简介
l MapReduce是一种分布式并行编程模型。
l HDFS中的文件会被切分为一个个小数据块提供给Map任务并行处理,其结果提供给Reduce处理,最后输出结果。
l 其设计理念为“计算向数据靠拢”,也就是说Map程序代码会发送到每一个节点上运行,而不是将数据发给Map程序。
l 使用MapReduce需要满足前提:大数据集可以拆分为小数据集完全并行处理,互相之间没有关联。
l Master上运行JobTracker,负责作业调度;Slave上运行TaskTracker,负责执行任务。
Map与Reduce函数
Map函数类似实地干工程的打工仔,Reduce负责将打工仔的信息汇总成结果。
Map
以某种映射分组
输入:文件转换的键值对,输出:给shuffle的键值对。
输入来自与文件数据块,Map根据自定义功能将数据转换为需要归并的键值对。
一般而言Map的输入键值对是<文件的行数, 文本内容>的样式。
Reduce
根据分组进行计算
输入:shuffle处理后的
Map的结果会被Shuffle处理后变成
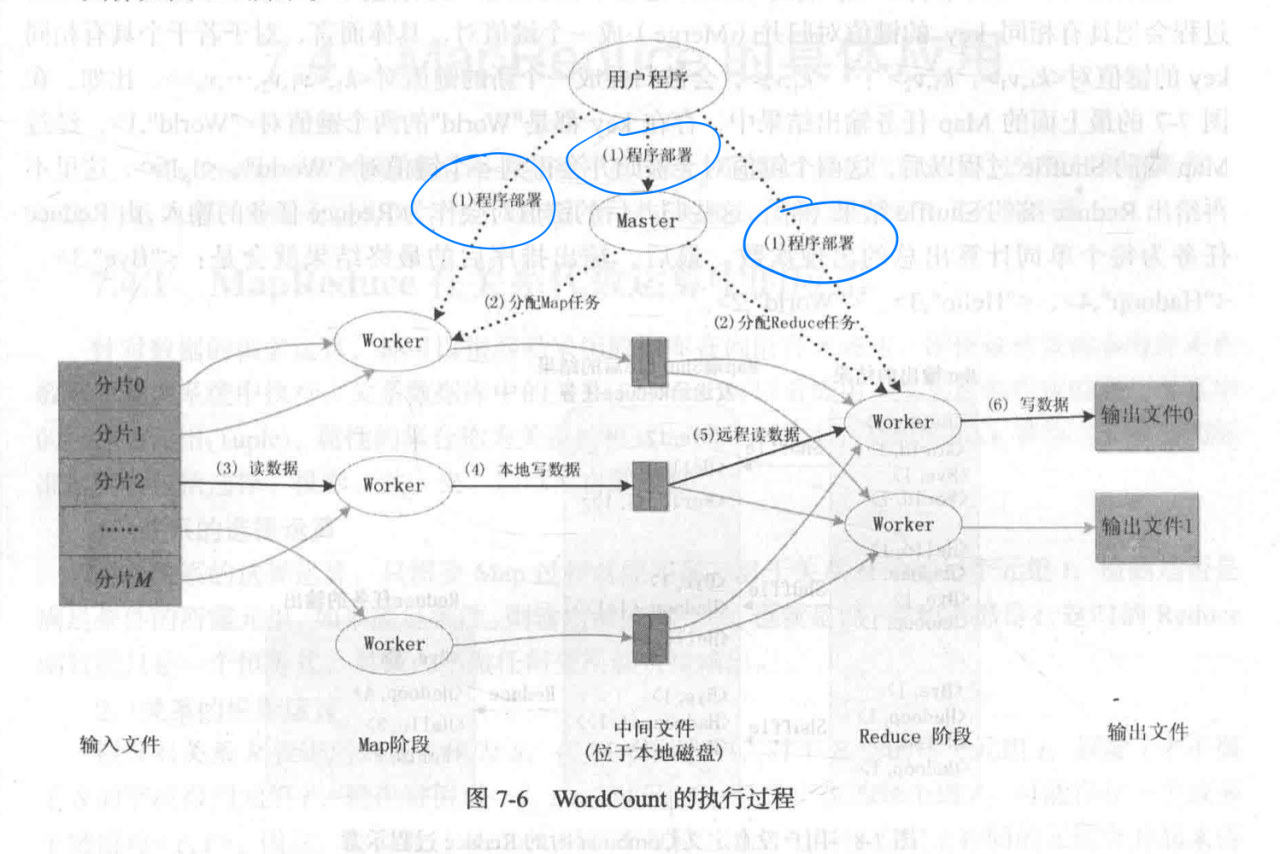
工作流程
执行过程
InputFormt预处理:格式验证、将文件逻辑上切分为InputSplit
↓
用RecordReader(RR)物理切分,形成Map的输入键值对
↓
Map函数自定义映射规则转换
↓
Shuffle对Map的输出键值对进行Partition、Sort、Combine、Merge,变成Reduce的输入
↓
