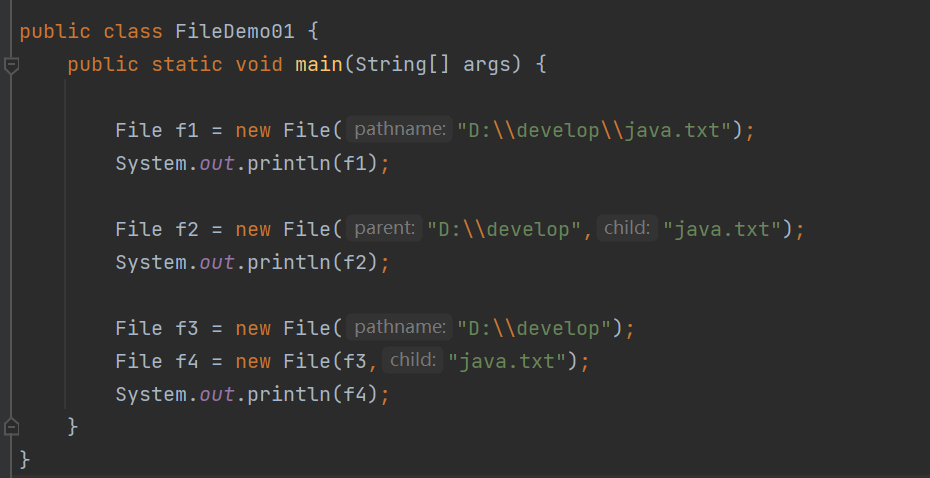
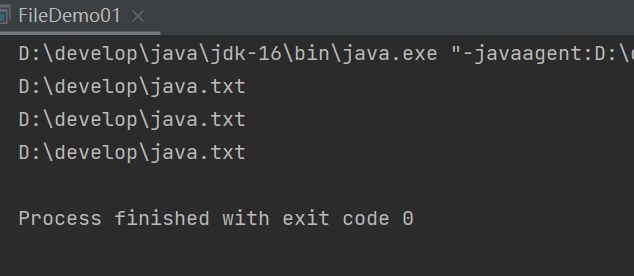
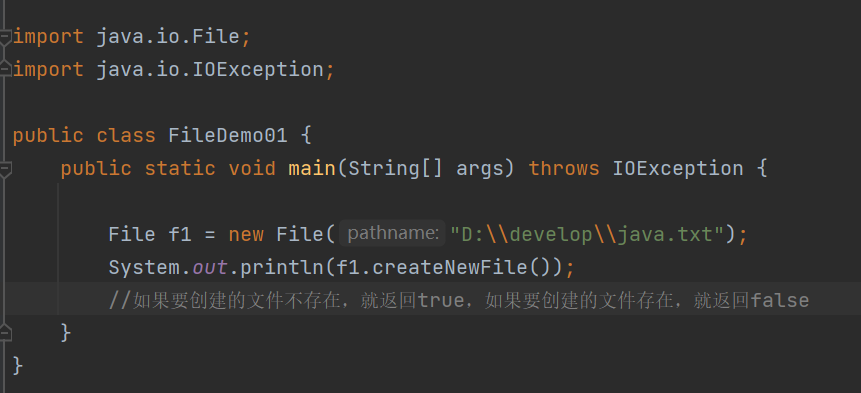
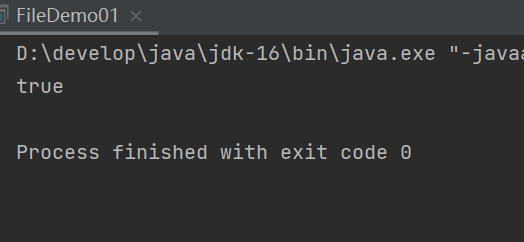
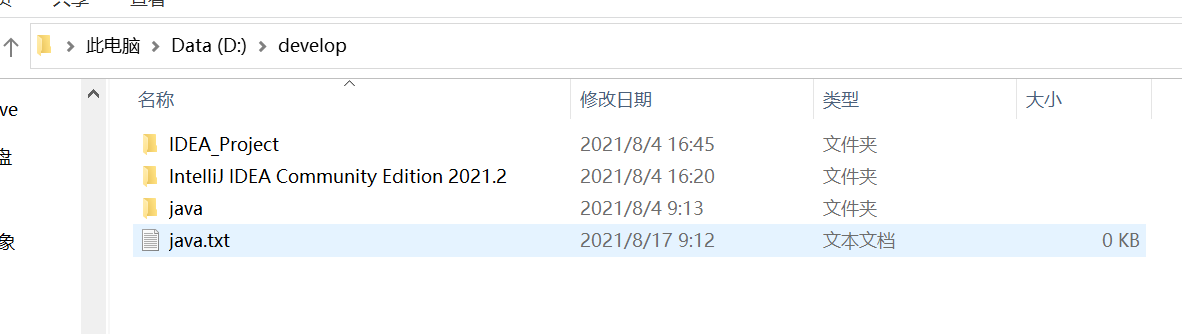
刚刚创建的,java.txt
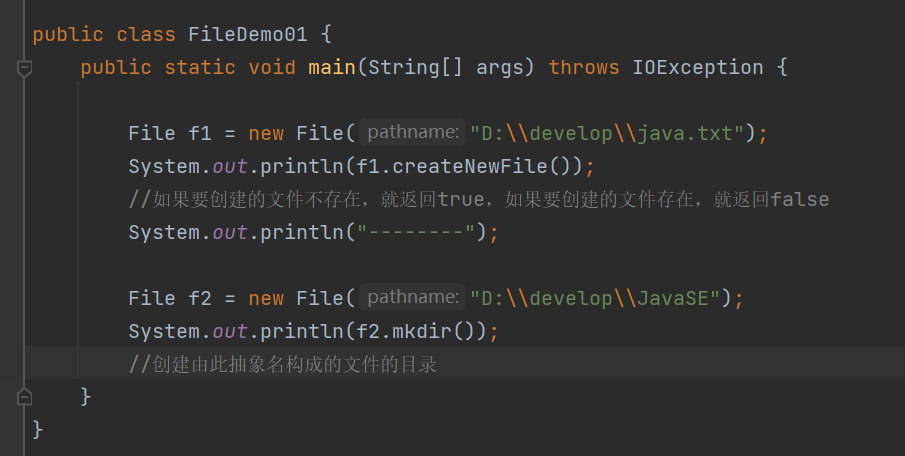
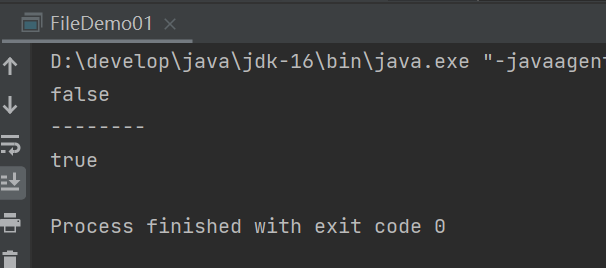
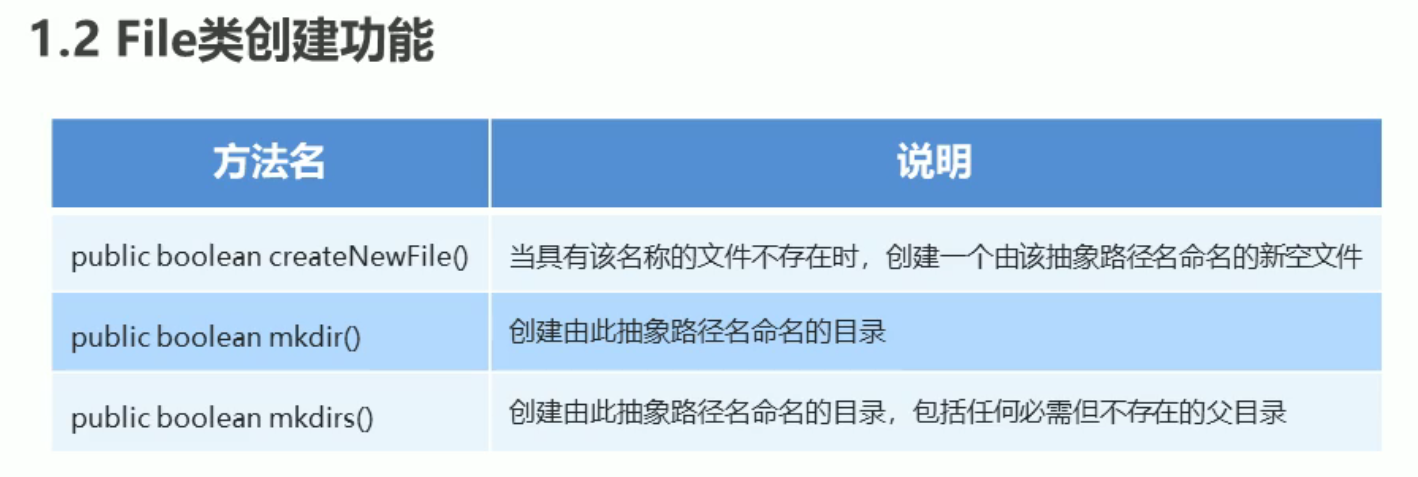
mkdirs() 创建多级目录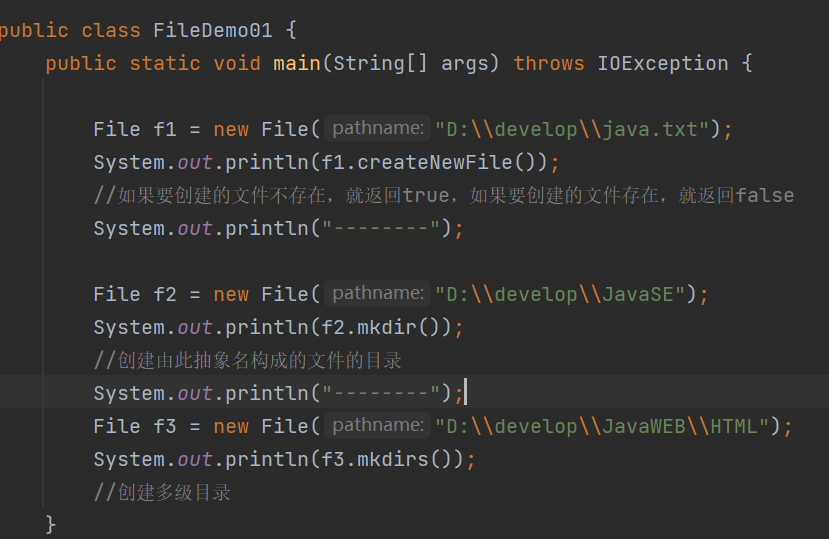
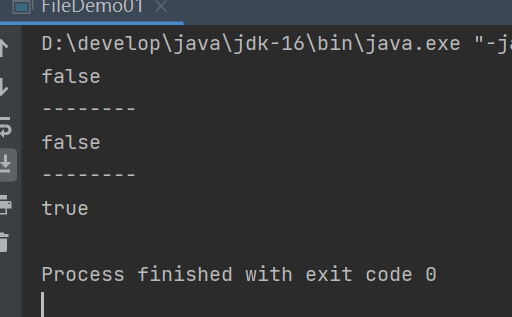

在已经存在javase.txt目录的情况下,创建javase.txt文件

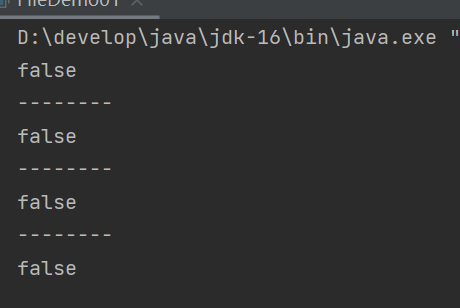
结果是false
因为我们已经存在javase.txt了,文件和目录都不能重名。
File类的删除功能

