MapTask和ReduceTask均会对数据按照key进行排序,该操作属于Hadoop的默认行为。默认按照字典顺序排序,且使用快速排序。
比如: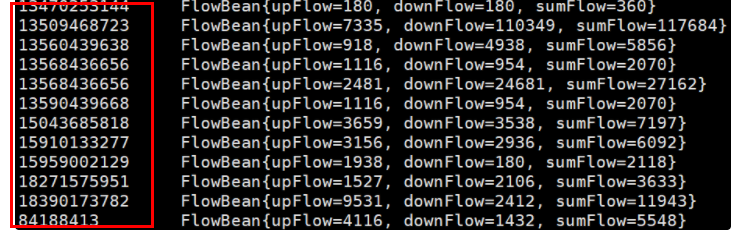
3.1 JAVA中的自定义排序
案例:对一个基本数据类型,调用Arrays.sort方法进行排序
package com.BigData.test;import java.util.Arrays;public class Test {public static void main(String[]args) {int[] data = {4,5,1,2,7,8};for(int x:data)System.out.println(x);System.out.println("#######################");Arrays.sort(data);for(int x:data)System.out.println(x);}}
案例:自定义排序
如果自定义类不支持排序,则会抛出异常
:::info
Exception in thread “main” java.lang.ClassCastException: com.BigData.test.Student cannot be cast to java.lang.Comparable
:::
让自定义类实现Comparable接口,并重写compareTo方法明确排序规则
package com.BigData.test;import java.util.Arrays;class Student implements Comparable {private String name;private int age;public Student() {}public Student(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +'}';}@Overridepublic int compareTo(Object o) {Student stu = (Student) o;return stu.age-this.age;}}public class Test {public static void main(String[]args) {Student [] stu = new Student[]{new Student("张三",10),new Student("李四",11),new Student("王五",9),new Student("赵六",15)};for(Student s : stu)System.out.println(s);System.out.println("############排序分割线");Arrays.sort(stu);for(Student s : stu)System.out.println(s);}}
运行结果: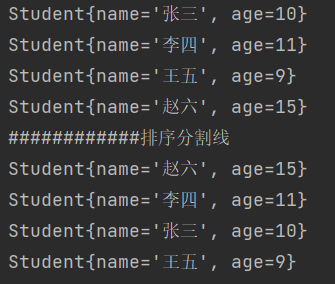
另比如需要按照姓名的字典序排序,则改写compareTo中的比较规则即可
public int compareTo(Object o) {Student stu = (Student) o;return stu.name.compareTo(this.name);}
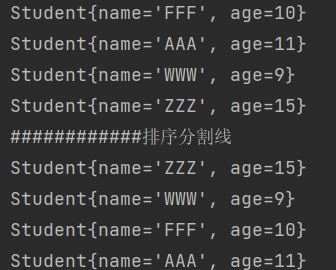
3.2 Hadoop中的自定义排序
bean对象实现WritableComparable接口重写compareTo方法,就可以实现排序
案例:
要求每个省份手机号输出的文件中按照总流量排序。
package com.BigData.MapReduce;import org.apache.hadoop.io.Writable;import org.apache.hadoop.io.WritableComparable;import org.apache.hadoop.yarn.webapp.hamlet.HamletSpec;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;public class FlowBean implements WritableComparable {private long upFlow;private long downFlow;private long sumFlow;private long phone;public FlowBean(){}public FlowBean(long upFlow, long downFlow, long sumFlow, long phone) {this.upFlow = upFlow;this.downFlow = downFlow;this.sumFlow = sumFlow;this.phone = phone;}public long getUpFlow() {return upFlow;}public void setUpFlow(long upFlow) {this.upFlow = upFlow;}public long getDownFlow() {return downFlow;}public void setDownFlow(long downFlow) {this.downFlow = downFlow;}public long getSumFlow() {return sumFlow;}public void setSumFlow(long sumFlow) {this.sumFlow = sumFlow;}public long getPhone() {return phone;}public void setPhone(long phone) {this.phone = phone;}@Overridepublic String toString() {return this.phone+"\t"+this.upFlow+"\t"+this.downFlow+"\t"+this.sumFlow;}@Overridepublic