为了实现控制最终文件的输出路径和输出格式,可以自定义OutputFormat。
例如:要在一个MapReduce程序中根据数据的不同输出两类结果到不同目录,这类灵活的输出需求可以通过自定义类来实现。
步骤:
- 自定义一个类继承FileOutputFormat
- 改写RecordWriter,具体改写输出数据的方法write()
- 在主程序中设置输出类为自定义类
案例:
(需求)过滤输入的log日志,包含atguigu的网址输出到/log/atguigu.log,不包含atguigu的网站输出到/log/other.log
(1) 数据
log.txt
package com.BigData.MapReduce;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FSDataOutputStream;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.*;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.RecordWriter;import org.apache.hadoop.mapreduce.TaskAttemptContext;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;import java.net.URI;import java.net.URISyntaxException;public class MapReduceDemo {public static class MyMapper extends Mapper<LongWritable, Text, Text, NullWritable> {protected void map(LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text,NullWritable>.Context context) throws java.io.IOException ,InterruptedException{String line = value.toString();context.write(new Text(line+"\n"),NullWritable.get());}}// =======分割线=========public static void main(String[] args) throws Exception{//设置配置参数Configuration conf = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://192.168.142.20:9000"),conf);if(fs.exists(new Path("/out")))fs.delete(new Path("/out"),true);//创建任务conf.set("fs.defaultFS","hdfs://192.168.142.20:9000");Path input = new Path("/data/log.data");Path output = new Path("/out");Job job = Job.getInstance(conf, MapReduceDemo.class.getSimpleName());//指定jar文件job.setJarByClass(MapReduceDemo.class);//指定输入路径,数据在hdfs上的输入路径,指定第一个参数是hdfs输入路径FileInputFormat.addInputPath(job,input);//指定map的类job.setMapperClass(MyMapper.class);//指定map输出的key和value的数据类型。job.setMapOutputKeyClass(OrderBean.class);job.setMapOutputValueClass(Text.class);//指定reduce类以及输出数据类型。job.setNumReduceTasks(0);//指定输出路径hdfsjob.setOutputFormatClass(MyFileOutPutFormat.class);FileOutputFormat.setOutputPath(job,output);//提交任务,如果是true,会返回任务执行的进度信息等。job.waitForCompletion(true);}}class MyFileOutPutFormat extends FileOutputFormat<Text,NullWritable>{@Overridepublic RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {try {return new MyRecordWriter(taskAttemptContext);} catch (URISyntaxException e) {e.printStackTrace();}return null;}}class MyRecordWriter extends RecordWriter<Text, NullWritable>{private Path output1;private Path output2;private FSDataOutputStream fos1;private FSDataOutputStream fos2;private FileSystem fs;public MyRecordWriter(TaskAttemptContext taskAttemptContext) throws IOException, URISyntaxException {output1 = new Path("/log/atguigu.log");output2 = new Path("/log/other.log");Configuration conf = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://192.168.142.20:9000"),conf);fos1 = fs.create(output1);fos2 = fs.create(output2);}@Overridepublic void write(Text key, NullWritable value) throws IOException, InterruptedException {String data = key.toString();if(data.contains("atguigu"))fos1.writeUTF(data);elsefos2.writeUTF(data);}@Overridepublic void close(TaskAttemptContext context) throws IOException, InterruptedException {if(fos1!=null)fos1.close();if(fos2!=null)fos2.close();if(fs!=null)fs.close();}}
(2)运行结果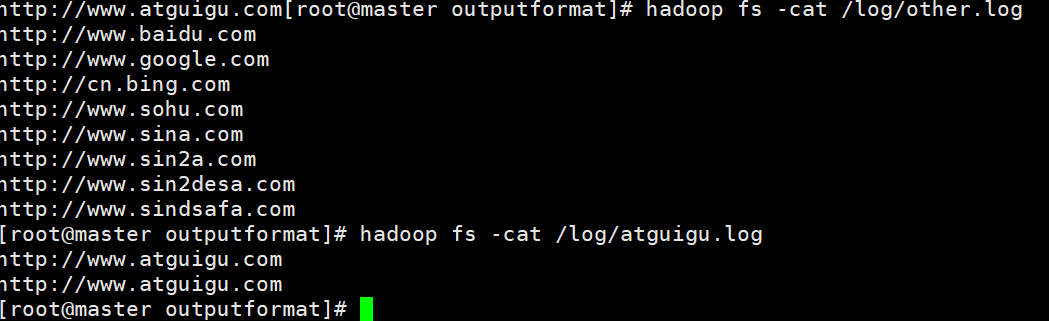

若有收获,就点个赞吧
0 人点赞
