HBase与其他Hadoop部分的关系

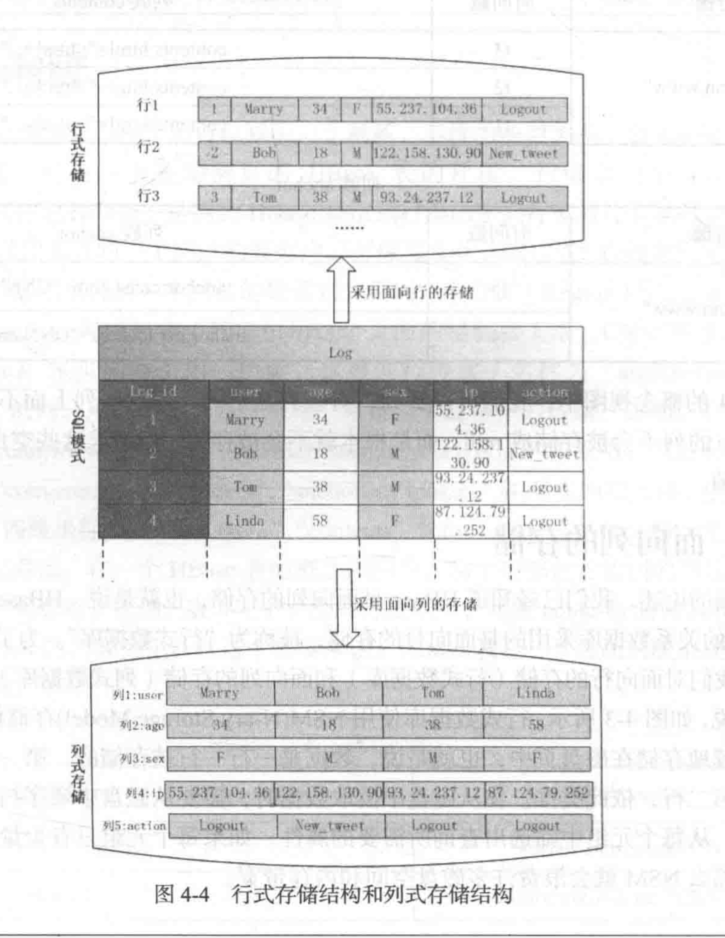
和关系(行式)数据库的对比
- HBase将数据全部存为字符串。数据类型要自己解析
- HBase没有连接操作
- HBase确定一行数据需要用行键、列族、列限定符确定,时间戳默认选最近的。
- HBase不删除旧数据
- 行式数据库使用NSM模型,连续储存在磁盘页中;列式数据库采用DSM模型,以列为单位分解,在连接时代价很大。
- 行式数据库适合于小批量处理,列式数据库适合批量数据处理和即席查询。
数据模型
列限定符类似属性。列族就把类似的属性聚成一团。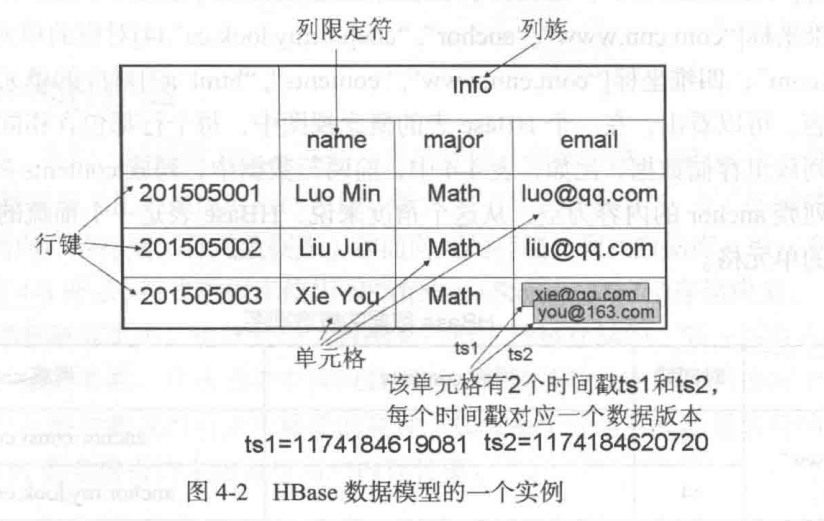
行键是唯一的,但要确定一行数据,需要列族、列限定符和时间戳配合。理解上类似([行键、列族、列限定符、时间戳], 值) 的键值对。
虽然从逻辑理解上HBase存在空列,但实际实现的时候空列并不存在,请求就发返回null。
实现原理与运行机制
HBase包含三个组件:库函数(连接客户端)、一个Master服务器(管理),一堆Region服务器(存储)。
使用Zookeeper获取Region信息,客户端不与Master直接通信,而是隔着Zookeeper。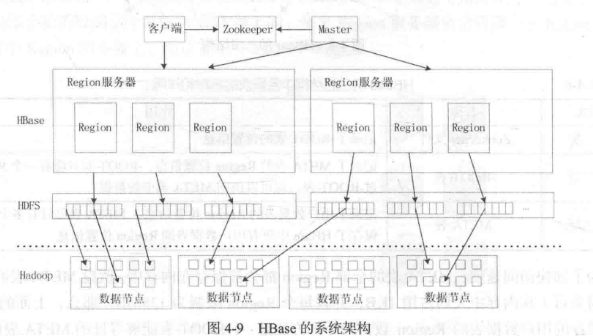
