1、容器初始化,ApplicationContext.xml的解析
Spring提供了很多种配置的方式,有xml,基于代码,基于注解。自然的,也就有很多种不同的初始化容器的方式。这里以使用最广泛的xml为例。
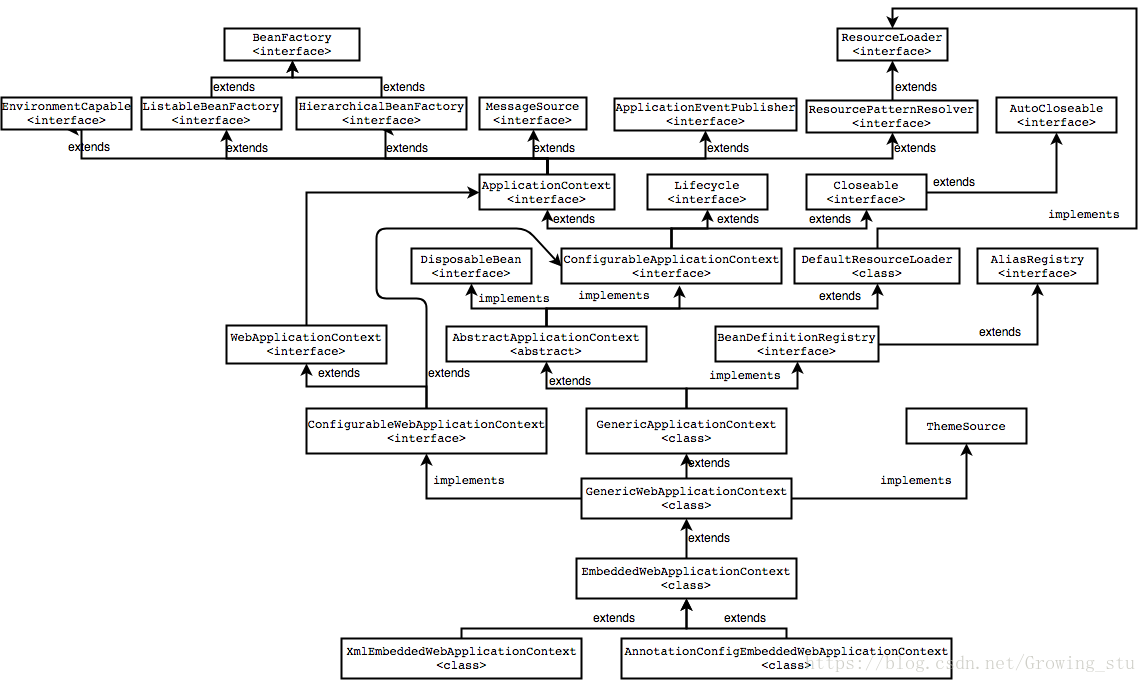
(图片来自网络)ApplicationContext有一张庞大的继承网络,源接口来自BeanFactory,即创建bean的工厂。因此,继承自ApplicationContext的ClassPathXmlApplicationContext类,也是Bean工厂的一种,它解析xml文件,创建配置好的bean。
首先来看它的构造方法。若有父AppllicationContext传入,则先调用父方法。随后设置配置路径。最后调用refresh方法。
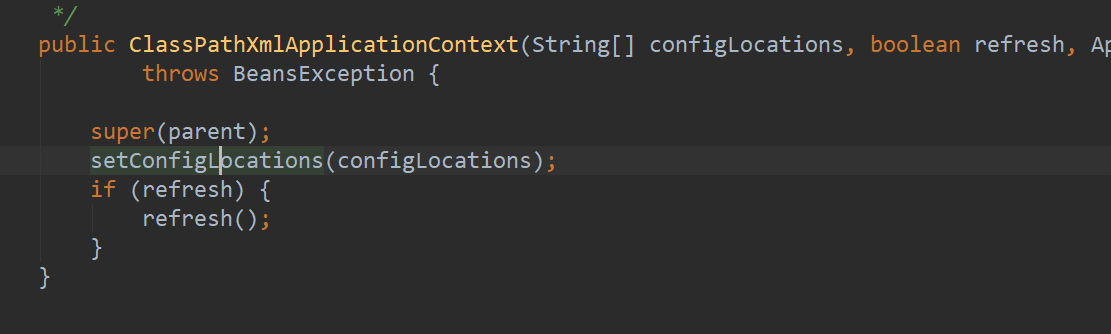
setConfigLocations方法,设置配置路径。通过断点我们可以清晰的看到,这个路径就是我们项目里配置的applicationContext.xml的路径。但是这一步并没有对文件做任何的解析,而是将文件名解析出来,放置到一个String类型的数组configLocations当中。
refresh方法开始进行实质性的容器刷新。方法比较长,步骤也比较多,属于spring比较核心的方法。
@Overridepublic void refresh() throws BeansException, IllegalStateException {//开始刷新之前需要加锁synchronized (this.startupShutdownMonitor) {// 刷新前的准备工作,记录启动时间//设置一些boolean的状态位,处理配置文件里的占位符prepareRefresh();// 这一步的核心是refreshBeanFactory方法,在方法中加载了bean的定义信息,loadBeanDefinitions//方法,即初始化xml阅读器,然后读取配置文件,将bean的定义,或其他定义,读取成Document//对象,然后在BeanDenifitionDocumentReader的doRegisterBeanDefinitions//方法中,将Document对象逐行解析,判断是import还是bean或者是其他,随即调用对应的//处理逻辑,processBeanDefinition,或importBeanDenifitionResource方法等,以//processBeanDefinition方法为例,首先获取BeanDefinitionHolder和BeanDefinitionRegistry//两个对象,随即对bean进行注册,注册的核心是registry.registerBeanDefinition//方法,其实非常简单,就是把bean的名称和一些其他的信息,放到一个map里ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();//对BeanFactory做一些准备工作,例如设置BeanClassLoader,BeanPostPocesser//,装载一些特殊的bean,例如environment, systemProperties等等prepareBeanFactory(beanFactory);try {//bean如果是实现了BeanFactoryPostProcessor 接口,那么在这里,可以调用bean的方法//来让bean提前做一些事postProcessBeanFactory(beanFactory);// Invoke factory processors registered as beans in the context.invokeBeanFactoryPostProcessors(beanFactory);//注册BeanPostProcessor 实现类,这类似于bean初始化的一个切面,分别在bean初始化之前//和之后执行方法,则对应的实现类需要给出两个方法的具体实现,postProcessBeforeInitialization和postProcessAfterInitializationregisterBeanPostProcessors(beanFactory);// Initialize message source for this context.initMessageSource();// Initialize event multicaster for this context.initApplicationEventMulticaster();// 模板方法,让子类去做一些自定义的操作。onRefresh();//注册事件监听器,事件监听需要实现ApplicationListener接口//例如dubbo的ServiceBean就实现了这个接口registerListeners();//初始化所有的单例bean。这里同样的也做了很多事情,例如注册注解替换处理器等finishBeanFactoryInitialization(beanFactory);// 广播事件,刷新完成finishRefresh();}catch (BeansException ex) {if (logger.isWarnEnabled()) {logger.warn("Exception encountered during context initialization - " +"cancelling refresh attempt: " + ex);}// Destroy already created singletons to avoid dangling resources.destroyBeans();// Reset 'active' flag.cancelRefresh(ex);// Propagate exception to caller.throw ex;}finally {// Reset common introspection caches in Spring's core, since we// might not ever need metadata for singleton beans anymore...resetCommonCaches();}}}
至此,spring就完成了容器的初始化,bean的初始化,以及一系列相关工具的初始化。下面对其中的方法进行进一步的解析。
prepareRefresh