相对路径是从项目为起点开始查找的
当我们在创建文件时,忘记标记目录。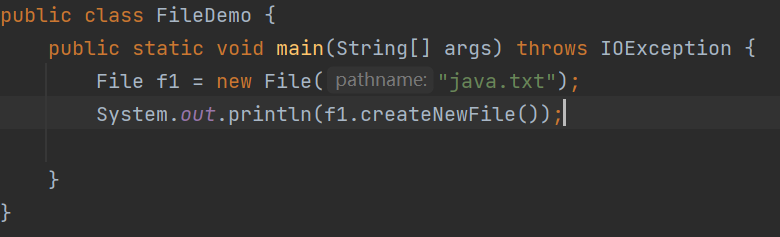
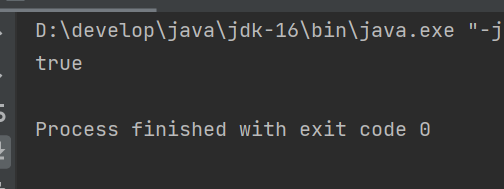
文件依然是能创建成功的。
找到f1的绝对路径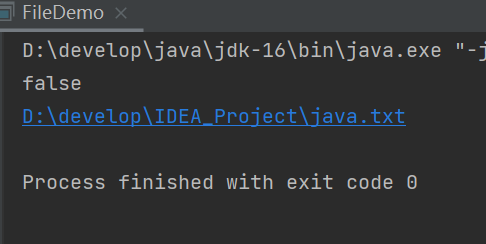
这里说明,项目是IDEA_Project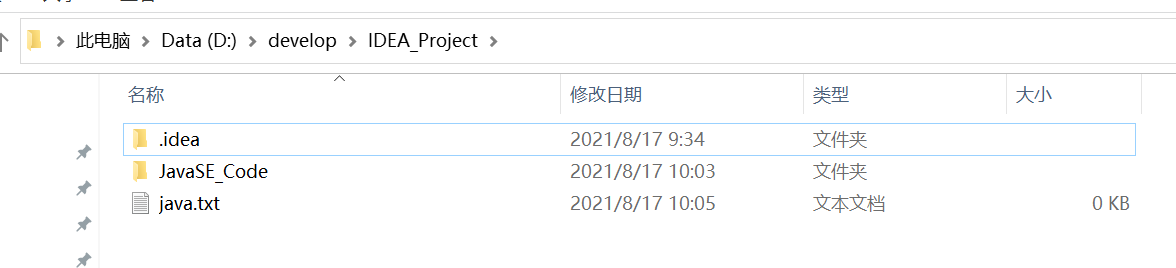
File的相对路径是从项目开始查找的,也就是从IDEA_Project开始查找的,只能看到JavaSE_Code和.idea两个文件夹。
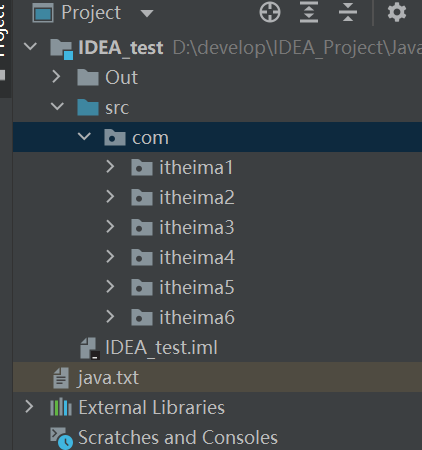
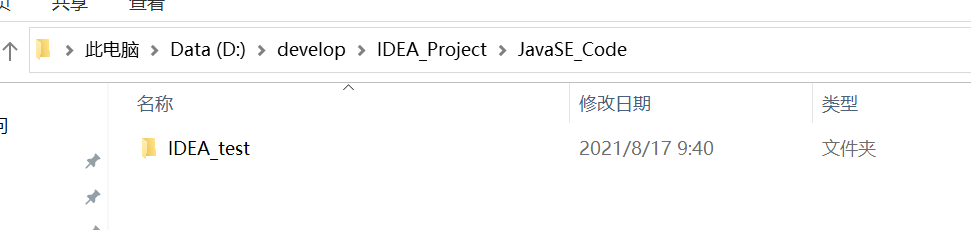
这是我们模块的位置。
如果我想创建文件在模块下怎么操作呢
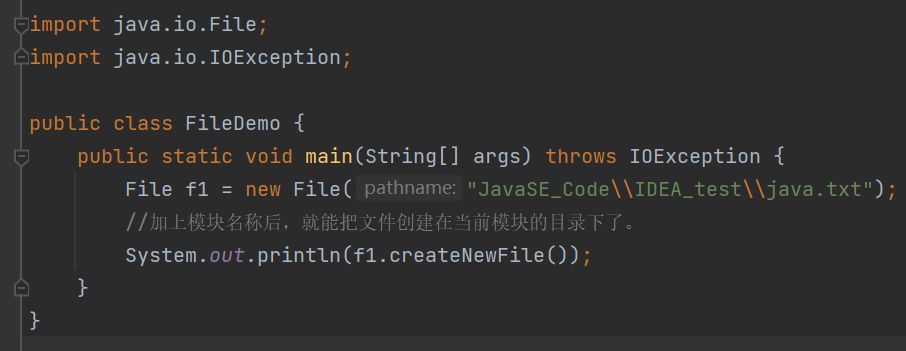
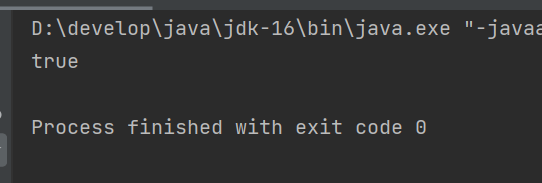
删除文件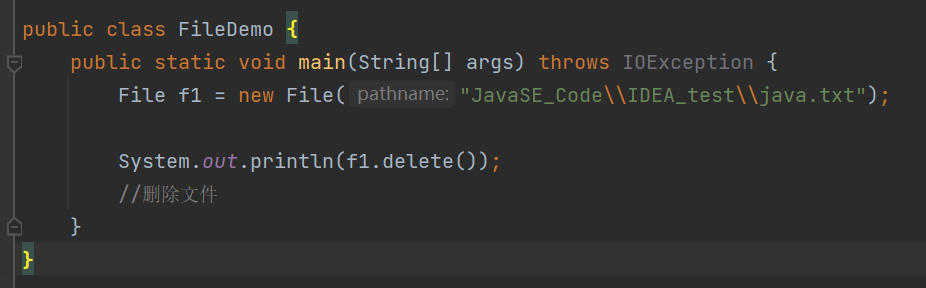

File类的判断和获取功能
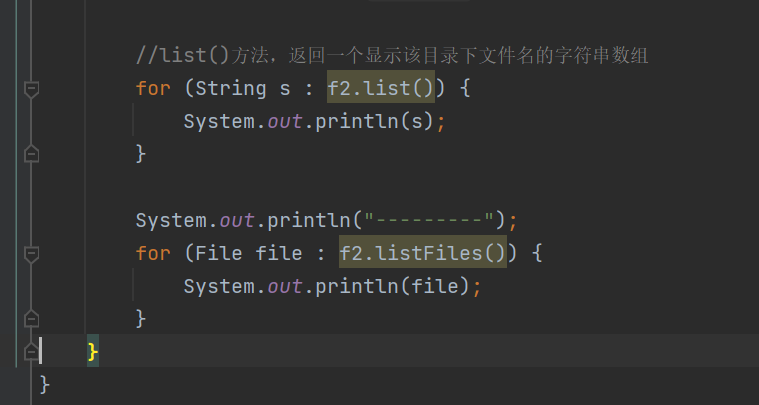
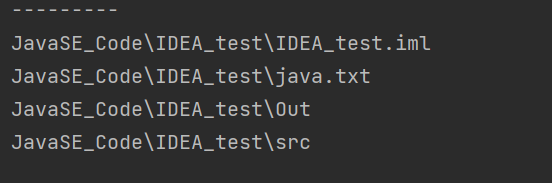
list()返回名字
listFiles()返回对象。
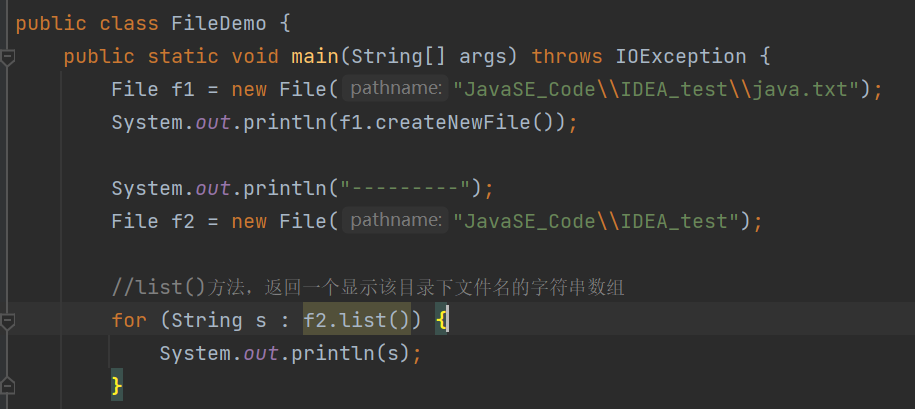
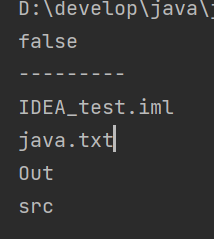
listFiles()返回文件对象。
IO流的概述和分类

流的本质是数据传输,数据在设备间的传输称为流
】
、、


字节流写数据

创建OutputStream类给文件写入数据
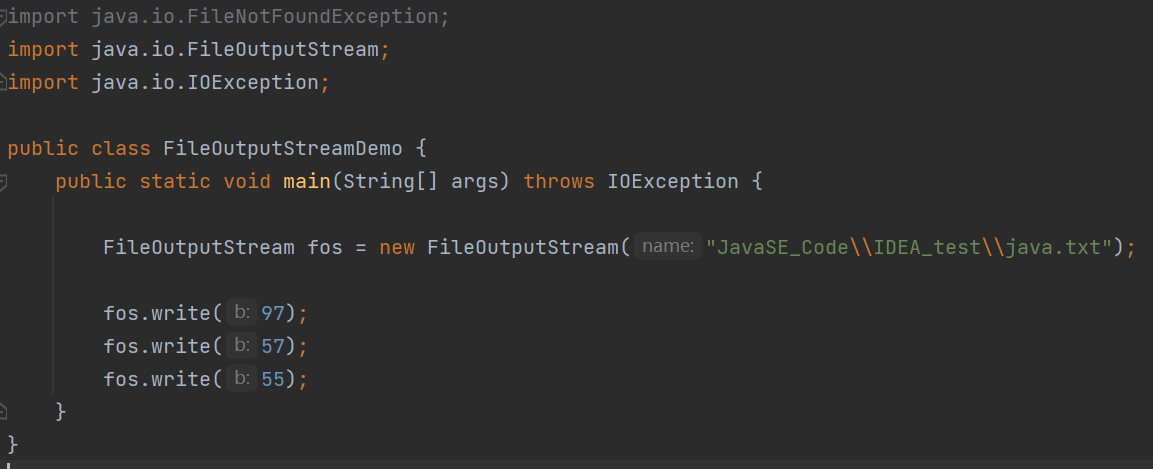
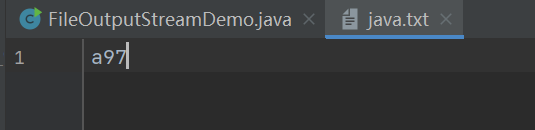
写入之后呈现的是输入数字的ASCII玛
所有和IO相关的操作,最后都要释放资源。
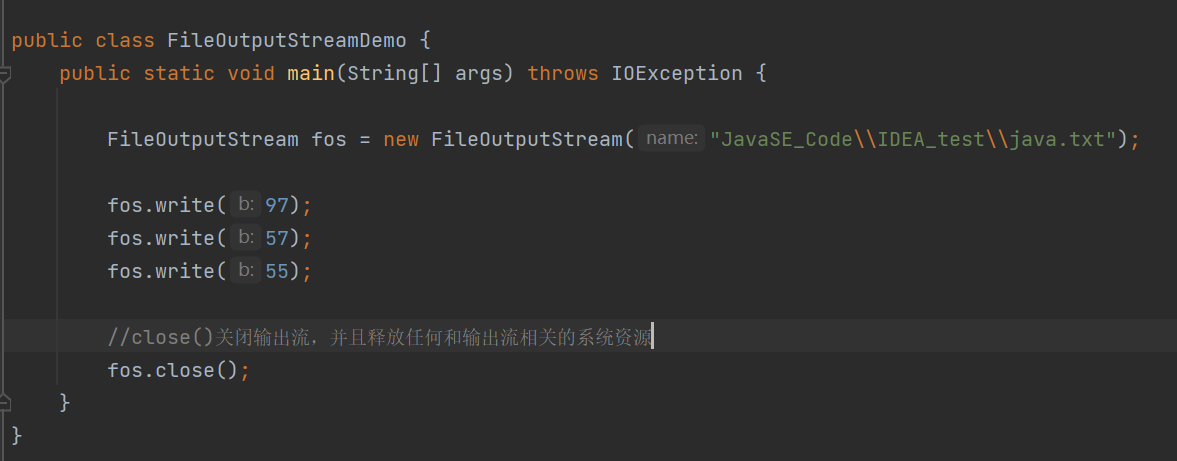
字节流写数据的三种方式

