B树与索引结构
二叉树的查找效率在O(logn)级别,性能十分优秀。但是mysql索引(以InnoDB为例)使用的是其升级版,B+Tree。两者的区别在于同样多的数据节点,二叉树的高度更高,导致磁盘IO的次数会更多。磁盘IO极为耗时,磁盘寻道,数据读取等都说很耗性能的操作。虽然磁盘已经有了预读等优化,但实际上效率比起内存读写还是要慢几百倍。
所以瘦高的树并不适应时代,B树应运而生。B树有B-树和B+树两类。
B-Tree
- m阶B-Tree满足以下条件:
- 每个节点最多拥有m个子树
- 根节点至少有2个子树
- 分支节点至少拥有m/2颗子树(除根节点和叶子节点外都是分支节点)
- 所有叶子节点都在同一层、每个节点最多可以有m-1个key,并且以升序排列
B+Tree
- 有m个子树的节点包含有m个元素(B-Tree中是m-1)
- 根节点和分支节点中不保存数据,只用于索引,所有数据都保存在叶子节点中。
- 所有分支节点和根节点都同时存在于子节点中,在子节点元素中是最大或者最小的元素。
- 叶子节点会包含所有的关键字,以及指向数据记录的指针,并且叶子节点本身是根据关键字的大小从小到大顺序链接。
与B-Tree不同的是,B+树的分支节点和根节点不存储数据,只有在叶子节点才会保存数据。这样做有三个好处 第一,相同数量的节点,树所占用的空间更小 第二,所有查询都要走到叶子节点,更稳定 第三,所有数据都在叶子节点有序,方便范围查找,方便遍历(主要是范围查找,所有叶子节点连成一个链表,范围查找极快)
MyISAM和InnoDB索引的区别
MyISAM的索引都是非聚集的,叶子节点保存的是数据的地址而不是值。而InnoDB的主键索引树的叶子节点会存储行信息,这样找到叶子节点就无需再进行一次磁盘IO,还可以保证在主键索引和行数据进行行分裂等操作时,辅助索引不需要做任何变化。
InnoDB的每一个节点都保存了一页数据,一页数据保存远远多余数据库表一行的数据,一个叶子节点能存储的数据在400行以上。
InnoDB的page结构
Page分为几种类型,常见的页类型有数据页(B-tree Node)Undo页(Undo Log Page)系统页(System Page) 事务数据页(Transaction System Page)等。单个Page的大小是16K(编译宏UNIV_PAGE_SIZE控制),每个Page使用一个32位的int值来唯一标识,这也正好对应InnoDB最大64TB的存储容量(16Kib * 2^32 = 64Tib)。一个Page的基本结构如下图所示:
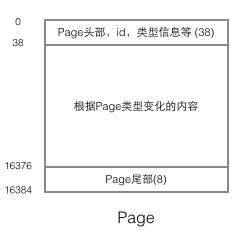
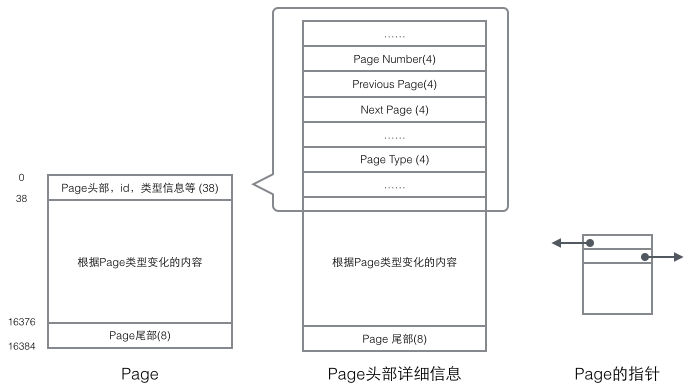
page头部保存了两个指针,分别指向前一个page和后一个page。因此索引树的叶子节点是一个双向的链表。
page的主体部分保存着行数据和索引信息。他们都保存在User Records部分,是一条一条的record,每条record代表索引树上的一个节点。在一个Page内部,单链表的头尾由固定内容的两条记录来表示,字符串形式的”Infimum”代表开头,”Supremum”代表结尾。这两个用来代表开头结尾的Record存储在System Records的段里,这个System Records和User Records是两个平行的段。