protected void prepareRefresh() {this.startupDate = System.currentTimeMillis();this.closed.set(false);this.active.set(true);if (logger.isInfoEnabled()) {logger.info("Refreshing " + this);}// Initialize any placeholder property sources in the context environment//从这句话的注解也可以看得出,这个方法就是处理配置文件中的占位符initPropertySources();// Validate that all properties marked as required are resolvable// see ConfigurablePropertyResolver#setRequiredPropertiesgetEnvironment().validateRequiredProperties();// Allow for the collection of early ApplicationEvents,// to be published once the multicaster is available...this.earlyApplicationEvents = new LinkedHashSet<ApplicationEvent>();}
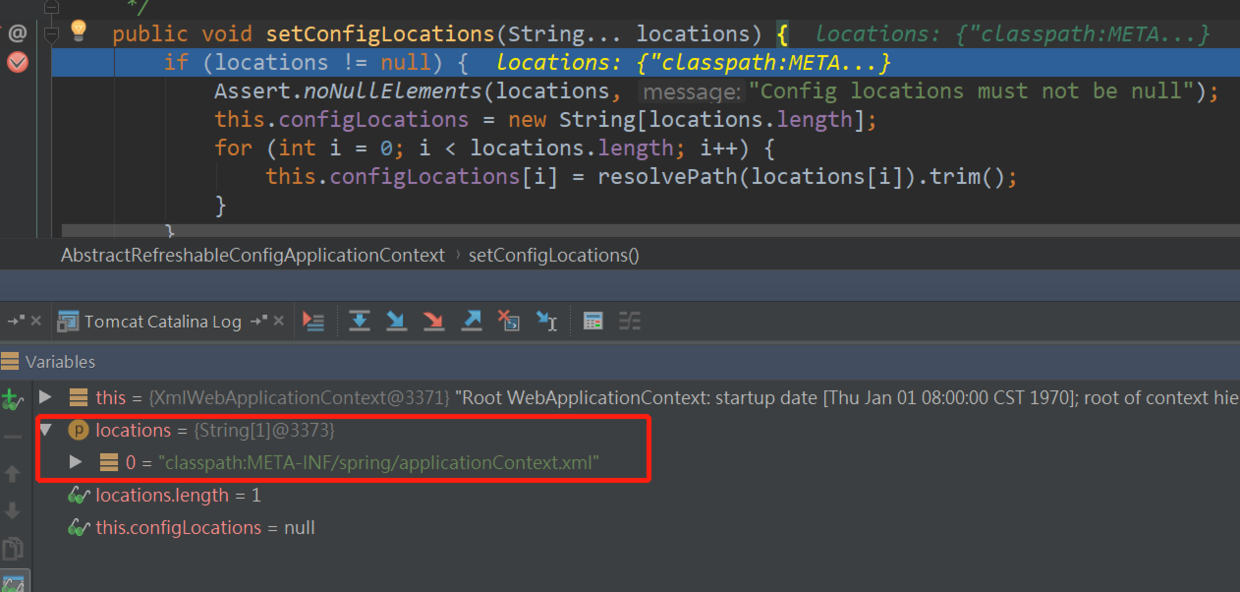
initPropertySources方法的默认实现在AbstraceRefreshableWebApplicationCOntext类中,在方法中,获取了当前的ConfigurableEnvironment对象,通过断点可以看到,env环境对象中,包含了一个
propertyResolver类,他的一些属性显而易见,是为了处理${}形式的占位符。
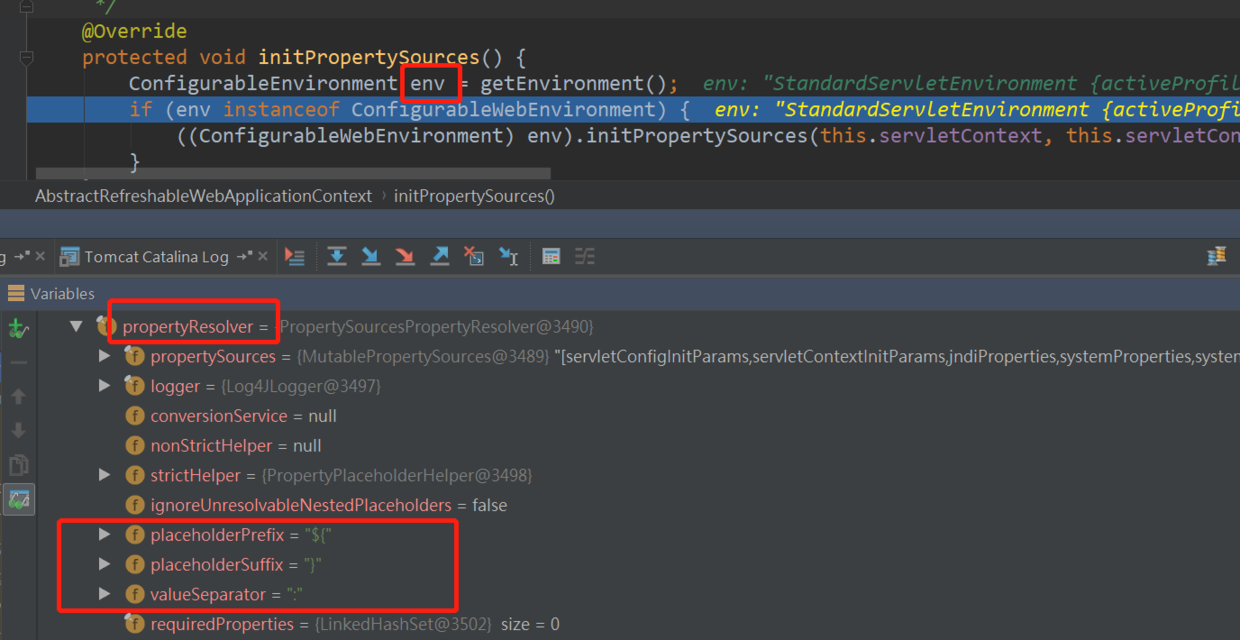
进入到env对象的initPropertySources方法里,最终是来到了WebApplicationContextUtils.initServletPropertySources方法来处理占位符。
obtainFreshBeanFactory
准备完毕,接下来进入obtainFreshBeanFactory方法,在这个方法里做了很多事情,例如创建BeanFactory,将bean注册(但是不初始化)等等。obtainFreshBeanFactory的核心是refreshBeanFactory方法。直接进入refreshBeanFactory方法
protected ConfigurableListableBeanFactory obtainFreshBeanFactory() {refreshBeanFactory();ConfigurableListableBeanFactory beanFactory = getBeanFactory();if (logger.isDebugEnabled()) {logger.debug("Bean factory for " + getDisplayName() + ": " + beanFactory);}return beanFactory;}
