序列化就是把内存中的对象,转换称字节序列以便于存储(持久化)和网络传输
反序列化就是将收到的字节序列或者硬盘的持久化数据,转换称内存中的对象
1.1 Java中的序列化和反序列化
package com.BigData.test;import java.io.*;class Student implements Serializable {//简单JAVA类实现Serializable接口private String name;private int age;public Student() {//无参构造}public Student(String name, int age) {//有参构造this.name = name;this.age = age;}public String getName() {//getter和setter方法return name;}public void setName(String name) {//getter和setter方法this.name = name;}public int getAge() {//getter和setter方法return age;}public void setAge(int age) {//getter和setter方法this.age = age;}@Override //toString方法public String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +'}';}}public class Test {public static void main(String[]args) throws IOException, ClassNotFoundException {Student stu = new Student("张三",1001); //构造对象//构造对象输出流ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("data.txt"));oos.writeObject(stu);//输出对象System.out.println("对象序列化输出");System.out.println("################################");//构造输入流ObjectInputStream ois = new ObjectInputStream(new FileInputStream("data.txt"));//输入对象并接受Student stu1 = (Student) ois.readObject();System.out.println("对象反序列化读入");System.out.println(stu1);}}
1.2 Hadoop中的序列化和反序列化
Hadoop框架自己开发了一套序列化机制(Writable)。紧凑,快速,可扩展,互操作
常用的数据类型对应的Hadoop数据序列化类型
| Java类型 | Hadoop Writable类型 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| map | MapWritable |
| array | ArrayWritable |
自定义bean对象要想序列化传输,必须实现序列化接口。具体操作步骤如下7步。
(1)必须实现Writable接口
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
| public FlowBean() { super(); } |
|---|
(3)重写序列化方法
| @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } |
|---|
(4)重写反序列化方法
| @Override public void readFields(DataInput in) throws IOException { upFlow = in.readLong(); downFlow = in.readLong(); sumFlow = in.readLong(); } |
|---|
(5)注意反序列化的顺序和序列化的顺序完全一致
(6)要想把结果显示在文件中,需要重写toString(),可用”\t”分开,方便后续用。
(7)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序。
| @Override public int compareTo(FlowBean o) { // 倒序排列,从大到小 return this.sumFlow > o.getSumFlow() ? -1 : 1; } |
|---|
1.3 案例
统计每一个手机号耗费的总上行流量、下行流量、总流量
数据
phone_data.txt
(1)输入数据格式:
| 7 13560436666 120.196.100.99 1116 954 200 id 手机号码 网络ip 上行流量 下行流量 网络状态码 |
|---|
(2)期望输出数据格式
| 13560436666 1116 954 2070 手机号码 上行流量 下行流量 总流量 |
|---|
实现代码
package com.BigData.MapReduce;import org.apache.hadoop.io.Writable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;public class FlowBean implements Writable {private long upFlow;private long downFlow;private long sumFlow;public FlowBean(){}public FlowBean(long upFlow, long downFlow, long sumFlow) {this.upFlow = upFlow;this.downFlow = downFlow;this.sumFlow = sumFlow;}public long getUpFlow() {return upFlow;}public void setUpFlow(long upFlow) {this.upFlow = upFlow;}public long getDownFlow() {return downFlow;}public