(一)Java
如何去重10亿手机号码?
手机号码一共11位,第一位都是1,所以我们只需要存储后10位(中国大陆)
常规数组
常规数组:使用String存储一个手机号码共计需要10(字节)8(位) = 80 位
那么10亿个手机号码需要消耗80 10亿 / (8 1024 1024) = 9537M = 9.5 G内存
如果使用Long存储,因为一个Long只需要8个字节,那么消耗 9.5 * 0.8 = 7.6G内存
同时遍历的时间复杂度达到10E,所以平时我们去重的方法是不可行的。
HashSet
HashSet:HashSet其实使用HashMap进行存储,HashMap每个Node节点除了要记录当前的K-V以外,还需要记录一个int型的hash值,以及Node型的next,因此至少需要15G内存。
BitMap (Java中为BitSet)
BitMap:BitMap的思想是用一个Bit数组,数组每个位置的索引就表示手机号(如果出现了当前索引对应的手机号则该bit位为1,否则为0),所以10位手机号共需要长度为99亿;也就是说我们需要用99亿个bit来存储10亿个电话号码,此时需要花费的内存为:99亿/(8 1024 1024)=1.2G
Java实现 BitSet
Java中是没有Bit数据类型的,那么如何实现呢?Java中提供一个类BitSet (java.util包)实现了BitMap。其底层是使用long[] words,也就是说一个long对应了BitMap中的64个bit。
现在我们使用BitSet和分桶实现号码的存储,去重
public class BitMap {public static void main(String[] args) {BitSet bitSet = new BitSet();bitSet.set(5);System.out.println(bitSet.get(5)); // trueSystem.out.println(bitSet.get(4)); // false// 132 44587123bitSet.set(3244587123); // set方法只能传入一个int数值,除去开头的1,10位手机号数值超过了int范围 报错// 解决方法:分桶// 132 44587123// 我们将11位手机号码的前三位分为一个号码段用String存储,后8位作为标识放在BitSet中// 用HashMap来存储号码段和后8位实现分桶HashMap<String, BitSet> map = new HashMap<>();BitSet bitSet132 = map.computeIfAbsent("132", k -> new BitSet());bitSet132.set(44587123); // 8位数不会超过int范围,且一个号码段下只需要 12M的内存来存储号码// 假设有50个号码段,那么存储所有电话号码只需要 50 * 12 = 600 M 内存}}
synchronized关键字的底层原理
修饰同步代码块
public class Phone1 {public void hello() {synchronized (Phone1.class) {System.out.println("-------hello");}}}
看一下用同步代码块修饰的字节码文件: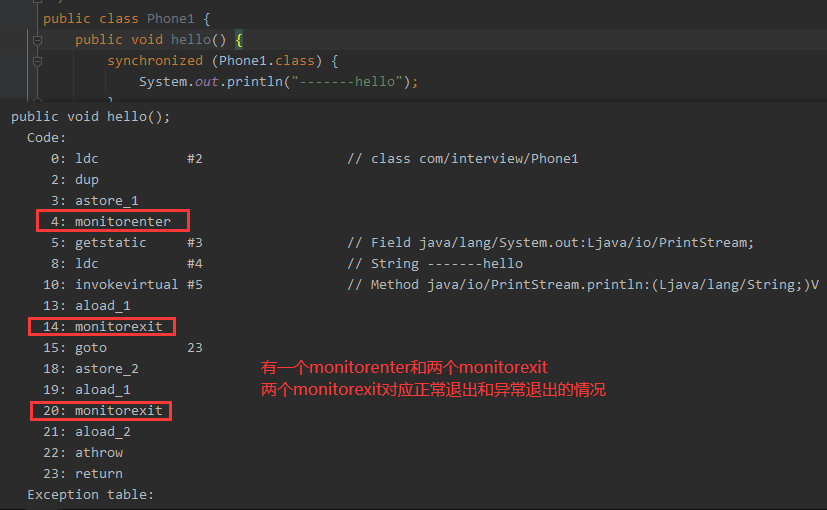