refreshBeanFactory
@Overrideprotected final void refreshBeanFactory() throws BeansException {if (hasBeanFactory()) {destroyBeans();closeBeanFactory();}try {DefaultListableBeanFactory beanFactory = createBeanFactory();beanFactory.setSerializationId(getId());customizeBeanFactory(beanFactory);loadBeanDefinitions(beanFactory);synchronized (this.beanFactoryMonitor) {this.beanFactory = beanFactory;}}catch (IOException ex) {throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);}}
首先判断beanFactory是不是为null,如果不是,会把单例的bean全部清理,然后将beanFactory置为null。既然要刷新,就得把之前的先清理干净。
随后createBeanFactory方法,newl了一个DefaultListableBeanFactory,这是ApplicationContext持有的BeanFactory的默认实现。
接下来一行,通过获取类的id来作为序列化ID
接下来一行调用customizeBeanFactory方法,这个方法设置了两个属性,是否允许同名bean覆盖,是否允许循环依赖。
接下来一行loadBeanDefinitions方法,这是解析xml,初始化Bean的核心方法。在方法中先实例化一个XmlBeanDefinitionReader,xml的解析和bean的加载都在reader中完成。重点在loadBeanDefinitions方法里。
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws IOException {String[] configLocations = getConfigLocations();if (configLocations != null) {for (String configLocation : configLocations) {reader.loadBeanDefinitions(configLocation);}}}
getConfigLocations获取一个String数组。这个数组里装的就是配置文件的路径了,随后放入reader进行解析。loadBeanDefinitions代码如下,核心的逻辑是获取了一个Resource数组然后再次调用了loadBeanDefinitions的重载方法。
