神经网络的基本结构
卷积层
- Conv2d()函数:
- in_channels : 输入数据通道数
- out_channels : 输出数据通道数
- kernel_size : 卷积核的大小
- stride : 步长
- padding : 填充大小
- 示例代码:
import torchimport torchvisionfrom torch.utils.data import DataLoaderfrom torch import nnfrom torch.nn import Conv2dfrom torch.utils.tensorboard import SummaryWritertest_dataset = torchvision.datasets.CIFAR10(root="./download_data",train=False,transform=torchvision.transforms.ToTensor(),download=True)dataloader = DataLoader(test_dataset,batch_size=64)class SecondTime(nn.Module):def __init__(self):super().__init__()self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)def forward(self,input):input = self.conv1(input)return inputsecond = SecondTime()# print(second)writer = SummaryWriter("logs")step = 0for data in dataloader:img,label = dataoutput = second(img)for i in range(10):output = torch.reshape(img, (-1,3,32,32)) # 第一个参数不知道该如何设置时可以设置为-1output =second(output)# img = torch.reshape(img,(-1,3,32,32))print(img.shape) # torch.Size([64, 3, 32, 32])writer.add_images("input",img,step)output = torch.reshape(img, (-1,3,32,32)) # 第一个参数不知道该如何设置时可以设置为-1print(output.shape) # torch.Size([64, 6, 30, 30])writer.add_images("output",output,step)# 因为conv2d中设置了不同的channel数,所以channel改变为6step+=1
池化层
- 池化类似于卷积,也是输入图像后利用池化核进行矩阵运算
- MaxPool2d
- stride : 默认值等于池化核的大小,类似于步长
- padding : 和卷积层一样
- dilation : 具体GIF图演示:GIF图演示
- 池化层的作用:保留数据的特征并且减少数据量,为了提高计算速度
一个通俗的解释:视频的输入格式为1080p输出为720p就类似于一个池化过程,
减少了数据量,加速了数据的传播 - 示例代码:
import torchimport torchvisionfrom torch import nnfrom torch.nn import modules, MaxPool2dfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWritertest_dataset = torchvision.datasets.CIFAR10(root="./download_data",train=False,transform=torchvision.transforms.ToTensor(),download=True)dataloader = DataLoader(test_dataset,batch_size=64)input = torch.tensor([[1,2,0,3,1],[0,1,2,3,1],[1,2,1,0,0],[5,2,3,1,1],[2,1,0,1,1]],dtype=torch.float32) # 要加上float32类型,否则会报类型错误input = torch.reshape(input,(-1,1,5,5)) # channel=1,h=5,w=5print(input.shape)class max_pool(nn.Module):def __init__(self):super(max_pool,self).__init__()# self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=False)# ceil_mode 的用处自己去查def forward(self,input):output = self.maxpool1(input)return outputtest_pool = max_pool()# output = test_pool(input)# print(output)writer = SummaryWriter("logs")step = 0for data in dataloader:img,label = data# img = torch.reshape(img,(-1,1,32,32))writer.add_images("pool",img,step)output = test_pool(img)writer.add_images("pool_after",output,step)# 可以看到输出效果,图片被马赛克处理了一般step += 1writer.close()
非线性激活
ReLU(inplace = bool)
- inplace=True时,不对原变量进行替换,直接更改原变量的值
- inplace=False时,对原变量进行替换,生成一个新的变量
- ReLU示例代码:
import torchfrom torch import nnfrom torch.nn import ReLUinput = torch.tensor([[1,-0.5],[-1,3]])input = torch.reshape(input,(-1,1,2,2))print(input)class nn_relu(nn.ReLU):def __init__(self):super(nn_relu,self).__init__()self.relu = ReLU(inplace=True)def forward(self,input):input = self.relu(input)return inputnn = nn_relu()output = nn(input)print(output)
