从这章开始就是子领域的介绍了。针对性了解即可。剩余章节不再学习。
概念与处理流程
l 将数据想像成水流,重要的就不是水流的存储,而是如何控制水流的流向,即数据状态的变化。
l 流数据是时间和数量上无限的数据,也就是说在流处理的框架中是没有任务的开始和结束概念的,只有数据的有无才能决定任务的结束(类似触发器)。
l 流数据讲究实时性,用户不需要发出查询,由框架保证数据的最新性。很明显,MapReduce这种结构是没啥速度可言的,即使查询间隔很短。因此就开发了全新的框架(Storm、Flink等)。
l 大多数情况下流数据的框架应该使用非关系数据库保证效率,这些数据库依然可以并行地部署在HDFS上。但是流数据的框架不一定和Hadoop有关。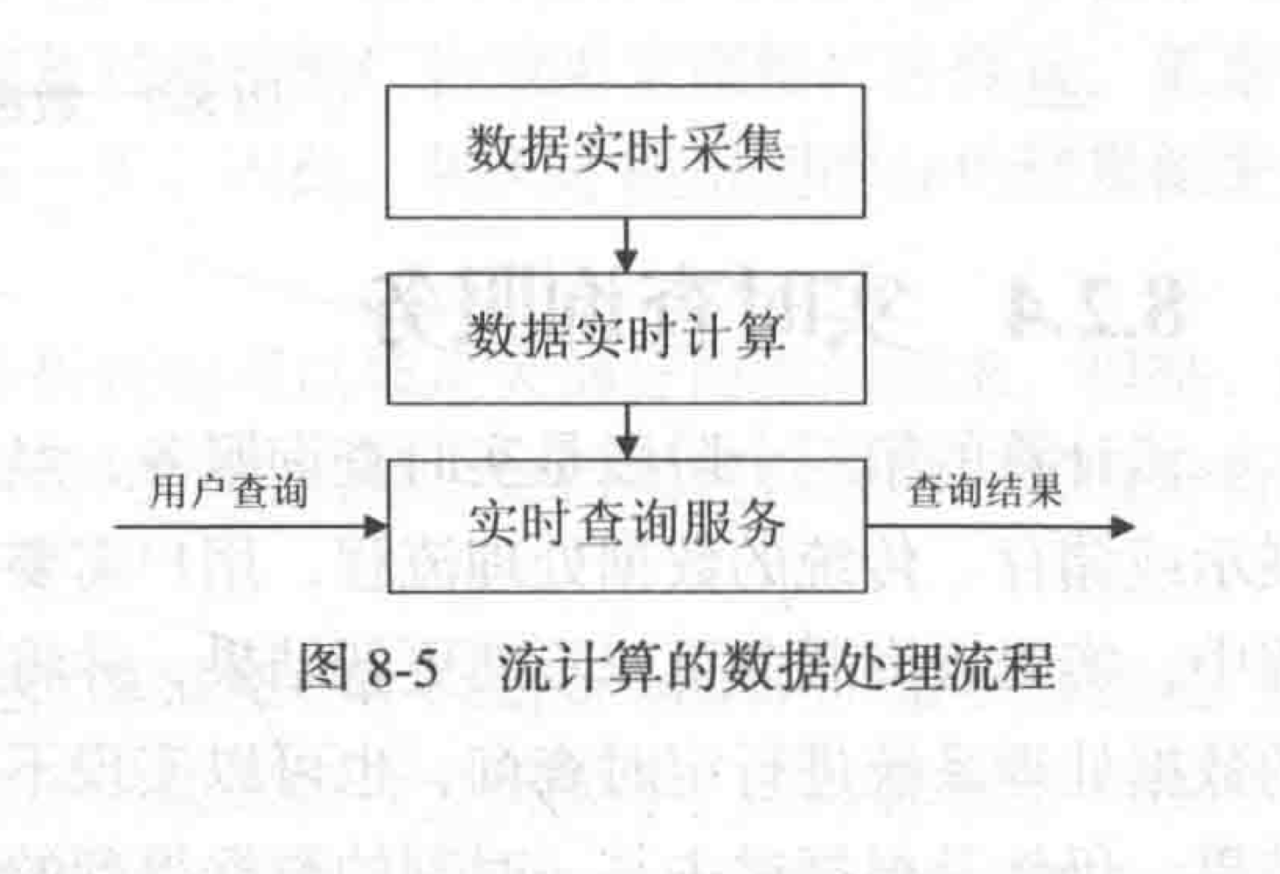