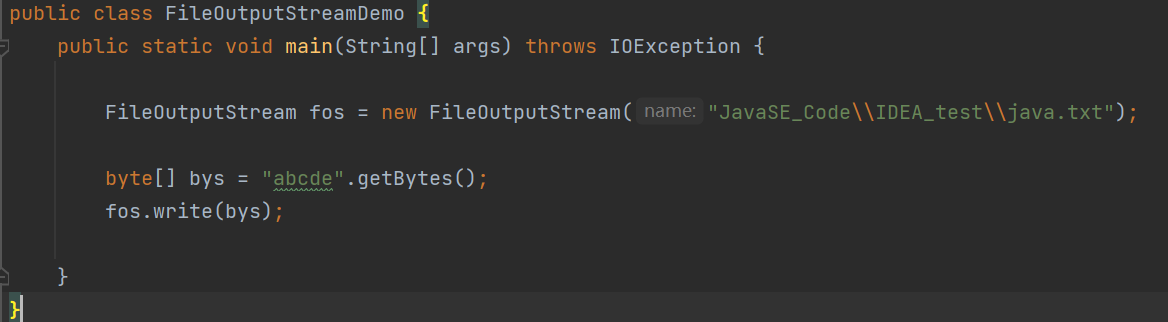
通过getBytes来写数据。
追加写入: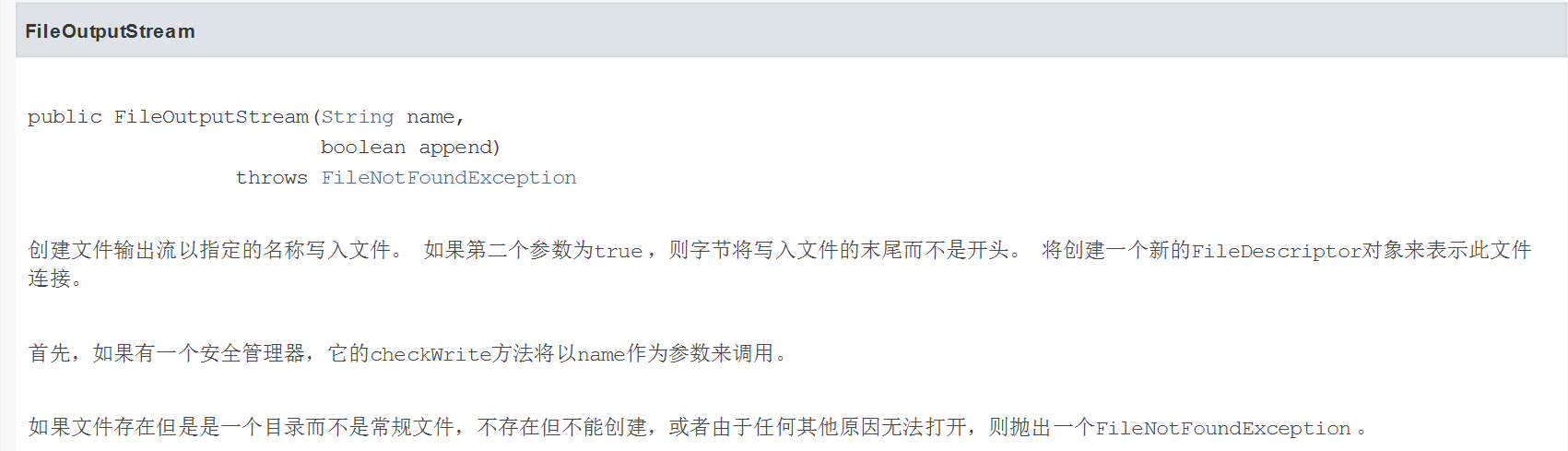


在字节流处理中,close()语句是一定要执行的,所以我们要使用finally修饰符

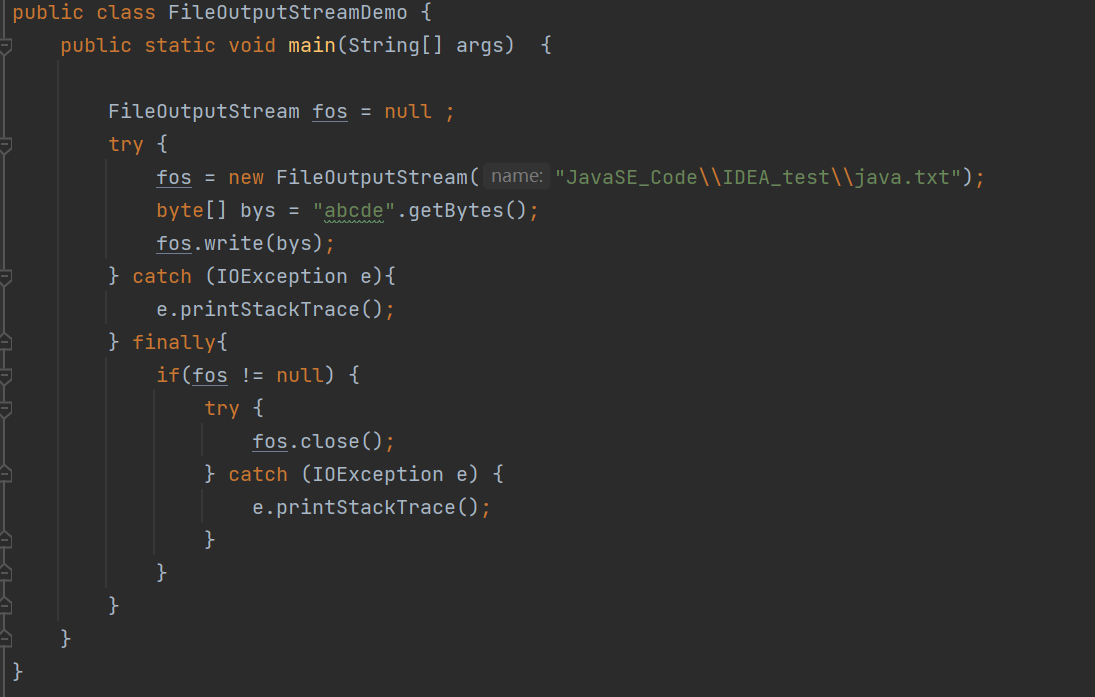
try中定义的语句finally中不一定会执行。因为try中的语句遇到异常之后就不会继续往下运行。
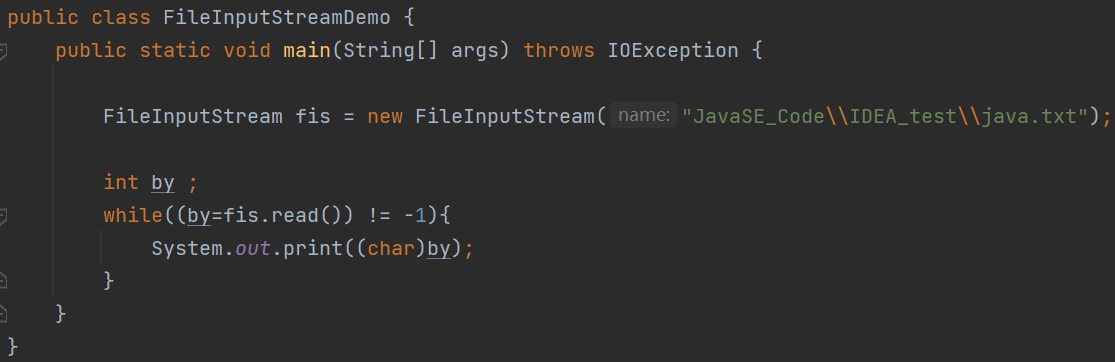
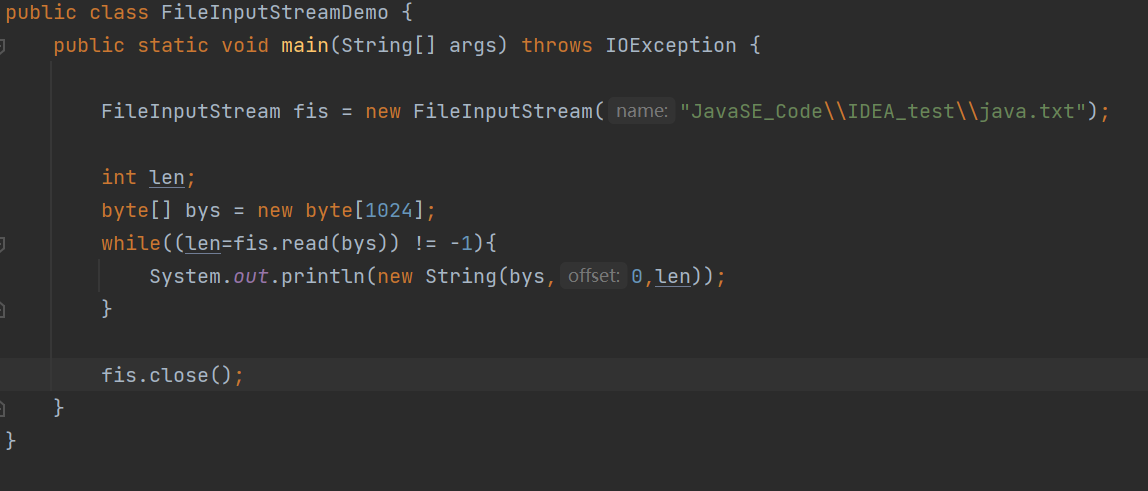
字节流读数据

