数据结构
在HashMap的数据结构基础上,并通过双向链表维护顺序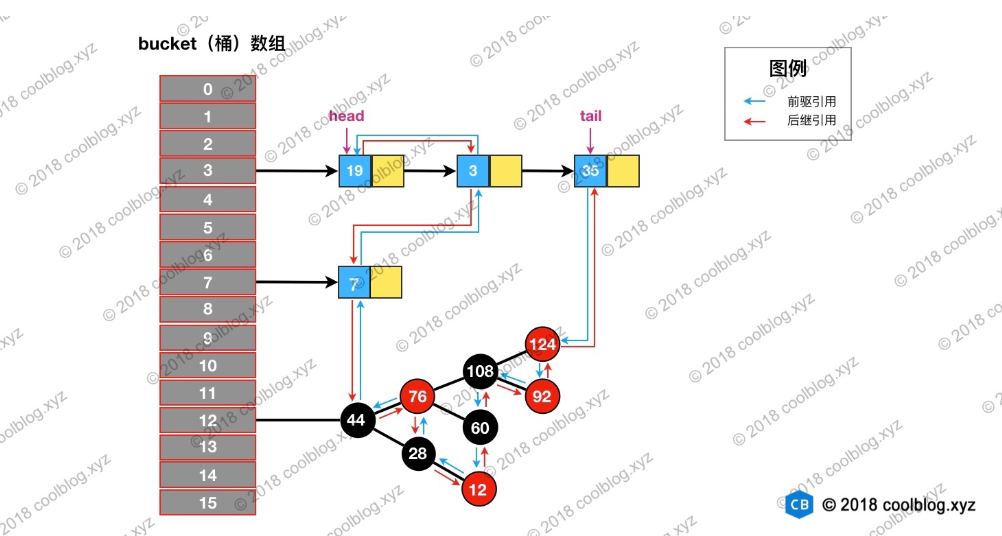
public class LinkedHashMap<K, V> extends HashMap<K, V> implements Map<K, V> {// 继承HashMap,并维护自己独有的双向链表transient LinkedHashMap.Entry<K, V> head;transient LinkedHashMap.Entry<K, V> tail;}
put()
调用的是HashMap的put()方法,但会使用LinkedHashMap覆盖的newNode()
Node<K, V> newNode(int var1, K var2, V var3, Node<K, V> var4) {LinkedHashMap.Entry var5 = new LinkedHashMap.Entry(var1, var2, var3, var4);// 将插入的节点放到链表尾部this.linkNodeLast(var5);return var5;}private void linkNodeLast(LinkedHashMap.Entry<K, V> var1) {LinkedHashMap.Entry var2 = this.tail;this.tail = var1;if (var2 == null) {this.head = var1;} else {var1.before = var2;var2.after = var1;}}
get()
JDK1.8的LRU最近访问放在链表尾部
public V get(Object var1) {Node var2;// 这里的getNode是HashMap get()的核心逻辑if ((var2 = this.getNode(hash(var1), var1)) == null) {return null;} else {// 添加了维护链表顺序的LRU逻辑if (this.accessOrder) {this.afterNodeAccess(var2);}return var2.value;}}void afterNodeAccess(Node<K, V> var1) {LinkedHashMap.Entry var2;if (this.accessOrder && (var2 = this.tail) != var1) {LinkedHashMap.Entry var3 = (LinkedHashMap.Entry)var1;LinkedHashMap.Entry var4 = var3.before;LinkedHashMap.Entry var5 = var3.after;var3.after = null;// 前置节点为Null,则原节点为head节点// 处理前后节点关系if (var4 == null) {this.head = var5;} else {var4.after = var5;}// 后置节点为null,则原节点为tail节点// 处理前后节点关系if (var5 != null) {var5.before = var4;} else {var2 = var4;}// 链表原来是否没元素if (var2 == null) {this.head = var3;} else {// 不是则将原节点放到链表尾部var3.before = var2;var2.after = var3;}this.tail = var3;++this.modCount;}}

若有收获,就点个赞吧
0 人点赞
