程序1:
编程初体验
下面这个程序 exit.s 实现的功能仅仅是退出而已,如下所示
# 目的:退出并向 Linux 内核返回一个状态码的简单程序# 输入:无# 输出:返回一个状态码,在运行程序后可通过输入 echo $? 来读取状态码# 变量:# %eax 保存系统调用号# %ebx 保存返回状态.section .data.section .text.globl _start_start:mov $1, %eax # 这是用于退出程序的 Linux 内核命令号(系统调用)mov $0, %ebx # 这是我们将返回给操作系统的状态码int $0x80 # 这将唤醒内核,运行退出命令
将上述源文件编译为可执行文件,步骤如下
 汇编程序,输入以下指令
汇编程序,输入以下指令
as exit.s -o exit.o
 链接程序,输入以下指令
链接程序,输入以下指令
ld exit.o -o exit
 执行程序
执行程序
./exit
每个程序退出时都会返回给 Linux 一个退出状态码,执行 exit 程序后后,立即输入 echo $? 可以查看此状态码,如果一切正常,就会返回 0,UNIX 程序如果返回 0 以外的状态码,就表示失败或者其他错误、警告、状态。

程序解释
 注释,使用
注释,使用 # 符号来表示注释
 指令
指令 .section .data 和 .section .text
在上述程序中,有一行为 .section .data。在汇编程序中,任何以小数点符号 . 开始的指令都不会被直接翻译成机器指令,这些针对汇编程序本身的指令,由于是由汇编程序处理,实际上并不会由计算机运行,因此被称为汇编指令或伪操作。
在本程序中,.section 指令将程序分成几个部分。.section .data 命令是数据段的开始,数据段中要列出程序数据所需的所有内存存储空间。由于该程序没有使用任何数据,所以我们不需要这个段。保留这个指令只是为了保留程序的完整性,因为将来的每一个程序都会有数据段。
上述指令之后是:.section .text。这表示文本段开始,文本段是存放程序指令的部分。
 指令
指令 .global _start
在汇编程序中 _start 是一个很重要的符号,它将在汇编或者链接过程中被其他内容替换。符号一般用来标记数据或程序的位置。
.global表示汇编程序不应在汇编以后废弃此符号,因为链接器需要它;_start是个特殊符号,总是用.global来标记,因为它标记了该程序的开始位置。如果不这样标记这个位置,当计算机加载程序时就不知道从哪里开始运行程序。
 指令
指令 _start:
_start:mov $1, %eax # 这是用于退出程序的 Linux 内核命令号(系统调用)mov $0, %ebx # 这是我们将返回给操作系统的状态码int $0x80
上述的指令 _start: 定义了标签 _start 的值。标签 _start 是一个符号,后面跟一个冒号。标签定义一个符号的值。当汇编器对程序进行汇编时,必须为每个数值和每条指令分配地址。标签告诉汇编程序以该符号的值作为下一条指令或下一个数据元素的位置(即,标签 _start 的值为下一条指令 mov $1,%eax 的位置)。
这样,如果数据或指令的实际物理位置更改,无序重写其引用,因为符号会自动获得新值。
 真正的计算机指令:
真正的计算机指令:mov $1, %eax 调用 Linux 内核
当程序运行时,该指令将数字 1 移入 %eax 寄存器。
将数字 1 移入 %eax 是因为我们准备调用 Linux 内核,数字 1 表示系统调用 exit。也就是说我们通过上述指令能够获得操作系统的帮助,正常的程序并非无所不能,许多操作如调用其他程序、处理文件及退出都必须通过系统调用操作系统完成。

进行系统调用时必须将系统调用号加载到 %eax,不同的系统调用可能要求其他寄存器也必须含有含有值。注意,系统调用并非寄存器的唯一或者是主要用途,只是我们上面的程序用到了它的一个功能。
 指令:
指令:mov $0, %ebx 将状态码加载到 %ebx 并且返回给系统
除了知晓进行哪个调用,操作系统还需要更多的信息。例如,在处理文件时,操作系统需要知道你正在处理哪个文件、想要写什么数据和其他相关细节。这些额外的详细信息称为参数,存储在其他寄存器中。
在进行系统调用 exit 的情况下,操作系统需要将状态码加载到 %ebx,然后这个值被返回给系统。而这个值也就是我们后面通过 echo $? 命令提取出的系统返回值。上述指令 mov $0, %ebx 就是把状态码加载到系统中的。
所以我们改变数值,mov $3, %ebx 将状态码 3 加载到系统中,则最后系统返回值为 3,如下图所示

