什么是倒排索引
倒排索引是相对正排索引而言,正排就是类似于MySQL的,倒排索引就是以单词为key,文档id列表为value的存储结构。通常由词典和倒排表组成
- 词典就是单词的集合
- 倒排表是单词对应的文档id
Lucene倒排索引
ES是基于Lucene高可用实现,底层就是Lucene的倒排索引
Posting List倒排表实现
包含三类文件
- .doc用于记录文档id和词频
- .pay记录偏移量
- .pos记录位置信息
doc文件
文件结构如下图,每个单词对应一堆TermFreq和SkipData,TermFreq包含文档id列表和词频
SkipData则是将文档id链表以跳跃表的形式组织,可以加快查询的速度,而跳跃表的节点则记录了docId以及当前term在doc, pos, pay的位置信息词典
词典代表每个单词,并记录倒排表的指针;每个相同前缀压缩为一个NodeBlock,Block中的Entry存储具体的单词以及倒排表引用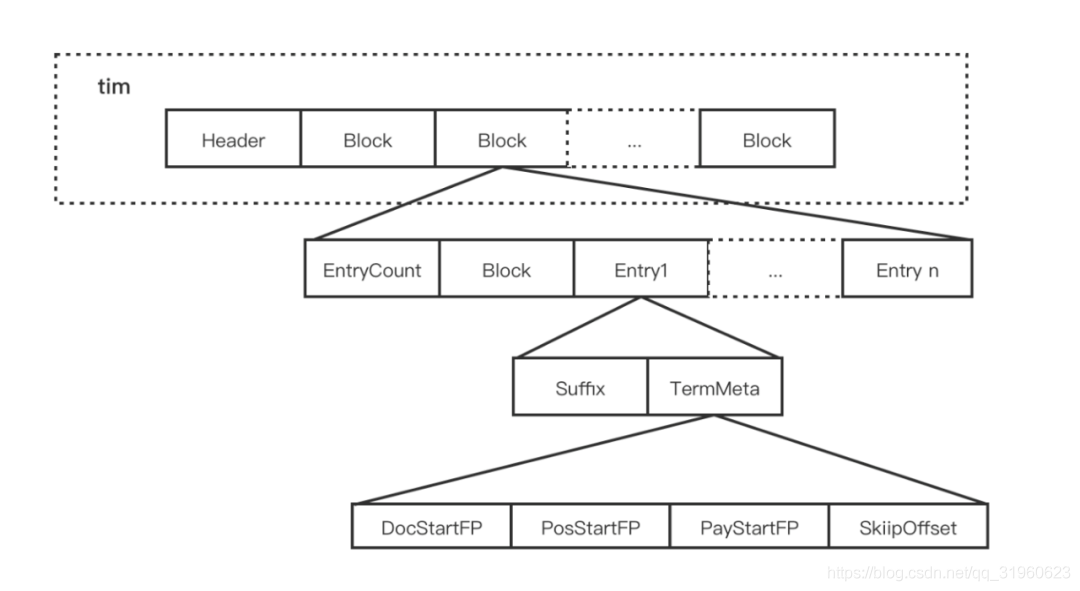
数据查找
因为词典是基于字典树组织的,所以当文档越来越多,查询效率就会下降,因此Lucene使用了FST索引,通过FST的字典树找到对应词典Block
倒排索引查询过程
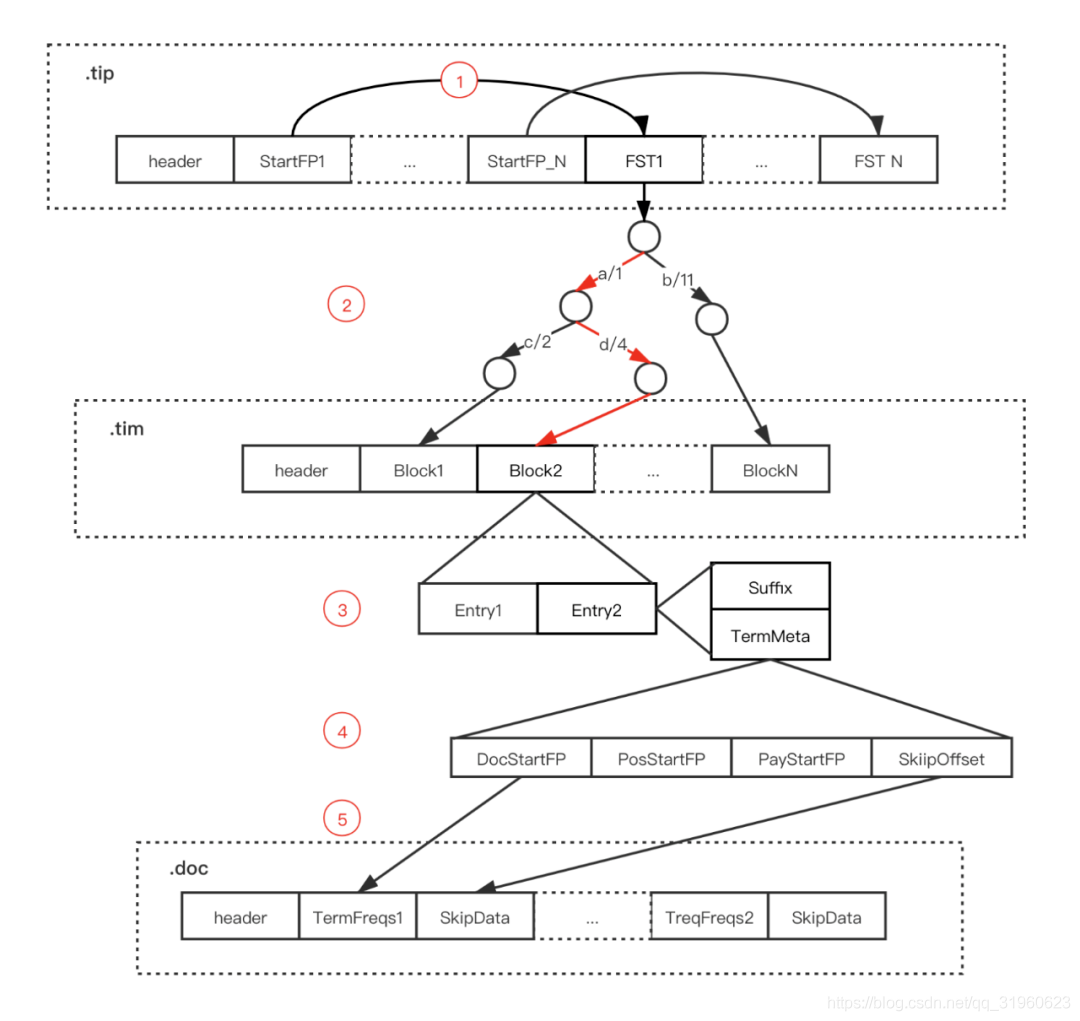
在介绍了索引表和记录表的结构后,就可以得到 Lucene 倒排索引的查询步骤:
- 通过 Term Index 数据(.tip文件)中的 StartFP 获取指定字段的 FST
- 通过 FST 找到指定 Term 在 Term Dictionary(.tim 文件)可能存在的 Block
- 将对应 Block 加载内存,遍历 Block 中的 Entry,通过后缀(Suffix)判断是否存在指定 Term
- 存在则通过 Entry 的 TermStat 数据中各个文件的 FP 获取 Posting 数据
- 如果需要获取 Term 对应的所有 DocId 则直接遍历 TermFreqs,如果获取指定 DocId 数据则通过 SkipData 快速跳转

若有收获,就点个赞吧
0 人点赞
