1、简单理解
内部使用数组+链表和红黑树结构,key-value的格式,key不可重复,线程不安全。hashmap初始内部数组为null,首次put会进行第一次初始化扩容,长度为16
2、存储原理
通过key的hash值计算和运算计算出存储数组的下标,查看当前下标是否有值,没有值就将key-value封装为一个node对象,判断当前位置的node类型,看是红黑树还是链表,树节点,是创建树节点插入,插入过程中判断key是否相等,相等则覆盖。如果是链表的话,通过尾插加入链表,链表长度大于8时转成红黑树,插入过程中判断key是否相等,相等则覆盖。插入完成判断长度是否大于阈值(默认12 默认长度160.75= 12)阈值= 长度负载因子 ,负载因子默认0.75,大于就扩容为原数组的二倍。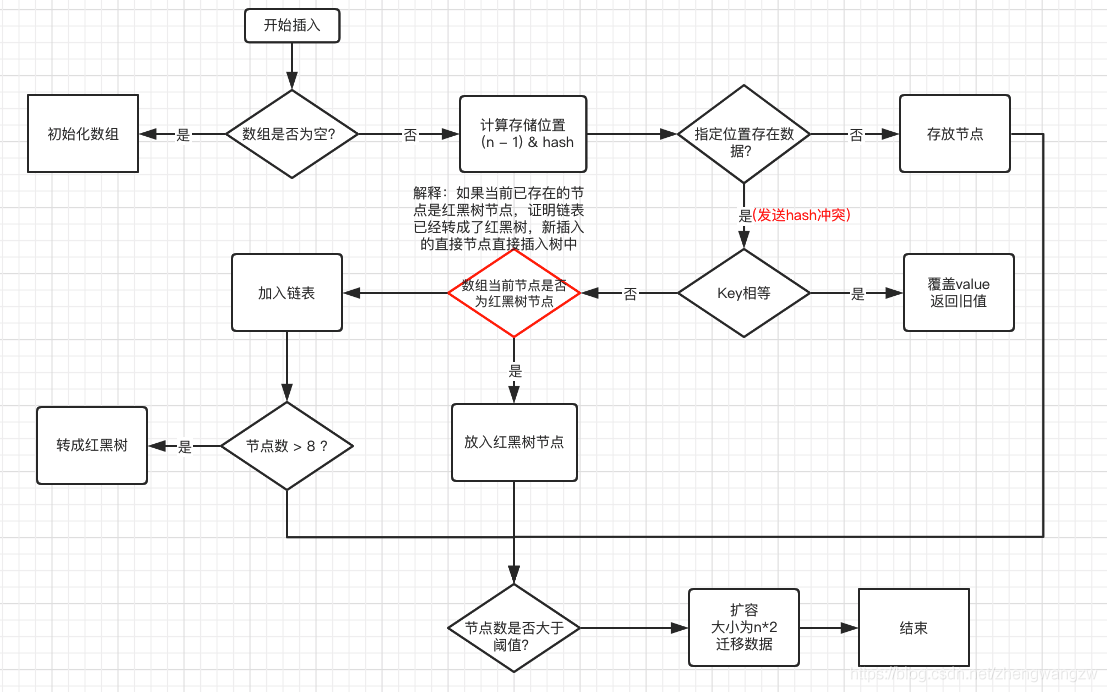
3、HashMap的扩容原理
- 生成新数组
- 遍历旧数组上的每个位置的链表或红黑树
- 链表会将每个元素重新计算下标,并添加新数组
- 红黑树会遍历整个红黑树,计算出每个元素在新数组中对应下标的位置
- 统计每个下标下的数量
- 超过8个就生成红黑树,将根节点添加到新数组的对应位置
- 不超过8个就生成链表,将链表的头节点添加到新数组相应位置
所有元素迁移完成将新数组复制给HashMap的table属性
4、ConcurrentHashMap的扩容机制
1.8版本的ConcurrentHashMap不再基于Segment实现
- 当某个线程进行put时,如果发现ConcurrentHashMap正在进行扩容那么该线程一起进行扩容
- 如果某个线程put时,发现没有正在进行扩容,则将key-value添加到ConcurrentHashMap中,然后判断是否超过阈值,超过了则进行扩容
- ConcurrentHashMap是支持多个线程同时扩容的
- 扩容之前也先生成一个新的数组
- 在转移元素时,先将原数组分组,将每组分给不同的线程来进行元素的转移,每个线程负责一组或多组的元素转移工作

若有收获,就点个赞吧
0 人点赞