Sigmoid()
- 无参数
- 示例代码:
import torchimport torchvisionfrom torch import nnfrom torch.nn import ReLU, Sigmoidfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriter'''input = torch.tensor([[1,-0.5],[-1,3]])input = torch.reshape(input,(-1,1,2,2))print(input)'''test_dataset = torchvision.datasets.CIFAR10(root="./download_data",train=False,transform=torchvision.transforms.ToTensor(),download=True)dataloader = DataLoader(test_dataset,batch_size=64)class nn_relu(nn.ReLU):def __init__(self):super(nn_relu,self).__init__()self.relu = ReLU(inplace=True)self.sigmoid = Sigmoid()def forward(self,input):# input = self.relu(input)input = self.sigmoid(input)return inputnn = nn_relu()writer = SummaryWriter("logs")step = 0for data in dataloader:img,label = dataimg = torch.reshape(img,(-1,3,32,32))writer.add_images("sigmoid",img,step)output = nn(img)writer.add_images("sigmoid2",output,step)# 注意是images# 显示效果为:图片整体颜色变灰色step += 1writer.close()
线性层LinearLayers
- 线性变化,简单的形容就是把一个矩阵拉长成一条线
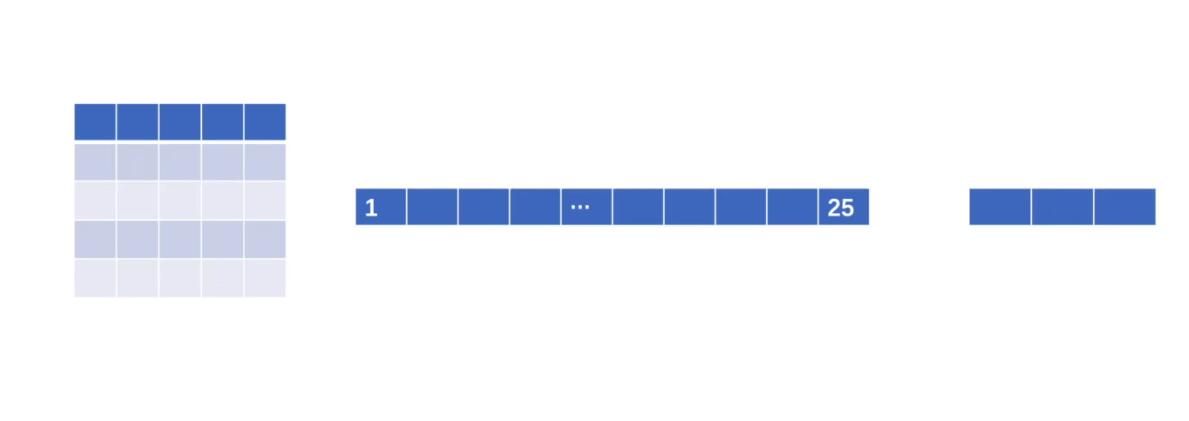
- torch.flatten(img) : 把一个矩阵摊平
- 示例代码:
import torchimport torchvisionfrom torch import nnfrom torch.nn import ReLU, Sigmoid, Linearfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWritertest_dataset = torchvision.datasets.CIFAR10(root="./download_data",train=False,transform=torchvision.transforms.ToTensor(),download=True)dataloader = DataLoader(test_dataset,batch_size=64)class linear(nn.Module):def __init__(self):super(linear,self).__init__()self.linear = Linear(196608,10)def forward(self,input):input = self.linear(input)return inputl = linear()for data in dataloader:img,label = dataprint(img.shape)# img = torch.reshape(img,(1,1,1,-1))output = torch.flatten(img)print(output.shape)output = l(output)print(output.shape)'''运行结果:torch.Size([64, 3, 32, 32])torch.Size([196608])torch.Size([10])图片最后被拉平为10'''
Sequential 结合实战
- 可以简化代码:
import torchfrom torch import nnfrom torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequentialfrom torch.utils.tensorboard import SummaryWriterclass Liucy(nn.Module):def __init__(self):super(Liucy,self).__init__()'''self.conv = Conv2d(3,32,5,padding=2)self.max_pool = MaxPool2d(2)self.conv2 = Conv2d(32,32,5,padding=2)self.max_pool2 = MaxPool2d(2)self.conv3 = Conv2d(64,32,5,padding=2)self.max_pool3 = MaxPool2d(2)self.flatten = Flatten()self.linear1 = Linear(1024,64)self.linear2 = Linear(64,10)'''self.modle = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self,x):'''x = self.conv(x)x = self.max_pool(x)x = self.conv2(x)x = self.max_pool2(x)x = self.conv3(x)x = self.max_pool3(x)x = self.flatten(x)x = self.linear1(x)x = self.linear2(x)'''x = self.modle(x)return xliu = Liucy()print(liu)x = torch.ones((64,3,32,32))output = liu(x)print(output.shape)writer = SummaryWriter("logs")writer.add_graph(liu,x)writer.close()

若有收获,就点个赞吧
0 人点赞
