1、为什么要使用线程池?
线程池做的工作主要是控制运行的线程的数量,处理过程中将任务放入队列,然后再线程创建后启动这些任务如果线程的数量超过最大数量,超过数量的线程将排队等候,等其他线程执行完毕,再从队列中取出任务来执行
特点:线程复用,控制最大并发数,管理线程
- 降低资源消耗。 通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。 当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。 线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控
2、线程执行流程
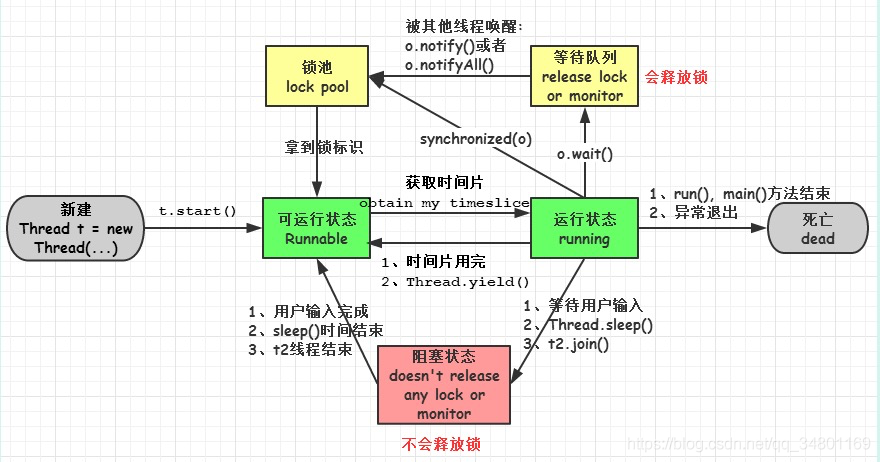
3、线程的五种状态
- 新建状态(New):当线程对象对创建后,即进入了新建状态,如:Thread t = new MyThread();
- 就绪状态(Runnable):当调用线程对象的start()方法(t.start();),线程即进入就绪状态。处于就绪状态的线程,只是说明此线程已经做好了准备,随时等待CPU调度执行,并不是说执行了t.start()此线程立即就会执行;
- 运行状态(Running):当CPU开始调度处于就绪状态的线程时,此时线程才得以真正执行,即进入到运行状态。注:就绪状态是进入到运行状态的唯一入口,也就是说:线程要想进入运行状态执行,首先必须处于就绪状态中;
- 阻塞状态(Blocked):处于运行状态中的线程由于某种原因,暂时放弃对CPU的使用权,停止执行,此时进入阻塞状态,直到其进入到就绪状态,才有机会再次被CPU调用以进入到运行状态。根据阻塞产生的原因不同,阻塞状态又可以分为三种:
- 等待阻塞 — 运行状态中的线程执行wait()方法,使本线程进入到等待阻塞状态;
- 同步阻塞 — 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态;
- 其他阻塞 — 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
- 死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
4、创建线程池的核心参数
1、七大核心参数
- corePoolSize:线程池核心线程数量,核心线程不会被回收,即使没有任务执行,也会保持空闲状态。如果线程池中的线程少于此数目,则在执行任务时创建。
- maximumPoolSize:池允许最大的线程数,当线程数量达到corePoolSize,且workQueue队列塞满任务了之后,继续创建线程。
- keepAliveTime:超过corePoolSize之后的“临时线程”的存活时间。
- unit:keepAliveTime的单位。
- workQueue:当前线程数超过corePoolSize时,新的任务会处在等待状态,并存在workQueue中,BlockingQueue是一个先进先出的阻塞式队列实现,底层实现会涉及Java并发的AQS机制,有关于AQS的相关知识,我会单独写一篇,敬请期待。
- threadFactory:创建线程的工厂类,通常我们会自定一个threadFactory设置线程的名称,这样我们就可以知道线程是由哪个工厂类创建的,可以快速定位。
handler:线程池执行拒绝策略,当线数量达到maximumPoolSize大小,并且workQueue也已经塞满了任务的情况下,线程池会调用handler拒绝策略来处理请求。
2、四大拒绝策略
AbortPolicy:为线程池默认的拒绝策略,该策略直接抛异常处理。
- DiscardPolicy:直接抛弃不处理。
- DiscardOldestPolicy:丢弃队列中最老的任务。
- CallerRunsPolicy:将任务分配给当前执行execute方法线程来处理。
3、三大方法
```java Executors.newSingleThreadExecutor();
Executors.newFixedThreadPool(5);
Executors.newCachedThreadPool();
<a name="bzEr4"></a>### 4、线程池最大值<a name="CiOEJ"></a>#### 1、CPU密集型**cpu 密集型(CPU-bound)线程池设计 最佳线程数=cpu核数或者cpu核数±1**```javaSystem.out.println(Runtime.getRuntime().availableProcessors()); //获取CPU核心数
CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading很高。
在多重程序系统中,大部份时间用来做计算、逻辑判断等CPU动作的程序称之CPU bound。例如一个计算圆周率至小数点一千位以下的程序,在执行的过程当中绝大部份时间用在三角函数和开根号的计算,便是属于CPU bound的程序。
CPU bound的程序一般而言CPU占用率相当高。这可能是因为任务本身不太需要访问I/O设备,也可能是因为程序是多线程实现因此屏蔽掉了等待I/O的时间。
2、I/O密集型
I/O密集型(I/O-bound)线程池设计 最佳线程数 = ((线程等待时间+线程cpu时间)/线程cpu时间cpu数目 2CPU核数
IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操作,此时CPU Loading并不高。
I/O bound的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而pipeline做得不是很好,没有充分利用处理器能力。比如接收一个前端请求—解析参数—查询数据库—返回给前端这样的,那么就是IO密集型的,例如web应用。
3、区别
5、怎么创建线程
1、通过继承Thread类
class Multi extends Thread{public void run(){System.out.println("线程运行中~");}public static void main(String args[]){Multi t1 = new Multi();t1.start();}}//执行结果 -- 线程运行中~//其中,// public void run(): 用于执行线程的操作。// public void start(): 开始执行thread.JVM调用线程上的run()方法。
2、通过实现Runnable接口
public class Multi implements Runnable{public void run() {System.out.println("反手就是一个线程运行中~");}public static void main(String[] args) {Multi m = new Multi();Thread t1 = new Thread(m);t1.start();}}//执行结果 -- 反手就是一个线程运行中~//区别:如果没有继承Thread类,你创建的对象自然不是一个线程对象,所以你要明确创建一个线程类对象,来接收你实现的这个接口。
6、线程池的种类
应用场景
- newCachedThreadPool:一个可以无限扩大的线程池,比较适合处理执行时间比较小的任务。
- newFixedThreadPool:一个固定大小的线程池,可以用于已知并发压力的情况下,对线程数做限制。
- newSingleThreadExecutor:一个单线程的线程池,可以用于需要保证顺序执行的场景,并且只有一个线程在执行。
- newScheduledThreadPool:可以延时启动,定时启动的线程池,适用于需要多个后台线程执行周期任务的场景。
- newWorkStealingPool:一个拥有多个任务队列的线程池,可以减少连接数,创建当前可用cpu数量的线程来并行执行。
1、newCachedThreadPool
作用:创建一个可根据需要创建新线程的线程池,但是在以前构造的线程可用时将重用它们,并在需要时使用提供的 ThreadFactory 创建新线程。
特征:
(1)线程池中数量没有固定,可达到最大值(Interger. MAX_VALUE)
(2)线程池中的线程可进行缓存重复利用和回收(回收默认时间为1分钟)
(3)当线程池中,没有可用线程,会重新创建一个线程
创建方式: Executors.newCachedThreadPool();2、newFixedThreadPool
作用:创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这些线程。在任意点,在大多数 nThreads 线程会处于处理任务的活动状态。如果在所有线程处于活动状态时提交附加任务,则在有可用线程之前,附加任务将在队列中等待。如果在关闭前的执行期间由于失败而导致任何线程终止,那么一个新线程将代替它执行后续的任务(如果需要)。在某个线程被显式地关闭之前,池中的线程将一直存在。
特征:
(1)线程池中的线程处于一定的量,可以很好的控制线程的并发量
(2)线程可以重复被使用,在显示关闭之前,都将一直存在
(3)超出一定量的线程被提交时候需在队列中等待
创建方式:
(1)Executors.newFixedThreadPool(int nThreads);//nThreads为线程的数量
(2)Executors.newFixedThreadPool(int nThreads,ThreadFactory threadFactory);//nThreads为线程的数量,threadFactory创建线程的工厂方式3、newSingleThreadExecutor
作用:创建一个使用单个 worker 线程的 Executor,以无界队列方式来运行该线程。(注意,如果因为在关闭前的执行期间出现失败而终止了此单个线程,那么如果需要,一个新线程将代替它执行后续的任务)。可保证顺序地执行各个任务,并且在任意给定的时间不会有多个线程是活动的。与其他等效的 newFixedThreadPool(1) 不同,可保证无需重新配置此方法所返回的执行程序即可使用其他的线程。
特征:
(1)线程池中最多执行1个线程,之后提交的线程活动将会排在队列中以此执行
创建方式:
(1)Executors.newSingleThreadExecutor() ;
(2)Executors.newSingleThreadExecutor(ThreadFactory threadFactory);// threadFactory创建线程的工厂方式
4、newScheduleThreadPool
作用: 创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行。
特征:
(1)线程池中具有指定数量的线程,即便是空线程也将保留