Reduce从多台机器上获取输入,并自定义归并逻辑处理
↓
OutPutFormat负责输出验证与文件写入
Shuffle
Shuffle实际上分为Map端和Reduce端的操作,因此有些图上看不到它。
Map端
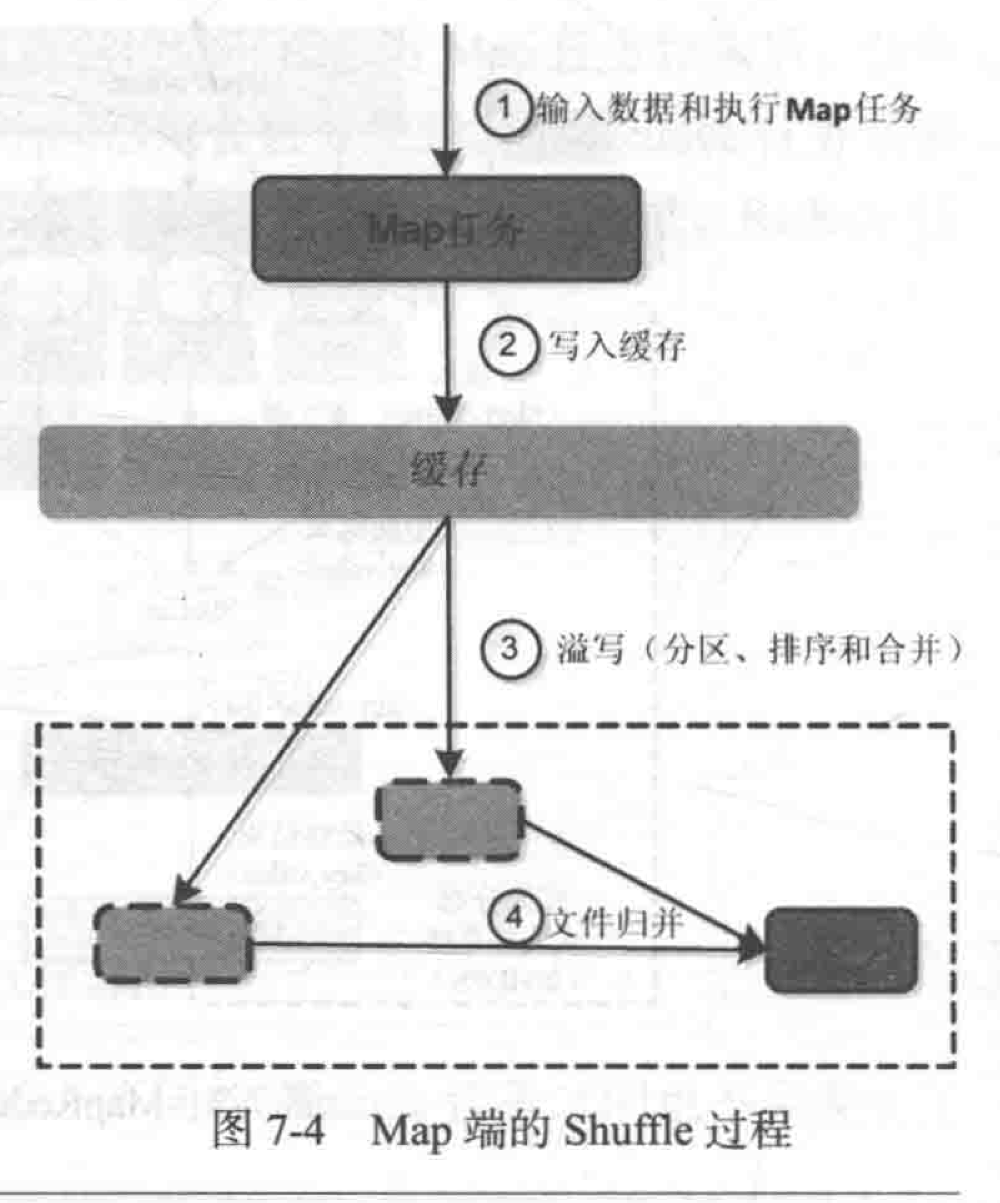
1. 输入数据,执行Map
2. 写入缓存,缓存满了就溢写。
3. 溢写。即Partition、Sort、Combine。每次溢写生成一个溢写文件。Partition默认使用Hash分配保证每个key的任务均匀分配。Combine类似Map端的Reduce操作,因为Reduce取任务要通信,Combine可以避免传输数据过大(非必须)。
4. 溢写的文件会Merge为一个
5. 分区的大文件等Reduce取走。相同key的键值对会被被Merge为一个。
6. JobTracker通知Reduce取货进行预处理。
Reduce端
- 多线程从多台Map机器上领取数据
8. 归并数据。同样有溢写机制。
9. Shuffle预处理结束把数据给Reduce任务,开始真正的Reduce执行。
样例
l 每台机器上都部署程序
l Map机器和Reduce机器是分开的(保证并行)
l 可以考虑使用Combiner优化通信效率
l 各种应用场景需要灵活思考:①我们需要什么样的
实验
和上面红字提到的一样我们思考解决方案时分为两步:
①我们需要什么样的
我只记录思路,题目与具体解析可以参考博客:https://blog.csdn.net/gongsai20141004277/article/details/70146797实验1
