pd.read_csv的功能是读取csv的数据。
其中,seq,header,names是比较重要的参数。
https://zhuanlan.zhihu.com/p/340441922
seq就是读取csv时候的分隔符。
header就是读取的数据的列的索引
names就是给读取的数据的列的索引加名称
6、names:当names没被赋值时,header会变成0,即选取数据文件的第一行作为列名;当 names 被赋值,header 没被赋值时,那么header会变成None。如果都赋值,就会实现两个参数的组合功能。
举个栗子:
1) names 没有被赋值,header 也没赋值:
# 这种情况下,header为0,即选取文件的第一行作为表头 pd.readcsv(‘girl.csv’,delim_whitespace=True)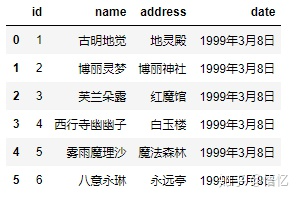
2) names 没有被赋值,header 被赋值:
# 不指定names,指定header为1,则选取第二行当做表头,第二行下面为数据_ pd.read_csv(‘girl.csv’,delim_whitespace=True, header=1)
3) names 被赋值,header 没有被赋值:
pd.read_csv(‘girl.csv’, delim_whitespace=True, names=[“编号”, “姓名”, “地址”, “日期”])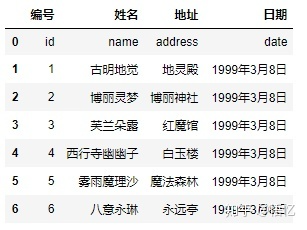
可以看到,names适用于没有表头的情况,指定names没有指定header,那么header相当于None。
一般来说,读取文件的时候会有一个表头,一般默认是第一行,但是有的文件中是没有表头的,那么这个时候就可以通过names手动指定、或者生成表头,而文件里面的数据则全部是内容。所以这里id、name、address、date也当成是一条记录了,本来它是表头的,但是我们指定了names,所以它就变成数据了,表头是我们在names里面指定的。
4) names和header都被赋值:
pd.readcsv(‘girl.csv’, delim_whitespace=True, names=[“编号”, “姓名”, “地址”, “日期”], header=0)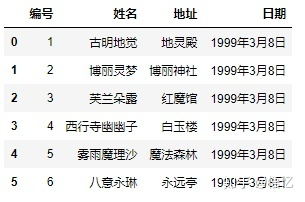
这个时候,相当于先不看names,只看header,header为0代表先把第一行当做表头,下面的当成数据;然后再把表头用names给替换掉。
**所以names和header的使用场景主要如下:_**
1. csv文件有表头并且是第一行,那么names和header都无需指定;
2. csv文件有表头、但表头不是第一行,可能从下面几行开始才是真正的表头和数据,这个时候指定header即可;
3. csv文件没有表头,全部是纯数据,那么我们可以通过names手动生成表头;
4. csv文件有表头、但是这个表头你不想用,这个时候同时指定names和header。先用header选出表头和数据,然后再用names将表头替换掉,就等价于将数据读取进来之后再对列名进行rename;

若有收获,就点个赞吧
0 人点赞