但是这些数字加载到寄存器后本身不会做任何事。系统调用之外的各类事务也要用到寄存器,它们是执行加、减、比较等所有程序逻辑的地方。
Linux 只需要在系统调用前将某些参数值加载到某些寄存器中,通常我们需要将系统调用号加载到 %eax,而对于其他寄存器,每个系统调用有不同要求。
旧系统调用 exit 而言,它要求将退出状态加载到 %ebx,关于通用系统调用列表机器对寄存器的要求,参见这里
 指令:
指令:int $0x80 中断
int 代表中断,0x80 是要用到的中断号。中断会中断正常的程序流,把控制权从我们的程序转到 Linux,因此系统将进行系统调用。当系统程序完成后,控制权再度回到程序手中。
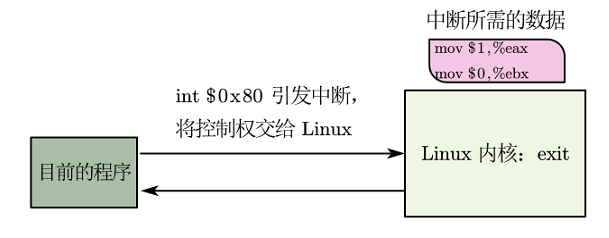
但是,本次我们所作的 Linux 终止程序,最终不会再度获得控制权。而如果我们不发出中断信号,系统调用就不会被执行。
程序2:
查找最大值
下面的程序 maximum.s 能够查找一组数中的最大值
# 目的:本程序寻找一组数据项中的最大值# 变量:寄存器有以下用途:# %edi - 保存正在检测的数据项索引# %ebx - 当前已经找到的最大数据项# %eax - 当前数据项# 使用以下内存位置:# data_items - 包含数据项# 0表示数据结束.section .datadata_items:.long 3, 67, 34, 222, 45, 75, 54, 34, 44, 33, 22, 11, 66, 0.section .text.global _start_start:movl $0, %edi # edi 中保存数组的索引movl data_items(, %edi, 4), %eax # 加载数据的第一个字节到 eax 寄存器movl %eax, %ebx # 将数据发送到最大值寄存器 ebxstart_loop: # 通过检测是否到达数组末尾元素 0cmpl $0, %eax # 从而检测是否到达数据末尾je loop_exit # 如果到达末尾,跳转到 loop_exitincl %edi # 如果没有到达末尾,加载下一个值movl data_items(, %edi, 4), %eaxcmpl %ebx, %eax # 比较值jle start_loop # 若新数据项不大于原最大值,则跳到循环起始处movl %eax, %ebx # 若新数据项小于原最大值,将新值移入最大值寄存器 ebxjmp start_loop # 跳到循环起始处loop_exit:# %ebx 是系统调用 exit 的状态码# 已经存放了最大值movl $1, %eax # 1是exit()系统调用int $0x80
现在将上述源文件进行编译链接:
as maximum.s -o maximum.o # 汇编ld maximum.o -o maximum # 链接
之后,我们运行程序,并且使用 echo $? 查看其状态