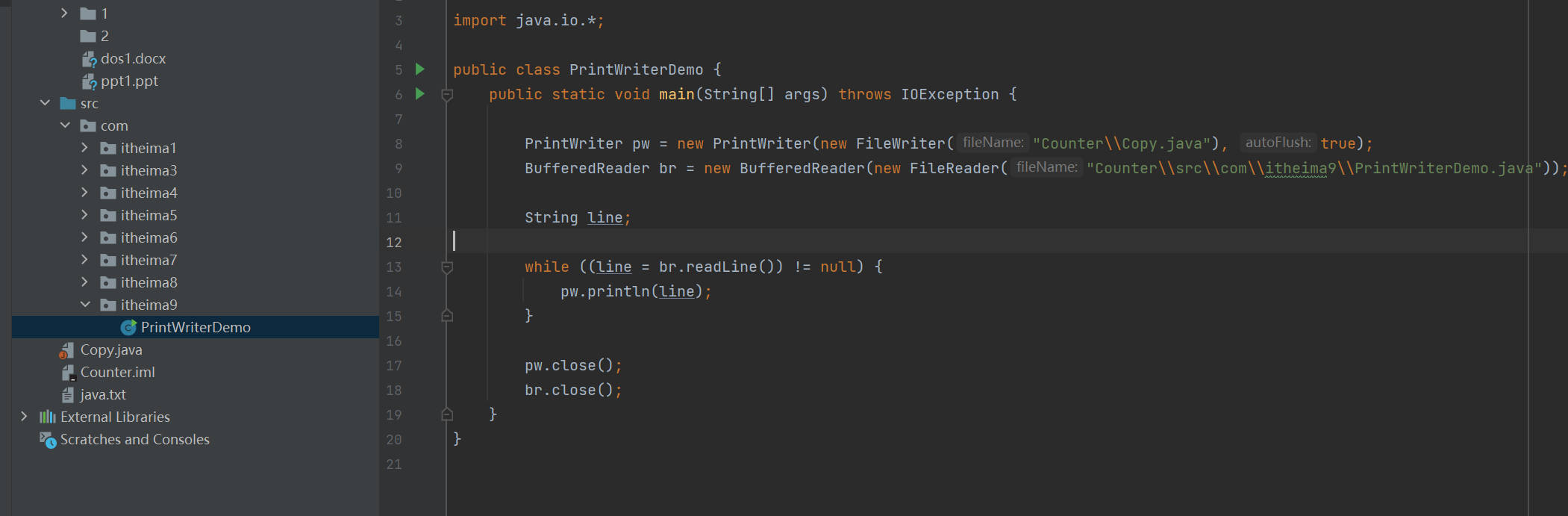
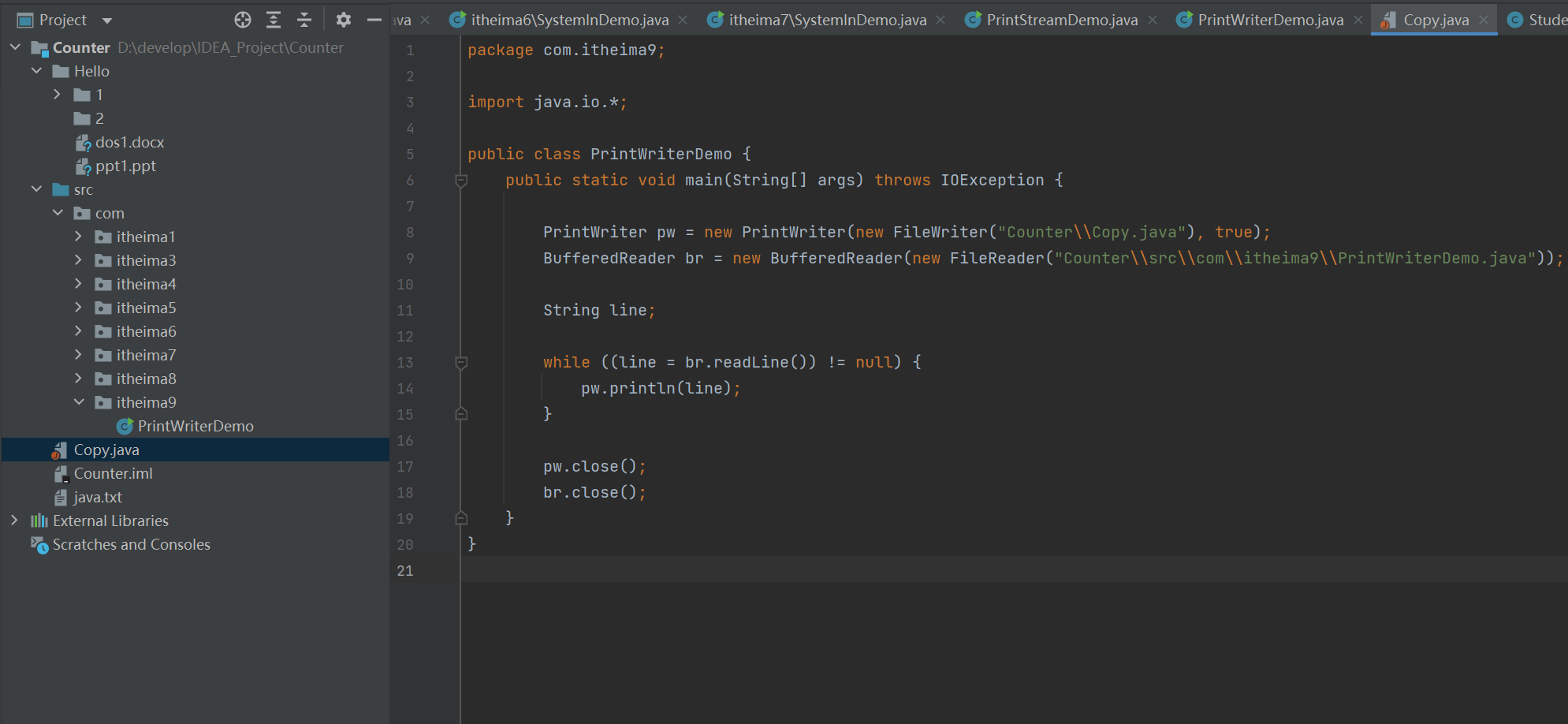
字节流复制文本文件

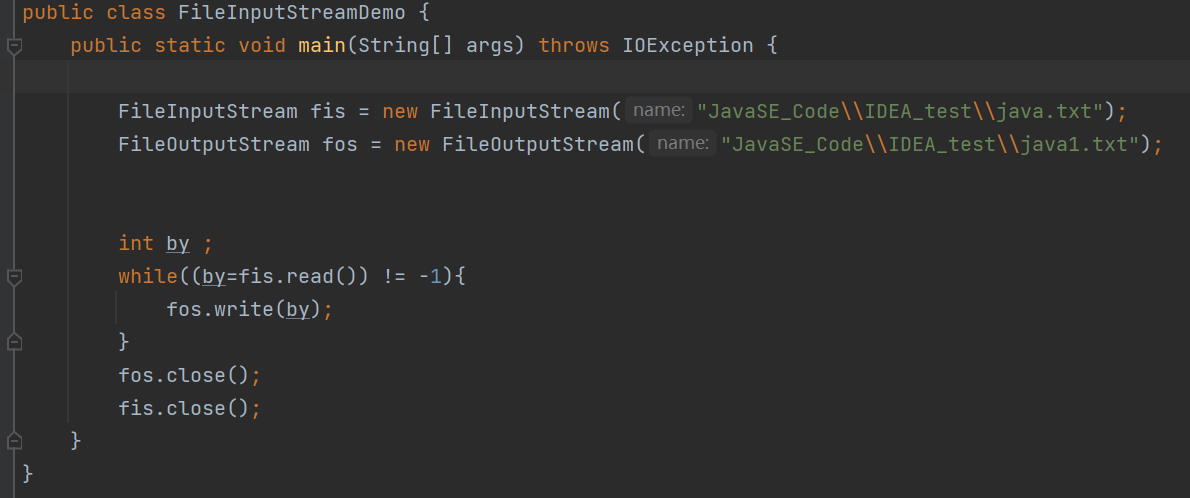
字节流读数据——一次读一个字节数组
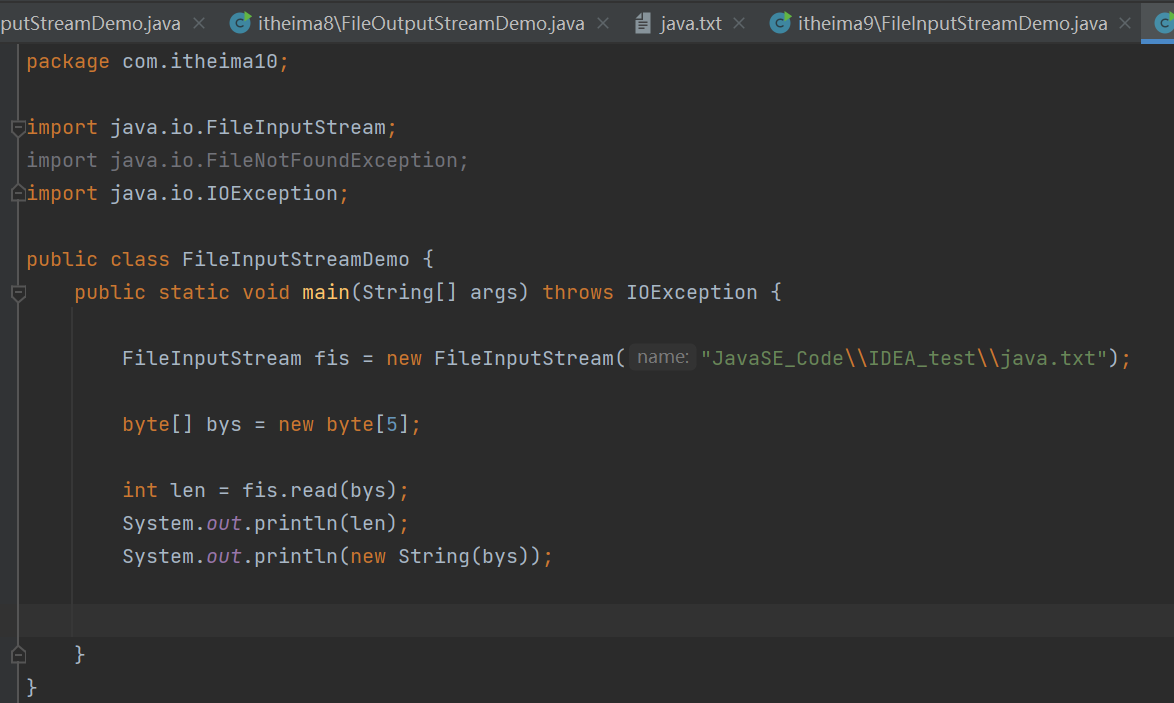
fis.read(bys);以字节数组的形式读取。
把文件中的数据读取到bys数组中。
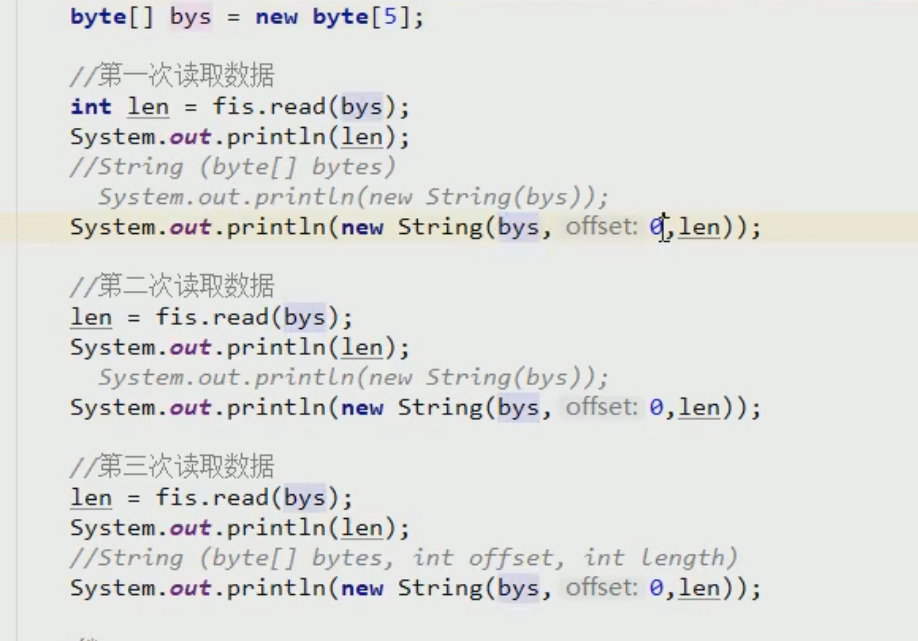
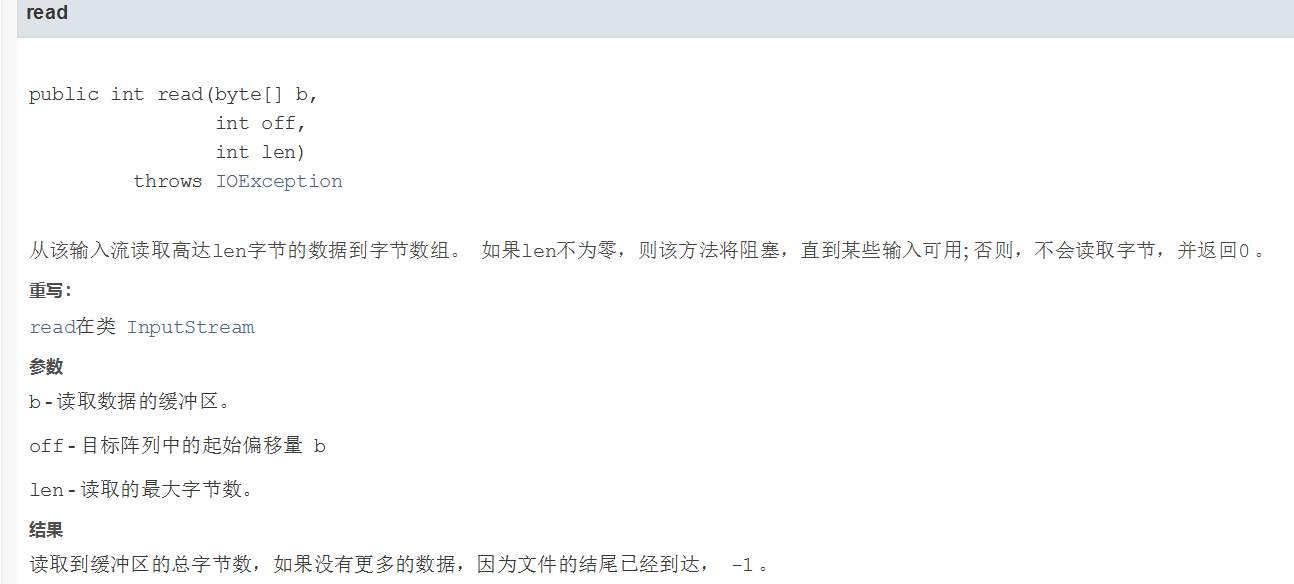
如果没有内容了,那就返回-1
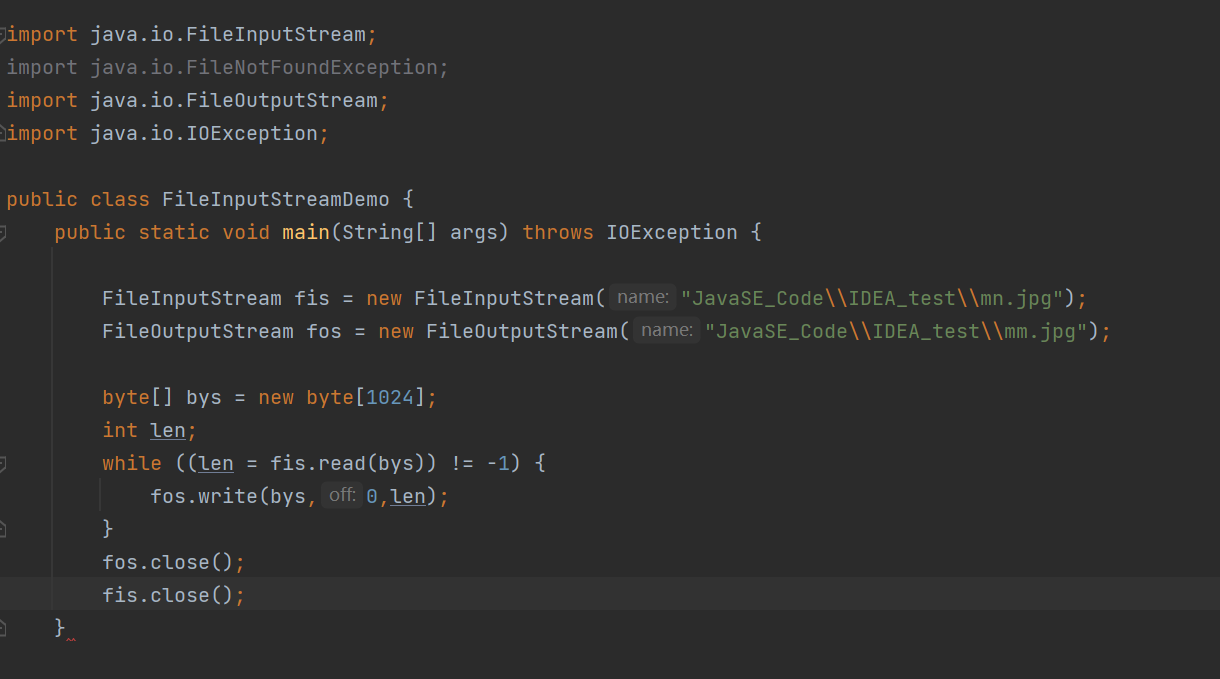
字节流复制图片
字节缓冲输出流
之前我们直接使用OutputStream的时候,这个类是向底层输出的字节流,是直接调用底层系统的。
现在我们可以通过BufferedOutputStream来产生一个缓冲。

