为什么是从SD开始?
当前主流的图片AIGC就是SD和Midjourney之争了,甚至在某些维度上让我想到iOS和Android。MJ做得很好,但我仍然希望你的入门和进阶都从SD入手。- 可控性。AI出图最大的阻力就是可控性,包括图片质量的可控和图片内容的可控。图片生成得完整,好看是MJ的强项,普通人大概只需要这个需求发发朋友圈吹牛打屁,换换头像。而真正要做到心有所想,生而所得,MJ和它的用户都在努力,但把这一部分只交给关键词来控制很难。这里有更多控制变量的SD有巨大的优势。
- 开源性,战未来。并不是说闭源不好,提供良好的使用体验,黑盒去噪,是MJ努力降低图片AIGC的门槛的产品思路,但拥有越来越成熟丰富的开源生态的SD,也意味着会有越来越多的神级插件,越来越厉害的技术融合,进一步提高美术生产效率和精度。
- 灵活私密性,SD可以像MJ一样云端部署,随时随地可以访问。也可以本地部署,调用本地的算力,灵活的调整配置所需的生产环境。隐私性也是很多像游戏、影视等商业项目只考虑SD本地部署的重要原因。
MJ很贵。呸,MJ很简单没挑战。呸,SD的知识体系很碎片,更需要一个开始。
准备工作
在决定使用SD来解决我们所需的生图需求后,也初步了解了AI和扩散模型的工作原理后我们需要开始准备第一部分了。这里有三个比较重要的部分需要提前准备,并且这三部分决定了后面我们在生图能达到的质量高度和效率高度,他们分别是算力,工具和模型。
硬件

你看我这算力如何(硬件篇)链接漏了,看公号历史查询。
如果,你对计算机的基础常识都不能理解,你只会用开关机,那我大概率还得出一篇:工具
准备好了硬件就要准备软件工具,与很多只能在云服务上使用的工具不同,SD借助开源工具,可以云端部署,也可以本地部署,使用上面提到的本地硬件来运行,这样更“私有”,也更灵活可控。 当然,你可能也需要忍受他们糟糕的用户体验和凌乱的界面。大概长这样。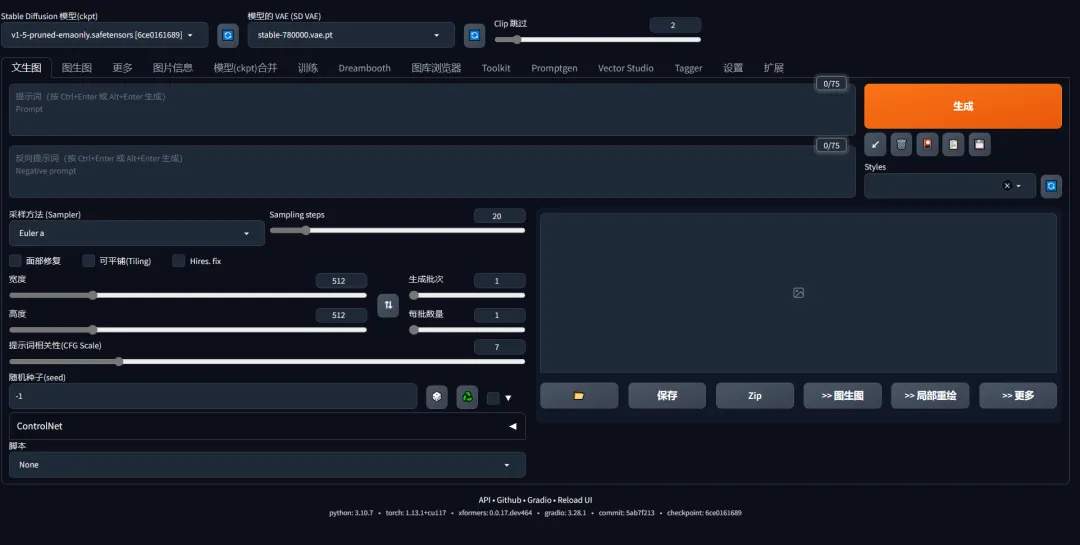
- Web UI Stable Diffusion WebUi 一个基于 Gradio 库的开源工具,由个人大神automatic1111开发,并在全球开发者贡献下,成为一个强大的最主流的生产工具。(上图1)
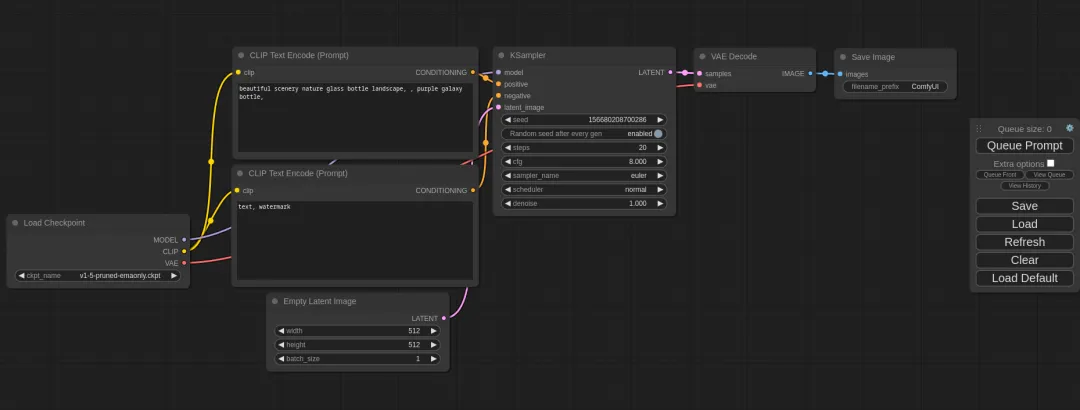
- ComfyUI 流程图/模块化设计的 Stable Diffusion GUI,采用连线式交互,更接近现有游戏、影视的生产流程和交互方式,门槛更高,天花板也更高。(上图2)
模型

上面提到的懒人包中通常有一个模型提供,如果没有可以自行从下面2个网站下载,
关于模型的更多格式版本补充可以看这篇:
我也会定期推荐优秀的模型给大家(挖坑2).