public int loadBeanDefinitions(String location, Set<Resource> actualResources) throws BeanDefinitionStoreException {ResourceLoader resourceLoader = getResourceLoader();if (resourceLoader == null) {throw new BeanDefinitionStoreException("Cannot import bean definitions from location [" + location + "]: no ResourceLoader available");}if (resourceLoader instanceof ResourcePatternResolver) {// Resource pattern matching available.try {Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);//将资源进行加载,也就是将xml文件进行解析int loadCount = loadBeanDefinitions(resources);if (actualResources != null) {for (Resource resource : resources) {actualResources.add(resource);}}if (logger.isDebugEnabled()) {logger.debug("Loaded " + loadCount + " bean definitions from location pattern [" + location + "]");}return loadCount;}catch (IOException ex) {throw new BeanDefinitionStoreException("Could not resolve bean definition resource pattern [" + location + "]", ex);}}else {// Can only load single resources by absolute URL.Resource resource = resourceLoader.getResource(location);int loadCount = loadBeanDefinitions(resource);if (actualResources != null) {actualResources.add(resource);}if (logger.isDebugEnabled()) {logger.debug("Loaded " + loadCount + " bean definitions from location [" + location + "]");}return loadCount;}}
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {//...多余代码不复制//核心逻辑,h获取了资源对象的inputStream,开始读取resource里保存的xml文件路径try {InputStream inputStream = encodedResource.getResource().getInputStream();try {InputSource inputSource = new InputSource(inputStream);if (encodedResource.getEncoding() != null) {inputSource.setEncoding(encodedResource.getEncoding());}//读到文件流之后调用doLoadBeanDefinitions方法return doLoadBeanDefinitions(inputSource, encodedResource.getResource());}finally {inputStream.close();}}}//不核心的代码省略
在这个方法里,Resource里保存的xml路径被转换为一个imputStream对象,文件流被读进来并且封装成一个InputResource对象。通过断点可以看到这个对象里啥都没有,只有一个byteStream
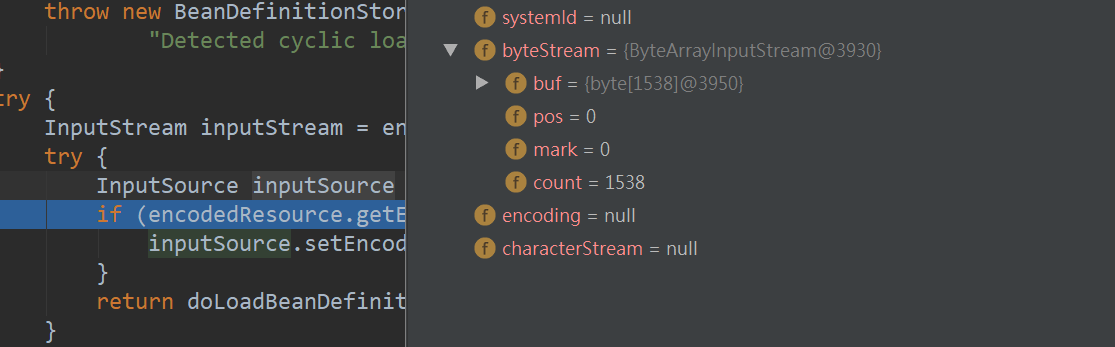
随后调用doLoadBeanDefinitions方法,代码如下
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)throws BeanDefinitionStoreException {try {Document doc = doLoadDocument(inputSource, resource);return registerBeanDefinitions(doc, resource);}}
doLoadDocument将文件流解析成了Document对象。随后调用registerBeanDefinitions方法对bean进行注册。registerBeanDefinitions最终来到DefaultBeanDefinitaionDocumentReader的doRegisterBeanDefinitions方法,代码如下
protected void doRegisterBeanDefinitions(Element root) {// 这里有一大堆注解,被我删掉了// 大意是说<beans>标签里可以递归的定义<beans>,所以为了解决递归问题// 需要传递一个parentBeanDefinitionParserDelegate parent = this.delegate;this.delegate = createDelegate(getReaderContext(), root, parent);//如果是默认的namespace//默认的namespace是http://www.springframework.org/schema/beansif (this.delegate.isDefaultNamespace(root)) {//然后是一大段关于profile配置的解析。profile就是环境之类的,不常用String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);if (StringUtils.hasText(profileSpec)) {String[] specifiedProfiles = StringUtils.tokenizeToStringArray(profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {if (logger.isInfoEnabled()) {logger.info("Skipped XML bean definition file due to specified profiles [" + profileSpec +"] not matching: " + getReaderContext().getResource());}return;}}}preProcessXml(root);parseBeanDefinitions(root, this.delegate);postProcessXml(root);this.delegate = parent;}
preProcessXml和postProcessXml都是模板方法,留给子类实现的,从断点可以看到,其实是没有提供实现。可以跳过。重点关注parseBeanDifinitions方法
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {if (delegate.isDefaultNamespace(root)) {NodeList nl = root.getChildNodes();for (int i = 0; i < nl.getLength(); i++) {Node node = nl.item(i);if (node instanceof Element) {Element ele = (Element) node;if (delegate.isDefaultNamespace(ele)) {parseDefaultElement(ele, delegate);}else {delegate.parseCustomElement(ele);}}}}else {delegate.parseCustomElement(root);}}
首先判断是不是默认的namespace,也就是说如果是beans标签,自然是要把子标签的bean都一一解析出来的。贴一张项目里的配置文件作为例子
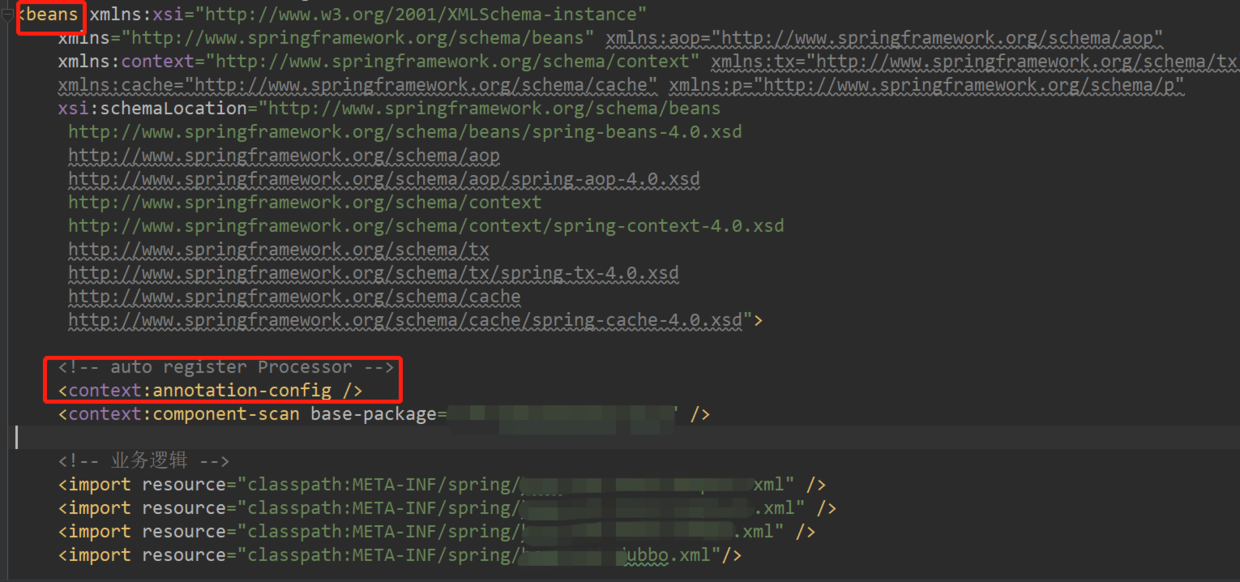
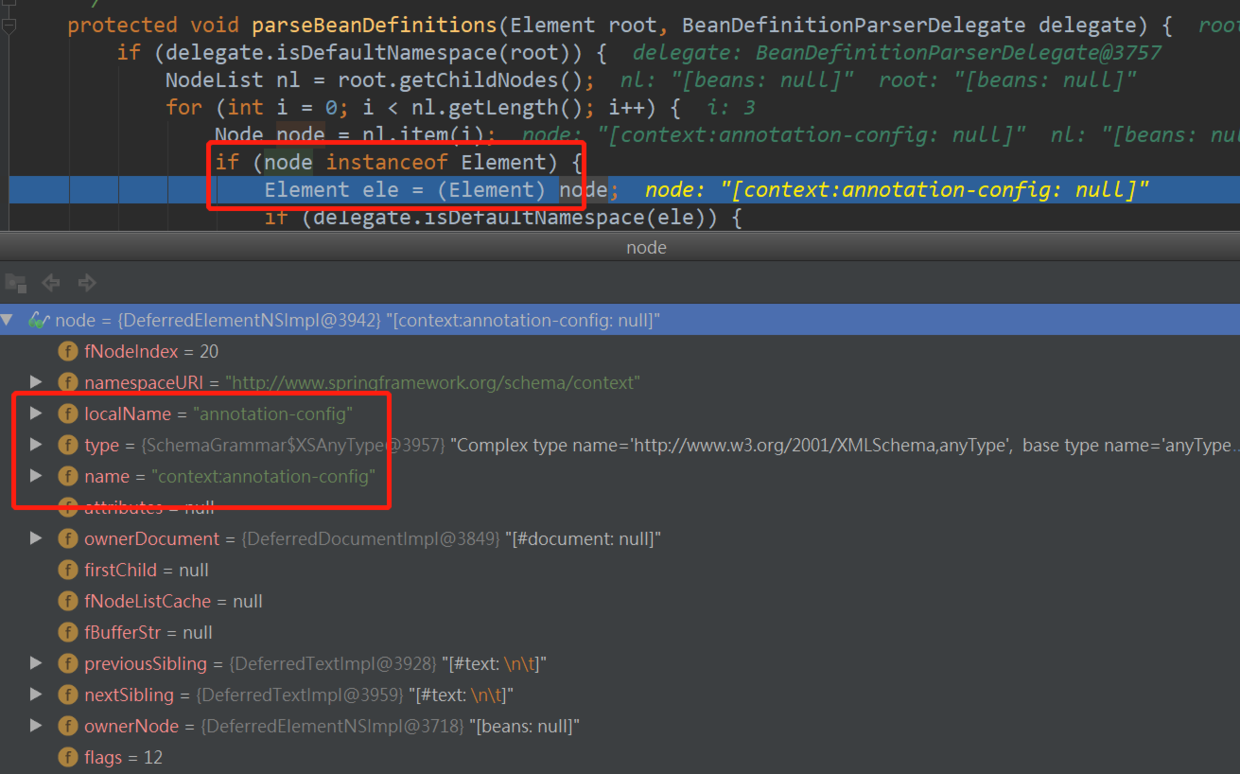
可以看到例子中的applicationContext.xml文件是以beans标签开头的,因此进入一个for循环,开始解析标签下的子node。由断点的截图可以看到,当前解析出了Element对象类型的node,即图一中的第一个标签context:annotation-config。解析出Element对象以后又判断了一次是不是默认的namespace,如果是那么递归解析。如果不是,那就默认解析,调用的是parseCustomElement方法,在这个方法中,根据其namespace来找到对应的namespaceHandler,所有的handlerMapping都被保存在一个map当中,以namespaceUri为key,查找对应的namespaceHandler。这也是spring的扩展性所在,自定义实现namespaceHandler就可以解析配置文件中的自定义标签了,例如dubbo的dubbo:xxx标签。每一个标签对应的bean,最后都被解析成了BeanDefinition对象。

若有收获,就点个赞吧
0 人点赞
