https://www.cnblogs.com/wang-meng/p/12945703.html
为什么要使用线程池
使用线程池主要有以下三个原因:
- 创建/销毁线程需要消耗系统资源,线程池可以复用已创建的线程。
- 控制并发的数量。并发数量过多,可能会导致资源消耗过多,从而造成服务器崩溃。(主要原因)
- 可以对线程做统一管理。
能否续使用Executors
Executors自带的线程池有四种
- newFixedThreadPool
- newSingleThreadPool
- newCachedThreadPool
- newScheduledThreadPool
在《阿里开发手册》中,不允许使用Executors而要直接使用ThreadPoolExecutor是因为在不明确线程池运作规则情况使用会有OOM或者频繁创建线程的风险,但是如果很熟悉,则可以使用Executors
ThreadPoolExecutor构造方法
public ThreadPoolExecutor(int corePoolSize, // 核心线程数int maximumPoolSize, // 最大线程数long keepAliveTime, // 非核心线程闲置超时时间TimeUnit unit,BlockingQueue<Runnable> workQueue, // 阻塞队列ThreadFactory threadFactory, // 创建线程的工厂RejectedExecutionHandler handler) // 拒绝策略
- 核心线程数:一直存在的线程,不会销毁
- 最大线程数:核心线程数+非核心线程数
- 线程工厂:用于在批量创建线程时,统一设置一些参数,如果不指定,则创建一个默认线程工厂
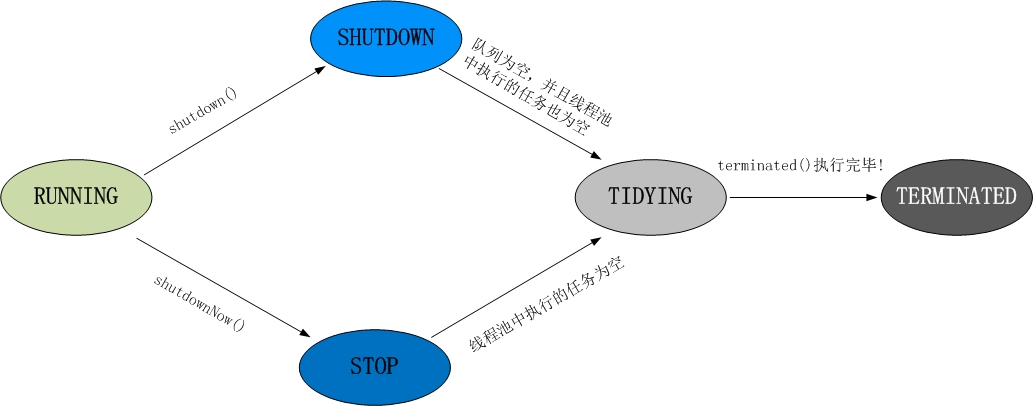
线程池的状态
线程池本身有一个调度线程负责管理线程池的创建、销毁、任务队列等。其中有runState记录线程池状态
- RUNNING:创建后的状态
- SHUTDOWN:调用shutdown(),不再接受任务,等待任务完成
- STOP:调用shutdownNow(),中断所有线程
- TIDYING:调用终止后,当任务数为0的状态
- TERMINATED:TIDYING后的状态
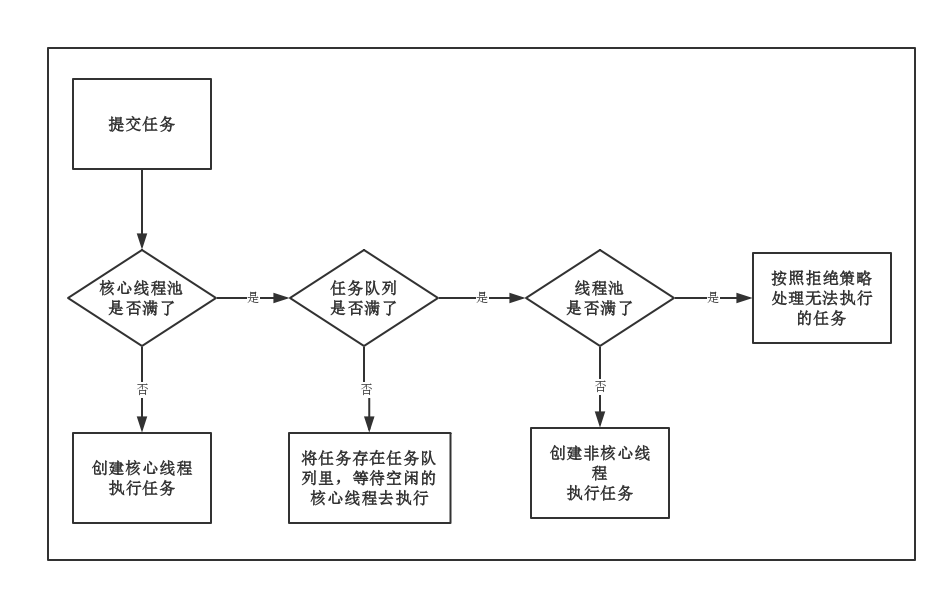
线程池处理流程
提交任务时,源码的执行逻辑
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 判断当前线程数是否小于核心线程数,如果是addWorker创建新的线程
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 否则尝试执行workQueue添加到阻塞队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 队列已满,尝试添加线程,如果失败执行拒绝策略