准备完毕,尝试生第一张图
你可以啥也不想,啥也不看,轻轻的用你的鼠标点击一下屏幕上那颗大大的,方方的,橘黄的生成按钮,在终端中会显示进度,右下角的区域就出现了一张图,它可能长这么个模样。
Step1. 先认参数
把大象装冰箱,得先把冰箱门打开。同样,想自己生图就需要先认识一下一张图片是由哪些参数得出的。上面我们点了生成按钮,在电脑右下角收获了一张图片,这张图片的下发有一堆参数(每一次生成都有一组参数在这个地方显示)
| Steps: 20, Sampler: Euler a, CFGscale: 7, Seed: 2607380765, Size: 512x512, Modelhash: b6928134bb,Model:25D_mixProV3_v3, Clipskip: 2, ENSD: 31337, Version: v1.3.2 |
|---|
简单解释这些参数:
Steps:**迭代次数**,取值与采样方法有关。 代表迭代(渲染)步数。根据图片质量和内容复杂程度,取15-30之间,太高影响较小,也加大运算时间。回报递减,取决于采样器。
Sampler:**采样方法**(不同的采样方法有不同的效果和速度),Euler a就很好用,速度也很快。其他采样器也各有特点,需要我们在生产的过程中耐心去试。
CFGscale:**图像与你的提示的匹配程度**。增加这个值将导致图像更接近你的提示(根据模型),但它也在一定程度上降低了图像质量。可以用更多的采样步骤来抵消。默认为7,更小ai更具创造力,太高则容易过饱和和混乱,一般少调整。
Seed:保持这个值不变,可以多次生成相同(或相似)的图像。种子是决定生图结果的随机数。遇到随到不错的种子可以记住这个值下次还找你。通常-1随机。
Size:就是图片的尺寸。默认都是512x512。更大的图片也意味着需要更多的显存和更长的时间来生成。
Model:这是我们选择的模型。Modelhash:这是模型的身份证。
ENSD:对图像质量无任何提升, 只为ancestral采样方法产生不同的结果,无视。
Version:这是你的sd版本,不用关心。
Clip skip:这个参数的原理是十分复杂的,而且设置它很频繁,简单理解就是写实图设置1,二次元一些就设置2。有些制作精良的模型介绍也会给出clip skip值的影响。

Step2. 再次认识WebUI
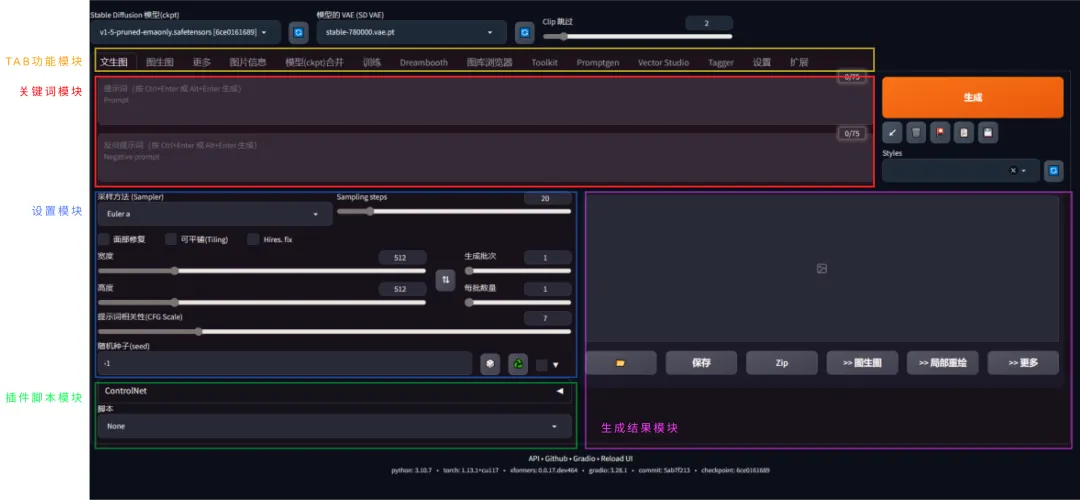
TAB功能模块:每个标签在WebUI都是一个独立的功能,如文生图,图生图,训练,设置,以及很多独立的,功能强大的插件。
关键词模块:这里有2个面积巨大的输入框,分别是正向关键词和反向关键词。这里就是我们用文本控制出什么图的操作台了。