synchronized 同步语句块的实现,使用的是 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置,monitorexit 指令则指明同步代码块的结束位置。 当执行 monitorenter 指令时,线程试图获取锁,也就是获取 monitor ( monitor 对象存在于每个 Java 对象的对象头中,synchronized 锁便是通过这种方式获取锁的,这也是为什么 Java 中任意对象都可以作为锁的原因) 的持有权。当计数器为0,则可以成功获取,获取后将锁计数器设为1,也就是加1;相应的,在执行 monitorexit 指令后,将锁计数器设为0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
修饰同步方法
public synchronized void sendSMS() throws Exception {System.out.println("-------sendSMS");}
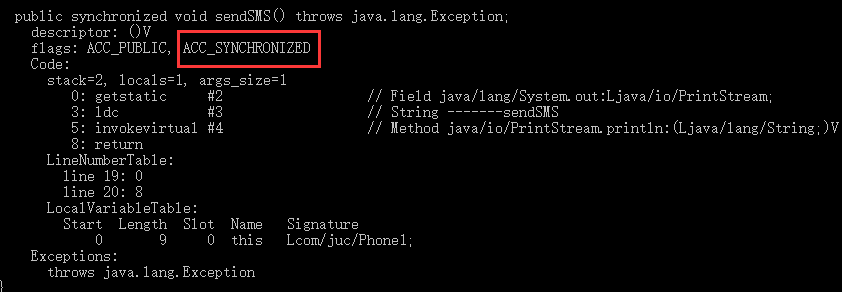
synchronized 修饰方法,并没有 monitorenter 指令和 monitorexit 指令,取得代之的是 ACC_SYNCHRONIZED 标识,该标识指明了该方法是一个同步方法,JVM 通过该 ACC_SYNCHRONIZED 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
说一说你对volatile关键字的理解
https://www.cnblogs.com/Mainz/p/3556430.html
volatile用于保证内存的可见性,可以将其看做是轻量级的锁,它具有如下的内存语义:
- 写内存语义:当写一个volatile变量时,JMM会把该线程本地内存中的共享变量的值刷新到主内存中。
- 读内存语义:当读一个volatile变量时,JMM会把该线程本地内存置为无效,使其从主内存中读取共享变量。
其中,JMM是指Java内存模型,而本地内存只是JMM的一个抽象概念,它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。在本文中,大家可以将其简单理解为缓存。
volatile只能保证单个变量读写的原子性,而锁则可以保证对整个临界区的代码执行具有原子性。所以,在功能上锁比volatile更强大,在可伸缩性和性能上volatile更优优势。
加分回答
volatile的底层是采用内存屏障来实现的,就是在编译器生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。内存屏障就是一段与平台相关的代码,Java中的内存屏障代码都在Unsafe类中定义,共包含三个方法:LoadFence()、storeFence()、fullFence()。
Serializable接口为什么需要定义serialVersionUID常量
serialVersionUID是序列化版本,为一个类定义序列化版本,是出于兼容性的考虑。如果某个类随着项目进行了升级,那么对于升级之前序列化的数据,在升级之后反序列化时就很可能出现不兼容的情况。如果事先定义了序列化的版本,则在反序列化的时候,只要版本不变就可以将其认定为同一个class文件。
需要注意的是,如果没有显示定义serialVersionUID,则JVM会根据类的信息自动计算出它的值,如果升级前后类的内容发生了变化,该值的计算结果通常就不同,这会导致反序列化的失败。所以,最好在打算序列化的类中显示地定义serialVersionUID,这样即便在序列化后它对应的类被修改了,由于版本号是一致的,所以该对象依然可以被正确的反序列化。
加分回答
如果类的修改会导致反序列化的失败,则应该为此类分配新的serialVersionUID,那么类的哪些内容发生修改会导致反序列化失败呢?