字符流
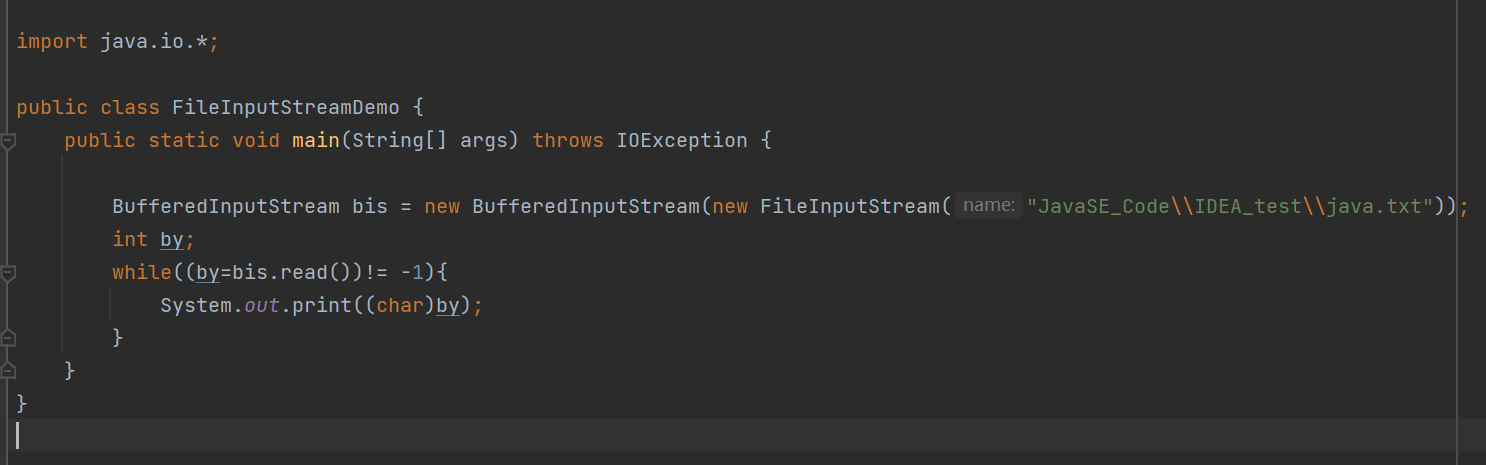
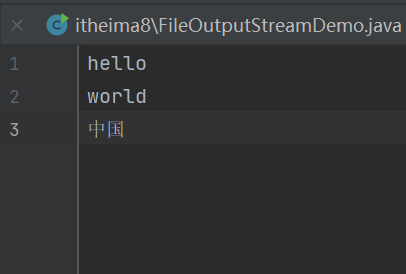
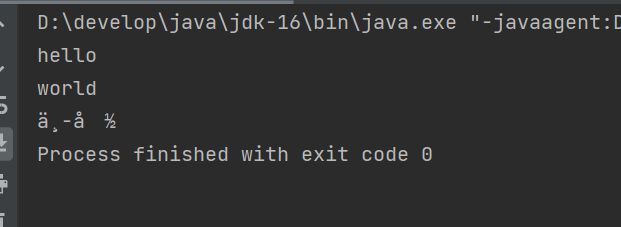
当我们读取字符的时候,一个中文相当于是两个到三个字节(根据不同的编码呈现不同的字节数)
如果我们只是一个一个读取字节并输出,系统就会提示错误的结果。
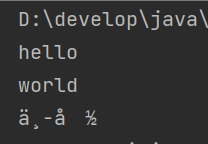
一个汉字的存储
如果是GBK编码,占用2个字节
如果是UTF-8编码,占用3个字节
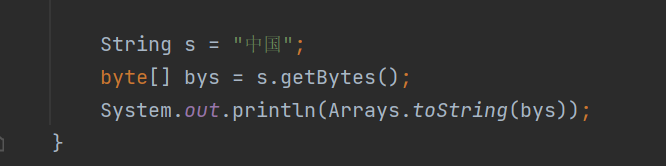
UTF-8编码
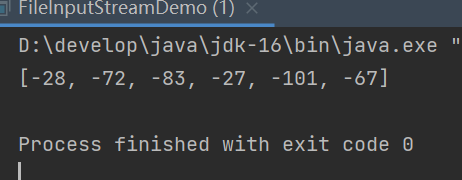
前面三 个 [-28,-72,083] 代表 中
后面三个 [-27,-101,-67]代表 国
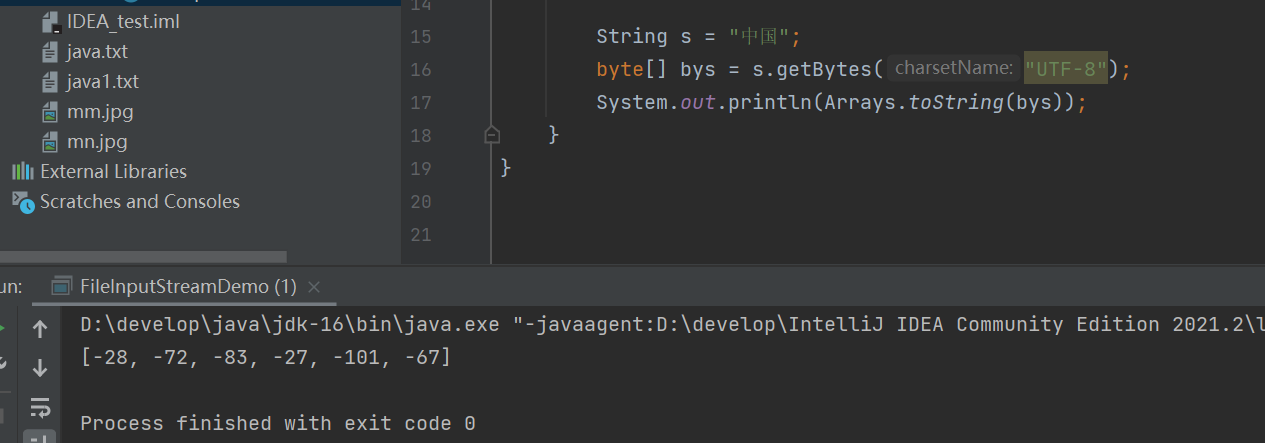
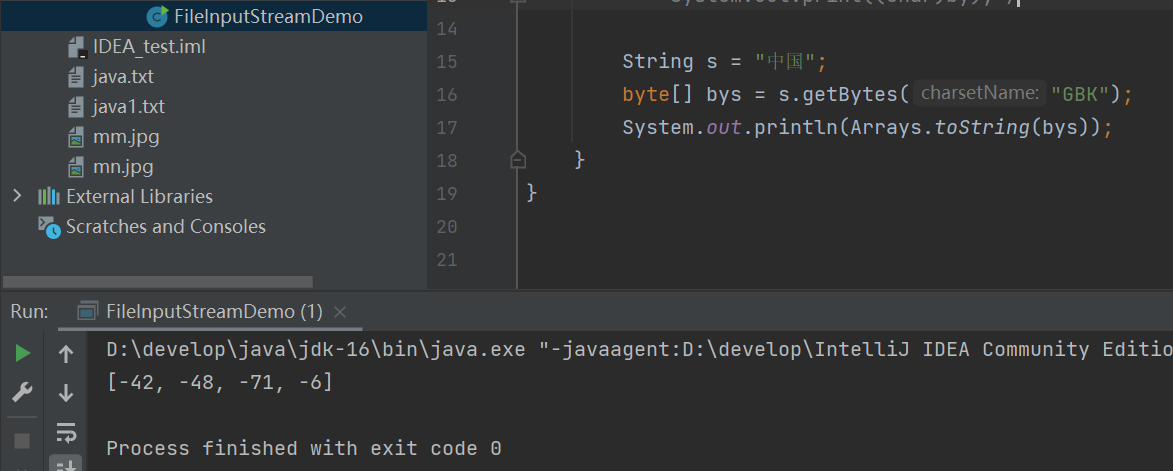
当我们采用GDK编码的时候,就变成了两个字符了

编码表









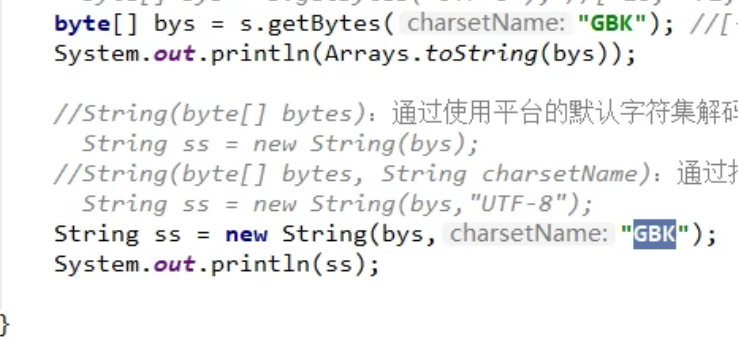
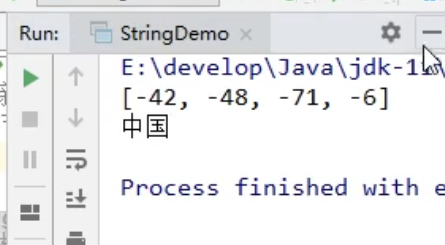
字符流中的编码解码问题