设置模块:有没有很熟悉,这里很多参数都是我们在生成一张图后,显示出来的参数,上面已经有一一介绍,这里通过uikit调整这些参数来控制最终生成的图片是什么样子的。(MJ策略性的隐藏了这部分)
生成结果模块:这里预留了一些空间,来实时预览我们的生图过程和展现生图结果,如果有多张图片也会罗列,有一些快捷功能可以操作图片。还有底部有图片参数详细信息和生图过程中的错误反馈。
插件脚本模块:最后就是插件脚本模块,在生图的前中后周期中都有不同的插件服务,这里会是主要的陈放之所。
Step3. 关键词和基础设置
我们在TAB功能模块区找到PNG图像信息(PNG info),切换过去然后将一张AI生成的PNG图片导入进去。我们也会得到这样的一组参数:

| 关键词 shose, sleek glass thickness,transparent, holographic,smooth color background,cinematic lighting,4k, Negative prompt(low quality), (worst quality:1.4) |
|---|
| 设置 Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 3793992816, Size: 512x512, Model hash: 9aba26abdf, Model: deliberate_v2, Clip skip: 2, ENSD: 31337, Version: v1.3.2 |
|---|
复习一下上面的知识点。
这只鞋子的参数是:采样步数20(默认),采样器Eular a(默认),CFG7(默认),种子balabala,尺寸512(默认),Clip跳过2(默认),模型deliberate_v2。 除了模型和第一次的生成不同外,其他参数都一样的,起到生出这双科技质感的鞋子关键作用的是关键词+模型了。
关键词:
- Prompt:对你想要生成的东西进行文字描述。正向关键词可以使用英文的自然语言描述,可以用单词,词组,颜文字,emoji…通过逗号,空格来分割。词汇的顺序,重复,权重,在模型中语义的自带权重等都会影响生图结果。
- Negative prompt:用文字描述你不希望在图像中出现的东西。反向关键词与上面相同的格式语法,且2者互相 影响。如果填写了仍然出现可以适当的增加权重。格式为(),(()),(xxx:1.6),降权同理[],[[]].[xxx:1.4]。
模型:
模型前面已经提及,在生图过程过,WebUI的工作都需要基于某一个大模型,所以在用户界面上,选模型是放在最靠前的位置。基础设置:
那是不是前面讲的一大堆参数就都默认不管就行了? 如果在对策入门早期,没有精力理解确实可以不用掌握,都默认即可。但不代表这部分是没用的,看我调整了采样器和采样步数后(仍然随机种子),又会得到下面这张图。
| Steps: 40, Sampler: DDIM, CFGscale: 7, Seed: 1196435060, Size: 512x512, Modelhash: 9aba26abdf, Model: deliberate_v2, Clipskip: 2, ENSD: 31337, Version: v1.3.2 |
|---|
最后再补充一个经常使用的设置参数:
Batch count/Batch size:决定生成的图片数量。可以简单理解前者生几批图,后者每批生几张图。如果显存足够,则可以增加 Batch Size;否则,只能增加 Batch Count,得到的图片数量是两者之积(对于显存较小的情况,建议只修改 Batch Count)。进阶部分
至此,恭喜你,你已经成功把大象装进了冰箱~ 至于想再装狮子老虎,就是进阶部分了。主要也就4个部分。分别是图生图(包括局部重绘),WebUI插件,小模型(LoRA、Embedding、Hypernetwork等),以及大小模型的训练finetune(俗称炼丹)。图生图(img2img)&局部重绘(inpaint)
图生图其实本质仍然是文生图(txt2img),只是把上传的参考图转出成为了关键词信息,其他参数都与上面提到的文生图参数一致,当你把文生图熟练掌握后,图生图就显得十分简单了。 只多了1个与图片相关的设置:Denoise strength,而inpaint则是在图生图的基础上多了一组蒙版设置。 局部重绘在很多时候能在工作流程上提供很好的解决办法,将生成图片导入局部重绘中,对问题部分进行多次局部重绘,且可进行多次图生图。这里如果使用一些第三方插件如ps插件会更加自如,最新的ps官方也是使用相似的工作原理。 利用好图生图和局部重绘在复杂的工作流中将是一个很重要的技能。后续实战篇会有更多的提及。(挖坑2)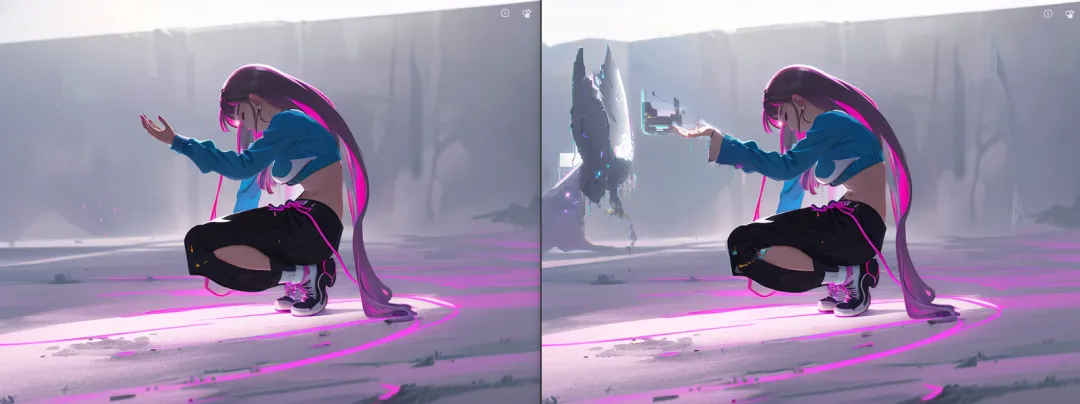
插件
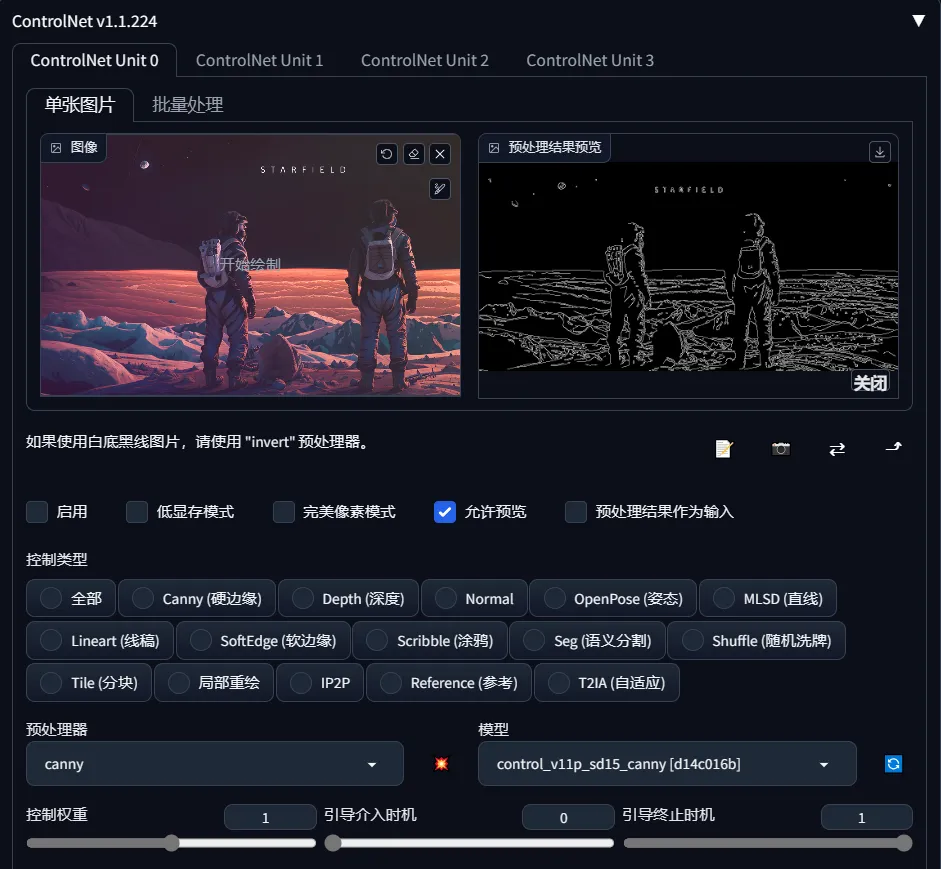
得益于良好的开源生态,我们能在webui上使用很多拓展工具,这些插件有的能改变工作体验,有些能实现某些革命性的解决问题的办法。受篇幅影响,我不在这里一一列举,只先管中窥豹一下它们的强大。 值得庆幸的是,很多整合包就整合了很多好用的插件(这也是懒人包的亮点之一,佬与佬的品味差距)比如:controlnet:能用专门的轮廓识别、动作识别、景深识别等预处理模型让需要的对应图片牢牢的control住的神级插件!