else if (!addWorker(command, false))
reject(command);
}
也就是说无界队列不会再创建非核心线程数,而是直到内存满了而引发OOM
addWorker
Worker类
线程池本质是一个HashSet<Worker>
本质就是一个thread对象的封装
private final class Worker extends AbstractQueuedSynchronizer implements Runnable{
private static final long serialVersionUID = 6138294804551838833L;
final Thread thread;
Runnable firstTask; // 被分配的第一个工作任务
volatile long completedTasks;
Worker(Runnable firstTask) {
setState(-1);
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
public void run() {
runWorker(this);
}
}
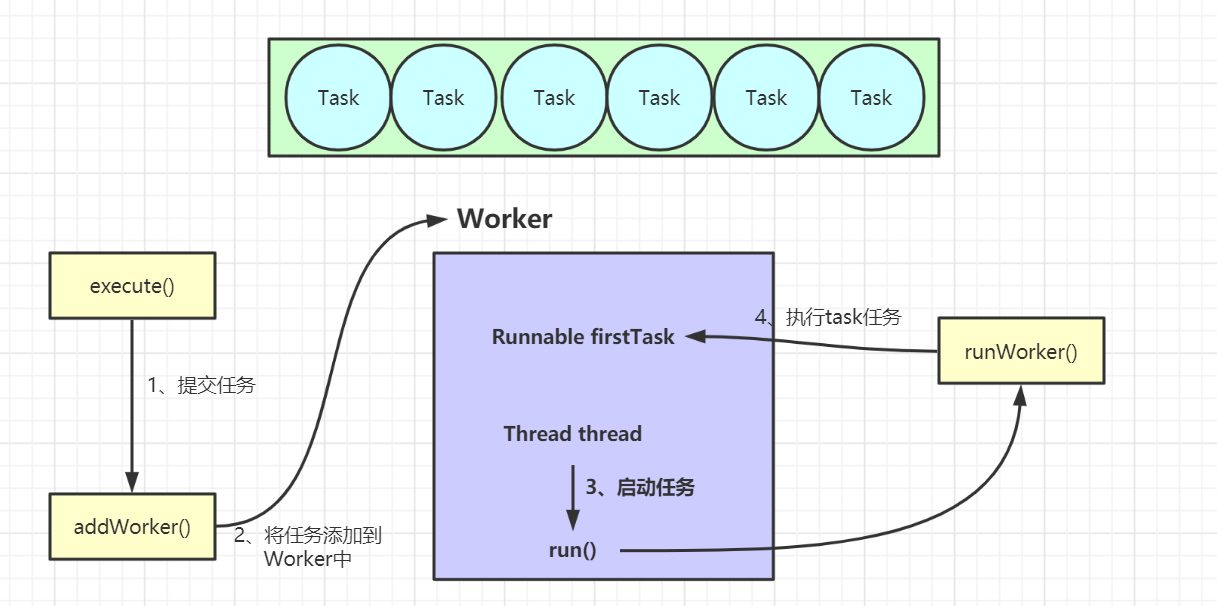
addWorker流程
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
if (rs >= SHUTDOWN && !(rs == SHUTDOWN && firstTask == null && !workQueue.isEmpty()))
return false;
// 自旋修改线程池的线程数
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get();
if (runStateOf(c) != rs)
continue retry;
}
}
// 添加worker,全局操作需要加锁
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
// 调用worker内部的run方法
t.start();
workerStarted = true;
}
}
} finally {
if (!workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
runWorker
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
// 这里unlock是为了防止被线程池中断
w.unlock();
boolean completedAbruptly = true;
try {
// 线程复用(getTask尝试从队列中获取)
while (task != null || (task = getTask()) != null) {