Storm框架
Storm框架是经典流处理框架,略作了解。之后再学习最新的Flink框架。
概念
Stream:数据流,定义为无限的Tuple序列。
Spout:数据的源头。
Bolts:状态转换的过程,自定义函数的核心。
Topology:数据流网络的抽象,运行任务的总体。
StreamGrouping:Tuple传送的方式,有6种不同方式,会在Bolts的定义后出现。
工作流程
Nimbus:类似Hadoop中的JobTracker。
Supervisor:监听工作。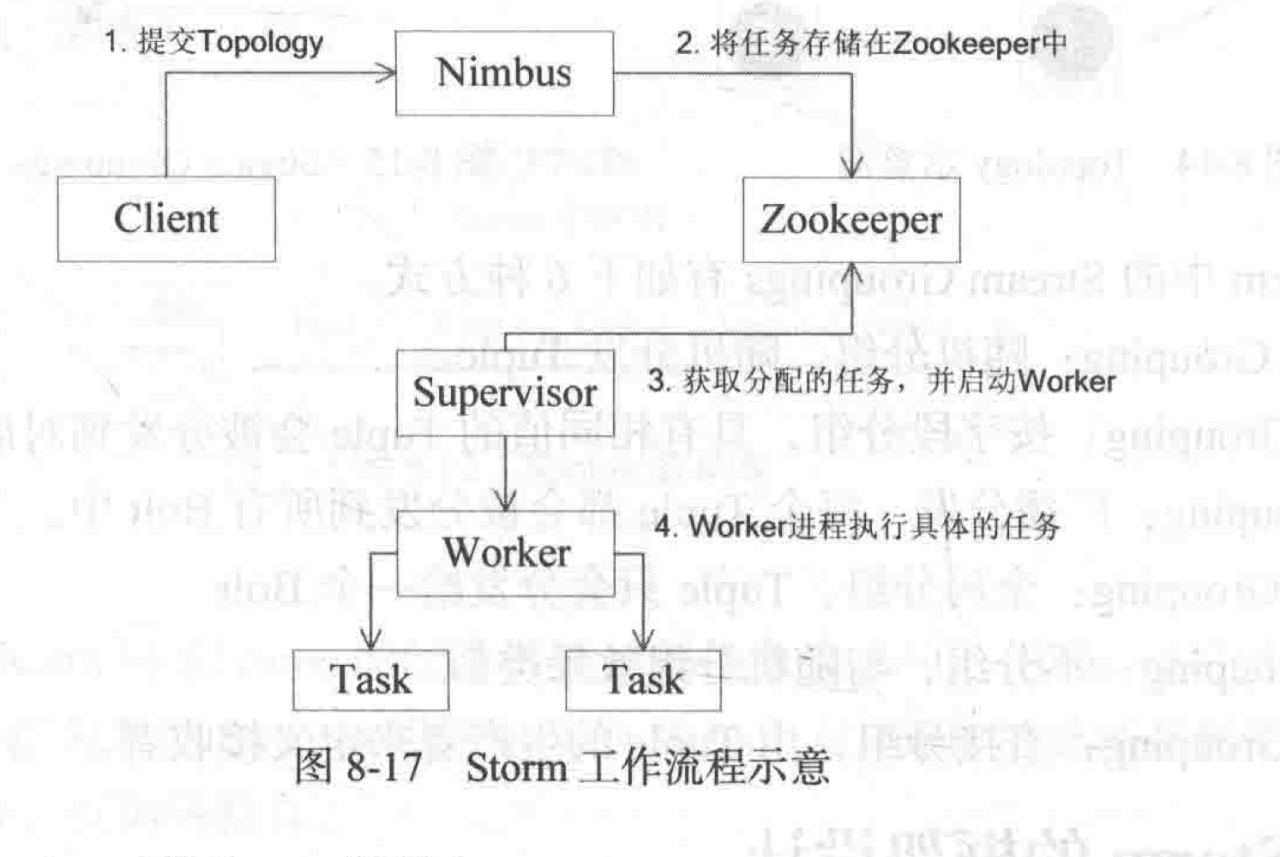

若有收获,就点个赞吧
0 人点赞