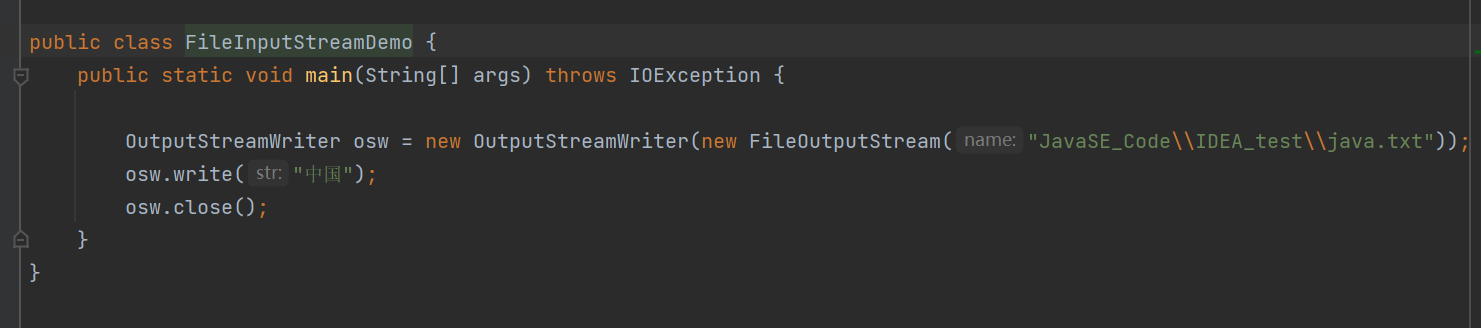
OutputStreamWriter的输入应该是字节输出流的对象
字符输出流,是字节输出流和字符串的桥梁
- InputStreamReader是从字节流到字符流的桥梁:它读取字节,并使用指定的charset将其解码为字符。它使用的字符集可以由名称指定,也可以被明确指定,或者可以接受平台的默认字符集。
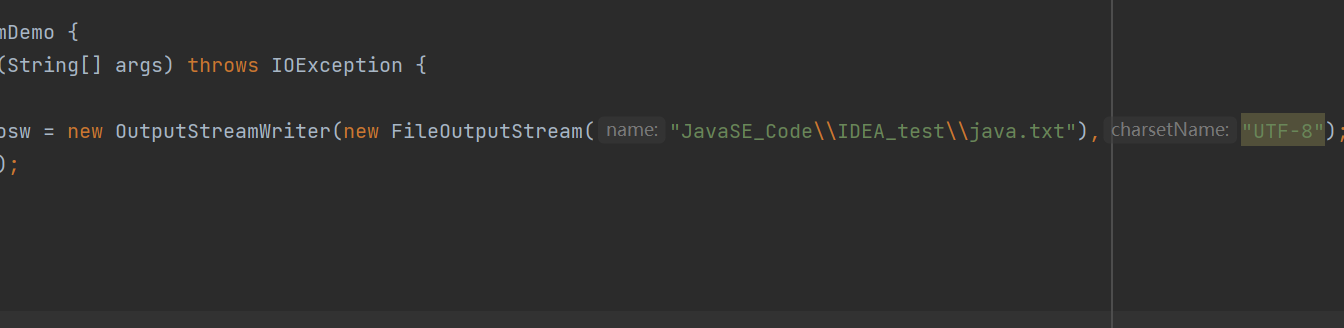
我们还可以在字节输出/输入流中指定charsetName就是字符集。
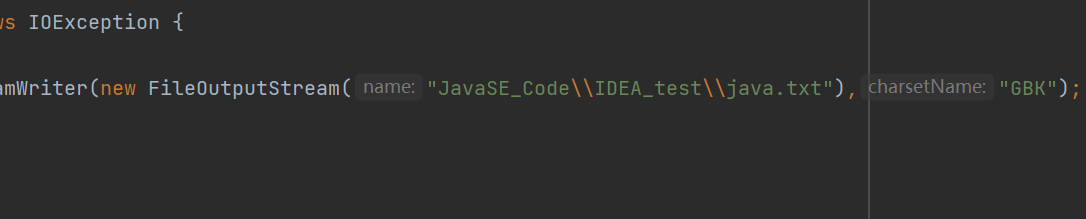
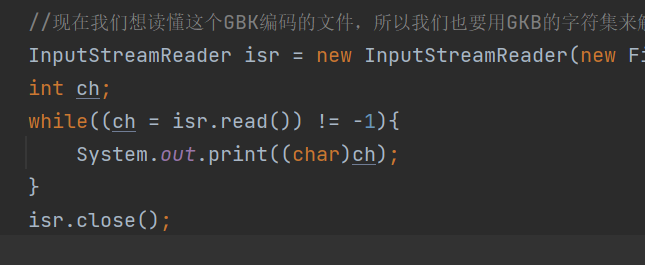
如果我们把字符集设计为GBK,那么我们再打开文件试试看。
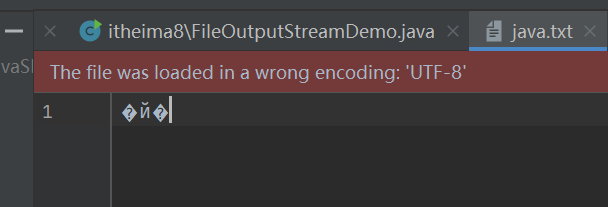
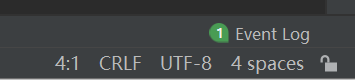
我们会发现,打开的文件不是我们想要的内容,那是因为,文件默认是用UTF-8解码的
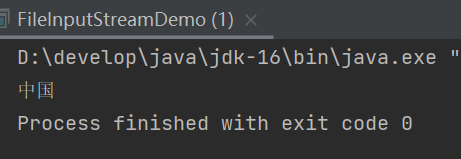
我们可以用InputStreamReader转化

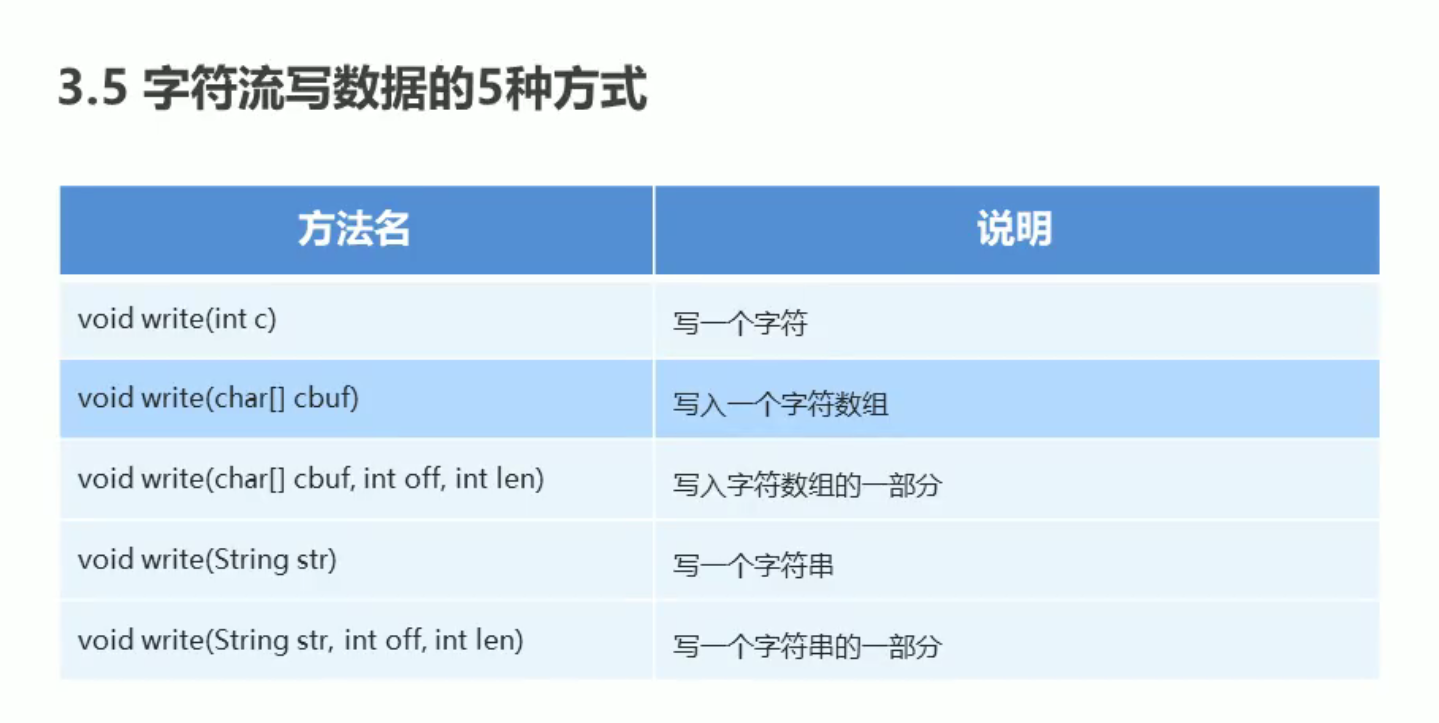
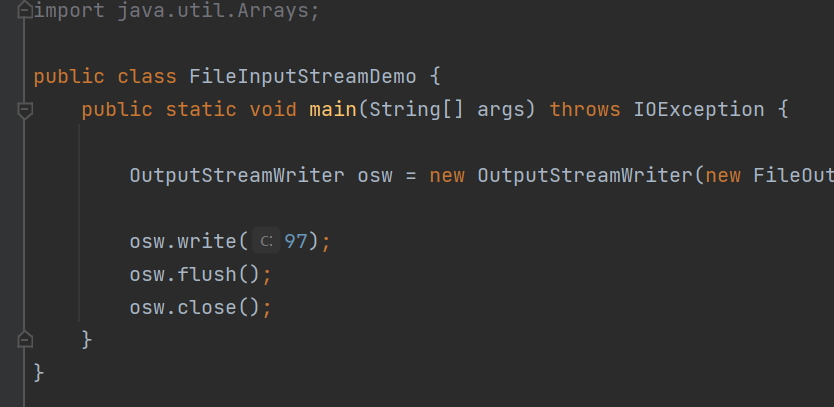
字节流写数据的五种方式

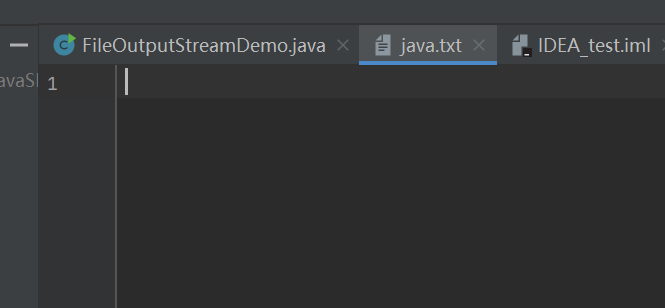
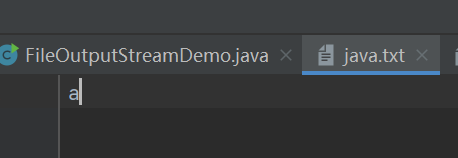
我们可以看到文本文件中并没有输入内容
这是因为,我们向OUtputStreamWriter写的内容只是暂时存放在缓冲区里的,我们还没有真正的通过字节流输入到文本文件中。
这时候我们需要使用flush()方法去刷新缓冲区,把字节流输入到电脑之中
close()方法自带刷新数据
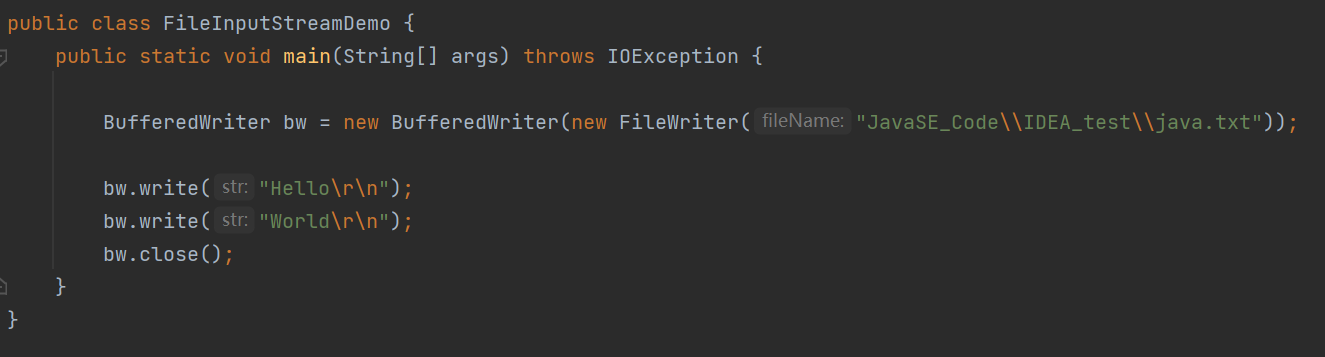
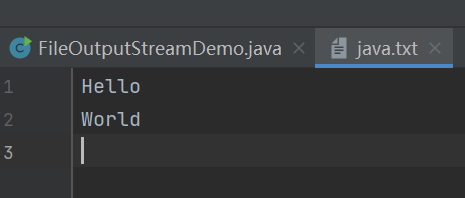
字符缓冲流