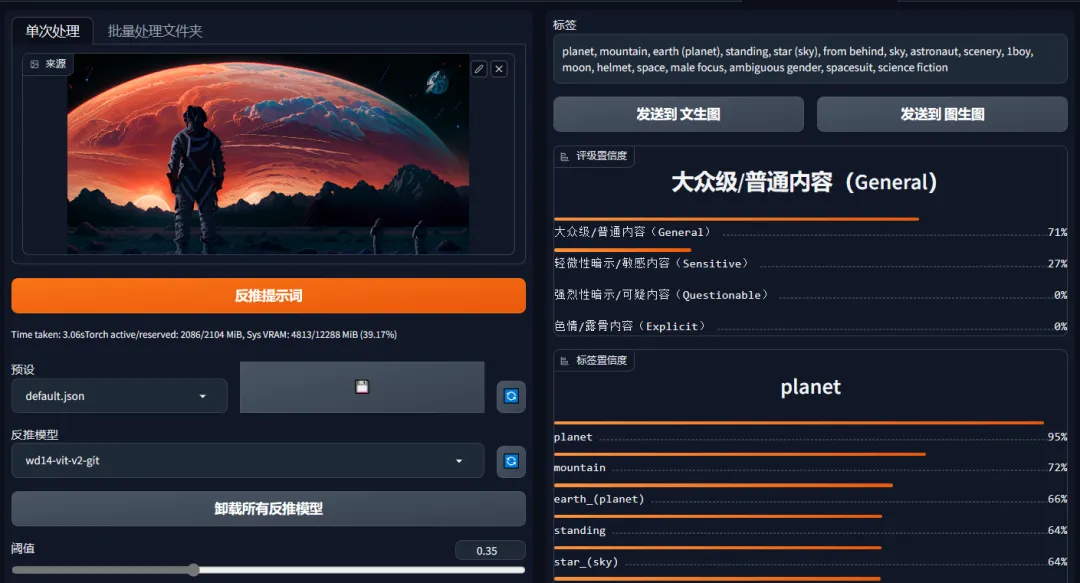
tagger:可以通过图像识别,反推关键词的插件。
LoRA、Embedding、Hypernetwork
这部分要解释起来还很麻烦,但这些又是进阶的很重要的一部分,大概是很多人使用SD而不用MJ的最核心部分吧。 简单的说,他们就是一个个的微型模型。他们可以在一个模型上串联另一个模型的一部分特征,并且可以修改权重。- LoRA:与下面二者不同,LoRA更接近完整的大模型,这个是出现最晚,但最强的概念。通过少量图片就能很好的微调大模型得到一个文件大小相对很小的模型文件。(大小几兆-两三百兆的.safetensors格式)
- Embedding:是Textual Inversion的结果,教 AI 用模型中的标签组成一个 人或者物品。更接近从模型中“找”。是去年还比较流行的炼丹方式,文件很小是优点(大小2kb的.pt格式)。
- Hypernetwork:中文叫超网,也是很成熟的一种技术,就像一层层盖棉被一样去改变模型的细节。通过调节权重来改变生成结果,适合调整风格。(大小100-300兆的.pt格式,根据层数决定)
炼丹
至于如何生产大小模型,想到过年那会儿我没日没夜,废寝忘食的炼丹,炸炉,炼丹…睁眼炼丹,闭眼睡觉的场景就不寒而栗…
若有收获,就点个赞吧
0 人点赞
