写入流程
新建、索引(这里的索引是动词,指写入操作,将文档添加到Lucene的过程称为索引一个文档)和删除请求都是写操作。写操作必须先在主分片执行成功后才能复制到相关的副分片。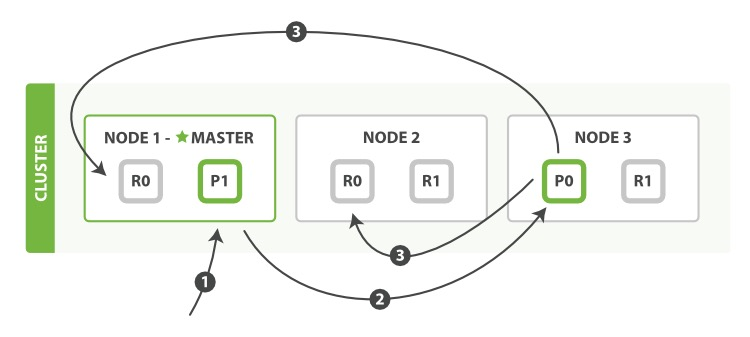
以下是写单个文档所需的步骤:
- 客户端向NODE1发送写请求。
- NODE1使用文档ID来确定文档属于分片0,通过集群状态中的内容路由表信息获知分片0的主分片位于NODE3,因此请求被转发到NODE3上。
- NODE3上的主分片执行写操作。如果写入成功,则它将请求并行转发到NODE1和NODE2的副分片上,等待返回结果。当所有的副分片都报告成功,NODE3将向协调节点报告成功,协调节点再向客户端报告成功。
在客户端收到成功响应时,意味着写操作已经在主分片和所有副分片都执行完成。
写一致性的默认策略是quorum,即多数的分片(其中分片副本可以是主分片或副分片)在写入操作时处于可用状态。
quorum = int( (primary + number of replicas) / 2 ) + 1
查询流程
1. Query阶段
在初始查询阶段,查询会广播到索引中每一个分片副本(主分片或副分片)。每个分片在本地执行搜索并构建一个匹配文档的优先队列。
优先队列是一个存有topN匹配文档的有序列表。优先队列大小为分页参数 from + size.
QUERYTHEN FETCH 搜索类型的查询阶段步骤如下:
- 客户端发送search请求到NODE 3。
- Node3将查询请求转发到索引的每个主分片或副分片中。
- 每个分片在本地执行查询,并使用本地的Term/Document Frequency 信息进行打分,添加结果到大小为 from+size 的本地有序优先队列中。
- 每个分片返回各自优先队列中所有文档的ID和排序值给协调节点,协调节点合并这些值到自己的优先队列中,产生一个全局排序后的列表。
协调节点广播查询请求到所有相关分片时,可以是主分片或副分片,协调节点将在之后的请求中轮询所有的分片副本来分摊负载。
查询阶段并不会对搜索请求的内容进行解析,无论搜索什么内容,只看本次搜索需要命中哪些shard,然后针对每个特定shard选择一个副本,转发搜索请求。
2. Fetch阶段
Query阶段知道了要取哪些数据,但是并没有取具体的数据,这就是Fetch阶段要做的。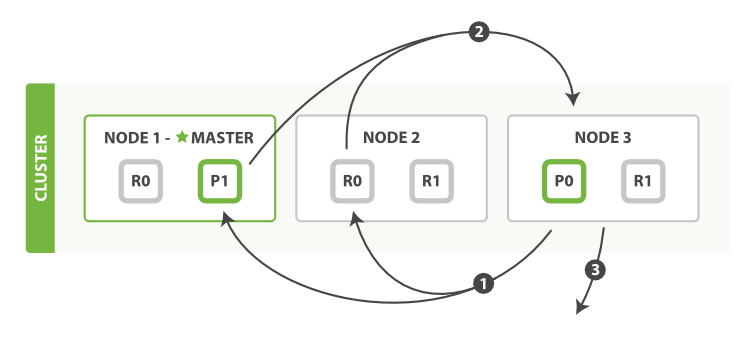
Fetch阶段由以下步骤构成:
- 协调节点向相关NODE发送GET请求。
- 分片所在节点向协调节点返回数据。
- 协调节点等待所有文档被取得,然后返回给客户端。
分片所在节点在返回文档数据时,处理有可能出现的source字段和高亮参数。
协调节点首先决定哪些文档“确实”需要被取回,例如,如果查询指定了 { “from”: 90, “size”: 10}, 则只有从第91个开始的10个结果需要被取回。
为了避免在协调节点中创建的 number_of_shards*(from+size) 优先队列过大,应尽量控制分页深度。

若有收获,就点个赞吧
0 人点赞