数据会被拆为好几个Region存在不同的Region服务器中,一个Region与一个Region服务器对应,一个Region服务器能存好多个Region。
为了知道Region在Region服务器上的映射,建立META表。但是META表也会太大,所以META表也拆为Region。由ROOT表存储META的Region映射关系,ROOT由Zookeeper管理。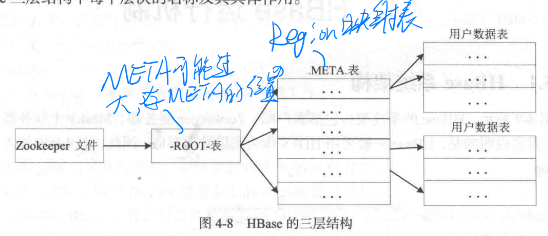
META的Region存在内存中
客户端
管理类通过Zookeeper与Master进行Rpc,读写类与Region服务器进行RPC。
Zookeeper
监控服务器状态,包括Master和Region服务器都监控。
Master
Region服务器
对HDFS(类似文件系统实现也可以)进行读写。
写入时:数据->MemStore->HLog
读取时:请求->MemStore->StoreFile
StoreFile以Hfile的形式存在HDFS上,当大小到了一定程度就会拆分,本质上相当于region的拆分。
一个Region服务器只有一个HLog。服务器上所有的Region公用一个Hlog。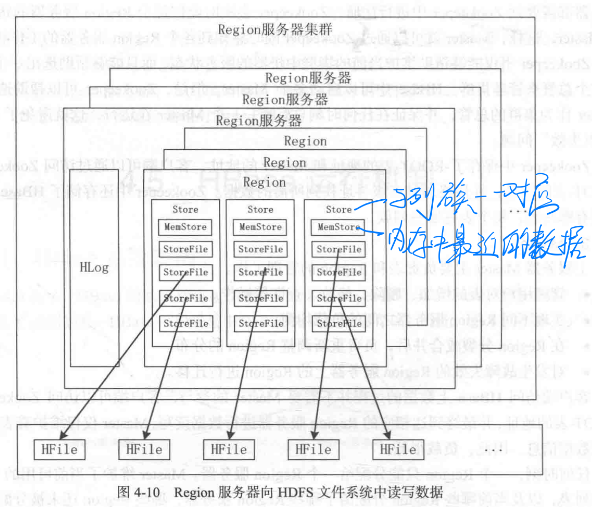

若有收获,就点个赞吧
0 人点赞