只需要把Record当成一个存储了数据同时含有Next指针的单链表节点即可。
把User Record的组织形式和若干Page组合起来,就看到了稍微完整的形式。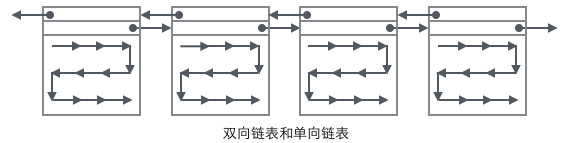
如何定位一个Record:
1、通过根节点开始遍历一个索引的B+树,通过各层非叶子节点最终到达一个Page,这个Page里存放的都是叶子节点。
2、在Page内从”Infimum”节点开始遍历单链表(这种遍历往往会被优化),如果找到该键则成功返回。如果记录到达了”supremum”,说明当前Page里没有合适的键,这时要借助Page的Next Page指针,跳转到下一个Page继续从”Infimum”开始逐个查找。
根据B+树节点的不同,User Record可以被分成四种格式
- 主索引树非叶节点(绿色)
1 子节点存储的主键里最小的值(Min Cluster Key on Child),这是B+树必须的,作用是在一个Page里定位到具体的记录的位置。
2 最小的值所在的Page的编号(Child Page Number),作用是定位Record。 - 主索引树叶子节点(黄色)
1 主键(Cluster Key Fields),B+树必须的,也是数据行的一部分
2 除去主键以外的所有列(Non-Key Fields),这是数据行的除去主键的其他所有列的集合。
这里的1和2两部分加起来就是一个完整的数据行。 - 辅助索引树非叶节点非(蓝色)
1 子节点里存储的辅助键值里的最小的值(Min Secondary-Key on Child),这是B+树必须的,作用是在一个Page里定位到具体的记录的位置。
2 主键值(Cluster Key Fields),非叶子节点为什么要存储主键呢?因为辅助索引是可以不唯一的,但是B+树要求键的值必须唯一,所以这里把辅助键的值和主键的值合并起来作为在B+树中的真正键值,保证了唯一性。但是这也导致在辅助索引B+树中非叶节点反而比叶子节点多了4个字节。(即下图中蓝色节点反而比红色多了4字节)
3 最小的值所在的Page的编号(Child Page Number),作用是定位Record。 - 辅助索引树叶子节点(红色)
1 辅助索引键值(Secondary Key Fields),这是B+树必须的。
2 主键值(Cluster Key Fields),用来在主索引树里再做一次B+树检索来找到整条记录。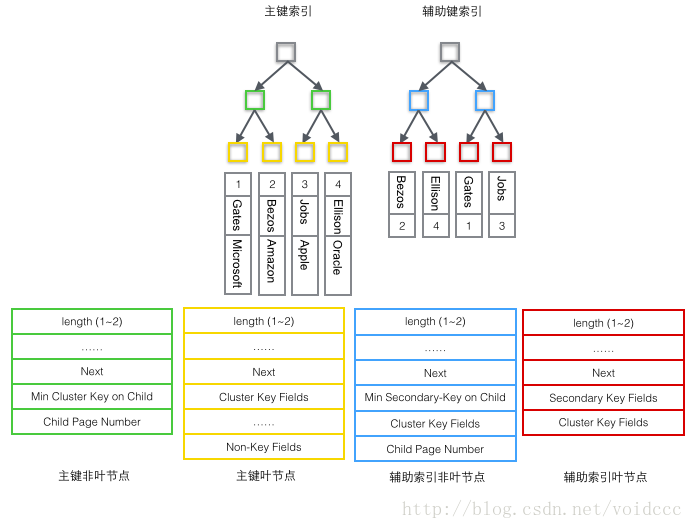
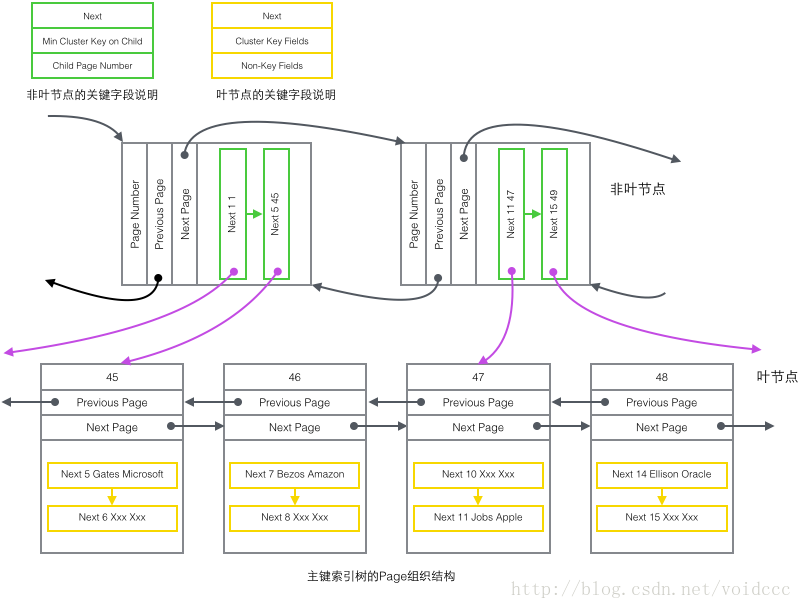
把上图还原成下面这个更简洁的树形示意图,这就是B+树的一部分。注意Page和B+树节点之间并没有一一对应的关系。Page只是作为一个Record的保存容器,它存在的目的是便于对磁盘空间进行批量管理,上图中的编号为47的Page在树形结构上就被拆分成了两个独立节点。

若有收获,就点个赞吧
0 人点赞