上面的程序返回值为:222。为什么呢?
这是因为我们的 %ebx 保存的是数组的最大值,而程序的返回值便存储在 %ebx中,所以最后通过 echo $? 得到的结果为 222.
程序解释
 数据类型和大小
数据类型和大小
上述符号 .long 会让汇编程序为该符号之后的数字列表保留内存,data_items 是指第一个数字的位置。因为 data_items 是标签,在我们的程序中每当需要引用这个地址时,就可以使用 data_items 符号。
除了上述的 .long,还有几种其他类型的数据,如下所示:
- .byte:每个字节类型的数字占用一个存储位置,数字范围为 28 = 0~255
- .int:每个整型数字占用两个储存位置,数字范围为 216=0~65535
- .long:长整型占用 4 个存储位置(即 4 个字节),与寄存器使用的空间相同,数字范围 232=0~4294967295
- .ascii:用于将字符输入内存,每个字符占用一个存储位置(即 1 个字节),如下所示。
.ascii "Hello,World!\0" # 包含 \0 结束符共 12 个字符
 是否将符号设置为
是否将符号设置为 .global
在上面的程序中,我们并没有将符号 data_items 设置为 .global,这是因为我们只在本程序中引用这些位置,其他任何文件或程序都不需要直到它们的位置。
_start 符号与此相反,Linux 需要直到它在哪里,这样才能直到程序从哪里开始执行。用 .global data_items 也不算错,只是这么做没有必要。
 退出码的大小
退出码的大小
上述我们的数据为
.section .datadata_items:.long 3, 67, 34, 222, 45, 75, 54, 34, 44, 33, 22, 11, 66, 0
最终的退出码大小 (%ebx)=222,但是如果这个退出码的大小大于 255 的话,最终将会出现奇怪的结果.
比如,我们将上面的数据修改一下,让它的最大值为 2222.
.section .datadata_items:.long 3, 67, 34, 222, 45, 75, 54, 34, 44, 33, 22, 11, 66, 0
最终程序的退出码返回的是 174,并不是预期的 2222.

 难理解的指令:
难理解的指令:movl data_items(, %edi, 4), %eax
这一行代码的意思是:从 data_items 所在的位置开始,取第 %edi 项的数字(这里是第一项,因为 %edi=0),而要取得数据大小为 4 个字节(4 个存储位置),并将数字存储到 %eax。
该指令得通用格式如下:
movl 起始地址(, %索引寄存器, 字长)
这个便是计算机得一种寻址方式
计算机寻址方式
上面我们用到了内存地址引用的,而引用的通用格式如下:
地址或偏移 (%基址寄存器, %索引寄存器, 字长)
而得到得结果地址为
地址或偏移以及字长必须是常量,其余两个必须是寄存器。如果忽略任何一项,将以 0 来代替。
而下面的几种寻址方式都是上述通用格式的特殊形式:
 直接寻址方式:通过使用地址或偏移部分实现,示例:
直接寻址方式:通过使用地址或偏移部分实现,示例:
movl ADDRESS, %eax
以上指令将内存地址 ADDRESS 加载到 %eax。
 索引寻址方式:通过使用地址或偏移部分 + %索引寄存器部分实现。
索引寻址方式:通过使用地址或偏移部分 + %索引寄存器部分实现。
通过将索引寄存器的比例因子值常量定位 1、2 或 4,使之更适合字节、双字节和字进行索引。例如,我们有一个名为 string_start 的字节串,并想访问其中第三个字节(由于从 0 开始计数,索引为 2),%ecx 中保存值 2。如果想将其加载到 %eax中,通过如下指令实现:
movl string_start(, %ecx, 1), %eax
该指令的结果地址为:string_start + 1 * %ecx,将该结果地址中的数加载到 %eax 中。
 间接寻址方式:从寄存器指定的地址加载值。
间接寻址方式:从寄存器指定的地址加载值。
例如,如果 %eax 保存着一个地址,可以通过如下操作将地址中的值移入 %ebx:
movl (%eax), %ebx
 基址寻址方式:基址寻址方式与间接寻址方式类似,不同之处在于它将一个常量值与寄存器中的地址相加。
基址寻址方式:基址寻址方式与间接寻址方式类似,不同之处在于它将一个常量值与寄存器中的地址相加。
例如,如果某个值位于起始地址后 4 字节处,而起始地址在 %eax 中,则通过如下指令实现
movl 4(%eax), %ebx
 立即寻址方式
立即寻址方式
对立即数进行操作,很简单
movl $12, %eax
 寄存器寻址方式
寄存器寻址方式
寄存器寻址方式仅仅是将数据移入或移出寄存器。

若有收获,就点个赞吧
0 人点赞