(2)可定时或者延迟执行线程活动
创建方式:
(1)Executors.newScheduledThreadPool(int corePoolSize);// corePoolSize线程的个数
(2)newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory);// corePoolSize线程的个数,threadFactory创建线程的工厂
5、newSingleThreadScheduledExecutor
作用: 创建一个单线程执行程序,它可安排在给定延迟后运行命令或者定期地执行。
特征:
(1)线程池中最多执行1个线程,之后提交的线程活动将会排在队列中以此执行
(2)可定时或者延迟执行线程活动
创建方式:
(1)Executors.newSingleThreadScheduledExecutor() ;
(2)Executors.newSingleThreadScheduledExecutor(ThreadFactory threadFactory) ;//threadFactory创建线程的工厂
7、怎么创建线程池
《阿里巴巴Java开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
Executors 返回线程池对象的弊端如下:
- FixedThreadPool 和 SingleThreadExecutor : 允许请求的队列长度为 Integer.MAX_VALUE ,可能堆积大量的请求,从而导致OOM。
- CachedThreadPool 和 ScheduledThreadPool : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致OOM。
方式一:通过构造方法实现 
方式二:通过Executor 框架的工具类Executors来实现 我们可以创建三种类型的ThreadPoolExecutor:
- FixedThreadPool : 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
- SingleThreadExecutor: 方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
- CachedThreadPool: 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。

8、自定义线程池
1、使用场景
虽然jdk提供了几种常用特性的线程池给我们,但是很多时候,我还是需要自己去自定义自己需要特征的线程池。并且阿里巴巴规范手册里面,就是不建议使用jdk的线程池,而是建议程序员手动创建线程池。
为什么呢?原文如下
【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
说明:Executors 返回的线程池对象的弊端如下:
1、FixedThreadPool 和 SingleThreadPool:
允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
2、CachedThreadPool 和 ScheduledThreadPool:
允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM
但是除此之外,自己通过ThreadPoolExecutor定义线程池还有很多好处。
比如说,
1.自己根据需求定义自己的拒绝策略,如果线程过多,任务过多 如何处理。
2.补充完善的线程信息,比如线程名,这一点在将来如果出现线上bug的时候,你会感谢自己,因为你绝不想在线上看到什么threa-1 threa-2 等这种线程爆出的错误,而且是看到自己 “处理xxx线程 错误”,可以一眼看到
3.可以通过ThreadPoolExecutor的beforExecute(),
afterExecute()和terminated()方法去拓展对线程池运行前,运行后,结束后等不同阶段的控制。比如说通过拓展打印日志输出一些有用的调试信息。在故障诊断是非常有用的。
4.可以通过自定义线程创建,可以自定义线程名称,组,优先级等信息,包括设置为守护线程等,根据需求。
2、 线程池详解
之前我们在Executors工厂里面看到的方法,
/*newFixedThreadPool 固定线程线程数量的线程池,该线程池内的线程数量始终不变,如果任务到来,内部有空闲线程,则立即执行,如果没有或任务数量大于线程数,多出来的任务,则会被暂存到任务队列中,待线程空闲,按先入先出的顺序处理。该任务队列是LinkedBlockingQueue,是无界队列,如果任务数量特别多,可能会导致内存不足*/public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}/*newSingleThreadExecutor(),该方法返回一个只有一个线程的线程池,多出来的任务会被放到任务队列内,待线程空闲,按先入先出的顺序执行队列中的任务。队列也是无界队列*/public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}
可以看到,本质都是对ThreadPoolExecutor进行封装。
那么强大的ThreadPoolExecutor又是如何使用?