- 修改方法、静态变量不会导致反序列化失败
- 修改了实例变量,则可能导致反序列化失败
说一说你对Spring AOP的理解
AOP是通过预编译方式和运行期动态代理的方式,在不修改源代码的情况下实现给程序动态统一添加功能的技术。利用AOP可以对业务逻辑各个部分进行隔离,从而使业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高开发效率。
AOP可以有多种实现方式,而Spring AOP支持如下两种实现方式。
- JDK动态代理:这是Java提供的动态代理技术,可以在运行时创建接口实现类的代理实例。Spring AOP默认采用这种方式,在接口的代理实例中织入代码。
- CGLib动态代理:采用底层的字节码技术,在运行时创建子类代理的实例。当目标对象不存在接口时,Spring AOP就会采用这种方式,在子类实例中织入代码。
AOP不能增强的类:
- Spring AOP只能对IoC容器中的Bean进行增强,对于不受容器管理的对象不能增强。
由于CGLib采用动态创建子类的方式生成代理对象,所以不能对final修饰的类进行代理。
线程池executor和submit的区别
execute只能提交Runnable类型的任务,submit可以提交Callable和Runnable类型的;
- execute直接抛出异常,而submit方法捕获了异常,通过get获取异常与返回值;
-
两个对象可能equals为true但是hahCode不同吗
可能,如果一个类没有重写hashCode方法,那么就会出现这种现象,我们举个例子 ```java /**
- @author mrlinxi
- @create 2022-04-15 15:06
有没有可能两个对象equals相等,但是hashCode不相等 */ public class HashCodeDemo { public static void main(String[] args) { // MyObject类没有重写hashCode方法,但是重写了equals方法 MyObject o1 = new MyObject(“aa”, 10); MyObject o2 = new MyObject(“aa”, 10); System.out.println(“MyObject 两个内容一样的对象 hashCode是否相等:” + (o1.hashCode() == o2.hashCode())); // false System.out.println(“MyObject 两个对象是否相等:” + o1.equals(o2)); // true
// HashObject重写了hashCode与equals方法 HashObject b1 = new HashObject(“bb”, 5); HashObject b2 = new HashObject(“bb”, 5); System.out.println(“HashObject 内容一样的对象 hashCode是否相等:” + (b1.hashCode() == b2.hashCode())); // false System.out.println(“HashObject 两个对象是否相等:” + b1.equals(b2)); // true } }
@AllArgsConstructor @NoArgsConstructor class MyObject { @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; MyObject myObject = (MyObject) o; return Objects.equals(name, myObject.name) && Objects.equals(age, myObject.age); }
String name;Integer age;
}
@AllArgsConstructor @NoArgsConstructor class HashObject { String name; Integer age;
@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;HashObject that = (HashObject) o;return Objects.equals(name, that.name) && Objects.equals(age, that.age);}@Overridepublic int hashCode() {return Objects.hash(name, age);}
}
```
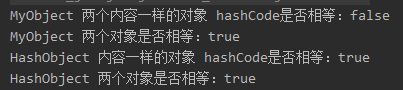
MyObject类是没有重写hashCode方法的,他会调用Object默认的hashCode方法,返回一个随机数,因此会导致hashCode不相等但是equals相等。
(二)数据库
数据库三大范式?
第一范式(1NF):列不可再分
- 每一列属性都是不可再分的属性值,确保每一列的原子性
- 两列的属性相近或相似或一样,尽量合并属性一样的列,确保不产生冗余数据
第二范式(2NF):属性完全依赖于主键
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。这个惟一属性列被称为主键第三范式(3NF):属性不依赖于其它非主属性 属性直接依赖于主键
数据不能存在传递关系,即每个属性都跟主键有直接关系而不是间接关系。像:a—>b—>c 属性之间含有这样的关系,是不符合第三范式的。1000W(或者更多)数据入库,该怎么设计?
首先需要明确的问题:是一次性导入?还是每天都需要导入这么多?属于oltp还是olap应用?
主流db都会有官方的batch方案,batch size是根据内存和效率等约束决定的。最核心的是在导入前将索引干掉,导入完了再加索引。(三)计算机网络
UPD首部的结构
UDP首部有8个字节,由4个字段构成,每个字段都是两个字节
1.源端口号: 可有可无,需要对方回信时选用,不需要时全部置0。
2.目的端口号:必须有,在终点交付报文的时候需要用到。
3.长度:UDP的数据报的长度(包括首部和数据)其最小值为8字节(只有首部)。
4.校验和:检测UDP数据报在传输中是否有错,有错则丢弃。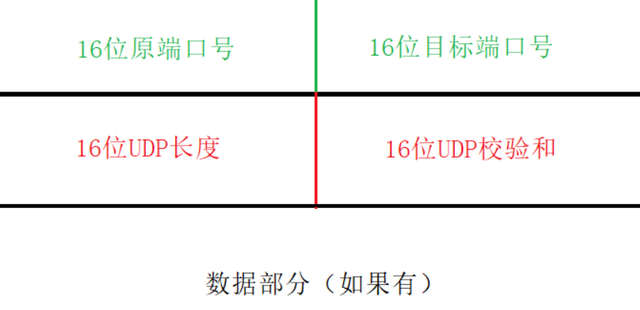
(四)Redis
Redis的大key是怎么回事?