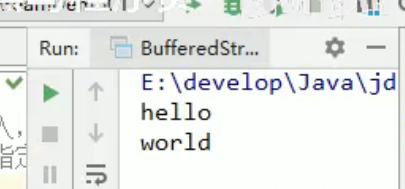


标准输入输出流



打印流


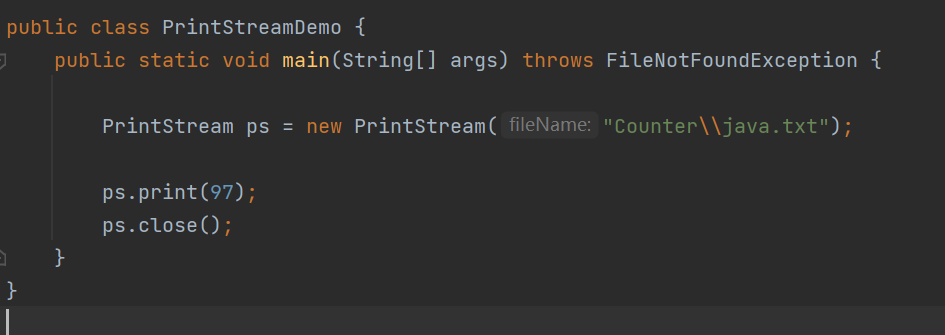
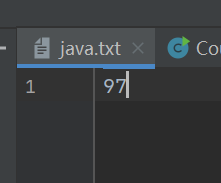
字符打印流
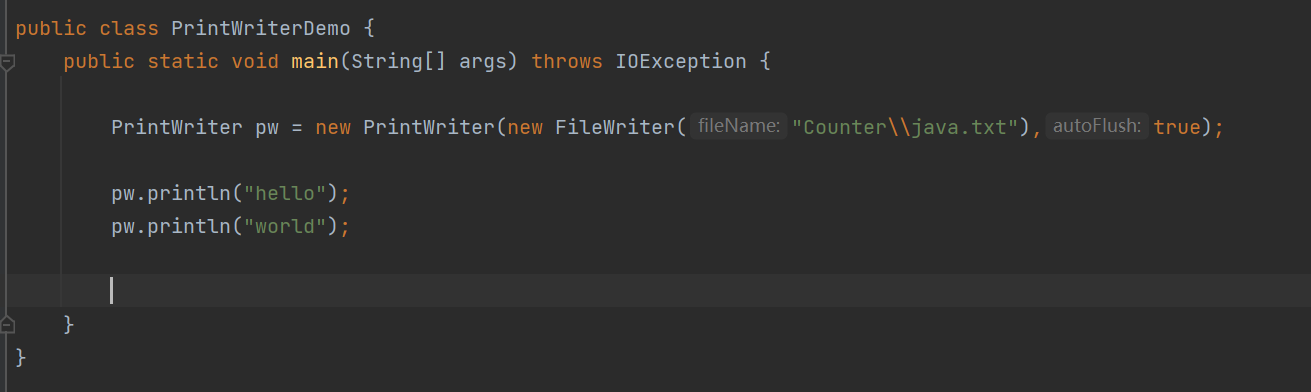
PrintWriter
对象序列化

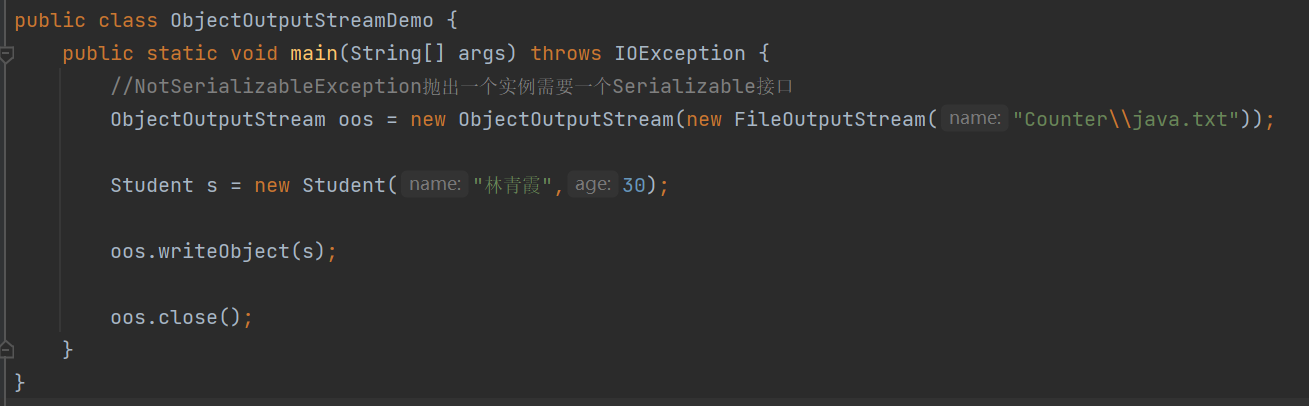



输出的值我们读不懂是因为我们还没有进行对象反序列化。
对象反序列化流

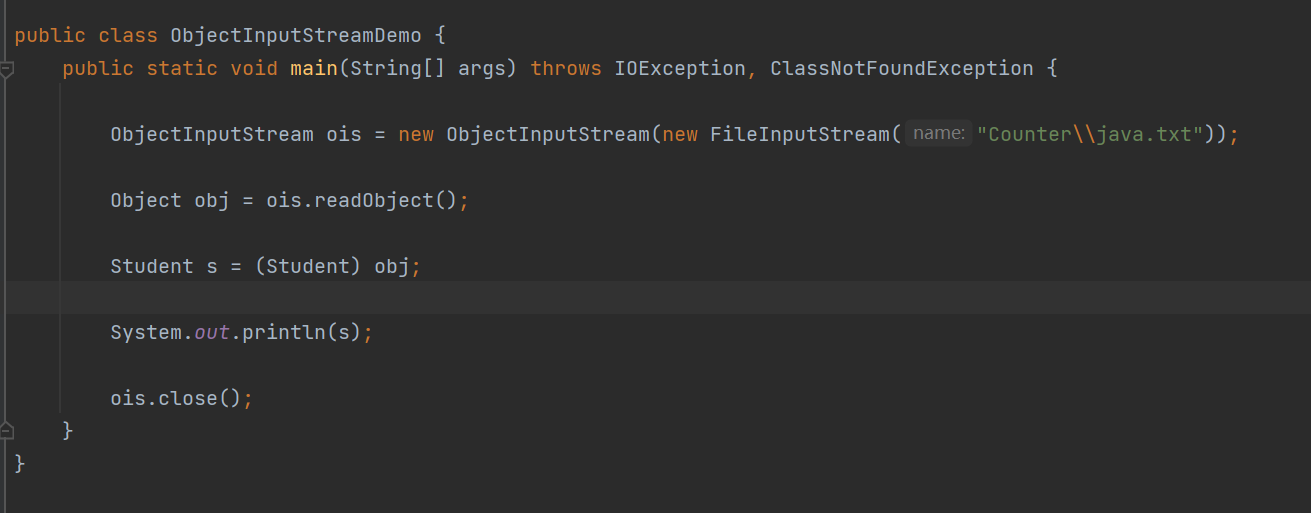


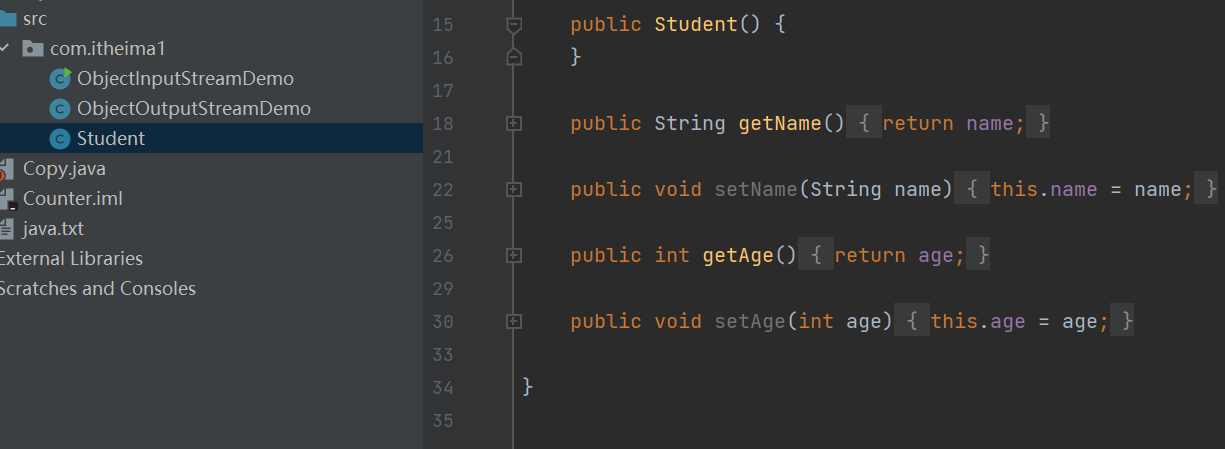
在学生类的,toString 方法还没修改之前
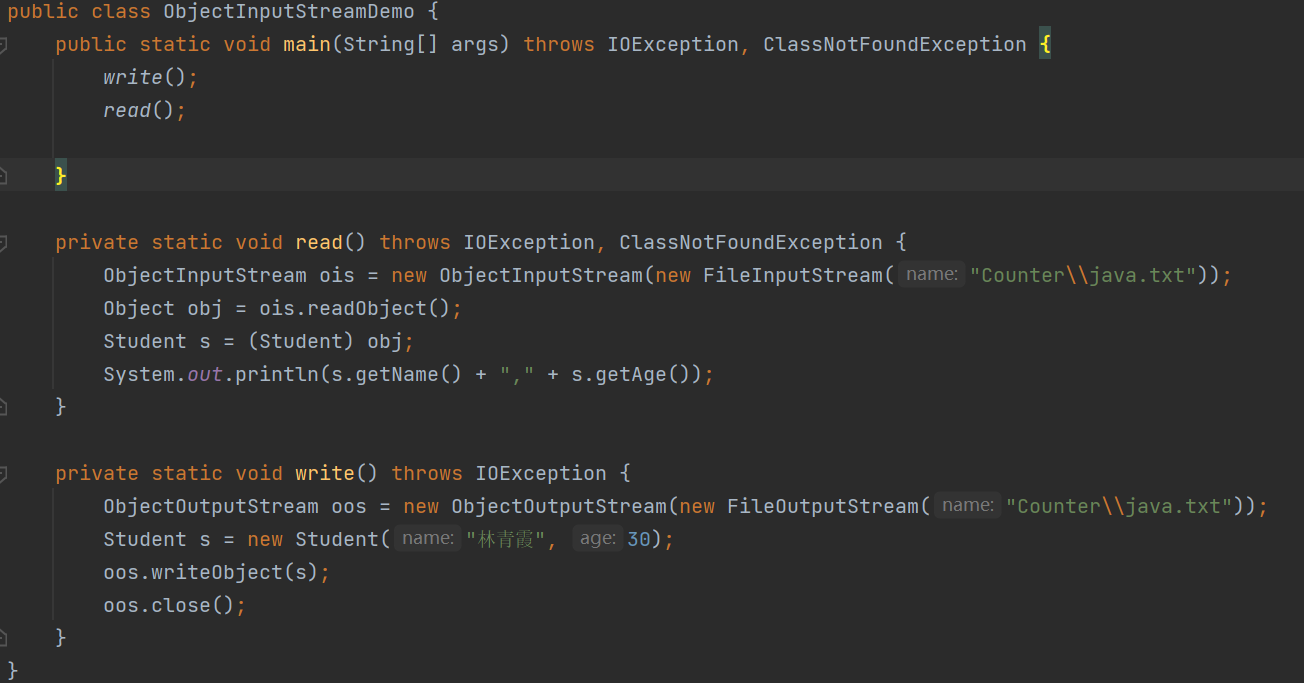
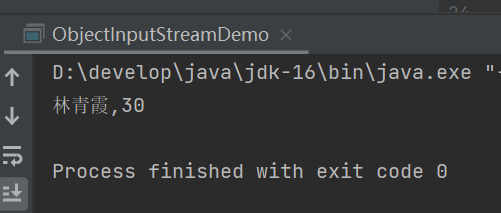
现在我们重写toString方法
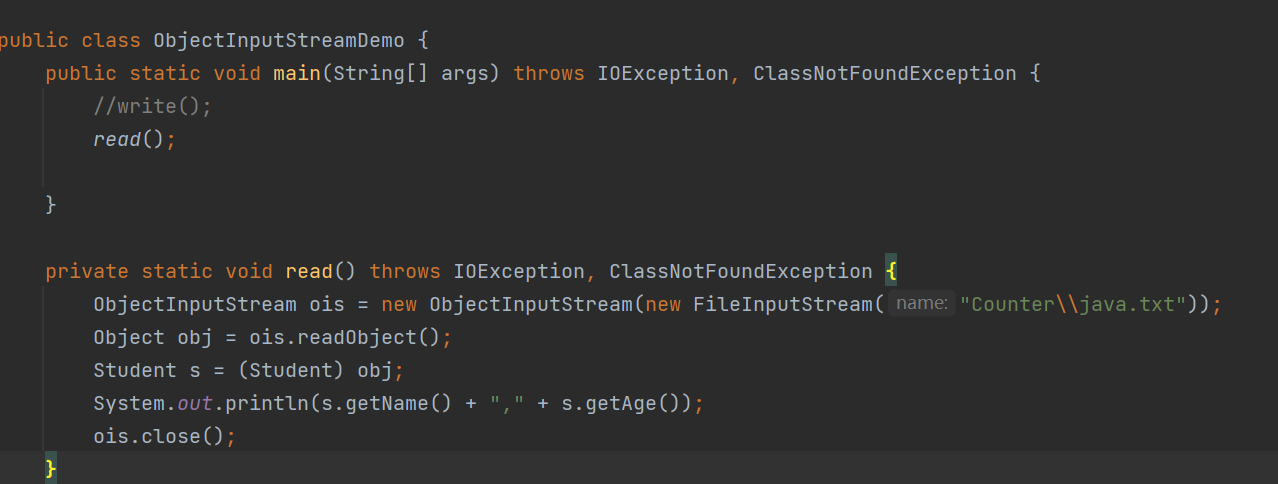