先看构造方法定义
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)
1.corePoolSize 指定了线程池里的线程数量
2.maximumPoolSize 指定了线程池里的最大线程数量
3.keepAliveTime 当线程池线程数量大于corePoolSize时候,多出来的空闲线程,多长时间会被销毁。
4.unit 时间单位
5.workQueue 任务队列,用于存放提交但是尚未被执行的任务。
6.threadFactory 线程工厂,用于创建线程,一般可以用默认的
7.handler 拒绝策略,当任务过多时候,如何拒绝任务。
主要是workQueue和handler的差异比较大
workQueue指被提交但未执行的任务队列,它是一个BlockingQueue接口的对象,仅用于存放Runnable对象。
ThreadPoolExecutor的构造函数中,可使用以下几种BlockingQueue
1.直接提交队列: 即SynchronousQueue ,这是一个比较特殊的BlockKingQueue, SynchronousQueue没有容量,每一个插入操作都要等待对应的删除操作,反之 一个删除操作都要等待对应的插入操作。 也就是如果使用SynchronousQueue,提交的任务不会被真实保存,而是将新任务交给空闲线程执行,如果没有空闲线程,则创建线程,如果线程数都已经大于最大线程数,则执行拒绝策略。使用这种队列,需要将maximumPoolSize设置的非常大,不然容易执行拒绝策略。比如说
没有最大线程数限制的newCachedThreadPool()
public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());}
但是这个在大量任务的时候,会启用等量的线程去处理,有风险造成系统资源不足。
2.有界任务队列。 有界任务队列可以使用ArrayBlockingQueue实现。需要给一个容量参数表示该队列的最大值。当有新任务进来时,如果当前线程数小于corePoolSize,则会创建新线程执行任务。如果大于,则会将任务放到任务队列中,如果任务队列满了,在当前线程小于将maximumPoolSize的情况下,将会创建新线程,如果大于maximumPoolSize,则执行拒绝策略。
也就是,一阶段,当线程数小于coresize的时候,创建线程;二阶段,当线程任务数大于coresize的时候,放入到队列中;三阶段,队列满,但是还没大于maxsize的时候,创建新线程。 四阶段,队列满,线程数也大于了maxsize, 则执行拒绝策略。
可以发现,有界任务队列,会大概率将任务保持在coresize上,只有队列满了,也就是任务非常繁忙的时候,会到达maxsie。
3.无界任务队列。
使用linkedBlockingQueue实现,队列最大长度限制为integer.MAX。无界任务队列,不存在任务入队失败的情况, 当任务过来时候,如果线程数小于coresize ,则创建线程,如果大于,则放入到任务队列里面。也就是,线程数几乎会一直维持在coresize大小。FixedThreadPool和singleThreadPool即是如此。 风险在于,如果任务队列里面任务堆积过多,可能导致内存不足。
4.优先级任务队列。使用PrioriBlockingQueue ,特殊的无界队列,和普通的先进先出队列不同,它是优先级高的先出。
因此 ,自定义线程池的时候,应该根据实际需要,选择合适的任务队列应对不同的场景。
这里给出ThreadPool的核心调度代码
//runnable为线程内的任务public void execute(Runnable command) {//为null则抛出异常if (command == null)throw new NullPointerException();//获取工作的线程数量int c = ctl.get();//数量小于coresizeif (workerCountOf(c) < corePoolSize) {//addWorker 直接执行新线程if (addWorker(command, true))return;c = ctl.get();}//如果大于corsize 则放到等待队列中//workQueue.offer()表示放到队列中if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();if (! isRunning(recheck) && remove(command))reject(command);else if (workerCountOf(recheck) == 0)addWorker(null, false);}//如果放到队列中失败,直接提交给线程池执行//如果提交失败,则执行reject() 拒绝策略else if (!addWorker(command, false))reject(command);}
jdk内置的拒绝策略如下:
拒绝策略
1.AbortPolicy 该策略会直接抛出异常,阻止系统正常工作。
2.CallerRunsPolic 策略:只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务,这样做不会真正的丢弃任务,但是 任务提交线程的性能可能会急剧下降。
3.DisCardOledestPolicy 策略: 该策略默默地丢弃无法处理的任务,不予任务处理,如果允许任务丢失,这是最好的方法了。
jdk内置的几种线程池,主要采用的是AbortPolicy 策略,会直接抛出异常,defaultHandler如下。
