之前做组内分享的准备的时候,我简单的写了一些RocketMQ与QMQ存储结构上的差异(https://www.jianshu.com/p/c2e2e9deb699),当时写的不是很详细,表述还有一些错误。我想重新用一篇文章,再理一理这里边的差异。
先讲更广为人知的RocketMQ,我先贴一张基础的存储结构
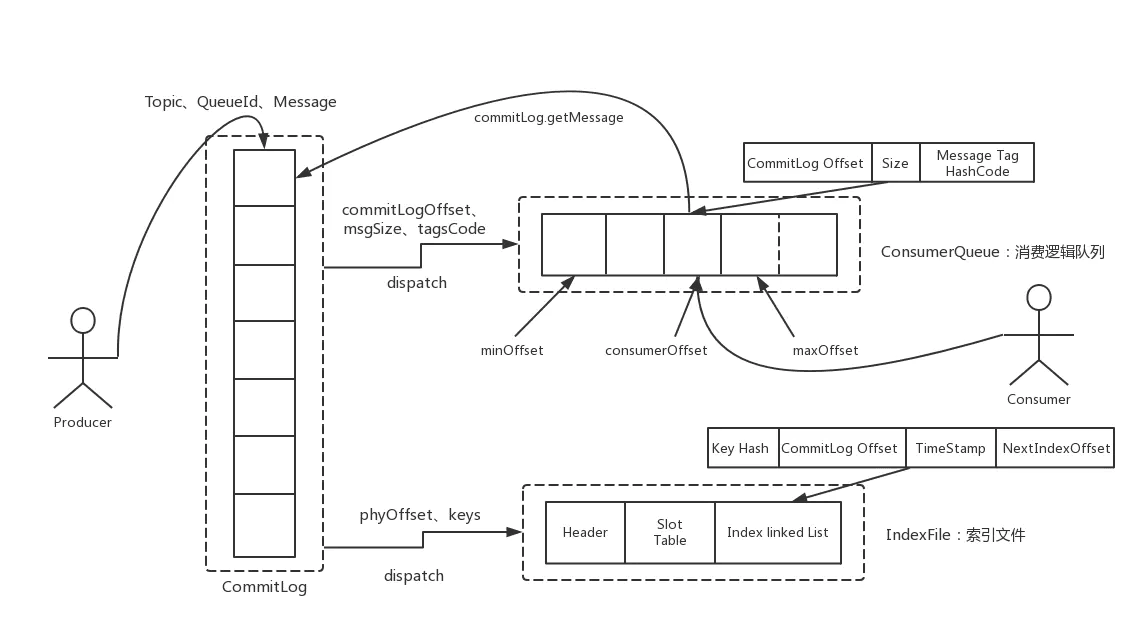
RocketMQ存储结构可以概括为三大部分:CommitLog,ConsumerQueue和IndexFile。
CommitLog是所有消息的顺序存储文件,broker收到的消息无脑往里边append。文件位于${ROCKET_HOME}/store/commitlog目录下,每个文件默认大小1G,超过就新建一个。所以commitLog并不是一个单一文件,而是一组文件的统称,文件名就是该文件的第一个偏移量。
在RocketMQ的源码中,commitlog目录对应的逻辑对象叫做MappedFileQueue,而具体的以起始偏移量命名的文件对应的逻辑对象叫做MappedFile。在消息写入commitlog文件之前,线程会先申请锁,因此消息写入commitlog的串行的。
ConsumerQueue众所周知,是commitlog的索引文件,根据topic来对消息区分存储,当然为了节约空间,ConsumerQueue文件里并不会存储消息的具体内容,从图中我们可以看到,commitlog在消息写入之后,由专门的线程产生消息转发任务,同步到ConsumerQueue中的只有commitlog offset,size,tag hashcode这三个信息。ConsumerQueue文件并不是像commitLog一样文件直接堆放在一起,而是在consumerQueue目录下,根据topic/queueId,再分了两层目录,提升了检索的效率。
IndexFile顾名思义就是一个索引文件,保存了消息的key值+消息在commitlog中的偏移量的键值对,便于通过消息的Key直接检索到消息的内容。IndexFile由三个部分组成,分别是总长为固定40个字节的IndexHeader,500w个Hash槽,还有2000w个Index条目,hash槽可以理解为HashMap中的数组,而index条目是用来解决hash冲突的,可以理解为Java HashMap中的链表。
总结来说,commitlog是一个大仓库,完成基本的存储,consumerQueue是针对消费者而设计的,而IndexFile是为了检索而设计的,侧重点不同。
CommitLog在构建ConsumerQueue是通过ReputMessageService异步实现的。从buffer中一条一条的读消息,读到以后根据消息的属性获取对应的ConsumerQueue文件,然后写进去。也就是说,从commitLog中读出来的消息就自己带了queueId,这样也比较好理解,consumerQueue由消息发送方指定的话,才有可能实现顺序消息。
说完了RocketQMQ的存储设计,再来聊聊QMQ的。QMQ的存储设计借鉴了RocketMQ和Kafka,并在他们的基础上做了自己的一些优化。
QMQ有类似于RocketMQ的commitlog的存储结构,叫messageLog,也是用来顺序存储消息的。每个文件的大小也是1G,基本的属性和RocketMQ都一致。
消息在写入messageLog后,起一个异步线程构建一个数据结构叫smt,全称为sorted messages table,顾名思义,这个smt不是对标ConsumerQueue的,它把所有的消息重新排序,按照subject排在一起。subject就是RocketMQ里的topic。这么做是为了在消息堆积时,提高page cache的命中率,使得消息消费时减少磁盘的IO。同时,smt是专门用来读的,等于对messageLog做了一个读写分离。这么做还有一个好处,就是消息内容在回写完smt之后,就可以将messageLog中的消息删除,节约了messageLog的磁盘占用,常规情况下messageLog就不会承担太多的消息存储,可以直接上SSD,提升消息写的IO性能。
consumerLog,将smt中排序好的消息,根据subject分发到各个文件里。文件中存储的是消息在smt中的索引。smt与consumerLog的内容写入是一起进行的。
pullLog文件是消费者的消费记录文件,以subject+consumerGroup+consumerId为维度,保留了每一个消费者的历史消费记录,这样可以在消费者重启之后快速定位到之前消费的位置。
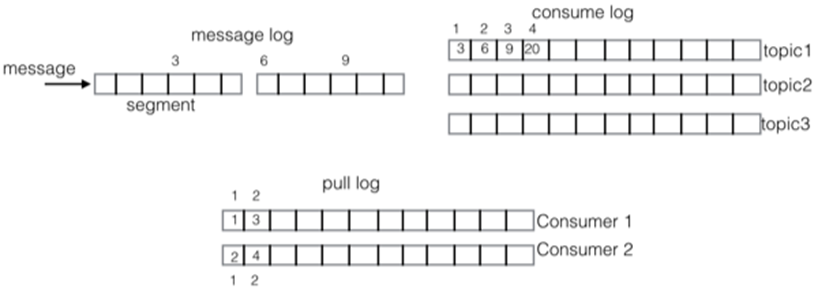
其实可以理解为,consumer log + pull log相当于替代了RocketMQ中的COnsumerQueue的作用,将其做了一个拆分。在系统架构中加一个中间层的好处和缺点都是很明显的,好处就是动态扩展会更加的灵活,耦合性会更加的低。同时,文件多了效率自然也就会收到影响,步骤越多 出错的机率越高。

若有收获,就点个赞吧
0 人点赞