最终结果是得到去重后的文本。
① Reduce**中的Key是唯一**的,也就是说没必要用value-list,只要保证key中的值是文本的每一行就行,格式应当是<文本行,<“ ”, “ “, “ “>>
② value-list是多余的,reduce又自带归并去除多余的key,那map直接把每一行按<文本行, “ “>的形式构建即可。实验2
最终结果是排序的数字。
① 因为Reduce是自带key排序的,所以把值放在key上就可以了。但是可能会有多个相同值的情况,所以value-list里应该记录下值的出现次数。那么格式应该是<33, <1, 1, 1, 1>>。
② 这个value-list和WordCount的格式基本一致,所以Map里需要的形成的映射应该是<33, 1>的形式。实验3
最终结果是孙和爷的对照。
① 为了得到a和c是爷孙,我们要知道b是a的爹,且b是c的儿。也就是说类似连接操作,儿将爷和孙连在一起。可以构建<儿, <孙, 爷>>这样的value-list,这样就能在遍历每个儿的时候知道正确的爷孙关系了。但是哪个是爷哪个是孙还需要标记,因此格式应该是<儿, <1+孙, 2+爷>>,这样先后就不会错了。
② 很明显我们需要的是<儿,1+孙>和<儿,2+爷>两种映射。重点是怎么得到儿。为了将儿作为key,我们需要知道即当child又当parent的人。因此将child列和parent列互换。这样再统计的时候,孙和爷都会在儿的value里。

若有收获,就点个赞吧
0 人点赞