int compareTo(Object o) {FlowBean fb = (FlowBean) o;return (int)(fb.sumFlow - this.sumFlow);}@Overridepublic void write(DataOutput out) throws IOException {out.writeLong(upFlow);out.writeLong(downFlow);out.writeLong(sumFlow);out.writeLong(phone);}@Overridepublic void readFields(DataInput in) throws IOException {this.upFlow = in.readLong();this.downFlow = in.readLong();this.sumFlow = in.readLong();this.phone=in.readLong();}}
MapReduce主程序
package com.BigData.MapReduce;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;import java.net.URI;public class MapReduceDemo {public static class MyMapper extends Mapper<LongWritable, Text, FlowBean,Text> {protected void map(LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, FlowBean, Text>.Context context) throws java.io.IOException ,InterruptedException{String line = value.toString();String[] data = line.split("\t");FlowBean flow = new FlowBean();flow.setPhone(Long.parseLong(data[1]));flow.setUpFlow(Long.parseLong(data[data.length-3]));flow.setDownFlow(Long.parseLong(data[data.length-2]));flow.setSumFlow(Long.parseLong(data[data.length-3])+Long.parseLong(data[data.length-2]));context.write(flow,new Text(""));}}// =======分割线=========// shuffle 进行合并,分区,分组,排序。相同的k2的数据会被同一个reduce拉取。// 第二部分,写Reduce阶段public static class MyReduce extends Reducer<FlowBean, Text, FlowBean, Text> {//同样是有reduce函数@Overrideprotected void reduce(FlowBean k2, Iterable<Text> v2s,Reducer<FlowBean, Text, FlowBean, Text>.Context context) throws IOException, InterruptedException {for(Text fb : v2s)context.write(k2,fb);}}public static void main(String[] args) throws Exception{//设置配置参数Configuration conf = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://192.168.142.20:9000"),conf);if(fs.exists(new Path("/out")))fs.delete(new Path("/out"),true);//创建任务conf.set("fs.defaultFS","hdfs://192.168.142.20:9000");Path input = new Path("/data/phone_data.txt");Path output = new Path("/out");Job job = Job.getInstance(conf, MapReduceDemo.class.getSimpleName());//指定jar文件job.setJarByClass(MapReduceDemo.class);//指定输入路径,数据在hdfs上的输入路径,指定第一个参数是hdfs输入路径FileInputFormat.addInputPath(job,input);//指定map的类job.setMapperClass(MyMapper.class);//指定map输出的key和value的数据类型。job.setMapOutputKeyClass(FlowBean.class);job.setMapOutputValueClass(Text.class);//指定reduce类以及输出数据类型。job.setReducerClass(MyReduce.class);job.setOutputKeyClass(FlowBean.class);job.setOutputValueClass(Text.class);//指定输出路径hdfsFileOutputFormat.setOutputPath(job,output);//提交任务,如果是true,会返回任务执行的进度信息等。job.waitForCompletion(true);}}
运行结果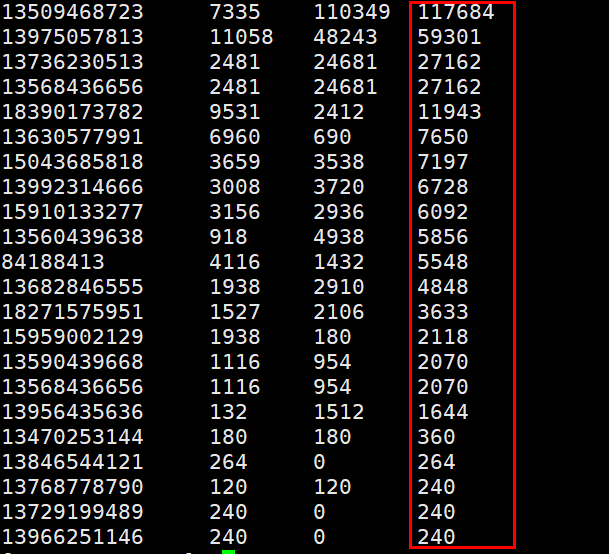

若有收获,就点个赞吧
0 人点赞