void setDownFlow(long downFlow) {this.downFlow = downFlow;}public long getSumFlow() {return sumFlow;}public void setSumFlow(long sumFlow) {this.sumFlow = sumFlow;}@Overridepublic String toString() {return "FlowBean{" +"upFlow=" + upFlow +", downFlow=" + downFlow +", sumFlow=" + sumFlow +'}';}@Overridepublic void write(DataOutput out) throws IOException {out.writeLong(upFlow);out.writeLong(downFlow);out.writeLong(sumFlow);}@Override//反序列化方法读顺序必须和写序列化方法的写顺序必须一致public void readFields(DataInput in) throws IOException {this.upFlow = in.readLong();this.downFlow = in.readLong();this.sumFlow = in.readLong();}}
package com.BigData.MapReduce;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.yarn.webapp.hamlet.HamletSpec;import java.io.IOException;import java.net.URI;import java.net.URISyntaxException;public class MapReduceDemo {public static class MyMapper extends Mapper<LongWritable, Text, Text, FlowBean> {protected void map(LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, FlowBean>.Context context) throws java.io.IOException ,InterruptedException{String line = value.toString();String[] data = line.split("\t");FlowBean flow = new FlowBean();flow.setUpFlow(Long.parseLong(data[data.length-3]));flow.setDownFlow(Long.parseLong(data[data.length-2]));flow.setSumFlow(Long.parseLong(data[data.length-3])+Long.parseLong(data[data.length-2]));context.write(new Text(data[1]),flow);}}//=======分割线=========//shuffle 进行合并,分区,分组,排序。相同的k2的数据会被同一个reduce拉取。//第二部分,写Reduce阶段// public static class MyReduce extends Reducer<Text, LongWritable, Text, LongWritable> {// //同样是有reduce函数// @Override// protected void reduce(Text k2, Iterable<LongWritable> v2s,// Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {//// }// }public static void main(String[] args) throws Exception{//设置配置参数Configuration conf = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://192.168.142.20:9000"),conf);if(fs.exists(new Path("/out")))fs.delete(new Path("/out"),true);//创建任务conf.set("fs.defaultFS","hdfs://192.168.142.20:9000");Path input = new Path("/data/phone_data.txt");Path output = new Path("/out");Job job = Job.getInstance(conf, MapReduceDemo.class.getSimpleName());//指定jar文件job.setJarByClass(MapReduceDemo.class);//指定输入路径,数据在hdfs上的输入路径,指定第一个参数是hdfs输入路径FileInputFormat.addInputPath(job,input);//指定map的类job.setMapperClass(MyMapper.class);//指定map输出的key和value的数据类型。job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);job.setNumReduceTasks(0);//指定reduce类以及输出数据类型。//job.setReducerClass(MyReduce.class);//job.setOutputKeyClass(Text.class);//job.setOutputValueClass(LongWritable.class);//指定输出路径hdfsFileOutputFormat.setOutputPath(job,output);//提交任务,如果是true,会返回任务执行的进度信息等。job.waitForCompletion(true);}}
运行结果: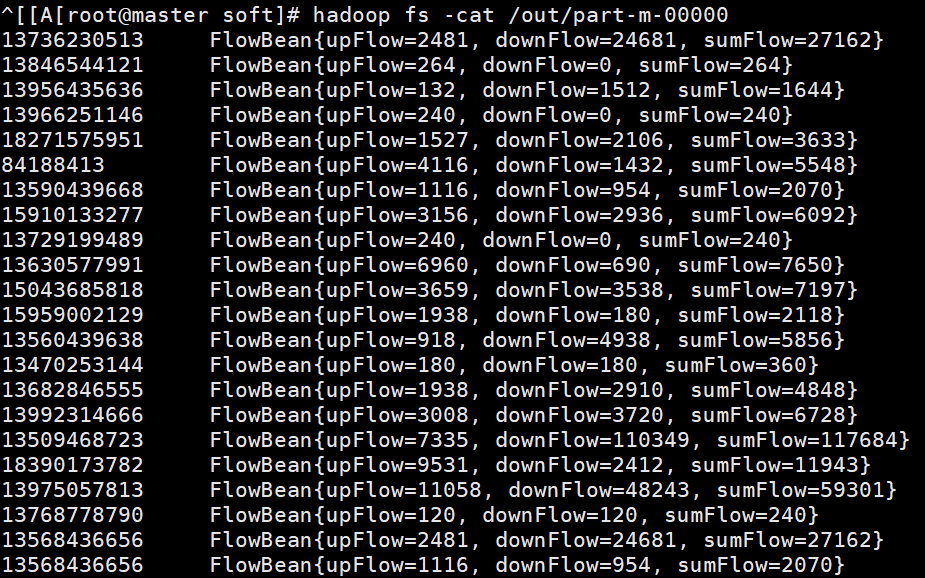
调整运行结果的格式,修改FlowBean的toString()方法即可

若有收获,就点个赞吧
0 人点赞