什么是大key
首先需要明确什么是大key,大key是指key下面的是数据(value)很大而不是key过大。
string类型控制在10kb以内,hash、list、set、zset元素个数不要超过5000;(超过这些我们就称之为大key)
怎么排查大key
string类型可使用命令 —bigkeys redis-cli -h 127.0.0.1 -p 6379 -a "password" --bigkeys
Rdbtools工具:rdb dump.rdb -c memory --bytes 10240 -f redis.csv 这句指令的意思就是找到大于10240 byte(10 kb)的key,将其导入到redis.csv文件中
如何删除大key
主动删除(同步):UNLINK mykey
被动删除(异步):在redis.conf中设置如下几个配置
- lazyfree-lazy-expire on # 开启过期惰性删除
- lazyfree-lazy-eviction on # 开启超过最大内存惰性删除
lazyfree-lazy-server-del on # 开启服务端被动惰性删除
其他
jar包跟war包的区别?
jar包
jar包(Java Application Archive)包含java类的普通库、资源(resources)、辅助文件(auxiliary files)等。
- jar包是java打的包,一般只是包括一些编译后class文件和一些部署文件,在声明了Main_class之后是可以用java命令运行的。
-
war包
War文件(扩展名为.War,Web Application Archive)包含全部Web应用程序。在这种情形下,一个Web应用程序被定义为单独的一组文件、类和资源,用户可以对war文件进行封装,并把它作为小型服务程序(servlet)来访问;
- war包可以理解为Javaweb打的包,里面包含:class文件、依赖包、配置文件以及所有的静态资源(html、jsp等等),一个war包可以理解为一个web项目
汉德信息
maven install 跟package的区别
install 做了两件事:
- 将项目打包(jar/war),将打包结果放到项目的target目录下
- 将打包好的项目放到本地仓库的目录中,供其他模块使用
package:package只是将项目打包,然后放到target目录下
Spring事务
SpringMVC流程
Redis分布式锁
git 将项目clone到本地并新建一个分支
swagger
mybatis mapper中怎么获取主键
最左匹配原则
华为od二面
JVM的生命周期
反射的优缺点
如果发现一个对象回收不了,应该从哪方面去分析?
数据库常用的字段对象
整形:
tinyint、smallint、mediumint、int/integer、bigint 都可以设置 unsigned
定点数:decimal(M,D)
浮点数:
float(M,D) 4
double(M,D) 8
字符型:char、varchar、binary、varbinary、enum、set、text、blob
这里被问到了char跟varchar的区别 没答上来 被问蒙了
char:固定长度的字符,写法为char(M),最大长度不能超过M,其中M可以省略,默认为1
varchar:可变长度的字符,写法为varchar(M),最大长度不能超过M,其中M不可以省略
日期类型:
year年
date日期
time时间
datetime 日期+时间 8
timestamp 日期+时间 4 比较容易受时区、语法模式、版本的影响,更能反映当前时区的真实时间
索引分类,怎么建索引
单值索引、唯一索引(主键、唯一)、复合索引、全文索引
/ 如果只写一个字段就是单值索引,写多个字段就是复合索引 /
CREATE [UNIQUE] INDEX indexName ON tabName(columnName(length),[columnName2(length)]);
索引有什么作用?原理是啥
加快查找(降低I0成本)和排序(降低CP功耗)的速度。 聚簇索引与非聚簇索引的区别,底层使用的B+树
mysql删除数据有几种方式?
delete drop [table/database] [tablename/databasename]
truncate table 数据表名称(删数据但不删表) TRUNCATE TABLE语句是一种快速、无日志记录的方法。TRUNCATE TABLE语句与不含有 WHERE 子句的 DELETE 语句在功能上相同。但是,TRUNCATE TABLE语句速度更快,并且使用更少的系统资源和事务日志资源。
速度 drop>truncate>delete
ONES
数据库WAL
WAL(Write Ahead Log)预写日志,是数据库系统中常见的一种手段,用于保证数据操作的原子性和持久性。
在使用 WAL 的系统中,所有的修改在提交之前都要先写入 log 文件中。WAL 机制的原理也很简单:「修改并不直接写入到数据库文件中,而是写入到另外一个称为 WAL 的文件中;如果事务失败,WAL 中的记录会被忽略,撤销修改;如果事务成功,它将在随后的某个时间被写回到数据库文件中,提交修改。」
mysql 通过 redo、undo 日志实现 WAL。redo log 称为重做日志,每当有操作时,在数据变更之前将操作写入 redo log,这样当发生掉电之类的情况时系统可以在重启后继续操作。undo log 称为撤销日志,当一些变更执行到一半无法完成时,可以根据撤销日志恢复到变更之间的状态。mysql 中用 redo log 来在系统 Crash 重启之类的情况时修复数据(事务的持久性),而 undo log 来保证事务的原子性。
seata是几阶段提交?
Redis分布式锁

若有收获,就点个赞吧
0 人点赞