再次运行的时候,我们发现报错了。
注意哦,我们一定要注释掉write方法,不然是不会出问题的,因为每一次写write都会写一次UID进去
Exception in thread “main” java.io.InvalidClassException
com.itheima1.Student; local class incompatible:
stream classdesc serialVersionUID = -6281151665433793349,
local class serialVersionUID = -534666271653364536
这里是因为修改了Student之后,UID变得跟之前不同了,所以我们会出现无效类异常。
这里我们需要学习如何给类添加自定义的UID,这样就不会类似的情况了。
- 序列化运行时与每个可序列化的类关联一个版本号,称为serialVersionUID,它在反序列化过程中使用,以验证序列化对象的发送者和接收者是否加载了与序列化兼容的对象的类。如果接收者已经为具有与对应发件人类别不同的serialVersionUID的对象加载了一个类,则反序列化将导致一个InvalidClassException 。一个可序列化的类可以通过声明一个名为”serialVersionUID”的字段来显式地声明它自己的serialVersionUID,该字段必须是static,final和long类型: ANY-ACCESS-MODIFIER static final long serialVersionUID = 42L; 如果可序列化类没有显式声明serialVersionUID,则序列化运行时将根据Java(TM)对象序列化规范中所述的类的各个方面计算该类的默认serialVersionUID值。然而, 强烈建议所有可序列化的类显式声明serialVersionUID值,因为默认的serialVersionUID计算对类细节非常敏感,这些细节可能因编译器实现而异,因此可能会在反序列化期间导致意外的InvalidClassException 。
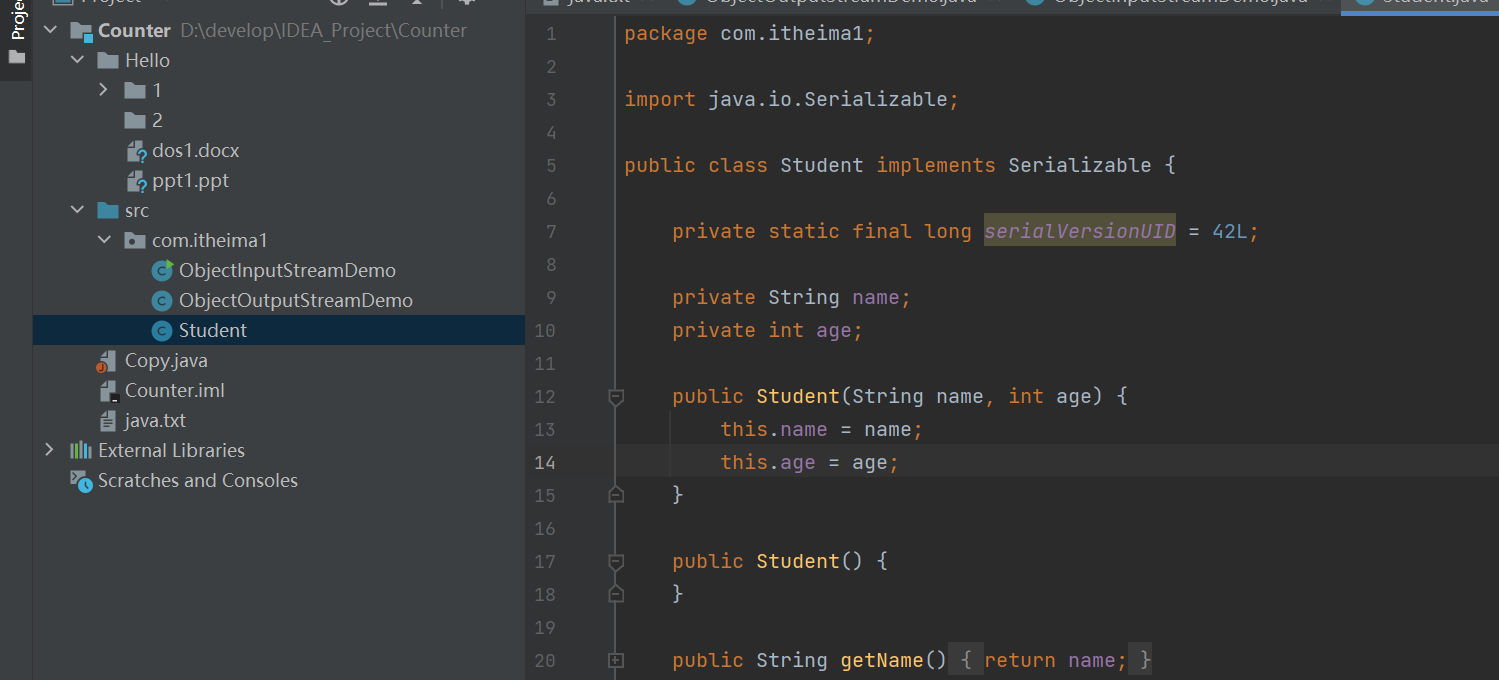
我们现在在学生类中加入
serialVersionUID的值,现在我们再看一下。
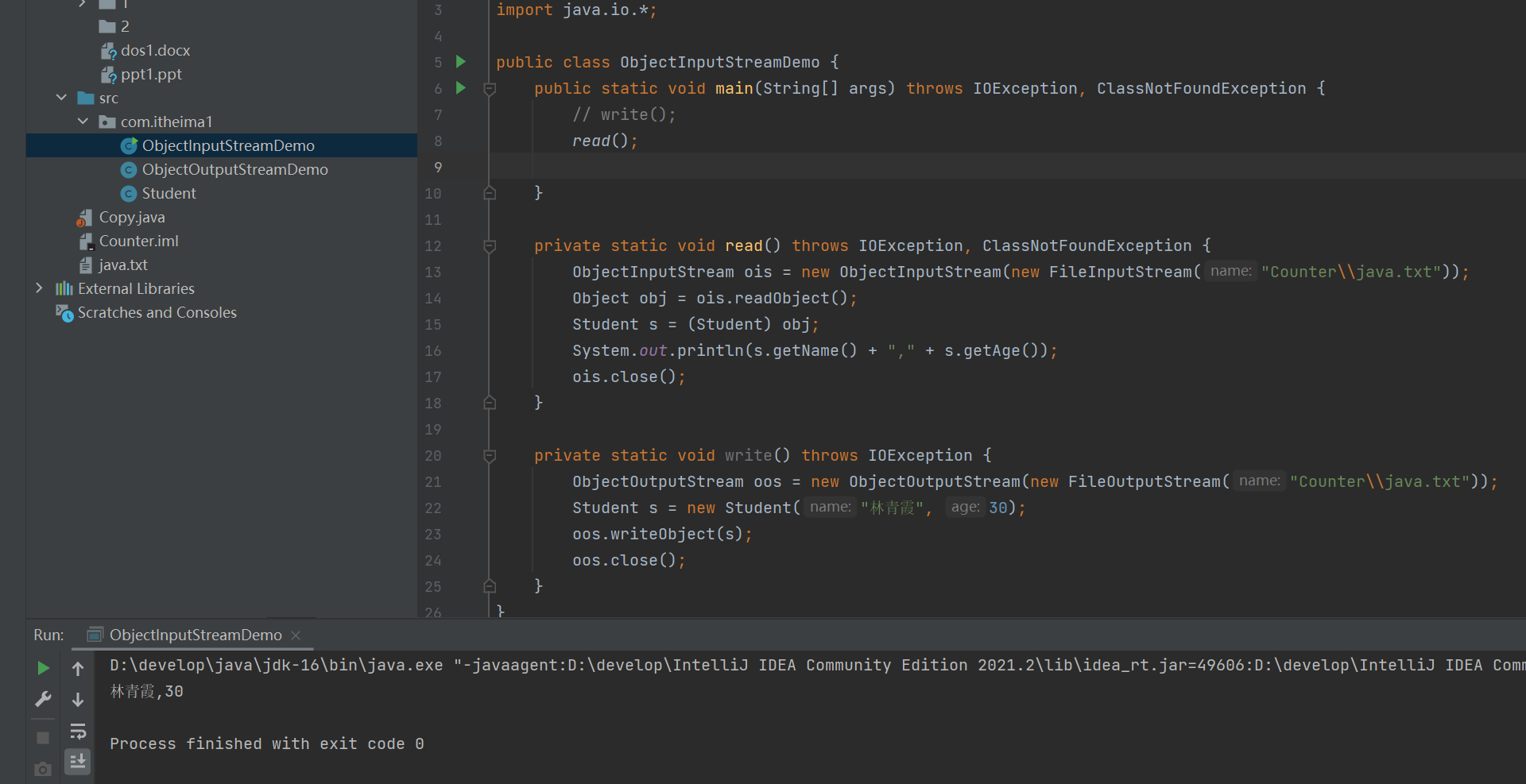
复制SerialVersionUID之后,我们就可以读取文件了。
Properties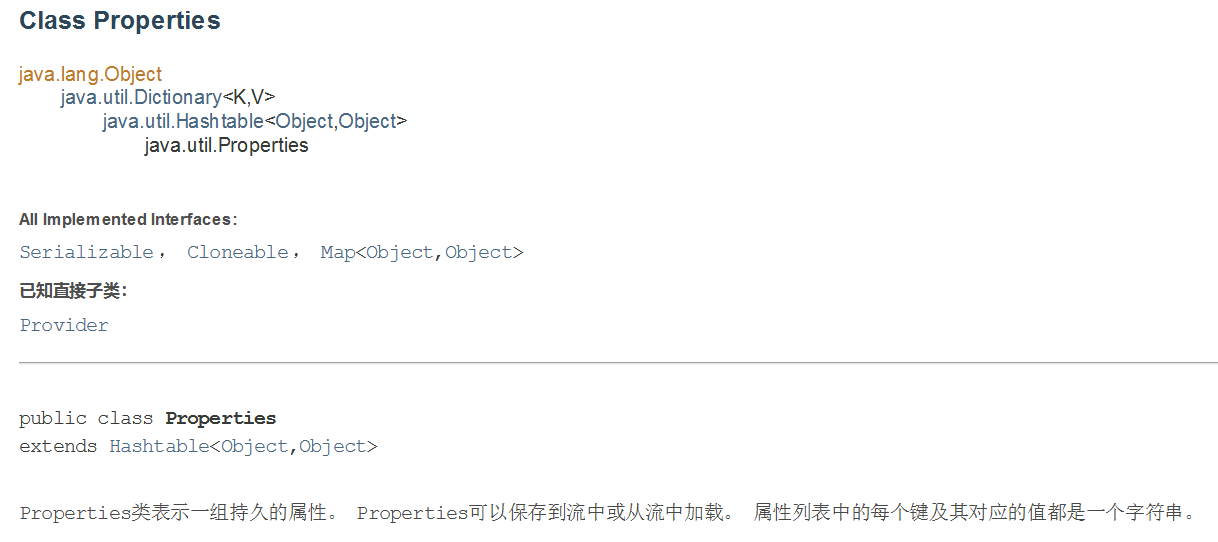


若有收获,就点个赞吧
0 人点赞