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
// 前置处理(可自定义)
beforeExecute(wt, task);
Throwable thrown = null;
try {
// 真正执行任务
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// 后置处理(可自定义)
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
// Woker退出方法
processWorkerExit(w, completedAbruptly);
}
}

getTask
private Runnable getTask() {
boolean timedOut = false;
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 线程状态或线程数已经不满足要求,主动退出worker并自旋线程数减一
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
// 从队列获取任务的核心方法,take会阻塞,poll会尝试超时等待
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
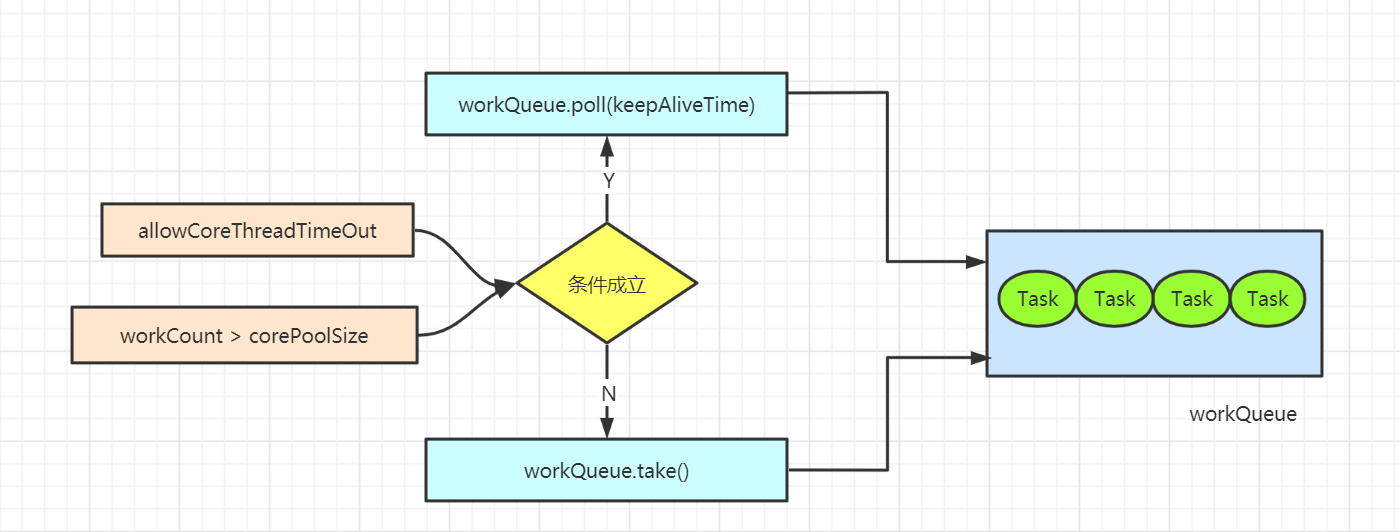
Worker退出
worker进入退出方法后(任务为null,或队列无任务,或异常退出),会尝试执行tryTerminate
final void tryTerminate() {
for (;;) {
int c = ctl.get();
// 判断线程池状态
if (isRunning(c) || runStateAtLeast(c, TIDYING) || (runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))
return;
if (workerCountOf(c) != 0) {
// 尝试中断一个线程(之所以是一个是因为想交由其他worker线程也协助中断)
interruptIdleWorkers(ONLY_ONE);
return;
}
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
// 自定义方法
terminated();
} finally {
ctl.set(ctlOf(TERMINATED, 0));
termination.signalAll();
}
return;
}
} finally {
mainLock.unlock();
}
}
}
线程池的线程复用原理
其实就是runWorker和getTask的逻辑

若有收获,就点个赞吧
0 人点赞
