输入数据:
group.txt
实现每一类订单中输出最大值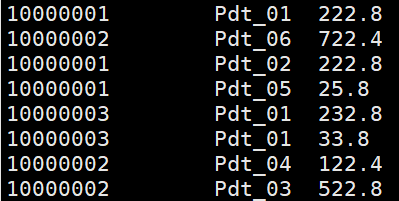
4.1 方式一
方式一:按订单id分组,进入同一个reduce中排序输出最大值。此方法也可以输出排序后的前N条记录,但是这种方法在数据量大时候不科学。
package com.BigData.MapReduce;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;import java.net.URI;import java.util.ArrayList;import java.util.Arrays;import java.util.List;public class MapReduceDemo {public static class MyMapper extends Mapper<LongWritable, Text, Text,OrderBean> {protected void map(LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, OrderBean>.Context context) throws java.io.IOException ,InterruptedException{String line = value.toString();String[] data = line.split("\t");OrderBean ob = new OrderBean();ob.setId(Integer.parseInt(data[0]));ob.setMoney(Double.parseDouble(data[2]));context.write(new Text(data[0]),ob);}}// =======分割线=========// shuffle 进行合并,分区,分组,排序。相同的k2的数据会被同一个reduce拉取。// 第二部分,写Reduce阶段public static class MyReduce extends Reducer<Text, OrderBean, OrderBean, Text> {//同样是有reduce函数@Overrideprotected void reduce(Text k2, Iterable<OrderBean> v2s,Reducer<Text, OrderBean, OrderBean, Text>.Context context) throws IOException, InterruptedException {List<OrderBean> list = new ArrayList<>();for(OrderBean o : v2s){OrderBean ob = new OrderBean(o.getId(),o.getMoney());list.add(ob);}list.sort((o1,o2)->(int)(o2.getMoney()-o1.getMoney()));context.write(list.get(0),new Text(""));}}public static void main(String[] args) throws Exception{//设置配置参数Configuration conf = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://192.168.142.20:9000"),conf);if(fs.exists(new Path("/out")))fs.delete(new Path("/out"),true);//创建任务conf.set("fs.defaultFS","hdfs://192.168.142.20:9000");Path input = new Path("/data/group.txt");Path output = new Path("/out");Job job = Job.getInstance(conf, MapReduceDemo.class.getSimpleName());//指定jar文件job.setJarByClass(MapReduceDemo.class);//指定输入路径,数据在hdfs上的输入路径,指定第一个参数是hdfs输入路径FileInputFormat.addInputPath(job,input);//指定map的类job.setMapperClass(MyMapper.class);//指定map输出的key和value的数据类型。job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(OrderBean.class);//指定reduce类以及输出数据类型。job.setReducerClass(MyReduce.class);job.setOutputKeyClass(OrderBean.class);job.setOutputValueClass(Text.class);//指定输出路径hdfsFileOutputFormat.setOutputPath(job,output);//提交任务,如果是true,会返回任务执行的进度信息等。job.waitForCompletion(true);}}

方式二
GroupingComparator进行辅助分组排序,该类方法可以自定义进入同一reduce的规则。首先将记录封装称OrderBean,先按id排序,再按money排序,自定义id相同进入同一reduce,按个数直接输出即可
package com.BigData.MapReduce;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.io.WritableComparator;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;import java.net.URI;import java.util.ArrayList;import java.util.List;public class MapReduceDemo {public static class MyMapper extends Mapper<LongWritable, Text, OrderBean,Text> {protected void map(LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, OrderBean,Text>.Context context) throws java.io.IOException ,InterruptedException{String line = value.toString();String[] data = line.split("\t");OrderBean ob = new OrderBean();ob.setId(Integer.parseInt(data[0]));ob.setMoney(Double.parseDouble(data[2]));context.write(ob,new Text(""));}}// =======分割线=========// shuffle 进行合并,分区,分组,排序。相同的k2的数据会被同一个reduce拉取。// 第二部分,写Reduce阶段public static class MyReduce extends Reducer<OrderBean, Text, OrderBean, Text> {//同样是有reduce函数@Overrideprotected void reduce(OrderBean k2, Iterable<Text> v2s,Reducer<OrderBean, Text, OrderBean, Text>.Context context) throws IOException, InterruptedException {context.write(k2,new Text(""));}}public static void main(String[] args) throws Exception{//设置配置参数Configuration conf = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://192.168.142.20:9000"),conf);if(fs.exists(new Path("/out")))fs.delete(new Path("/out"),true);//创建任务conf.set("fs.defaultFS","hdfs://192.168.142.20:9000");Path input = new Path("/data/group.txt");Path output = new Path("/out");Job job = Job.getInstance(conf, MapReduceDemo.class.getSimpleName());//指定jar文件job.setJarByClass(MapReduceDemo.class);//指定输入路径,数据在hdfs上的输入路径,指定第一个参数是hdfs输入路径FileInputFormat.addInputPath(job,input);//指定map的类job.setMapperClass(MyMapper.class);//指定map输出的key和value的数据类型。job.setMapOutputKeyClass(OrderBean.class);job.setMapOutputValueClass(Text.class);//指定reduce类以及输出数据类型。job.setReducerClass(MyReduce.class);job.setOutputKeyClass(OrderBean.class);job.setOutputValueClass(Text.class);job.setGroupingComparatorClass(MyGroupComparator.class);//指定输出路径hdfsFileOutputFormat.setOutputPath(job,output);//提交任务,如果是true,会返回任务执行的进度信息等。job.waitForCompletion(true);}}class MyGroupComparator extends WritableComparator{protected MyGroupComparator() {super(OrderBean.class, true);}@Overridepublic int compare(WritableComparable a, WritableComparable b) {OrderBean ob1 = (OrderBean) a;OrderBean ob2 = (OrderBean) b;return ob1.getId()-ob2.getId();}}
注意:
(1)需要设置 job.setGroupingComparatorClass(MyGroupComparator.class);
(2)重写compare方法中的参数要选择WritableComparable类型
(3)如果需要分组排序后输出前N项,在reduce中加一个循环即可。比如,输出每组排名前两个
for(int i = 0; i <=1; i++)context.write(k2,new Text(""));
运行结果: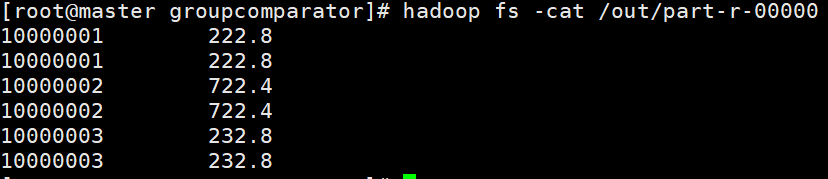

若有收获,就点个赞吧
0 人点赞