private static final RejectedExecutionHandler defaultHandler =new AbortPolicy();
以上内置的策略均实现了RejectedExecutionHandler接口,因此我们也可以实现这个接口,自定义我们自己的策略。
public static class AbortPolicy implements RejectedExecutionHandler {public AbortPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {throw new RejectedExecutionException("Task " + r.toString() +" rejected from " +e.toString());}}
最后的最后,所有的线程池里面,线程是从哪里来的?
答案是ThreadFactory
这个是一个接口,里面只有一个方法,用来创建线程
public interface ThreadFactory {Thread newThread(Runnable r);}
线程池的默认ThreadFactory如下
static class DefaultThreadFactory implements ThreadFactory {private static final AtomicInteger poolNumber = new AtomicInteger(1);private final ThreadGroup group;private final AtomicInteger threadNumber = new AtomicInteger(1);private final String namePrefix;DefaultThreadFactory() {SecurityManager s = System.getSecurityManager();group = (s != null) ? s.getThreadGroup() :Thread.currentThread().getThreadGroup();namePrefix = "pool-" +poolNumber.getAndIncrement() +"-thread-";}public Thread newThread(Runnable r) {Thread t = new Thread(group, r,namePrefix + threadNumber.getAndIncrement(),0);if (t.isDaemon())t.setDaemon(false);if (t.getPriority() != Thread.NORM_PRIORITY)t.setPriority(Thread.NORM_PRIORITY);return t;}}
同理我们也可以通过实现ThreadFactory来定义我们自己的线程工厂,比如说自定义线程名称,组,优先级等信息,可以跟着线程池究竟在何时创建了多少线程等等。
9、线程池的关闭
关闭线程池可以调用shutdownNow和shutdown两个方法来实现
shutdownNow:对正在执行的任务全部发出interrupt(),停止执行,对还未开始执行的任务全部取消,并且返回还没开始的任务列表。
shutdown:当我们调用shutdown后,线程池将不再接受新的任务,但也不会去强制终止已经提交或者正在执行中的任务。
还有一些业务场景下需要知道线程池中的任务是否全部执行完成,当我们关闭线程池之后,可以用isTerminated来判断所有的线程是否执行完成,千万不要用isShutdown,isShutdown只是返回你是否调用过shutdown的结果。
10、execute和submit的区别?
1)execute() 方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;
2)submit() 方法用于提交需要返回值的任务。线程池会返回一个Future类型的对象,通过这个Future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用 get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
11、线程池都有哪几种工作队列
1、ArrayBlockingQueue
是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
2、LinkedBlockingQueue
一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列
3、SynchronousQueue
一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
4、PriorityBlockingQueue
一个具有优先级的无限阻塞队列。
12、 实现Runnable接口和Callable接口的区别
如果想让线程池执行任务的话需要实现的Runnable接口或Callable接口。 Runnable接口或Callable接口实现类都可以被ThreadPoolExecutor或ScheduledThreadPoolExecutor执行。两者的区别在于 Runnable 接口不会返回结果但是 Callable 接口可以返回结果。
备注: 工具类Executors可以实现Runnable对象和Callable对象之间的相互转换。(Executors.callable(Runnable task)或Executors.callable(Runnable task,Object resule))。

若有收获,就点个赞吧
0 人点赞
